
Gói Proxy giảm tới75% GIẢM+15% Thưởngvới

Go, còn được gọi là Golang, là một ngôn ngữ lập trình mã nguồn mở được phát triển bởi Google để cải thiện hiệu suất và tốc độ lập trình, đặc biệt khi xử lý các nhiệm vụ đồng thời. Go kết hợp lợi ích của các ngôn ngữ kiểu tĩnh và kiểu động để cung cấp tốc độ biên dịch và hiệu suất chạy nhanh.
Làm thế nào để xây dựng một Web Scraper bằng cách sử dụng thư viện Colly trong ngôn ngữ lập trình Go? Nstbrowser sẽ hướng dẫn bạn qua từng phần mã để hiểu rõ hơn.
Đừng lãng phí thêm thời gian nữa! Hãy tìm hiểu các bước chi tiết ngay bây giờ.
Trước khi bắt đầu scraping, hãy thiết lập dự án Go của chúng ta. Tôi sẽ dành vài giây để thảo luận về cách cài đặt nó. Vì vậy, nếu bạn đã cài đặt Go, hãy kiểm tra lại.
Tùy thuộc vào hệ điều hành của bạn, bạn có thể tìm thấy hướng dẫn cài đặt trên trang tài liệu của Go. Nếu bạn là người dùng macOS và sử dụng Brew, bạn có thể chạy lệnh trong Terminal:
brew install goTạo một thư mục mới cho dự án của bạn, di chuyển đến thư mục này và chạy lệnh sau, bạn có thể thay thế từ webscraper bằng bất kỳ tên module nào bạn muốn.
go mod init webscraperBây giờ bạn có thể thiết lập các script crawling của Go. Tạo tệp scraper.go và khởi tạo nó như sau:
package main
import (
"fmt"
)
func main() {
// scraping logic...
fmt.Println("Hello, World!")
}Dòng đầu tiên chứa tên của gói toàn cục. Sau đó có một số imports, tiếp theo là hàm main(). Đây là điểm đầu vào cho bất kỳ chương trình Go nào và sẽ chứa logic crawling web Golang. Sau đó, bạn có thể khởi động chương trình:
go run scraper.goĐiều này sẽ in:
Hello, World!Bây giờ bạn đã xây dựng một dự án Go cơ bản. Hãy đi sâu hơn vào việc xây dựng một web scraper bằng Golang!
Tiếp theo, hãy lấy ScrapeMe làm ví dụ về cách thực hiện scraping trang web với Go.
Để xây dựng một web scraper dễ dàng hơn, bạn nên sử dụng một trong những gói đã giới thiệu trước đó. Tuy nhiên, bạn cần xác định thư viện web scraping Golang nào phù hợp nhất với mục tiêu của bạn ngay từ đầu.
Để làm điều này, bạn cần:
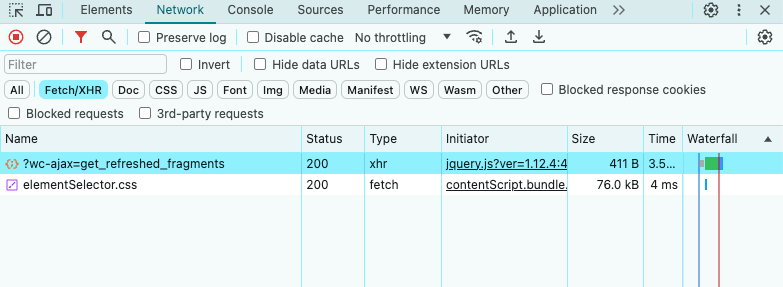
Như bạn có thể thấy ở trên, trang mục tiêu chỉ thực hiện một vài yêu cầu AJAX. Nếu bạn nghiên cứu từng yêu cầu XHR, bạn sẽ nhận thấy rằng chúng không trả về dữ liệu có ý nghĩa. Nói cách khác, máy chủ trả về một tài liệu HTML đã chứa tất cả dữ liệu. Đây là những gì thường xảy ra với các trang web có nội dung tĩnh.
Điều này có nghĩa là trang web mục tiêu không dựa vào JavaScript để truy xuất hoặc hiển thị dữ liệu một cách động. Do đó, bạn không cần thư viện có khả năng trình duyệt không đầu để truy xuất dữ liệu từ trang mục tiêu. Bạn vẫn có thể sử dụng Selenium, nhưng điều này chỉ làm tăng chi phí hiệu suất. Vì lý do này, bạn nên chọn một bộ phân tích cú pháp HTML đơn giản như Colly.
Bây giờ hãy cài đặt colly và các phụ thuộc của nó:
go get -u github.com/gocolly/collyLệnh này cũng sẽ cập nhật tệp go.mod với tất cả các phụ thuộc cần thiết và tạo tệp go.sum.
Colly là một gói Go cho phép bạn viết Web Scraper và crawler, được xây dựng trên gói net/HTTP của Go để giao tiếp mạng, và giúp bạn sử dụng
goquery, cung cấp cú pháp "giống jQuery" để định vị các phần tử HTML.
Trước khi bạn bắt đầu sử dụng nó, bạn cần tìm hiểu một số khái niệm chính của Colly:
Thực thể chính trong Colly là Collector, một đối tượng cho phép bạn thực hiện các yêu cầu HTTP và thực hiện web scraping với các callback sau:
OnRequest(): được gọi trước bất kỳ yêu cầu HTTP nào sử dụng Visit().OnError(): Được gọi nếu có lỗi xảy ra trong yêu cầu HTTP.OnResponse(): Được gọi sau khi nhận được phản hồi từ máy chủ.OnHTML(): Được gọi sau OnResponse() nếu máy chủ trả về một tài liệu HTML hợp lệ.OnScraped(): được gọi khi tất cả các cuộc gọi OnHTML() kết thúc.Mỗi hàm này nhận một callback làm tham số. Colly thực thi callback đầu vào khi sự kiện liên quan đến hàm được kích hoạt. Do đó, để xây dựng một data scraper trong Colly, bạn cần tuân theo cách tiếp cận dựa trên callback.
Bạn có thể sử dụng hàm NewCollector() để khởi tạo đối tượng Collector:
c := colly.NewCollector()Nhập Colly và tạo Collector bằng cách cập nhật scraper.go như sau:
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
// scraping logic...
}Sử dụng Colly để kết nối với trang mục tiêu bằng:
c.Visit("https://scrapeme.live/shop/")Trong văn phòng phía sau, hàm Visit() thực hiện một yêu cầu HTTP GET và truy xuất tài liệu HTML mục tiêu từ máy chủ. Cụ thể, nó kích hoạt sự kiện onRequest và bắt đầu vòng đời của hàm Colly. Lưu ý rằng Visit() phải được gọi sau khi đăng ký các callback khác của Colly.
Lưu ý rằng yêu cầu HTTP do Visit() thực hiện có thể thất bại. Khi điều này xảy ra, Colly sẽ kích hoạt sự kiện OnError. Nguyên nhân của sự cố này có thể là do máy chủ tạm thời không khả dụng hoặc URL không hợp lệ, trong khi các scraper web thường thất bại khi trang web mục tiêu áp dụng các biện pháp chống robot. Ví dụ, các kỹ thuật này thường lọc ra các yêu cầu không có tiêu đề HTTP User-Agent hợp lệ.
Điều gì gây ra điều đó?
Thông thường, Colly đặt một User-Agent placeholder không khớp với proxy được sử dụng bởi các trình duyệt phổ biến. Điều này khiến các yêu cầu của Colly dễ dàng bị phát hiện bởi các công nghệ chống scraping. Để tránh bị chặn, hãy chỉ định một tiêu đề User-Agent hợp lệ trong Colly, như được chỉ ra dưới đây:
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"Tìm kiếm một giải pháp hiệu quả hơn?
Nstbrowser có một API crawler web hoàn chỉnh để xử lý tất cả các chướng ngại vật chống bot cho bạn.
Hãy thử ngay miễn phí!
Bạn có suy nghĩ hoặc câu hỏi nào về việc thu thập dữ liệu web và Browseless không?
Hãy đến xem những gì các nhà phát triển khác đang chia sẻ trên Discord và Telegram!
Bất kỳ lệnh gọi Visit() nào giờ đây sẽ thực hiện một yêu cầu với header HTTP đó.
File scraper.go của bạn bây giờ sẽ trông như sau:
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// creating a new Colly instance
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
// visiting the target page
c.Visit("https://scrapeme.live/shop/")
// scraping logic...
}Bây giờ chúng ta cần duyệt và phân tích DOM của trang web mục tiêu để xác định dữ liệu cần lấy. Kết quả là, chúng ta có thể áp dụng một chiến lược truy xuất dữ liệu hiệu quả.
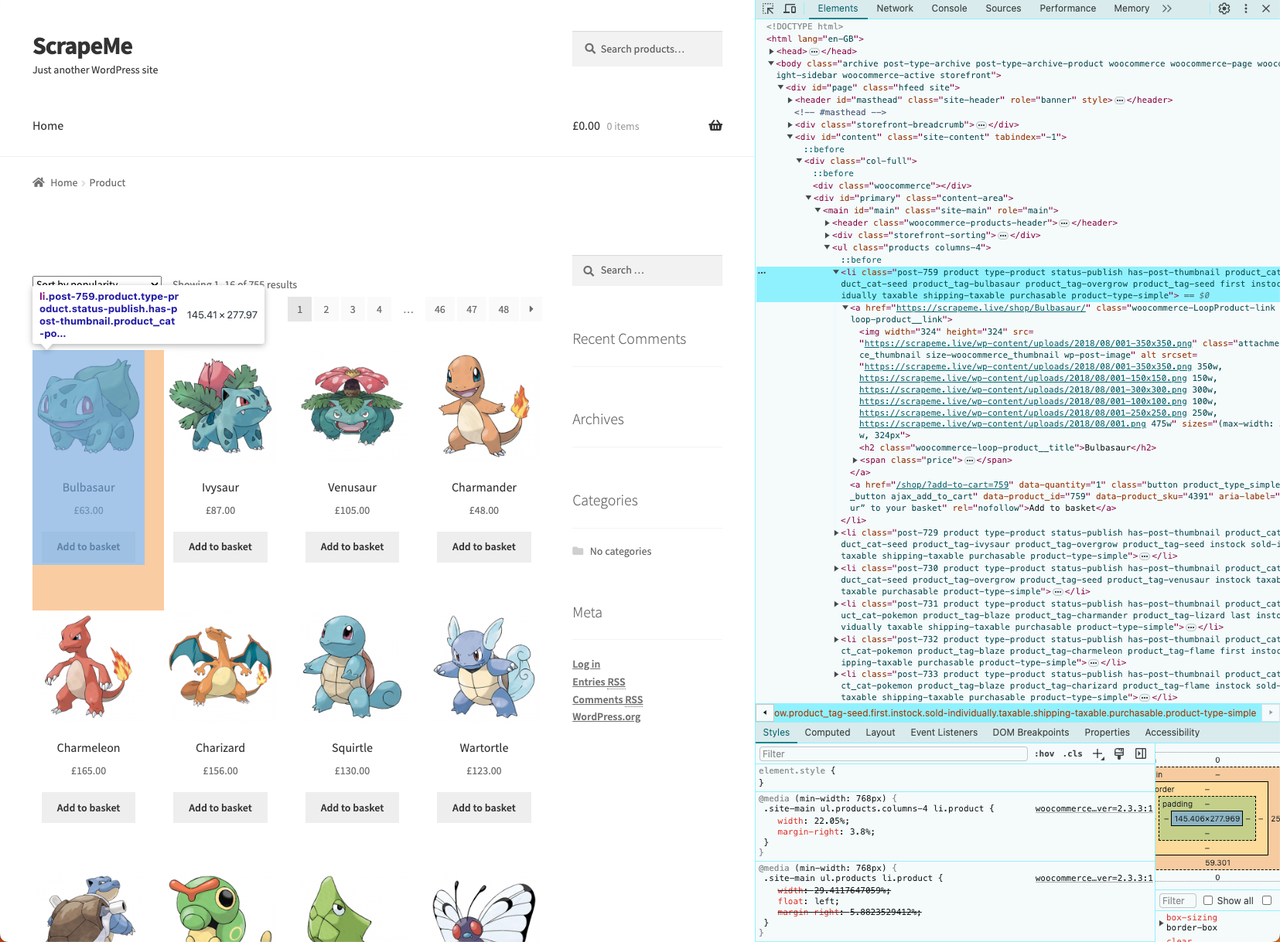
Chúng ta đã tìm ra cấu trúc HTML của nó, trước khi bắt đầu crawling, bạn cần một cấu trúc dữ liệu để lưu trữ dữ liệu đã lấy.
PokemonProduct như sau:// defining a data structure to store the scraped data
type PokemonProduct struct {
url, image, name, price string
}Sau đó, khởi tạo một slice của PokemonProduct sẽ chứa dữ liệu đã lấy:
// initializing the slice of structs that will contain the scraped data
var pokemonProducts []PokemonProductTrong Go, slices cung cấp một cách hiệu quả để làm việc với các chuỗi dữ liệu có kiểu. Bạn có thể nghĩ về chúng như các danh sách.
// iterating over the list of HTML product elements
c.OnHTML("li.product", func(e *colly.HTMLElement) {
// initializing a new PokemonProduct instance
pokemonProduct := PokemonProduct{}
// scraping the data of interest
pokemonProduct.url = e.ChildAttr("a", "href")
pokemonProduct.image = e.ChildAttr("img", "src")
pokemonProduct.name = e.ChildText("h2")
pokemonProduct.price = e.ChildText(".price")
// adding the product instance with scraped data to the list of products
pokemonProducts = append(pokemonProducts, pokemonProduct)
})Giao diện HTMLElement cung cấp các phương thức ChildAttr() và ChildText(). Chúng cho phép bạn trích xuất văn bản của giá trị thuộc tính tương ứng từ đối tượng con được xác định bởi CSS selector. Bằng cách thiết lập hai hàm đơn giản, bạn đã triển khai toàn bộ logic trích xuất dữ liệu.
append() để thêm một phần tử mới vào slice của các phần tử đã lấy.Logic để xuất dữ liệu đã lấy ra một file CSV bằng Go như sau:
// opening the CSV file
file, err := os.Create("products.csv")
if err != nil {
log.Fatalln("Failed to create output CSV file", err)
}
defer file.Close()
// initializing a file writer
writer := csv.NewWriter(file)
// defining the CSV headers
headers := []string{
"url",
"image",
"name",
"price",
}
// writing the column headers
writer.Write(headers)
// adding each Pokemon product to the CSV output file
for _, pokemonProduct := range pokemonProducts {
// converting a PokemonProduct to an array of strings
record := []string{
pokemonProduct.url,
pokemonProduct.image,
pokemonProduct.name,
pokemonProduct.price,
}
// writing a new CSV record
writer.Write(record)
}
defer writer.Flush()Để đoạn mã này hoạt động, đảm bảo bạn có các import sau:
import (
"encoding/csv"
"log"
"os"
// ...
)Dưới đây là mã hoàn chỉnh cho scraper.go:
package main
import (
"encoding/csv"
"log"
"os"
"github.com/gocolly/colly"
)
// initializing a data structure to keep the scraped data
type PokemonProduct struct {
url, image, name, price string
}
func main() {
// initializing the slice of structs to store the data to scrape
var pokemonProducts []PokemonProduct
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
// creating a new Colly instance
c := colly.NewCollector()
// visiting the target page
c.Visit("https://scrapeme.live/shop/")
// scraping logic
c.OnHTML("li.product", func(e *colly.HTMLElement) {
pokemonProduct := PokemonProduct{}
pokemonProduct.url = e.ChildAttr("a", "href")
pokemonProduct.image = e.ChildAttr("img", "src")
pokemonProduct.name = e.ChildText("h2")
pokemonProduct.price = e.ChildText(".price")
pokemonProducts = append(pokemonProducts, pokemonProduct)
})
// opening the CSV file
file, err := os.Create("products.csv")
if err != nil {
log.Fatalln("Failed to create output CSV file", err)
}
defer file.Close()
// initializing a file writer
writer := csv.NewWriter(file)
// writing the CSV headers
headers := []string{
"url",
"image",
"name",
"price",
}
writer.Write(headers)
// writing each Pokemon product as a CSV row
for _, pokemonProduct := range pokemonProducts {
// converting a PokemonProduct to an array of strings
record := []string{
pokemonProduct.url,
pokemonProduct.image,
pokemonProduct.name,
pokemonProduct.price,
}
// adding a CSV record to the output file
writer.Write(record)
}
defer writer.Flush()
}Chạy trình scraper dữ liệu Go của bạn với:
go run scraper.goSau đó, bạn sẽ tìm thấy một file products.csv trong thư mục gốc của dự án của bạn. Mở nó và nó sẽ chứa:
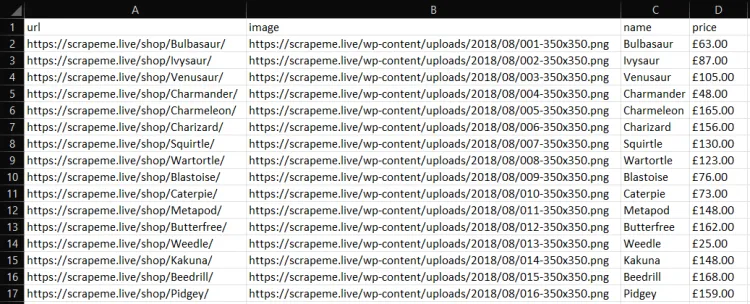
Trong hướng dẫn này,
Như bạn có thể thấy từ hướng dẫn này, crawling web với Go có thể được thực hiện với vài dòng mã sạch và hiệu quả.
Tuy nhiên, cũng quan trọng để nhận ra rằng việc trích xuất dữ liệu từ Internet không phải lúc nào cũng dễ dàng. Có nhiều thử thách bạn có thể gặp phải trong quá trình này. Nhiều trang web đã áp dụng các giải pháp chống scraping và chống bot có thể phát hiện và chặn các script crawling của Go.
Thực hành tốt nhất là sử dụng một API crawling web, chẳng hạn như Nstbrowser, một giải pháp hoàn toàn miễn phí cho phép bạn vượt qua tất cả các hệ thống chống bot chỉ với một lệnh gọi API, như một giải pháp cho những rắc rối khi bị chặn trong khi thực hiện các nhiệm vụ crawling của bạn.





