
Web Scraping
Веб-скрапинг с помощью Python и Selenium Учебник
Как скреативить веб-сайт с помощью Python и Selenium? Всего 3 шага, чтобы завершить задачу веб-скрепинга.
Jun 05, 2024Luke Ulyanov
Если ваша сегодняшняя работа заключается в сборе информации о ценах с страниц конкурентов на сайтах, как бы вы это осуществили? Копирование и вставка? Вручную ввод данных? На самом деле нет! Эти методы абсолютно тратят ваше большинство времени и могут привести к ошибкам.
Необходимо отметить, что Python стал одним из самых популярных языков программирования для сбора данных. В чем его привлекательность?
Давайте начнем наслаждаться миром веб-скрапинга с помощью Python!
Что такое веб-скрапинг?
Веб-скрапинг - это процесс извлечения данных с веб-сайтов. Это можно сделать вручную, но лучше использовать автоматизированные инструменты или скрипты для сбора больших объемов данных эффективно и точно. Копирование и вставка с веб-страниц также фактически является веб-скрапингом.
Почему Python для веб-скрапинга?
Python считается одним из лучших выборов для веб-скрапинга по нескольким причинам:
- Легкость использования: Благодаря ясности и интуитивной понятности Python доступен даже для начинающих.
- Мощные библиотеки: Python имеет богатую систему библиотек, таких как Beautiful Soup, Scrapy и Selenium, которые упрощают задачи веб-скрапинга.
- Поддержка сообщества: У Python большое и активное сообщество. Оно предоставляет обильные ресурсы и поддержку для устранения неполадок и обучения.
Java также является важным языком для веб-скрапинга. Вы можете узнать о трех замечательных методах в учебнике по веб-скрапингу на Java.
План для веб-скрапинга на Python
Вы готовы начать свое путешествие в веб-скрапинг с помощью Python? Прежде чем определить основные шаги, убедитесь, что вы знаете, чего ожидать и как действовать.
Основные шаги для овладения веб-скрапингом
Веб-скрапинг включает в себя систематический процесс, включающий четыре основных задачи:
1. Изучение целевых страниц
Прежде чем извлекать данные, вам нужно понять макет веб-сайта и структуру данных:
- Исследовать сайт
- Анализировать HTML-элементы
- Определить ключевые данные
2. Получение HTML-содержимого
Для скрапинга веб-сайта сначала необходимо получить доступ к его HTML-содержимому:
- Использовать библиотеки HTTP-клиента
- Отправлять HTTP-запросы GET
- Проверять получение HTML
3. Извлечение данных из HTML
После того как у вас есть HTML, следующим шагом будет извлечение нужной информации:
- Анализировать HTML-содержимое
- Выбирать соответствующие данные
- Написать логику извлечения
- Обрабатывать несколько страниц
4. Хранение извлеченных данных
После извлечения данных важно сохранить их в доступном формате:
- Преобразовывать форматы данных
- Экспортировать данные
Совет: Веб-сайты динамичны, поэтому регулярно пересматривайте и обновляйте свой процесс скрапинга, чтобы данные были актуальными.
Сценарии использования веб-скрапинга
Веб-скрапинг на Python может применяться в различных ситуациях, включая:
- Анализ конкурентов: Мониторинг продуктов, услуг и маркетинговых стратегий конкурентов путем сбора данных с их сайтов.
- Сравнение цен: Сбор и сравнение цен с различных электронных платформ для поиска лучших предложений.
- Аналитика социальных медиа: Извлечение данных из социальных медиа-платформ для анализа популярности и вовлеченности конкретных хэштегов, ключевых слов или влиятелей.
- Генерация лидов: Извлечение контактных данных с веб-сайтов для создания целевых маркетинговых списков с учетом юридических аспектов.
- Анализ настроений: Сбор новостей и сообщений в социальных медиа для отслеживания общественного мнения о теме или бренде.
Преодоление вызовов веб-скрапинга
Веб-скрапинг имеет свой набор вызовов:
- Разнообразные веб-структуры: Каждый веб-сайт имеет уникальный макет, требующий индивидуальных скриптов для скрапинга.
- Изменение веб-страниц: Веб-сайты могут изменять свою структуру без предупреждения, что требует корректировки вашей логики скрапинга.
- Проблемы масштабирования: По мере увеличения объема данных убедитесь, что ваш скрапер остается эффективным с использованием распределенных систем, параллельного скрапинга или оптимизации кода.
Кроме того, веб-сайты используют меры по защите от ботов, такие как блокировка IP-адресов, задачи JavaScript и CAPTCHA. Их можно обойти с помощью таких методов, как поворот прокси и безголовые браузеры.
Застряли в проблемах веб-краулинга?
Обойдите обнаружение анти-бота, чтобы упростить веб-скрапинг и автоматизацию
Попробуйте бесплатно Nstbrowser!
Есть ли у вас хорошие идеи или вопросы о веб-скрейпинге и Browserless?
Посмотрите чем делятся другие разработчики в Discord и Telegram!
Альтернативы веб-скрапингу
Хотя веб-скрапинг универсален, существуют альтернативы:
- API: Некоторые сайты предлагают API для запроса и получения данных. API стабильны и обычно не защищены от скрапинга, но они предлагают ограниченное количество данных, и не все сайты их предоставляют.
- Готовые наборы данных: Покупка наборов данных в Интернете - это еще один вариант, хотя они не всегда соответствуют вашим конкретным потребностям.
Несмотря на эти альтернативы, веб-скрапинг остается популярным выбором благодаря его гибкости и обширным возможностям доступа к данным.
Начните свое путешествие в веб-скрапинге с помощью Python и разблокируйте огромный потенциал онлайн-данных!
Как делать веб-скрапинг с помощью Python и Selenium?
Шаг 1. Подготовка
В самом начале мы должны установить нашу оболочку:
Shell
pip install selenium requests jsonПосле завершения установки, создайте новый файл scraping.py и подключите только что установленную библиотеку в файле:
Python
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import ByШаг 2. Подключение к Nstbrowser
Чтобы получить точную демонстрацию, мы будем использовать Nstbrowser, абсолютно бесплатный браузер с анти-детектом в качестве инструмента для завершения нашей задачи:
Python
def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'xxxxxxx' # ваш api-ключ
config = {
'once': True,
'headless': False, # без головы
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # требуется
'name': 'custom browser',
'platform': 'windows', # поддержка: windows, mac, linux
'kernel': 'chromium', # поддержка: chromium
'kernelMilestone': '120',
'hardwareConcurrency': 4, # поддержка: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # поддержка: 2, 4, 8
'proxy': '', # формат ввода: schema://user:password@host:port например: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # требуется
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
print('devtool url: ' + url)
port = get_debugger_port(url)
debugger_address = f'{host}:{port}'
print("debugger_address: " + debugger_address)После подключения к Nstbrowser, мы подключаемся к Selenium через адрес отладчика, который вернул нам Nstbrowser:
Python
def exec_selenium(debugger_address: str):
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", debugger_address)
# Замените на соответствующий путь к WebDriver.
chrome_driver_path = r'./chromedriver' # ваш путь к драйверу Chrome
service = ChromeService(executable_path=chrome_driver_path)
driver = webdriver.Chrome(service=service, options=options)Шаг 3. Скрапинг веба
С этого момента мы успешно запустили Nstbrowser через Selenium. Начнем сканирование!
- Посетите наш целевой веб-сайт, например: https://www.imdb.com/chart/top
Python
driver.get("https://www.imdb.com/chart/top")- Запуск кода, который мы только что написали:
Python
python scraping.pyКак вы можете видеть, мы успешно запустили Nstbrowser и посетили наш целевой сайт.
- Откройте Devtool, чтобы увидеть конкретную информацию, которую мы хотим спарсить. Да, очевидно, это элементы с той же структурой DOM.
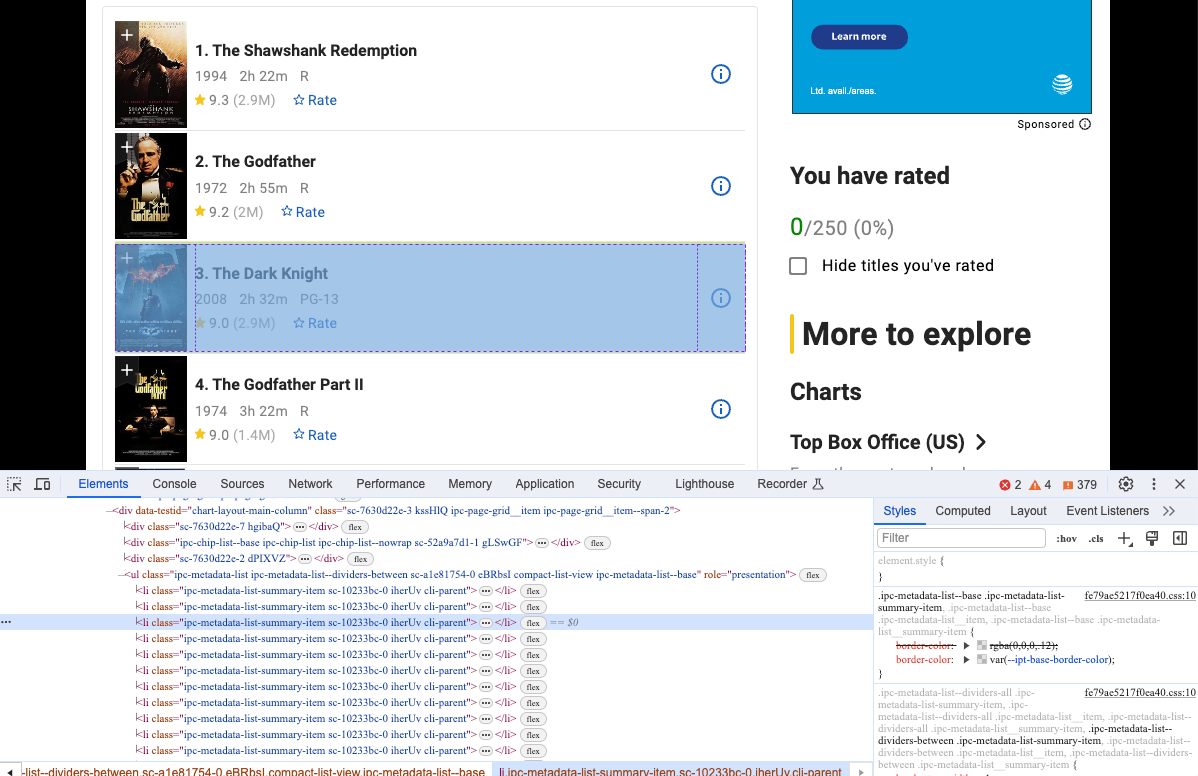
Мы можем использовать Selenium, чтобы получить эту структуру DOM и проанализировать их содержимое:
Python
movies = driver.find_elements(By.CSS_SELECTOR, "li.cli-parent")
for row in movies:
title = row.find_element(By.CLASS_NAME, 'ipc-title-link-wrapper') # получить заголовок
year = row.find_element(By.CSS_SELECTOR, 'span.cli-title-metadata-item') # получить год создания
rate = row.find_element(By.CLASS_NAME, 'ipc-rating-star') # получить оценку
move_item = {
"title": title.text,
"year": year.text,
"rate": rate.text
}
print(move_item)- Повторно запустите наш код, и вы увидите, что терминал уже вывел информацию, которую мы хотим получить.
Конечно, вывод этой информации в терминале не является нашей целью. Далее нам нужно сохранить собранные данные.
Мы используем библиотеку JSON для сохранения извлеченных данных в JSON-файл:
Python
movies = driver.find_elements(By.CSS_SELECTOR, "li.cli-parent")
movies_info = []
for row in movies:
title = row.find_element(By.CLASS_NAME, 'ipc-title-link-wrapper')
year = row.find_element(By.CSS_SELECTOR, 'span.cli-title-metadata-item')
rate = row.find_element(By.CLASS_NAME, 'ipc-rating-star')
move_item = {
"title": title.text,
"year": year.text,
"rate": rate.text
}
movies_info.append(move_item)
# создаем JSON-файл
json_file = open("movies.json", "w")
# конвертируем movies_info в JSON
json.dump(movies_info, json_file)
# освобождаем ресурсы файла
json_file.close()- Запустите код и откройте файл. Вы увидите, что рядом с scraping.py появился дополнительный файл movies.json, что означает, что мы успешно использовали Selenium для подключения к Nstbrowser и сбора данных для нашего целевого сайта!
Заключение
Как делать веб-скрапинг с помощью Python и Selenium? Это подробное руководство охватывает все, что вас интересует. Чтобы иметь всестороннее понимание, мы говорили о концепции и преимуществах Python для веб-скрапинга. Затем мы переходим к конкретным шагам, взяв в качестве примера бесплатный браузер с анти-детектом - Nstbrowser. Я уверен, что вы многое узнали о веб-скрапинге на Python сейчас! Пора начинать работу над вашим проектом и собирать данные.
Больше





