
Web Scraping
使用 Python 进行网络抓取 | 2024 完整指南
如何使用 Python 爬取网站?困难吗?在本指南中,您将获得有关 python 网页爬取的具体信息和代码。
May 13, 2024
如果您知道如何提取数据,互联网就是一个巨大的信息来源。因此,近年来网络抓取的需求呈指数级增长,Python 成为该任务最流行的编程语言。
在本教程中,您将:
- 学习并运行您的第一个 Python 程序
- 了解网站 URL
- 了解如何使用 Devtool 对网页进行深入分析。
- 使用 Python 中的 Beautiful Soup 和 Requests 了解网页抓取的基础知识。
- 了解如何使用 Beautiful Soup 从各个节点、列表、表格等中提取数据。
- 了解如何将抓取的内容导出为各种格式,例如 JSON 和 CSV。
让我们深入使用 Python 进行网络抓取的世界!
Python 中的网页抓取是什么?
网络抓取是从网络检索数据的过程。甚至从页面复制和粘贴内容也是一种抓取形式!然而,该术语通常指的是由软件自动化的任务,本质上是访问网站并从页面中提取所需数据的脚本(也称为机器人、蜘蛛或爬虫) 。在我们的示例中,我们将使用 Python。
值得注意的是,许多网站出于各种原因实施了反抓取技术。但别担心,我们稍后将向您展示如何绕过它们!
了解目标网站!
你准备好开始了吗?您将构建一个真正的蜘蛛来从ScrapeMe检索数据,ScrapeMe 是一个为学习网络抓取而构建的 Pokémon 电子商务网站。
您将看到的只是一个示例,旨在了解 Web 抓取在 Python 中的工作原理。但是,请记住,您可以将在这里学到的知识应用到任何其他网站。该过程可能更复杂,但要遵循的关键概念保持不变。
在开始编写代码之前,您需要满足一些先决条件:
设置您的环境
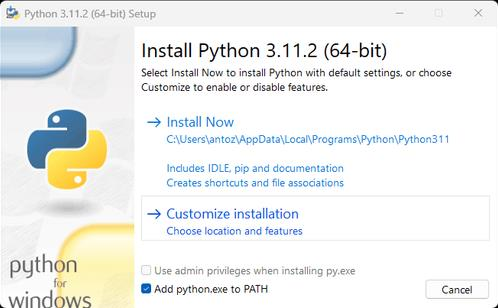
要使用 Python 构建数据抓取器,您需要下载并安装以下工具:
-
Python 3.11+:本教程指的是Python 3.11.2,即撰写本文时的最新版本。
-
IDE:任何支持Python的IDE都可以使用。
-
注意:如果您是 Windows 用户,请不要忘记在安装向导过程中选择
Add python.exe to PATH。这使得 Windows 能够在终端中使用python和pip命令。请注意,Python 3.4 或更高版本默认包含pip,因此您不需要手动安装它。
现在,您已经获得了使用 Python 构建第一个网络抓取工具所需的一切。
我们继续吧!
初始化Python项目
创建一个文件夹并在其中创建一个名为 main.py 的文件。在 IDE 中打开此文件。
在文件中写入以下代码:
python
def print_hello(name):
print(f"Hello, {name}!")
if __name__ == "__main__":
print_hello('world')在终端中执行以下命令进行验证:
bash
python3 main.py如果你在终端中看到以下输出,则说明你已经成功运行Python:
Hello, world!分析目标网站
您可能渴望立即开始编码,但这不是最好的方法。首先,您需要花一些时间了解您的目标网站。这可能听起来很乏味或没有必要,但这是研究网站结构并找出如何从中获取数据的唯一方法。每个抓取项目都是这样开始的。
浏览网站
全面的浏览网站(尝试搜索功能),可以单击一些按钮,然后观察网站的响应和页面结构。
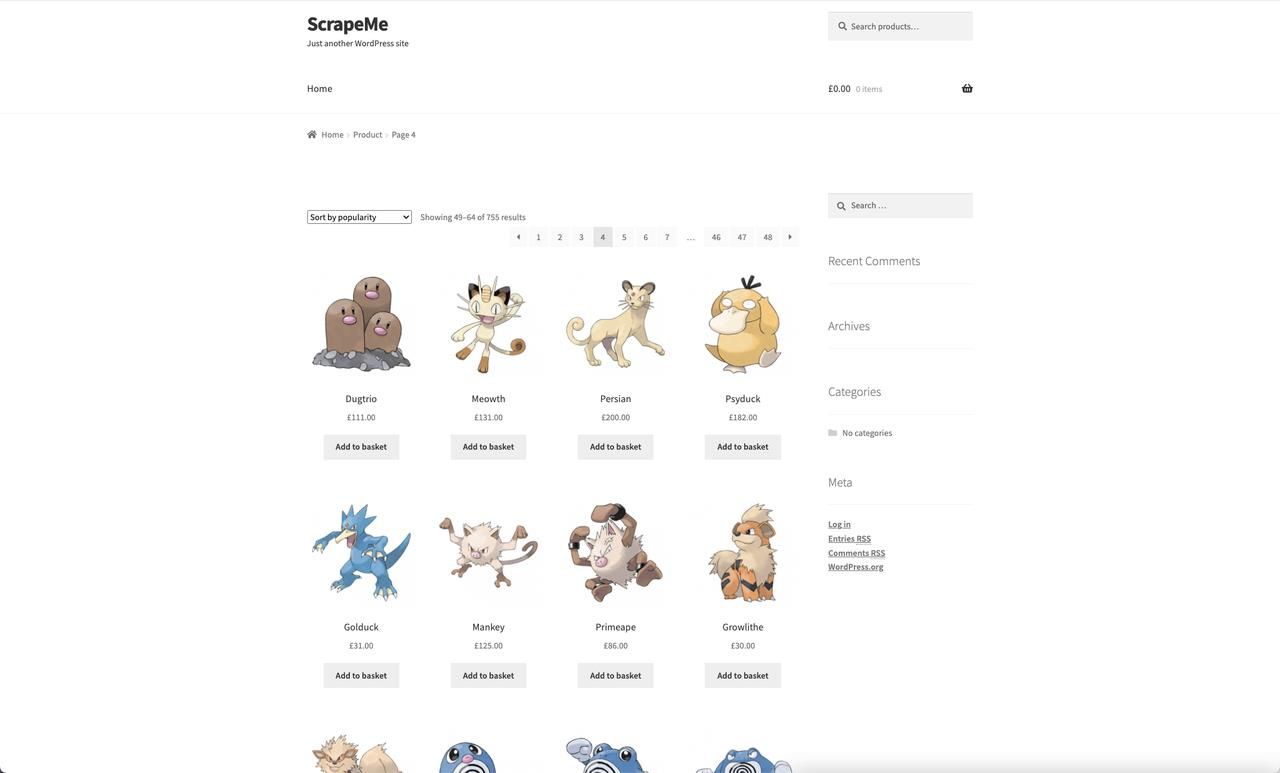
Web 服务器根据请求的 URL 返回 HTML 文档,每个文档与特定页面相关联。考虑产品列表第四页的 URL:
https://scrapeme.live/shop/page/4/
您可以将其中任何一个分解为两个主要部分:
- 基本 URL:网站商店部分的路径。在这里
https://scrapeme.live/shop/page/4/。 - 具体页面位置:具体产品的路径。 URL 可能以 , 结尾
.html,.php或者根本没有扩展名。
网站上提供的所有产品都将具有相同的基本 URL。每个页面的不同之处在于其后半部分,其中包含一个字符串,指定服务器应返回哪个产品页面。通常,相同类型页面的 URL 共享相似的格式。
此外,URL 还可以包含附加信息:
- 路径参数:这些用于捕获RESTful方法中的特定值(例如https://scrapeme.live/shop/page/4/中的路径参数是4)。
- 查询参数:这些参数添加在 URL 末尾的问号 (
?) 后面。它们通常对执行搜索时发送到服务器的过滤器值进行编码(例如, inhttps://www.example.com/search?search=blabla&sort=newest中search=blabla和sort=newest是查询参数)。
需要注意的是,任何查询参数字符串都包含:
?: 标记开始。key=value由&:分隔的参数对,其中key是参数的名称,value代表其值。查询字符串包含由字符分隔的键值对中的参数&。
换句话说,URL 不仅仅是 HTML 文档的简单位置字符串。它们可以包含参数信息,服务器使用这些信息来运行查询并用特定数据填充页面。
使用 DevTools 检查网站
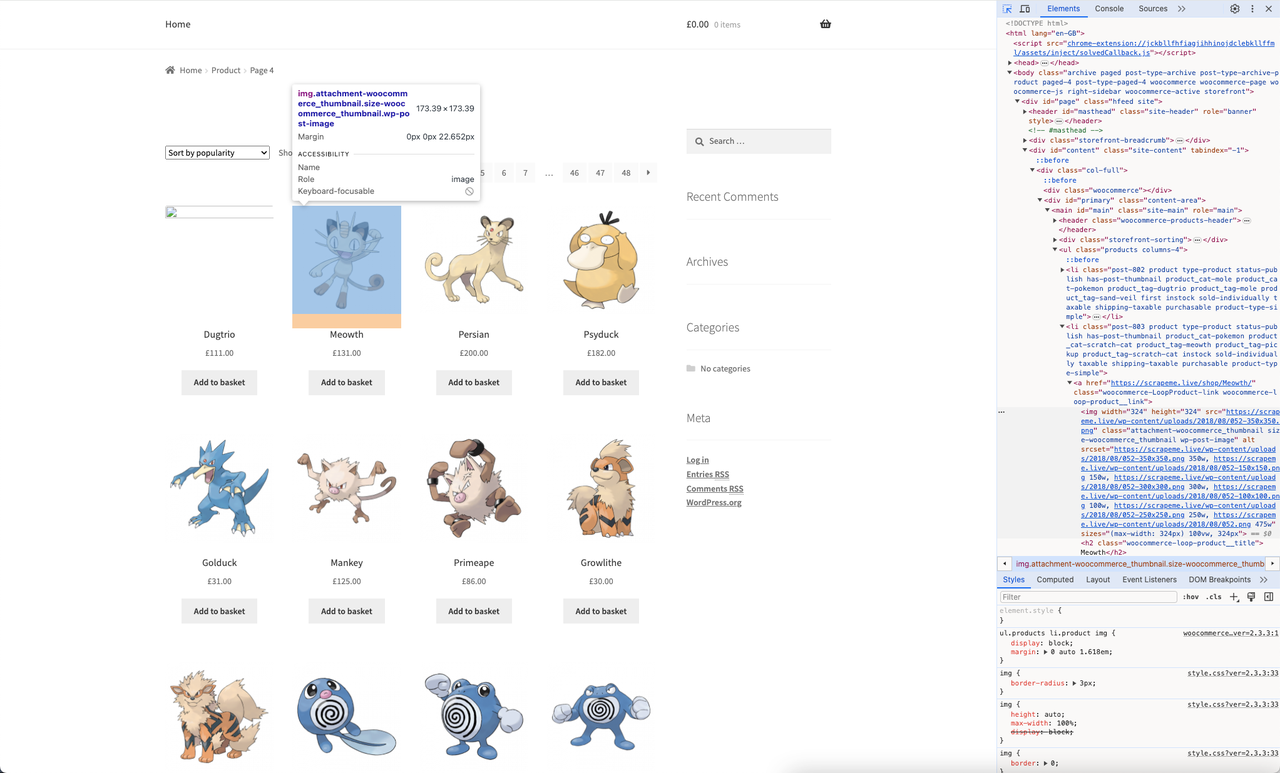
您现在已经熟悉该网站了。下一步是深入研究页面的 HTML 代码,研究其结构和内容,以了解如何从中提取数据。
所有现代浏览器都附带一组高级开发工具,其中大多数提供几乎相同的功能。这些工具允许您探索网页的 HTML 代码并使用它
在本篇 Python 网页抓取教程中,您将看到 Chorme开发工具的实际应用:
右键单击 HTML 元素并选择Inspect打开 DevTools 窗口。如果网站禁用了右键菜单,请执行以下操作:
- 在macOS上:从菜单栏中选择“视图 > 开发人员 > 开发人员工具”。
- 在Windows 和 Linux上:单击右上角的“ ⋮ ”菜单按钮,然后选择“更多工具 > 开发者工具”。
它们允许您检查网页的文档对象模型 (DOM)的结构。反过来,这可以帮助您更深入地理解源代码。在 DevTools 部分中,导航到Elements选项卡以访问 DOM。
网页抓取面临的挑战
然而,在当今先进的在线环境中,网络抓取面临着众多挑战。网站经常
- 施加访问限制和监控措施,阻碍爬取过程和数据检索
- 实施验证码等人工验证机制,手动处理可能非常耗时且费力。
Nstbrowser被视为应对这些挑战的解决方案之一。有了 Nstbrowser,您可以毫不费力地克服这些障碍。它采用浏览器模拟技术来模仿人类行为,降低触发自动保护机制的风险。用户代理轮换可确保您的抓取活动不被检测到。
如何使用Python爬取网站?
现在,我们所有的准备工作都完成了!最详细的步骤如下:
步骤 1. 下载 HTML 页面
准备好启动你的 Python,因为你已经准备好编写一些代码了。
假设您想从以下位置抓取一些数据:
typescript
https://scrapeme.live/shop/要检索目标页面的 HTML 代码,您首先需要下载与页面 URL 关联的 HTML 文档。为此,您可以使用 Python requests 库。
要安装 requests 库,请使用以下命令:
shell
pip install requests创建一个新scraper.py文件并将以下代码添加到该文件中:
python
import requests
# download the HTML document with an HTTP GET request
response = requests.get("https://scrapeme.live/shop/")
# print the HTML content of the page
print(response.text)此代码导入该requests库,然后使用它向目标页面的 URL 发出 GET 请求。它返回响应内容,其中包括 HTML 文档。
要打印text响应的属性,您将能够看到目标页面代码的结构。
html
<!doctype html>
<html lang="en-GB">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=2.0">
<link rel="profile" href="http://gmpg.org/xfn/11">
<link rel="pingback" href="https://scrapeme.live/xmlrpc.php">
<title>Products – ScrapeMe</title>
<!-- rest of the page omitted for brevity... -->常见错误:忘记处理异常。
GET 请求可能会因多种原因而失败,例如服务器暂时不可用、URL 不正确或您的 IP 被阻止。因此,按以下方式处理错误非常重要:
python
import requests
# download the HTML document with an HTTP GET request
response = requests.get("https://scrapeme.live/shop/")
if response.ok:
# scraping logic here
else:
# log the error response
# in case of 4xx or 5xx
print(response)通过使用错误处理技术,如果请求期间出现错误,您的脚本将不会崩溃。仅当响应状态代码在2xx范围内时才会继续
步骤 2. 解析 HTML 内容
在上一步中,您已从服务器检索了 HTML 文档。如果你看它,你会看到一长串代码,理解它的唯一方法是通过 HTML 解析提取所需的数据。
Beautiful Soup是一个用于解析 XML 和 HTML 内容的 Python 库,它公开了一个用于探索 HTML 代码的 API。换句话说,它允许您选择 HTML 元素并轻松地从中提取数据。
要安装该库,请在终端中键入并执行以下命令
shell
pip install beautifulsoup4首先使用 requests 请求页面,然后用于解析检索到的内容:
python
import requests
from bs4 import BeautifulSoup
# download the HTML document with an HTTP GET request
response = requests.get("https://scrapeme.live/shop/")
if response.ok:
# scraping logic here
soup = BeautifulSoup(response.text, 'html.parser')
else:
# log the error response
# in case of 4xx or 5xx
print(response)值得注意的是,网站包含各种格式的数据。单个元素、列表和表格只是几个示例。为了让你的Python scraper发挥作用,你需要知道如何在很多场景下使用Beautiful Soup。让我们看看如何应对最常见的挑战!
步骤 3. 从单个元素中提取数据
Beautiful Soup 提供了多种从 DOM 中选择 HTML 元素的方法,而id属性是选择单个元素最有效的方法。顾名思义,id唯一标识页面上的 HTML 节点。
要找到搜索框,请右键单击并打开 Devtools 以查看其 id:
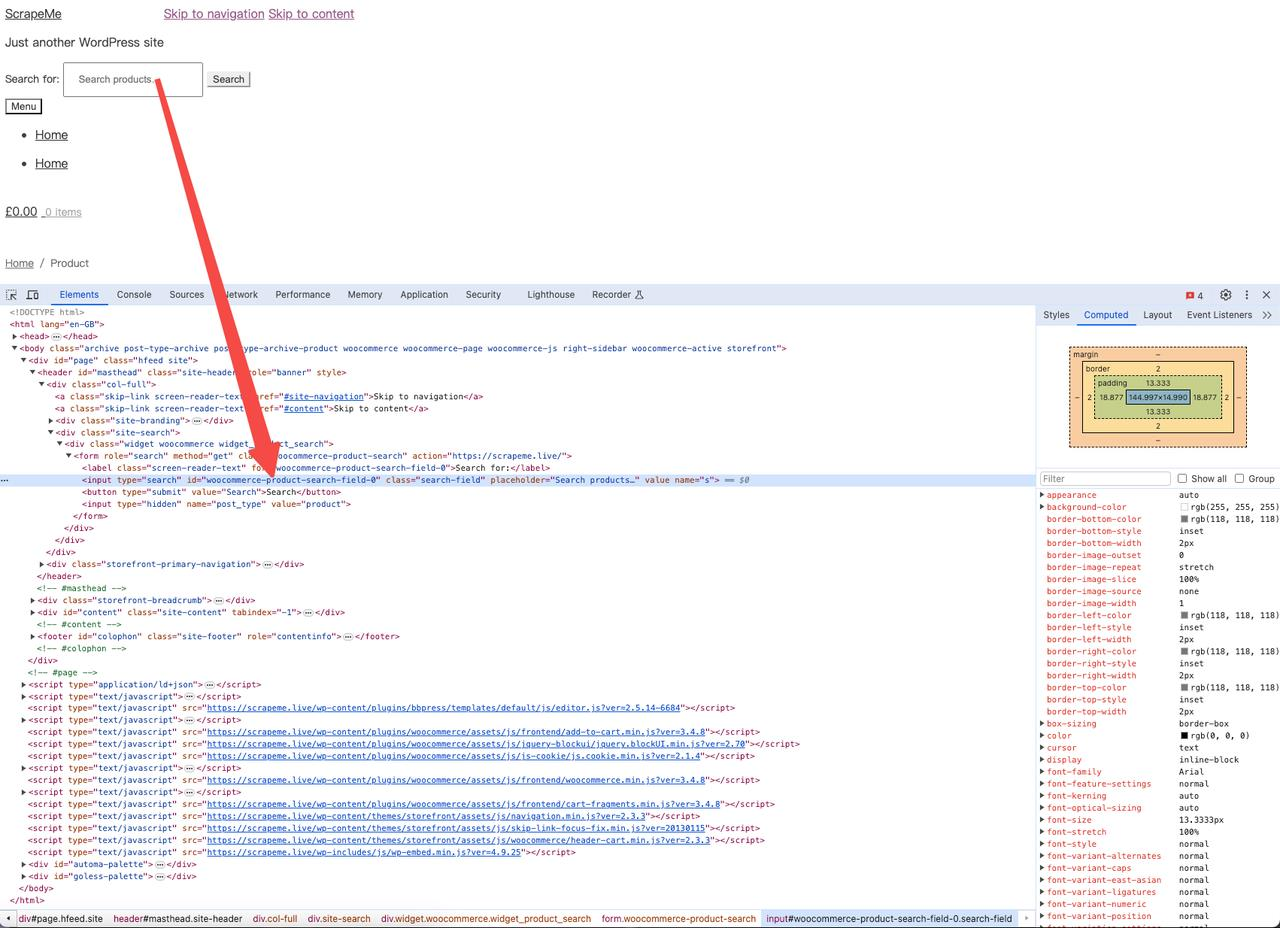
如您所见,该<input>元素具有以下 id:
python
woocommerce-product-search-field-0您可以使用此信息来选择产品搜索元素:
python
product_search_element = soup.find(id="woocommerce-product-search-field-0")该find()函数允许您从 DOM 中提取单个 HTML 元素。
请注意,这id是一个可选属性。这就是为什么有其他方法来选择元素:
按标签:find()不带任何参数使用:
python
h1_element = soup.find("h1")按类目:添加class_参数:
python
search_input_element = soup.find(class_="search_field")按属性:使用attrs参数:
python
search_input_element = soup.find(attrs={"name": "s"})步骤 4. 获取元素列表
现在您已经学会了如何导航页面并从元素中提取信息,让我们真正深入研究网络抓取!
网页通常包含元素列表,例如电子商务商店中的产品列表。从它们中检索数据可能非常耗时,但这就是 Python 的 Beautiful Soup 网络抓取发挥作用的地方!
Pokemon 中的产品列表包含在<li>以下元素中:
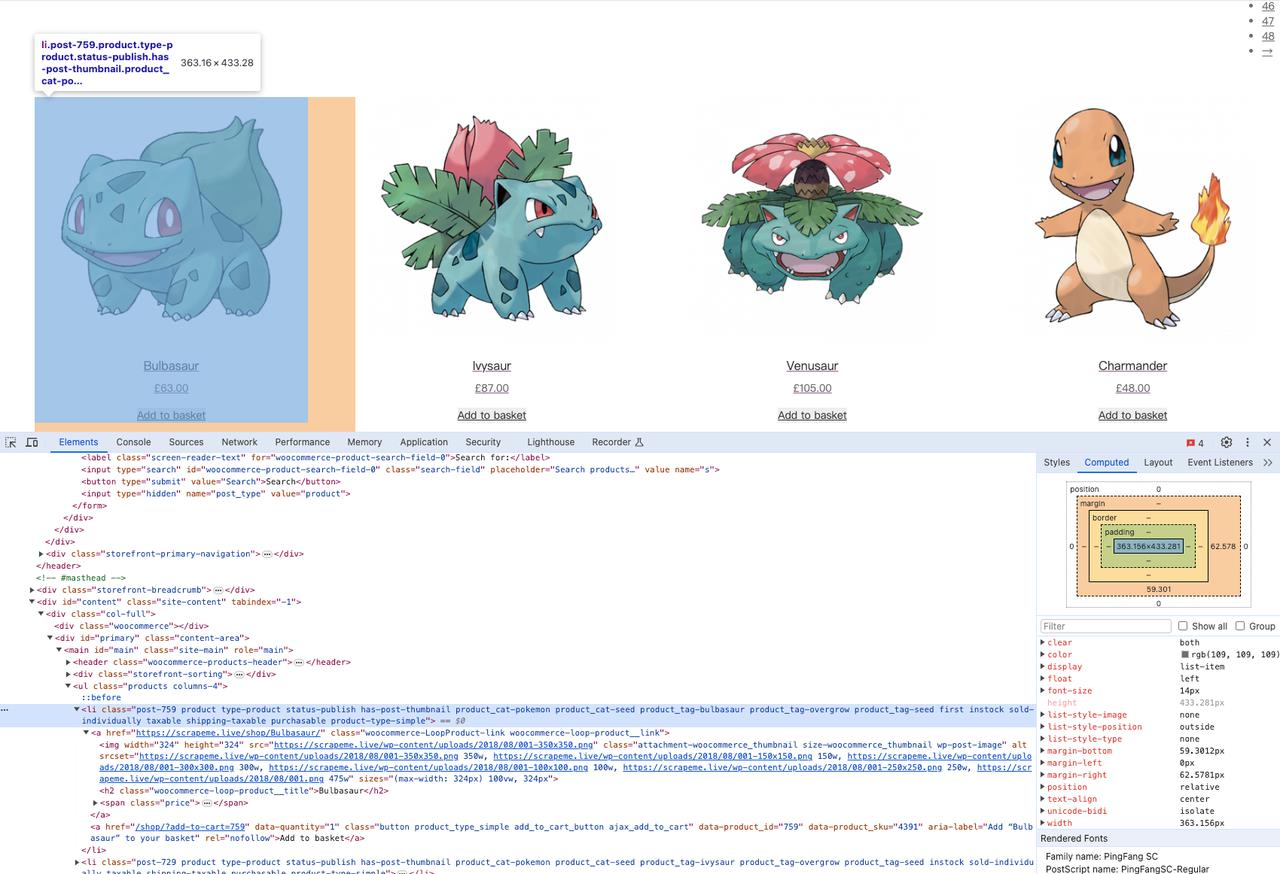
你会得到:
python
product_elements = soup.select("li.product")如下迭代其所有产品数据:
python
for product_element in product_elements:
product_name = product_element.find("h2").get_text()
product_url = product_element.find("a")["href"]
product_image = product_element.find("img")["src"]
product_price = product_element.select_one(".amount").get_text()处理元素列表时,建议将抓取的数据存储在字典列表中。在Python中,字典是键值对的无序集合,您可以按如下方式使用它:
python
# the list of dictionaries containing the
# scrape data
pokemon_products = []
for product_element in product_elements:
product_name = product_element.find("h2").get_text()
product_url = product_element.find("a")["href"]
product_image = product_element.find("img")["src"]
product_price = product_element.select_one(".amount").get_text()
# define a dictionary with the scraped data
new_pokemon_product = {
"name": product_name,
"url": product_url,
"image": product_image,
"price": product_price
}
# add the new product dictionary to the list
pokemon_products.append(new_pokemon_product)
# print the list of dictionaries
print(pokemon_products)您现在有一个名为的列表pokemon_products,其中包含从页面上每个单独产品中抓取的所有信息。
干得漂亮!现在,您已拥有使用 Python 中的 Beautiful Soup 构建数据抓取器所需的所有构建块。但让我们继续前进;教程还没结束!
步骤5.导出抓取的数据
检索网页内容通常是较大过程的第一步。下一步是将抓取的信息用于不同的需求和目的。因此,将其转换为易于阅读和探索的格式至关重要,例如 CSV 或 JSON。
您已在之前提供的pokemon_products列表中找到了产品信息。现在,让我们学习如何将其转换为新格式并将其导出到 Python 中的文件!
导出为 CSV
CSV 是一种流行的数据交换、存储和分析格式,尤其是在处理大型数据集时。 CSV 文件以表格形式存储信息,值之间用逗号分隔。这使得它与 Microsoft Excel 等电子表格程序兼容。
以下是如何在 Python 中将字典列表转换为 CSV 文件:
python
import csv
# scraping logic...
# write the scraped data to a CSV file
csv_file = open("pokemon_products.csv", "w", encoding="utf-8", newline="")
# create a CSV writer object
writer = csv.writer(csv_file)
# convert each element of the list to a row in the CSV file
for pokemon_product in pokemon_products:
writer.writerow(pokemon_product.values())
# release the resources
csv_file.close()导出为 JSON
JSON 是一种轻量级、通用且流行的数据交换格式,尤其是在 Web 应用程序中。它通常用于通过 API 在服务器之间或客户端和服务器之间传输信息。许多编程语言都支持它。
以下是在 Python 中将字典列表导出为 JSON 的代码:
python
import json
# scraping logic...
# create the pokemon_products.json
json_file = open("pokemon_products.json", "w")
# convert pokemon_products to JSON
# and write it into the JSON output file
json.dump(pokemon_products, json_file)
# release the file resources
json_file.close()上面提到的导出逻辑围绕着json.dump()函数,该函数来自Python的标准json模块,允许您将Python对象写入JSON格式的文件。
json.dump()有两个参数:
- 要转换为 JSON 格式的 Python 对象。
- 使用该函数使用将写入 JSON 数据的位置初始化文件对象open()。
完成上述所有步骤后,您可以导航到代码所在的文件夹,您会发现您抓取并导出的 CSV 和 JSON 文件已创建!
结论
恭喜!通过本教程,您已经学会了如何使用 Python 执行网页抓取并从网页中提取信息。
更多





