
Web Scraping
使用无头浏览器进行网络抓取: 扫描动态网站 2024
越来越多的网站在很大程度上都依赖Javascript来使用React、Angular、Vue.js等框架来构建。这些网站的内容是通过Ajax请求动态加载的,这对于传统的爬虫来说是一个挑战。
Apr 23, 2024
在这次的旅程中,我们将视角放到我们如何使用无头浏览器来爬取动态网站。无头浏览器是一个没有图形用户界面的浏览器,它可以模拟用户的行为,比如点击、滚动、填写表单等。这使得我们可以爬取那些需要用户交互的网站。现有的可用的工具以及如何使用它们?当开始进行爬取时,我们会遇到哪些挑战、提示和技巧?
什么是动态网页?
最常见的网站爬取问题之一是:“为什么我的爬虫不能够看到我在web浏览器中看到的数据?
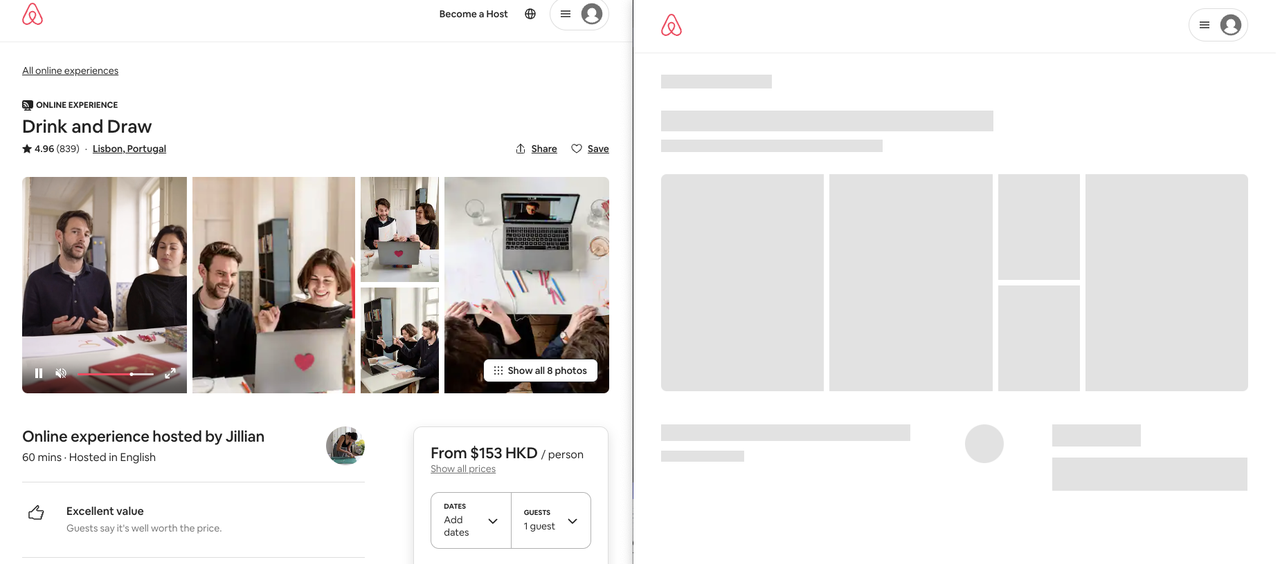
左侧是我们在浏览器中所看见的;右侧是我们爬虫所获取的;那其他的数据都去哪里了呢?
动态页面使用复杂的 JavaScript 驱动的 Web 技术,将处理卸载给客户端。换句话来说,它给用户数据和逻辑,但是不得不将它们放在一起才能看到完整的页面。这就是为什么我们的爬虫看到的只是一个空白页面。
一个简单的示例:
html
<!DOCTYPE html
<html>
<head>
<title>动态页面示例</title>
</head>
<body>
<div id="content"loading...</div
<script>
var data = {
name: "John Doe",
age: 30,
city: "New York",
};
document.addEventListener("DOMContentLoaded", function () {
var content = document.getElementById("content");
content.innerHTML = "<h1>" + data.name + "</h1>";
content.innerHTML += "<p>Age: " + data.age + "</p>";
content.innerHTML += "<p>City: " + data.city + "</p>";
});
</script>
</body>
</html>当打开页面并且禁用 JavaScript 时,我们会看到 loading...。但是当启用 JavaScript 时,我们会看到 John Doe、Age: 30 和 City: New York。这是因为 JavaScript 在页面加载后才会执行,所以我们的爬虫只能看到 loading...。因此,爬虫没有看到完全渲染的页面,因为它不是能够使用 JavaScript 加载页面的 Web 浏览器。
如何爬取动态网站?
我们能够通过集成一个真实的浏览器并操作它来爬取动态网站。对此,这里有大量的工具可供选择,比如 Puppeteer、Selenium and Playwright。这些工具都提供了用于控制浏览器的 API,使我们能够模拟用户的行为。
自动化浏览器是如何工作的?
现代化浏览器如 Chrome和Firefox等,随附内置自动化协议,允许其他程序控制这些Web浏览器。
当前,这里有两种浏览器的自动化协议:
- 新型的Chrome DevTools Protocol (CDP):这是 Chrome 浏览器的自动化协议,它允许其他程序控制 Chrome 浏览器。
- 旧的webdriver 协议:这是一个用于控制浏览器的协议,它会拦截操作请求并发出浏览器控制命令。
爬取示例
为了更好的表明这一挑战,我们将用现实世界真实的网页爬取做为示例。我们将会爬取一个在线的网站地址从 https://www.airbnb.com/experiences.。我们将简要介绍一下演示任务,并查看如何完全渲染一个体验页面,例如:https://www.airbnb.com/experiences/1653933 并返回完全渲染的内容以进行进一步处理。
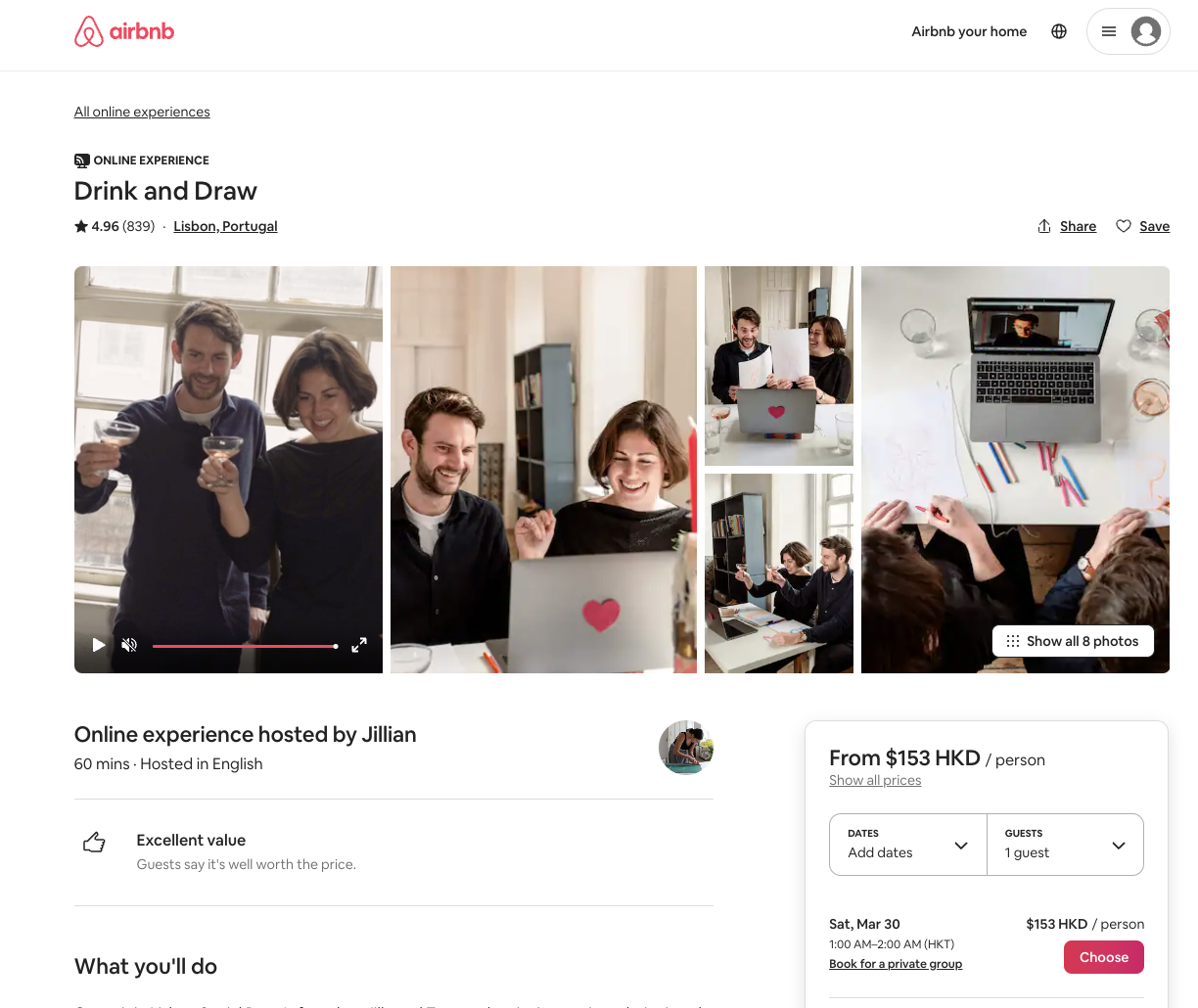
Airbnb是世界上使用React构建的生成的动态网站之一。这意味着我们的爬虫将无法看到完全渲染的页面。如果没有仿真的浏览器,我们就必须对网站的代码进行反向的工程,这样我们才能够爬取其完整的HTML内容。
但是,随着无头浏览器的出现,我们可以使用它来模拟用户的行为,从而爬取动态网站,我们的过程将会更加简单。
- 启动一个浏览器(如Chrome或者Firefox)
- 进去到网站 https://www.airbnb.com/experiences/1653933
- 等待页面加载完成
- 获取整个页面的源码内容,并且使用 BeautifulSoup 解析库来解析内容
接下里让我们尝试使用以下4中不同的浏览器自动化工具:Puppeteer、Selenium、Playwright和Nstbrowser。
Puppeteer
Puppeteer 是一个由 Google Chrome 团队开发的 Node.js 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chrome 或 Chromium。它是一个无头浏览器,这意味着它没有图形用户界面,但是可以模拟用户的行为。
与Selenium相比,Puppeteer支持更少的语言和浏览器,但它完全实现了CDP协议,并且在其背后的Google拥有强大的团队。
PuppeTeer还将自己描述为通用浏览器自动化客户端,而不是将自己适合于网络测试的利基市场 - 这是个好消息,因为网络剪裁问题获得了官方支持。
让我们看一下我们的airbnb.com示例在Puppeteer和JavaScript中的外观:
javascript
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://airbnb.com/experiences/1653933');
await page.waitForSelector("h1");
await page.content();
await browser.close();
})();Selenium
Selenium是为自动化网站测试而创建的第一个大型自动化客户端之一。它支持两个浏览器控制协议:WebDriver和CDP(仅由于Selenium V4+)。
Selenium是当今列表中最古老的工具,这意味着它具有相当大的社区和许多功能,并且几乎在每个编程语言中都得到支持,并且几乎每个网络浏览器都可以运行:
python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.expected_conditions import visibility_of_element_located
chrome_options = Options()
chrome_options.add_argument("--headless")
browser = webdriver.Chrome(chrome_options) # start a web browser
browser.get("https://www.airbnb.com/experiences/1653933") # navigate to URL
# wait for page to load
# by waiting for <h1> element to appear on the page
title = (
WebDriverWait(driver=browser, timeout=10)
.until(visibility_of_element_located((By.CSS_SELECTOR, "h1")))
.text
)
# retrieve fully rendered HTML content
content = browser.page_source
browser.close()
# we then could parse it with beautifulsoup
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, "html.parser")
print(soup.find("h1").text) # you will see the "Drink and Draw"
在上面,我们首先启动Web浏览器窗口,然后导航到一个Airbnb体验页面。然后,我们通过等待第一个h1元素出现在页面上来等待页面加载。最后,我们提取页面的HTML内容,并用 BeautifulSoup 对其进行解析。
Playwright
Playwright是Microsoft用多种语言提供的同步和异步Web浏览器自动化库。
Playwright的主要目标是可靠的端到端现代Web应用程序测试,尽管它仍然实现了所有通用浏览器自动化功能(例如Puppeteer和Selenium),并且具有不断增长的Web craping社区。
python
from playwright.sync_api import sync_playwright
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=True)
context = browser.new_context(viewport={"width": 1920, "height": 1080})
page = context.new_page()
page.goto("https://airbnb.com/experiences/1653933") # go to url
page.wait_for_selector('h1')
title = page.inner_text('h1')
print(title) # you will see "Drink and Draw"在上面的代码中,我们首先启动了一个 Chromium 浏览器,然后导航到 Airbnb 体验页面。然后,我们等待页面加载,然后提取页面的 HTML 内容。
Nstbrowser
Nstbrowser 是一款功能强大的反检测浏览器,专为多账户专业人士设计,可安全高效地管理多个账户。Nstbrowser 采用了一系列先进的技术,包括反检测浏览器、多账户、虚拟浏览器、浏览器指纹、账户管理,为用户提供了一种全新的浏览器使用体验。下面我们将使用其浏览器进行Headless模式获取网页内容。
先决条件
- 您需要注册成为 Nstbrowser 用户, 注册入口
- 获取 API Key。如何获取API Key?登录Nstbrowser后,进入API菜单后,复制您的API Key
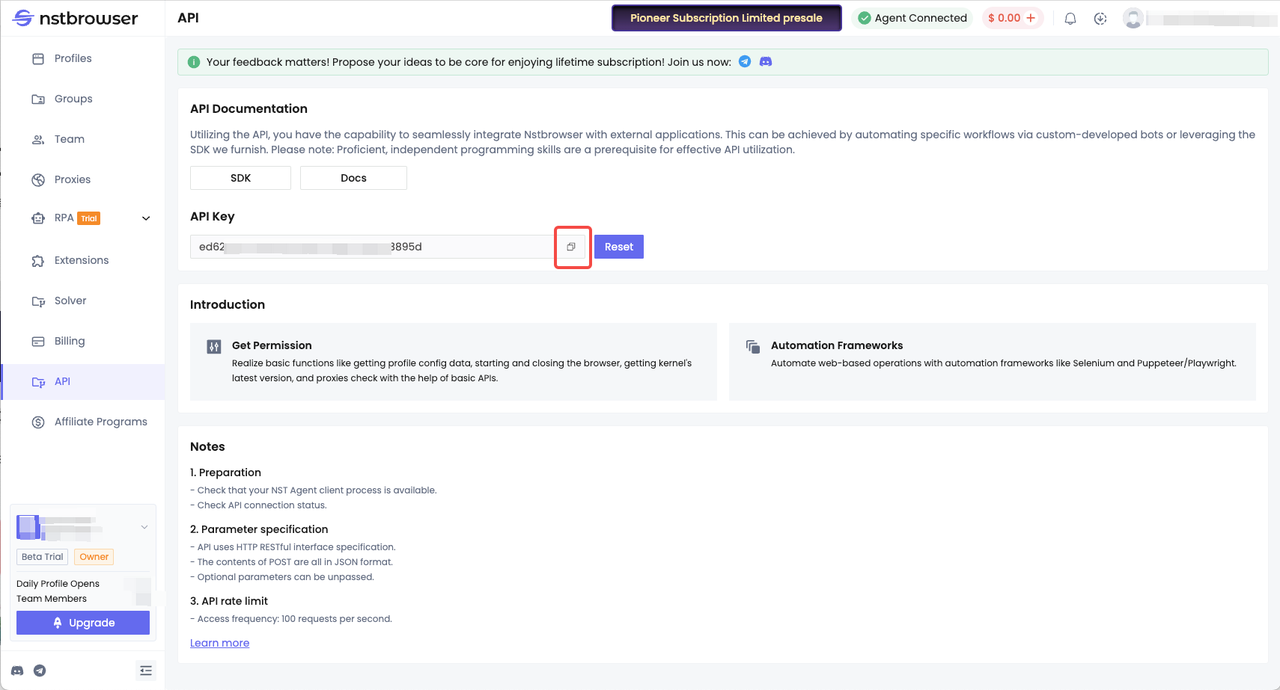
- 基于上面所了解到的 Playwright技术,我们继续使用Nstbrowser 来获取网页内容。
python
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.expected_conditions import visibility_of_element_located
from selenium.webdriver.chrome.service import Service as ChromeService
# get_debugger_port: Get the debugger port
def get_debugger_port(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
port = resp['data']['port']
return port
except HTTPError:
raise Exception(HTTPError.response)
def exec_selenium(debugger_address: str):
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", debugger_address)
# Replace with the corresponding version of WebDriver path.
chrome_driver_path = r'/Users/xxx/Desktop/chrome_web_driver/chromedriver_mac_arm64/chromedriver'
service = ChromeService(chrome_driver_path)
driver = webdriver.Chrome(service=service, options=options)
driver.get("https://www.airbnb.com/experiences/1653933")
# wait for page to load
# by waiting for <h1> element to appear on the page
title = (
WebDriverWait(driver=driver, timeout=10)
.until(visibility_of_element_located((By.CSS_SELECTOR, "h1")))
.text
)
content = driver.page_source
# we then could parse it with beautifulsoup
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, "html.parser")
print(soup.find("h1").text) # you will see the "Drink and Draw"
driver.close()
driver.quit()
def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'Your API Key Here' # got it from https://app.nstbrowser.io/
config = {
'headless': True, # open browser in headless mode
'remoteDebuggingPort': 9222,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
# userAgent supportted since v0.15.0
'fingerprint': { # required
'name': 'custom browser',
'platform': 'mac', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '113', # support: 113, 115, 118, 120
'hardwareConcurrency': 4, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # support: 2, 4, 8
'proxy': '', # input format: schema://user:password@host:port eg: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # required
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
print('devtool url: ' + url)
port = get_debugger_port(url)
debugger_address = f'{host}:{port}'
print("debugger_address: " + debugger_address)
exec_selenium(debugger_address)
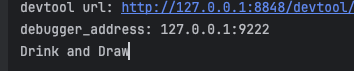
create_and_connect_to_browser()成功运行之后,我们同样会在控制台看到如下结果
为什么使用Nstbrowser?
- 真实的指纹浏览器环境,其数据指纹库包含了大量的真实浏览器指纹数据,可以模拟真实用户的行为。
- 在爬取过程中很多时候会遇到验证码识别的问题。Nstbrowser 利用人工智能技术实现自动 CAPTCHA 识别,使您在任何网站上畅通无阻的访问。
- 提供了自动代理池轮换功能,可以为特定目标确定最有效的代理。
- 强大的兼容性,与 Puppeteer、Playwright 和 Selenium 兼容,内置代理和解锁技术,比自动浏览器和无头浏览器强大得多。
总结
希望通过这次的教程学习,了解到下面2个要点
- Headless 模式爬取动态网站的原理
- Puppeteer、Selenium、Playwright 和 Nstbrowser 的使用
更多





