
Web Scraping
2024最好的Python网络爬虫分步指南
Python提供了非常强大的网络爬虫开发能力,是目前最流行的爬虫语言之一。阅读本文以了解如何使用Python进行网络爬取。
Jun 13, 2024Robin Brown
网络爬虫是一种强大的技术,它允许我们通过访问网页并发现网站上 URL来收集各种数据和信息。Python 有各种支持网络爬虫的库和框架。在本文中我们将了解到:
- 什么是 Python 爬虫
- 如何使用 Python 爬虫和 Nstbrowser API 爬取网页
- 如何应对 Python 爬取时被禁止的问题
- Python 的爬取实例
Python 中的网络爬虫是什么?
Python 提供了非常强大的网络爬虫开发能力,是目前最流行的爬虫语言之一。Python 网络爬虫是一种浏览网站或互联网以搜索网页的自动化程序。它是一个 Python 脚本,可以探索页面、发现链接并跟踪它们以增加可以从相关网站提取的数据。
搜索引擎依靠爬行机器人来构建和维护其页面索引,而网络抓取工具则使用它来访问和查找所有页面以应用数据提取逻辑。
Python 中的网络爬虫主要通过使用一些第三方库来实现。常见的 Python 网络爬虫库包括:
-
urllib/urllib2/requests:这些库提供了基本的网页抓取功能,可以发送 HTTP 请求并获取响应内容。
-
BeautifulSoup:这是一个用于解析 HTML 和 XML 文档的库,可以帮助爬虫提取网页中的有用信息。
-
Scrapy:这是一个强大的网络爬虫框架,提供了诸如数据提取、pipeline处理、分布式爬取等高级功能。
-
Selenium:这是一个 Web 浏览器自动化工具,可以模拟人工操作浏览器,用于抓取 JavaScript 生成的动态页面内容。
流行的网络爬虫用例:
搜索引擎(例如 Googlebot、Bingbot、Yandex Bot...)收集 Web 重要部分的所有 HTML。该数据被编入索引以使其可搜索。
SEO 分析工具除了收集 HTML 之外,还收集元数据,例如响应时间、响应状态以检测损坏的页面以及不同域之间的链接以收集反向链接。
价格监控工具会抓取电子商务网站以查找产品页面并提取元数据,尤其是价格。然后定期重新访问产品页面。
Common Crawl 维护着一个开放的网络爬网数据存储库。例如,2022 年 5 月的档案包含 34.5 亿个网页。
那么如何使用Python 自动化工具 Pyppeteer 来进行网络爬虫呢,请继续往下阅读。
如何使用 Python 自动化工具 Pyppeteer 和Nstbrowser API进行网络爬虫?
第一步:前提条件
在开始进行爬虫之前,需要做一些准备工作:
Shell
pip install pyppeteer requests json在安装完上述需要的库之后,新建一个文件 scraping.py,然后将我们刚才安装的库以及一些系统库引入文件:
Python
import asyncio
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from pyppeteer import launcher使用 pyppeteer 之前,我们首先要连接 Nstbrowser,Nstbrowser 提供了 api 来返回供 pyppeteer 使用的 webSocketDebuggerUrl
Python
# get_debugger_url: Get the debugger url
def get_debugger_url(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
webSocketDebuggerUrl = resp['data']['webSocketDebuggerUrl']
return webSocketDebuggerUrl
except HTTPError:
raise Exception(HTTPError.response)
async def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'your api key'
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # required
'name': 'custom browser',
'platform': 'windows', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '120', # support: 113, 115, 118, 120
'hardwareConcurrency': 4, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # support: 2, 4, 8
'proxy': '', # input format: schema://user:password@host:port eg: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # required
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
browser_ws_endpoint = get_debugger_url(url)
print("browser_ws_endpoint: " + browser_ws_endpoint) # pyppeteer通过browser_ws_endpoint来连接Nstbrowser
(
asyncio
.get_event_loop()
.run_until_complete(create_and_connect_to_browser())
)在成功获取到 Nstbrowser 的 webSocketDebuggerUrl 之后,我们使用 pyppeteer 来连接 Nstbrowser:
Python
async def exec_pyppeteer(wsEndpoint: str):
browser = await launcher.connect(browserWSEndpoint = wsEndpoint)
page = await browser.newPage()在终端运行我们刚才编写的代码:python scraping.py,可以看到我们成功的打开了一个 Nstbrowser,并且在 Nstbrowser 中新创建了一个标签页。
一切准备就绪,现在,我们可以正式开始进行爬虫了。
第二步:访问目标网站
比如:https://www.imdb.com/chart/top
Python
await page.goto('https://www.imdb.com/chart/top')第三步:执行代码
再执行一次我们的代码,会看到我们通过Nstbrowser访问了我们的目标网站。打开Devtool,查看我们想要爬取的具体信息,你会发现,他们是具有相同dom结构的元素。
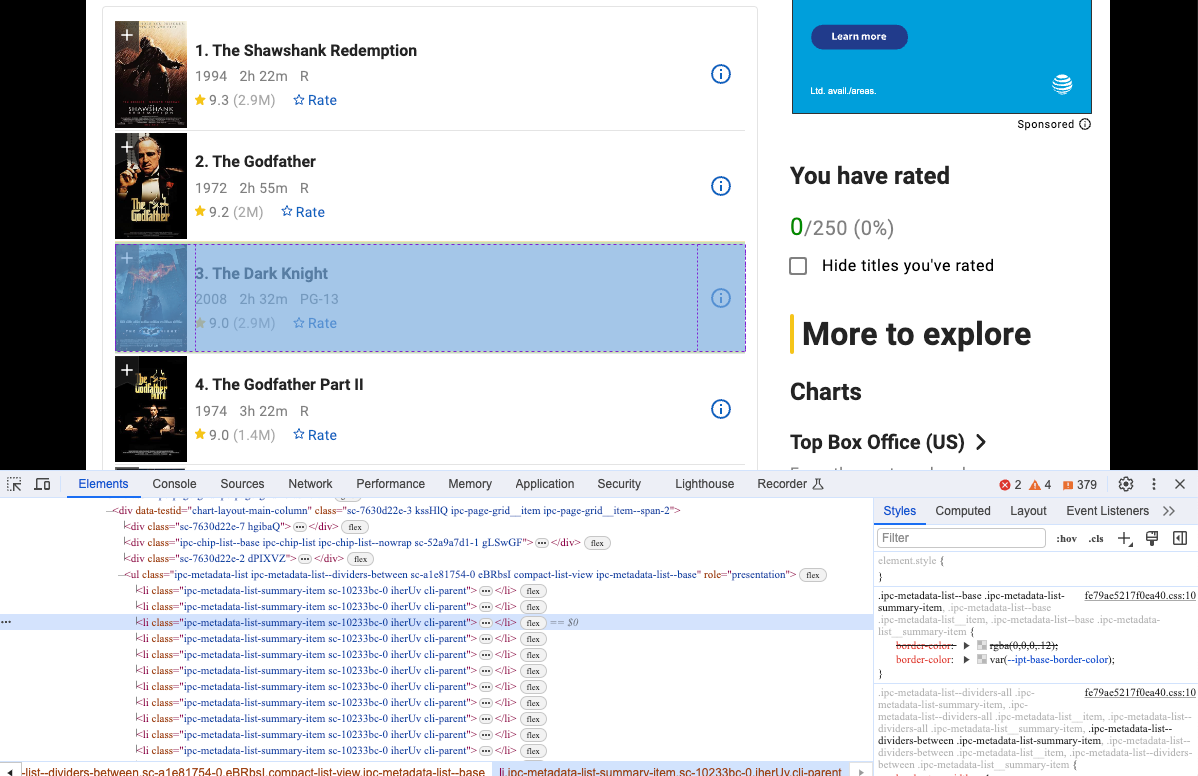
第四步:爬取网页
我们可以使用pyppeteer对这些dom结构进行爬取,并分析获取他们的内容:
Python
movies = await page.JJ('li.cli-parent')
for row in movies:
title = await row.J('.ipc-title-link-wrapper')
year = await row.J('span.cli-title-metadata-item')
rate = await row.J('.ipc-rating-star')
title_text = await page.evaluate('item => item.textContent', title)
year_text = await page.evaluate('item => item.textContent', year)
rate_text = await page.evaluate('item => item.textContent', rate)
pringt('titile: ', title_text)
pringt('year: ', title_text)
pringt('rate: ', title_text)当然,只在终端对数据进行输出显然不是我们的最终目的,我们要做的是将这些数据保存下来。
第五步:保存数据
我们使用json库,来将这些获取的数据保存到本地的json文件中:
Python
movies = await page.JJ('li.cli-parent')
movies_info = []
for row in movies:
title = await row.J('.ipc-title-link-wrapper')
year = await row.J('span.cli-title-metadata-item')
rate = await row.J('.ipc-rating-star')
title_text = await page.evaluate('item => item.textContent', title)
year_text = await page.evaluate('item => item.textContent', year)
rate_text = await page.evaluate('item => item.textContent', rate)
move_item = {
"title": title_text,
"year": year_text,
"rate": rate_text
}
movies_info.append(move_item)
# create the json file
json_file = open("movies.json", "w")
# convert movies_info to JSON
json.dump(movies_info, json_file)
# release the file resources
json_file.close()运行我们的代码,然后打开代码所在的文件夹,你会看到新出现了一个movies.json文件,打开json文件查看他的内容,如果你发现它的内容是这样的:
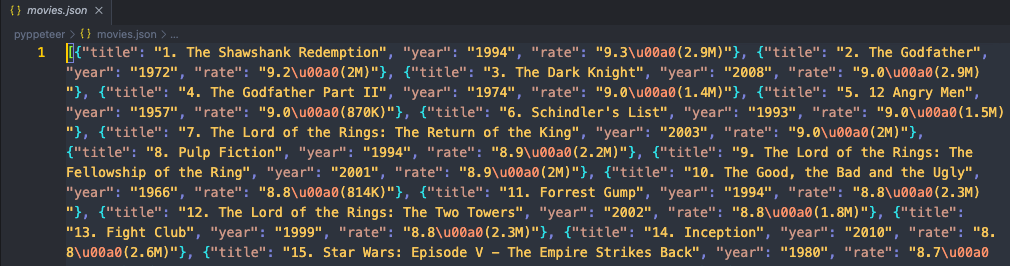
这说明我们已经成功的使用 pyppeteer 和Nstbrowser爬取了目标网站的数据!
4个解决 Python 爬虫被阻止的技巧
在 Python 中进行网络爬行时,最大的挑战是被阻止。许多网站通过反机器人措施来保护他们的访问,这些措施可以识别并停止自动化应用程序,阻止他们访问页面。
使用Nstbrowser 避免网络封锁和IP封禁
现在开始免费使用
您对网页抓取和 Browseless 有什么好的想法或疑惑吗?
快来看看其他开发人员在 Discord 和 Telegram 上分享了什么!
以下是一些克服反抓取技术的建议:
- 轮换
User-Agent:不断更改请求中的User-Agent标头有助于模仿不同的 Web 浏览器并避免被检测为机器人。
可以通过修改启动Nstbrowser时的config来修改UA信息:
Python
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # required
'name': 'custom browser2',
'platform': 'mac', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '120', # support: 113, 115, 118, 120
'hardwareConcurrency': 8, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 2, # support: 2, 4, 8
}
}-
在非高峰时段运行:在非高峰时段启动爬网程序并在请求之间加入延迟有助于防止网站服务器不堪重负并触发阻止机制。
-
尊重
robots.txt:遵循网站的 robots.txt 指令表明了道德的抓取行为。此外,它还有助于避免访问受限区域并使来自脚本的请求变得可疑。请参阅我们的指南,了解如何读取 robots.txt 进行网页抓取。 -
避免蜜罐:并非所有链接都相同,有些链接还隐藏着机器人陷阱。通过关注他们,您将被标记为机器人。详细了解什么是蜜罐以及如何避免它。
然而,这些技巧对于简单的场景来说非常有用,但对于更复杂的场景来说却不够。查看我们更多关于 网站爬取 的完整文章。
绕过所有防御措施并不容易,需要付出很大的努力。另外,今天有效的解决方案明天可能就失效了。但是等等,还有更好的解决方案!
Nstbrowser 通过 Browser Emulation、User-Agent Rotation 等有助于防止网站识别和阻止抓取活动。立即注册免费试用!
3个受欢迎的 Python 网络爬虫工具
有几种有用的网络爬行工具可以使发现链接和访问页面的过程变得更容易。以下是可以为您提供帮助的最佳 Python 网络爬行工具的列表:
-
Nstbrowser: 提供真实的浏览器指纹。结合先进的网站解锁和机器人绕过技术,并且可以智能轮换IP,极大减少被检测的概率。
-
Scrapy:适合初学者的最强大的 Python 爬行库选项之一。它提供了一个用于构建可扩展且高效的爬虫的高级框架。
-
Selenium:一个流行的无头浏览器库,用于网络抓取和爬行。与 BeautifulSoup 不同的是,它可以像人类用户一样与浏览器中的网页进行交互。
结论
通过本篇文章,您一定完全清楚了网络爬行的基础知识。需要指出的是,无论您的爬虫程序有多智能,反机器人程序措施都可以检测并阻止它。
但是,您可以使用 Nstbrowser 摆脱任何挑战,Nstbrowser 是一个具有自动化功能的一体化反检测浏览器,具有 Browser Fingerprinting 、Captcha Solver、UA Rotation 和许多其他避免被阻止的必备功能。
爬行从未如此简单!现在开始使用 Nstbrowser 成为一个网络爬虫大师!
更多





