
Web Scraping
如何使用 Node.js 进行网络抓取?
Node.js 以其高效的性能、丰富的生态系统和广泛的应用场景,成为现代Web开发中非常流行的一种技术。本文将介绍如何使用Node.js进行网页抓取,包括基本概念、工具使用及反检测方法,帮助高效获取和处理网站数据。
May 15, 2024Robin Brown
使用 “Node.js” 进行网页抓取是一种非常常见的需求,比如我们需要抓取某个网站的数据,然后进行分析,或者是需要抓取某个网站的数据,然后展示在自己的网站上。这个时候,我们可以使用 Node.js 来进行网页抓取。
在阅读完本文之后,您将会:
- 了解 Web scraping 的基本概念
- 了解
Node.js的相关知识 - 了解如何使用 Node.js 进行网页抓取
什么是 Web Scraping?它有什么益处?
“Web scraping” 是指从网页上抓取数据的过程。在这个过程中,我们会使用一些工具或者程序来模拟浏览器的行为,然后从网页上抓取我们需要的数据。这个过程有时候也被称为 “web harvesting” 或者 “web data extraction”。
Web scraping 有很多的益处,比如:
- 可以帮助我们抓取一些网站上的数据,用于进行分析。
- 在产品开发的过程中,能够帮助我们获取一些竞品的数据,用于分析竞品的优劣势。
- 自动化的完成一些重复性的工作,比如抓取某个网站上的所有图片,或者是抓取某个网站上的所有链接等等。
什么是Node.js?
Node.js是一个开源的、跨平台的JavaScript运行时环境,能够在服务器端执行JavaScript代码。它由Ryan Dahl在2009年创建,并且是基于Chrome的V8 JavaScript引擎构建的。Node.js 的设计初衷是为了构建高性能的、可扩展的网络应用,特别是那些需要处理大量并发连接的应用,如Web服务器和实时应用。
Node.js 的特点:
- 事件驱动和异步编程模型:Node.js采用事件驱动的架构,使用非阻塞I/O操作,使其在处理并发请求时非常高效。这意味着即使在处理大量请求时,服务器也不会因为等待I/O操作完成而阻塞。
- 单线程架构:Node.js运行在单个线程上,利用事件循环机制来处理并发。这与传统的多线程模型不同,通过避免线程上下文切换开销,提高了性能和资源利用率。
- npm(Node包管理器):Node.js附带了npm,这是一个包管理工具,允许开发者轻松地安装和管理项目所需的各种库和工具。npm上有大量的开源模块,可以极大地加速开发过程。
- 跨平台:Node.js可以在多个操作系统上运行,包括Windows、Linux和macOS,使其成为一个灵活的开发平台。
为什么你应该使用 Node.js 进行网页抓取?
Node.js 是一个非常流行的 JavaScript 运行环境,它可以让我们使用 JavaScript 来进行服务器端的开发。使用 Node.js 进行网页抓取有很多的优势,比如:
- Node.js 有很多的库可以帮助我们进行网页抓取,比如 request、cheerio、puppeteer 等等。
- Node.js 的异步非阻塞的特性,使得我们可以很方便的进行并发的网页抓取。
- Node.js 能够处理I/O密集型的任务,这样我们就可以很方便的进行网页抓取。
- Node.js 是学起来是非常容易的,只要你懂得 JavaScript,那么你就可以很快的上手 Node.js 进行网页抓取。
如何使用 Node.js 进行网页抓取?
废话少说,现在我们正式开始使用 Node.js 进行网络抓取。
第一步:初始化环境
首先,我们必须下载并安装配置好 Node.js 环境。Node.js 的官方网站提供了非常详细的安装教程,你可以根据自己的操作系统下载对应的安装包,然后安装配置好 Node.js 环境。
第二步:安装Puppeteer
Node.js 有很多的库可以帮助我们进行网页抓取,比如 request、cheerio、puppeteer 等等。这里我们以 puppeteer 为例,来演示如何使用 Node.js 进行网页抓取。
Puppeteer 是Node.js的一个库,我们可以使用Node.js的包管理器npm来安装它。在终端中输入以下命令来安装puppeteer:
Bash
mkdir web-scraping && cd web-scraping
npm init -y
npm install puppeteer-core第三步:创建编码文件
在项目目录下创建一个文件,比如 index.js,然后在 index.js 中输入以下代码:
goTo方法用于打开一个网页。它接受两个参数,第一个参数是要打开的网页的 URL,第二个参数是一个配置对象,我们可以通过配置对象来设置一些参数,比如 waitUntil,表示等待页面加载完成之后再返回。waitForSelector方法用于等待一个选择器出现。它接受一个选择器作为参数,当这个选择器出现在页面上的时候,它会返回一个 Promise 对象,我们可以通过这个 Promise 对象来判断选择器是否出现。content方法用于获取页面的内容。它会返回一个 Promise 对象,我们可以通过这个对象来进行页面内容的获取。page.$eval方法用于获取选择器的文本内容。它接受两个参数,第一个参数是选择器,第二个参数是一个函数,这个函数会在浏览器中执行,我们可以通过这个函数来获取选择器的文本内容。
JavaScript
const puppeteer = require('puppeteer');
async function run() {
const browser = await puppeteer.launch({
headless: false,
ignoreHTTPSErrors: true,
});
const page = await browser.newPage();
await page.goto('https://airbnb.com/experiences/1653933', {
waitUntil: 'domcontentloaded',
});
await page.waitForSelector('h1');
await page.content();
const title = await page.$eval('h1', (el) => el.textContent);
console.log(title);
await browser.close();
}
run();第四步:执行程序
在终端中输入以下命令来运行 index.js:
Bash
node index.js执行成功之后,你将会在终端中看到如下的输出结果:

通过以上的实例,我们首先使用 puppeteer.launch() 方法来创建一个浏览器实例,然后使用 browser.newPage() 方法来创建一个新的页面,接着使用 page.goto() 方法来打开一个网页,然后使用 page.waitForSelector() 方法来等待一个选择器出现,最后使用 page.$eval() 方法来获取选择器的文本内容。
在上面的例子中,我们也可以通过浏览器打开爬去的网站,然后打开开发者工具,然后通过选择器来定位到我们需要的元素,查看元素的内容和我们代码中获取的内容是否一致。
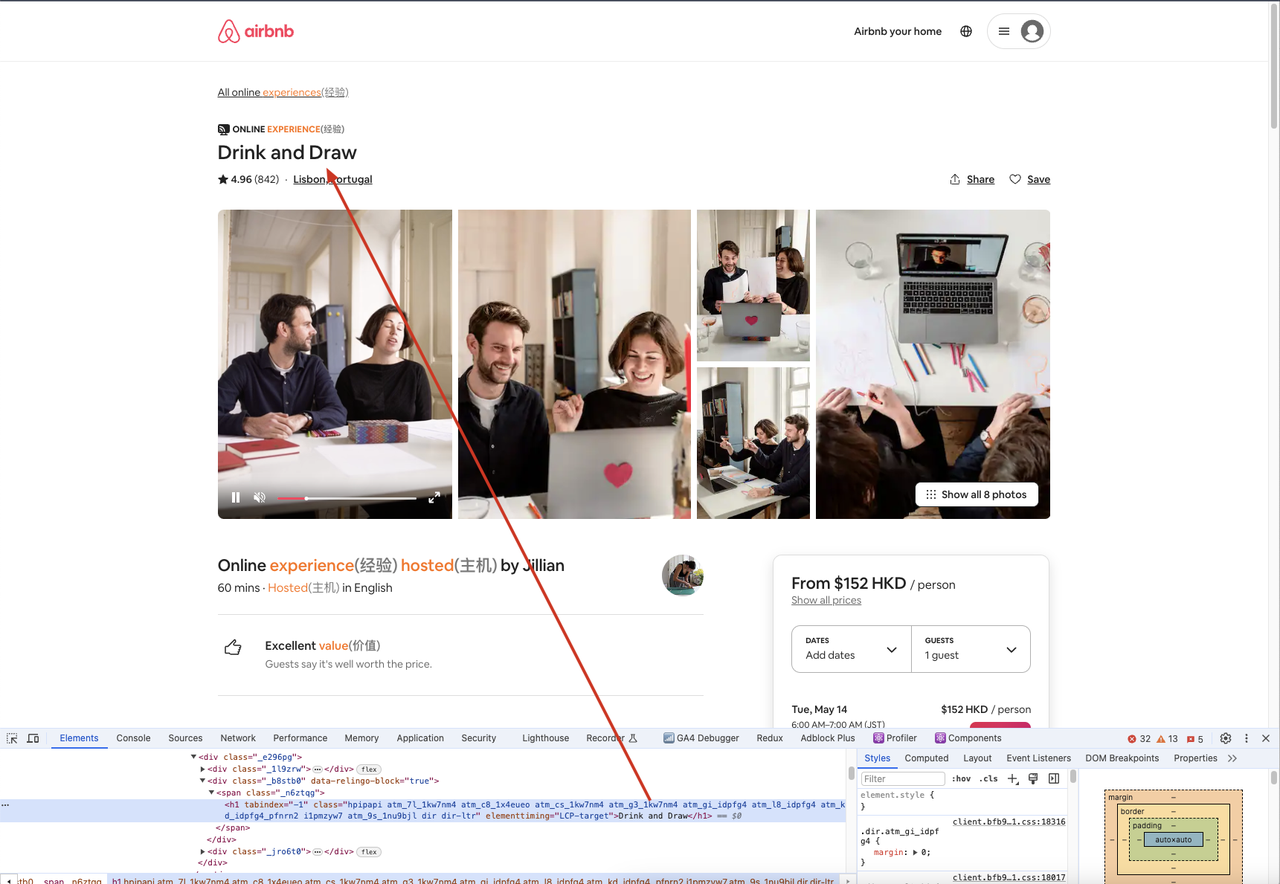
应对方案:反检测
在上面的例子中,我们使用了 puppeteer 来进行网页抓取,但是有些网站会检测到我们是通过程序来进行网页抓取的,然后会返回一些错误信息,比如 403 Forbidden,这个时候我们就需要进行反检测。反检测的方法有很多种,比如:
- 使用代理 IP
- 使用 User-Agent
- 使用 Headless
- 特定的 font 和 canvas指纹等等
通过这些方法,我们可以进行反检测,从而避免被网站检测到我们是通过程序来进行网页抓取的。推荐使用 Nstbrowser - Advanced Anti-Detect Browser 反检测浏览器进行 Web Scraping 的相关操作。
更多





