
Web ScrapingRPA
如何使用Nstbrowser RPA工具对Google地图搜索结果进行爬取?
怎样最有效地进行网站爬取呢?没错,RPA工具能大大提高效率、降低成本。在本篇博客中,你将了解到如何利用Nstbrowser RPA工具爬取谷歌地图搜索结果。
May 14, 2024
使用RPA工具进行网络数据爬取是一种常见的数据搜集手段,利用RPA工具可以大大提高数据搜集的效率,降低搜集成本。Nstbrowser RPA功能则能为您提供最好的RPA使用体验以及最好工作效率。
在阅读完本教程后,您将会:
- 了解如何使用RPA进行数据搜集
- 了解如何保存RPA搜集到的数据
第一步:准备工作
首先,您需要拥有Nstbrowser账号并登录Nstbrowser客户端,进入RPA模块的workflow页面,点击新建workflow。
现在,我们就可以开始配置基于Google地图搜索结果的RPA爬取的workflow了。
第二步:访问目标网站
在搜索目标内容前,我们需要先访问我们的目标网站:https://www.google.com/maps
使用Goto Url节点,配置网站url,就可以访问目标网站了
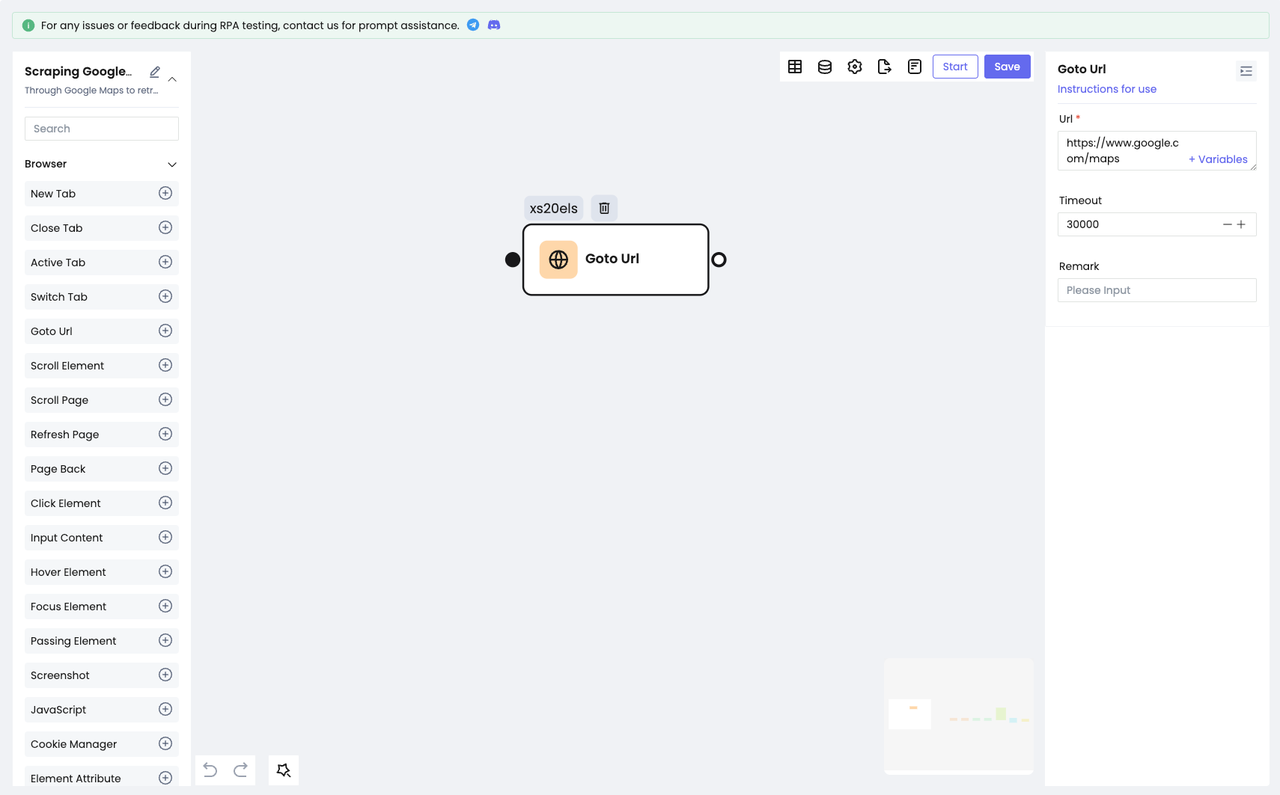
第三步:搜索目标内容
在到达目标网站之后,我们需要先对目标地址进行搜索,这里需要使用Chrome Devtool工具来对HTML元素进行定位。
打开Devtool工具,使用鼠标选取搜索框,我们可以看到:
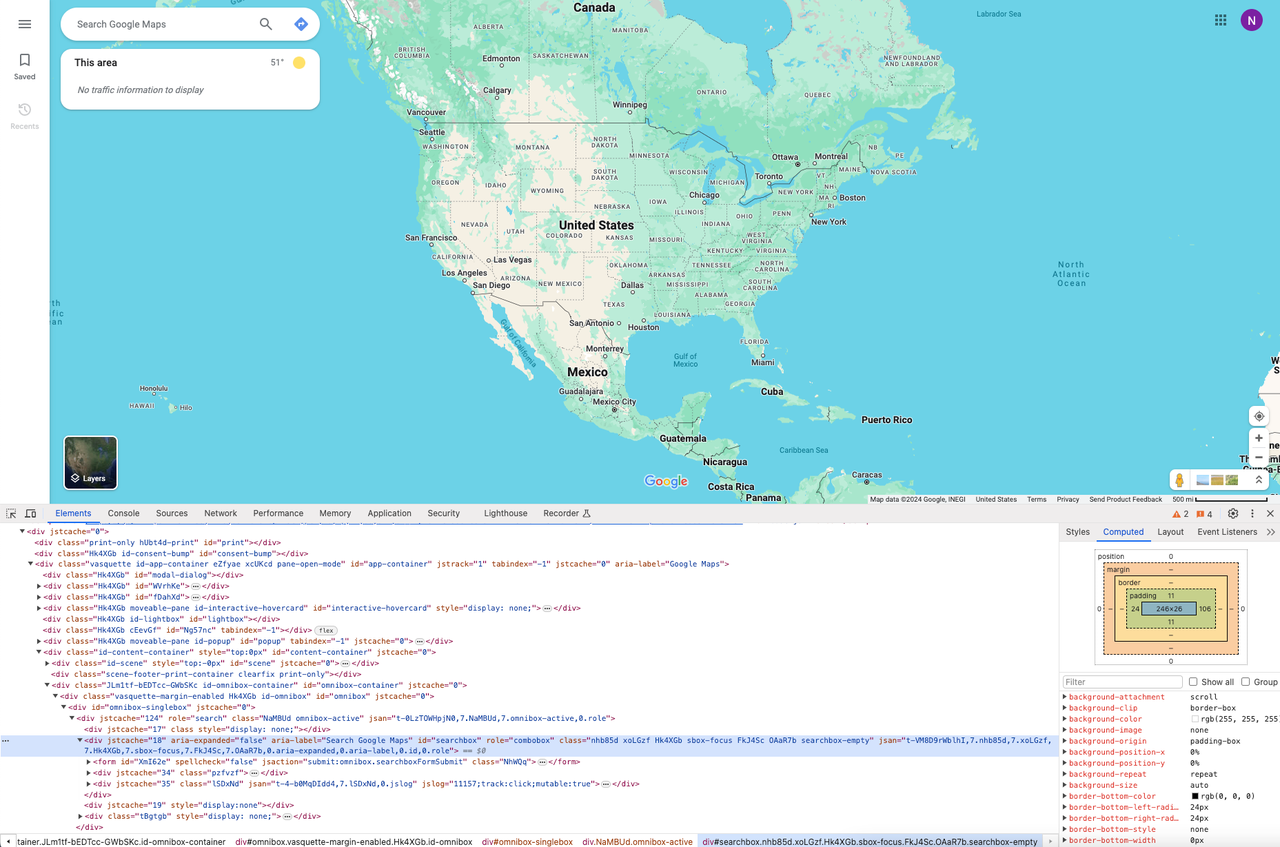
- 我们的目标输入框元素有一个
id属性,可以将这个属性作为CSS选择器,来定位输入框。
添加Input Content节点:Element选项选择“Selector”,Selector选项统一选择Selector。在输入框中填写我们定位到的id的值,然后在Content选项中输入我们要搜索的内容,这样,我们就完成了在输入框进行输入的动作:
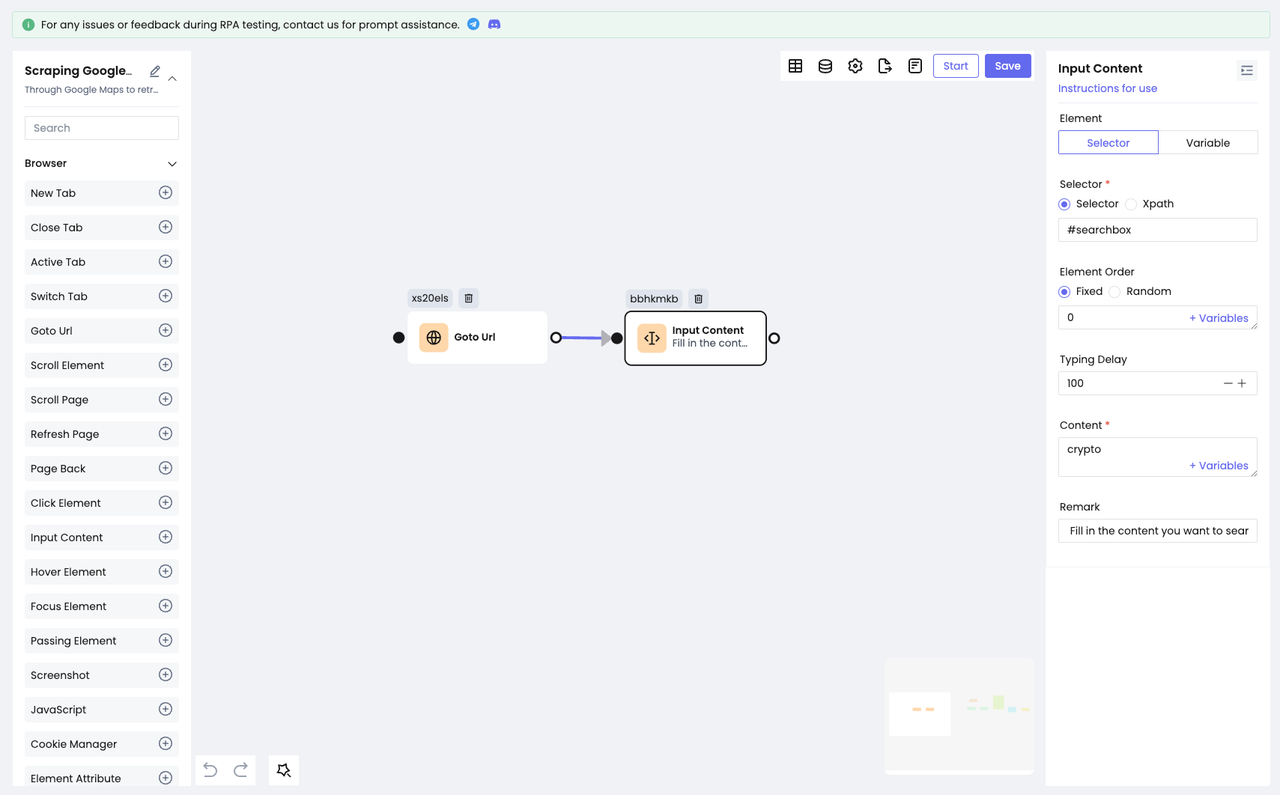
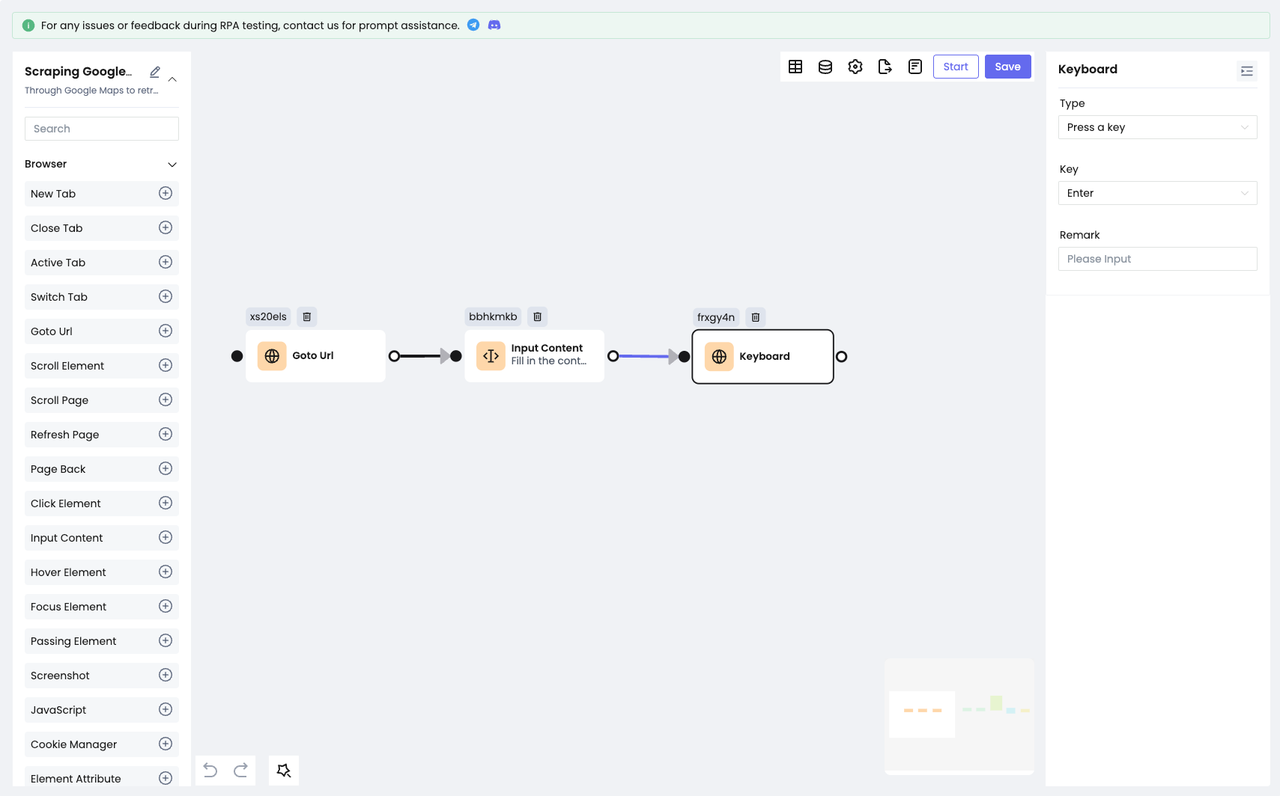
在完成了输入之后,我们还需要让Google地图搜索我们填写的内容:
- 使用
Keyboard节点模拟键盘的回车动作,可以快速完成这一操作。
第四步:抓取数据
好的,进行到现在,我们已经成功的搜索到了我们想要的内容,接下来就是抓取这些内容了。
通过观察,我们可以发现Google地图的搜索结果呈列表形态展示。这是一种很经典的展示方式,可以将部分重要信息展示在列表中,然后点击列表中的某一项,谷歌地图会在旁边展示出对应的全部信息。
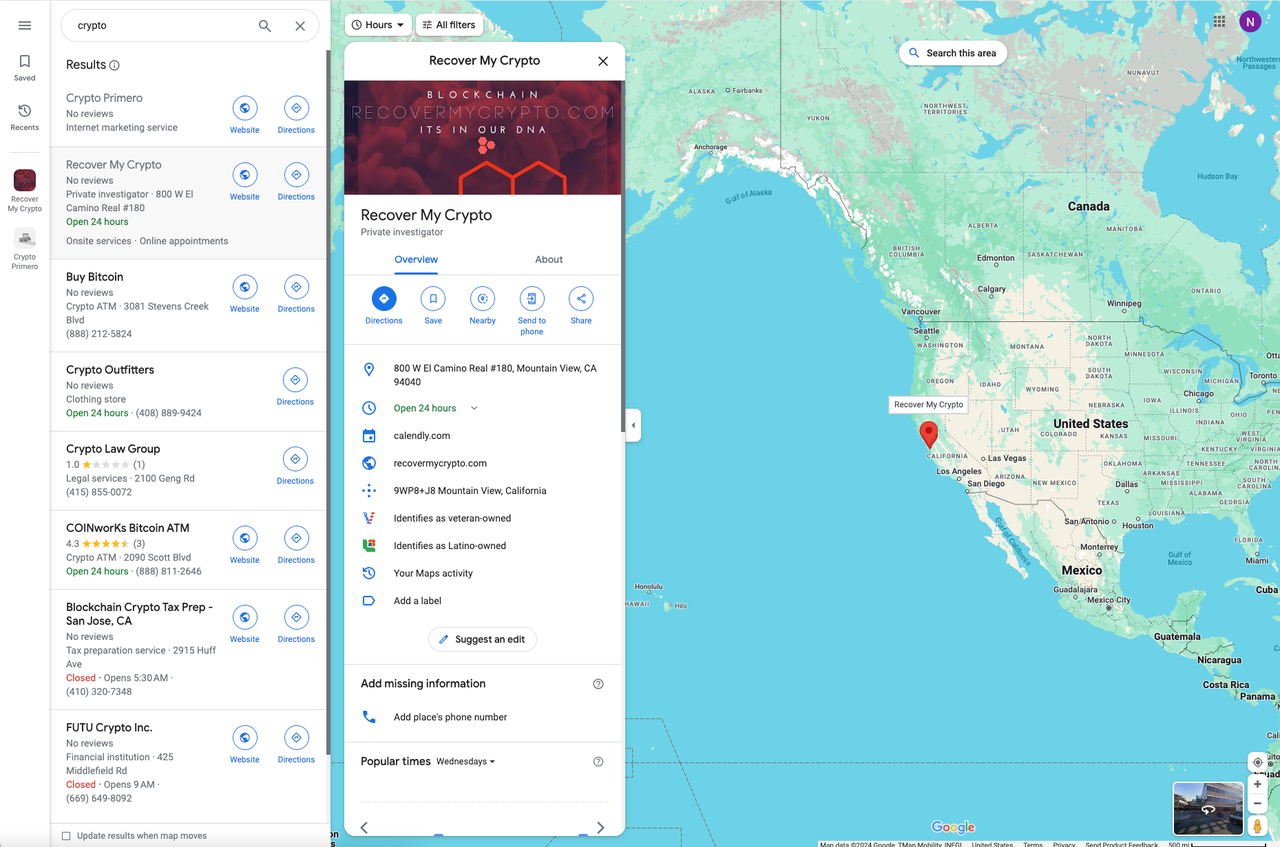
同样的,打开Devtool工具,对列表中的每一项结果进行定位:
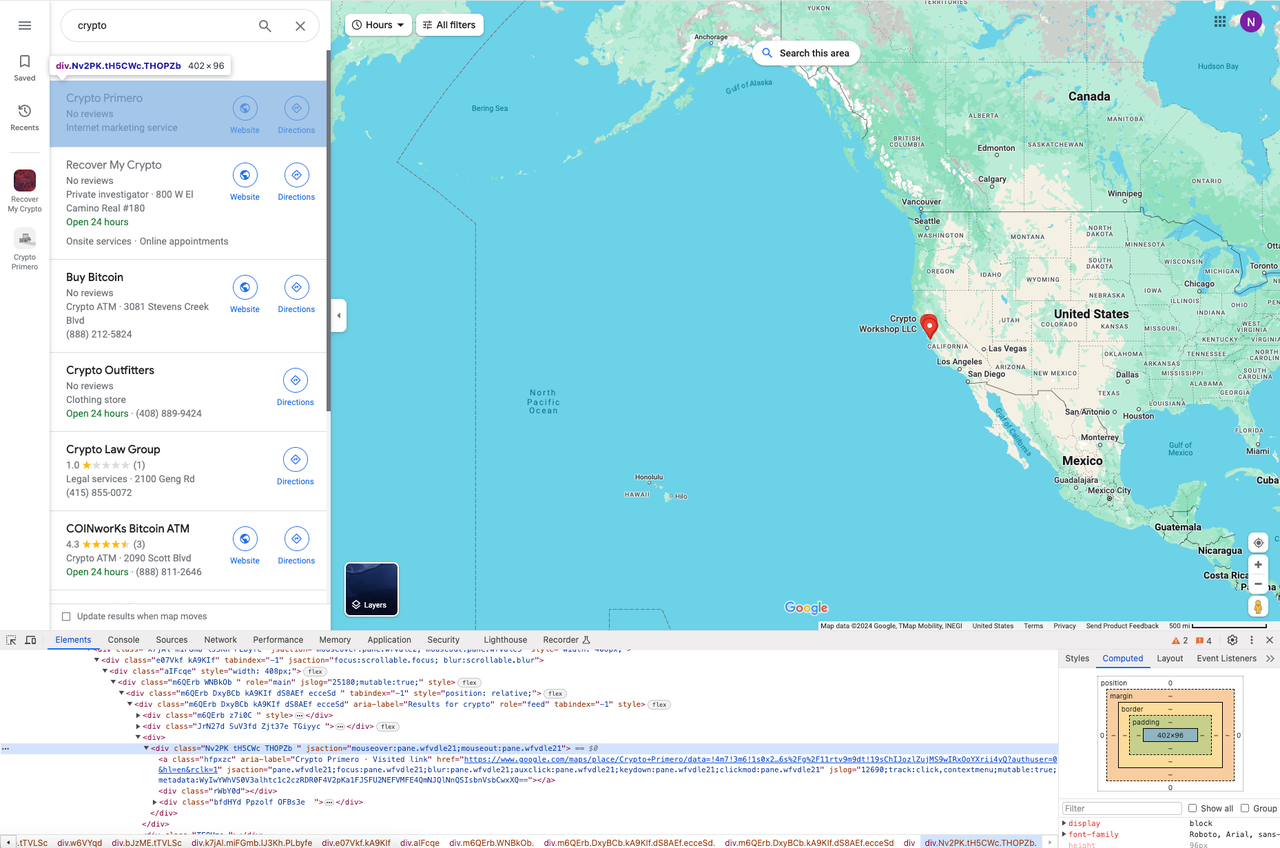
遍历结果列表
因为列表中的每一项都是用于的HTML布局,所以我们需要使用Loop Element节点,来遍历所有查询到的结果:
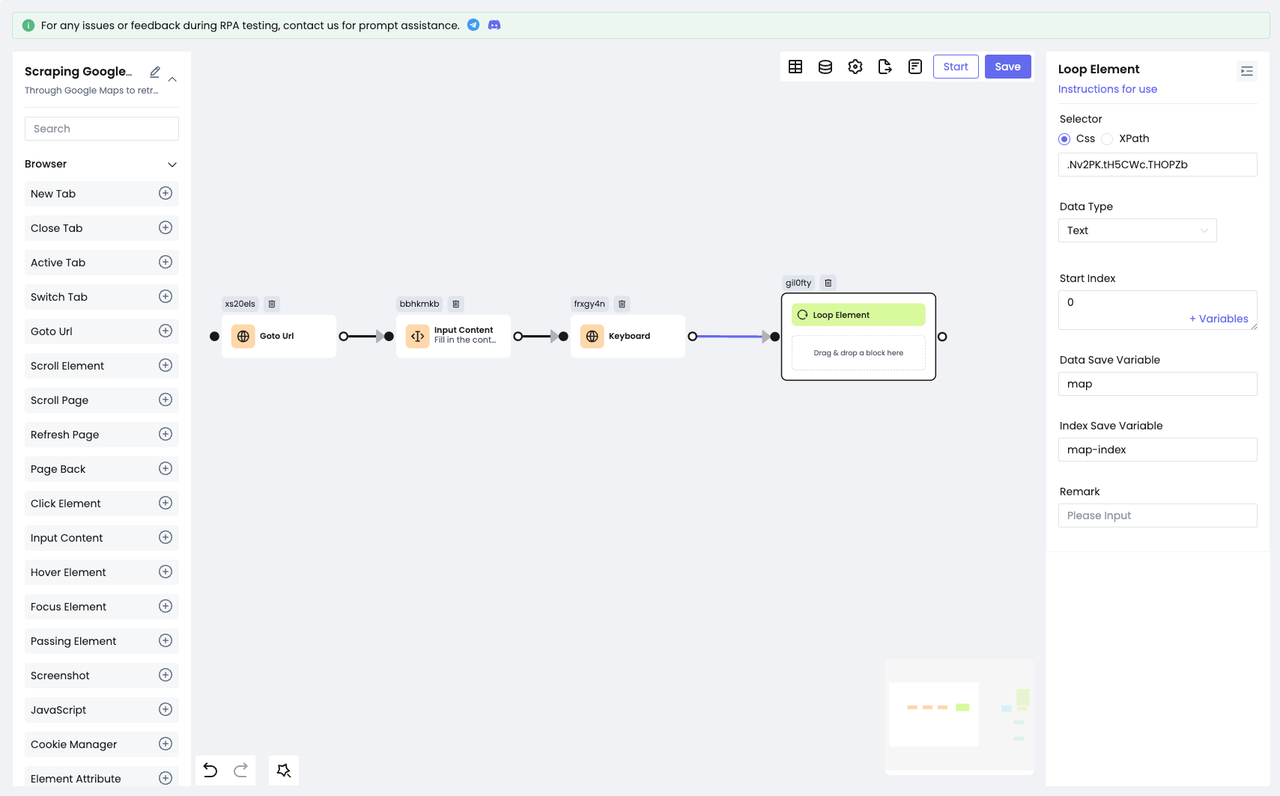
我们将遍历出的每一个元素都保存到map变量中,将每一个元素的索引都保存到map-index遍历中,以便后续使用。
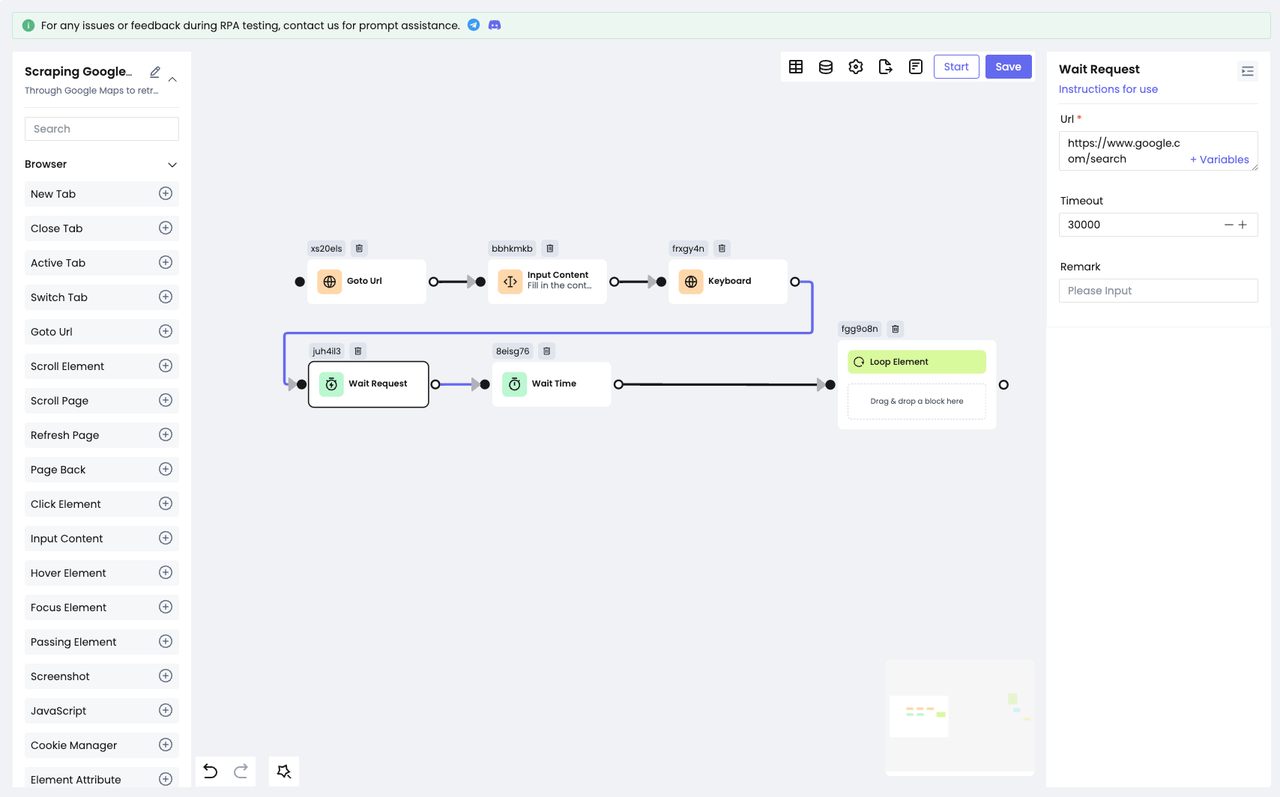
因为搜索结果是通过网络请求获取的,所以为了在遍历搜索结果的时候正确获取到目标元素,我们可以在遍历之前加一个等待的动作,以确保我们获取的是最新的正确的元素。Nstbrowser RPA提供了两种等待行为:Wait Time、Wait Request。
Wait Time:用于等待一段时间。可以根据自己的具体情况选择固定时间或随机时间。Wait Request:用于等待网络请求结束。适用于通过网络请求获取数据的情况。
点击列表项
在对每一项结果进行都遍历之后,我们需要对遍历中的每一项都进行数据搜集。
在获取到完整信息前,需要先点击列表项,这里我们可以使用Get Element Data节点根据map变量保存的元素定位到可以点击的目标元素:
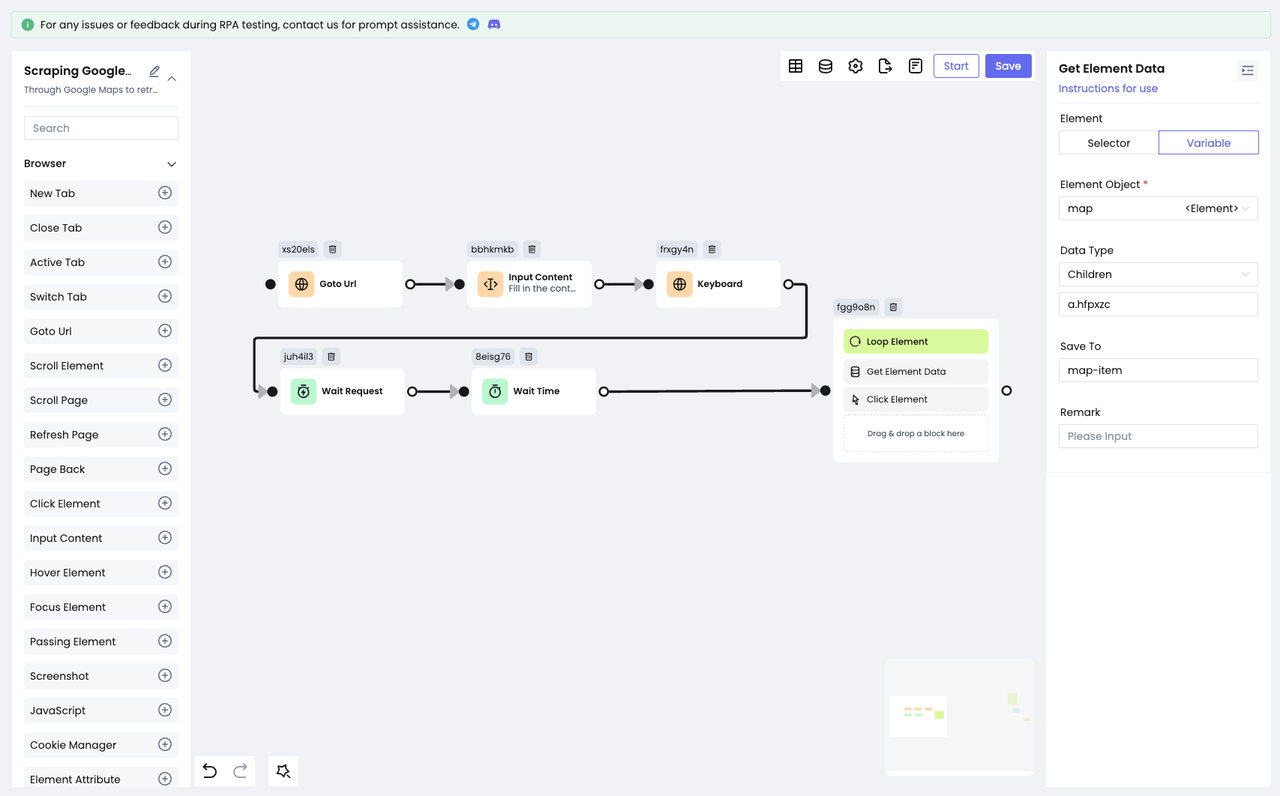
然后使用Click Element节点进行点击:
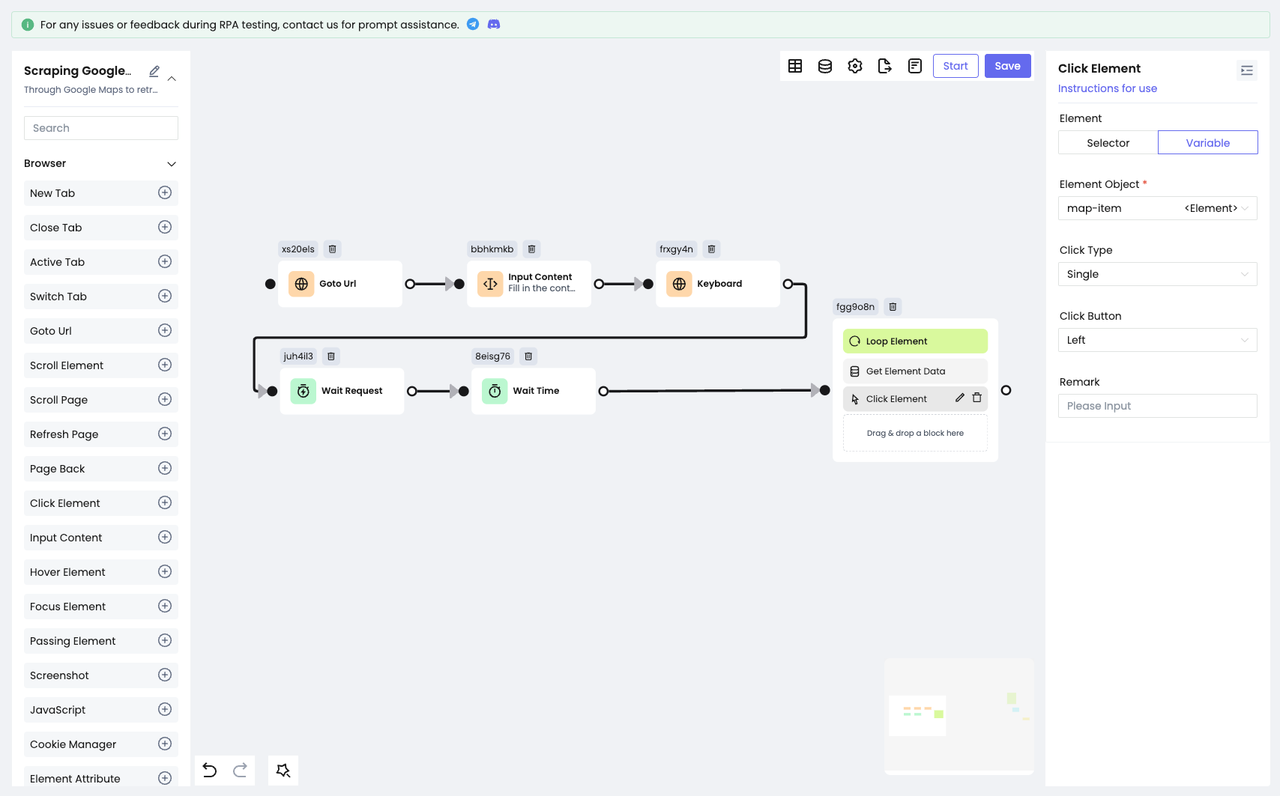
- 将上述节点拖拽进入
Loop Element内部,这样节点就会在循环内部执行了。
获取数据
在执行完上面的动作后,我们已经可以看到每一项搜索结果的具体信息了,这个时候我们就可以使用Get Element Data节点来获取我们想要的数据了。
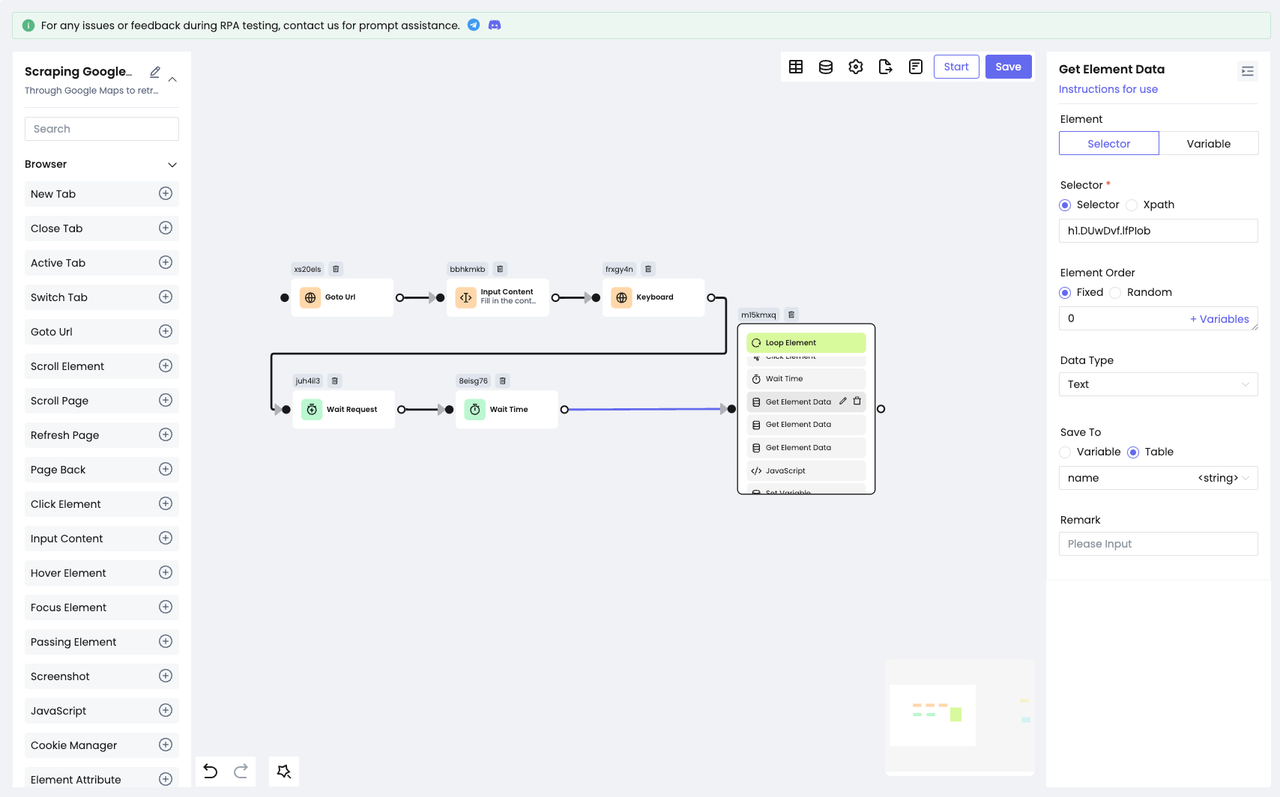
同样的,使用Devtool对我们的目标元素进行定位,然后使用节点获取元素的内容,并且将信息保存至我们预先设计好的表格中:
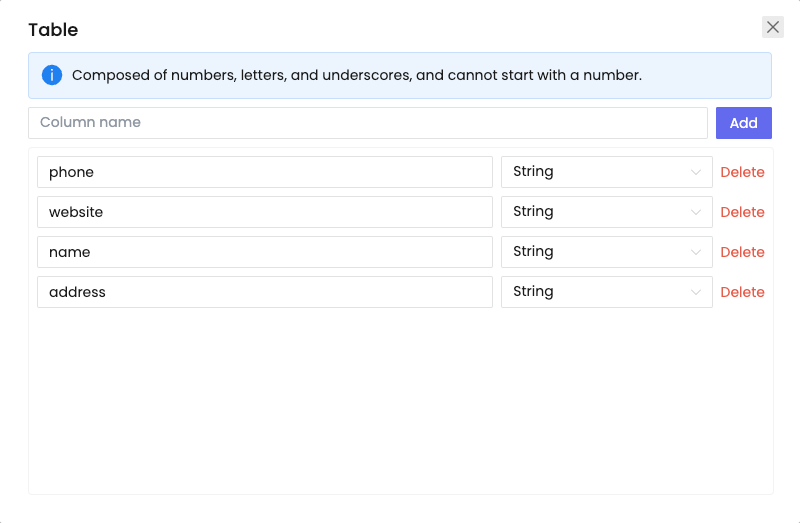
到这里,我们已经完成了对单独一项搜索结果的信息爬取了!
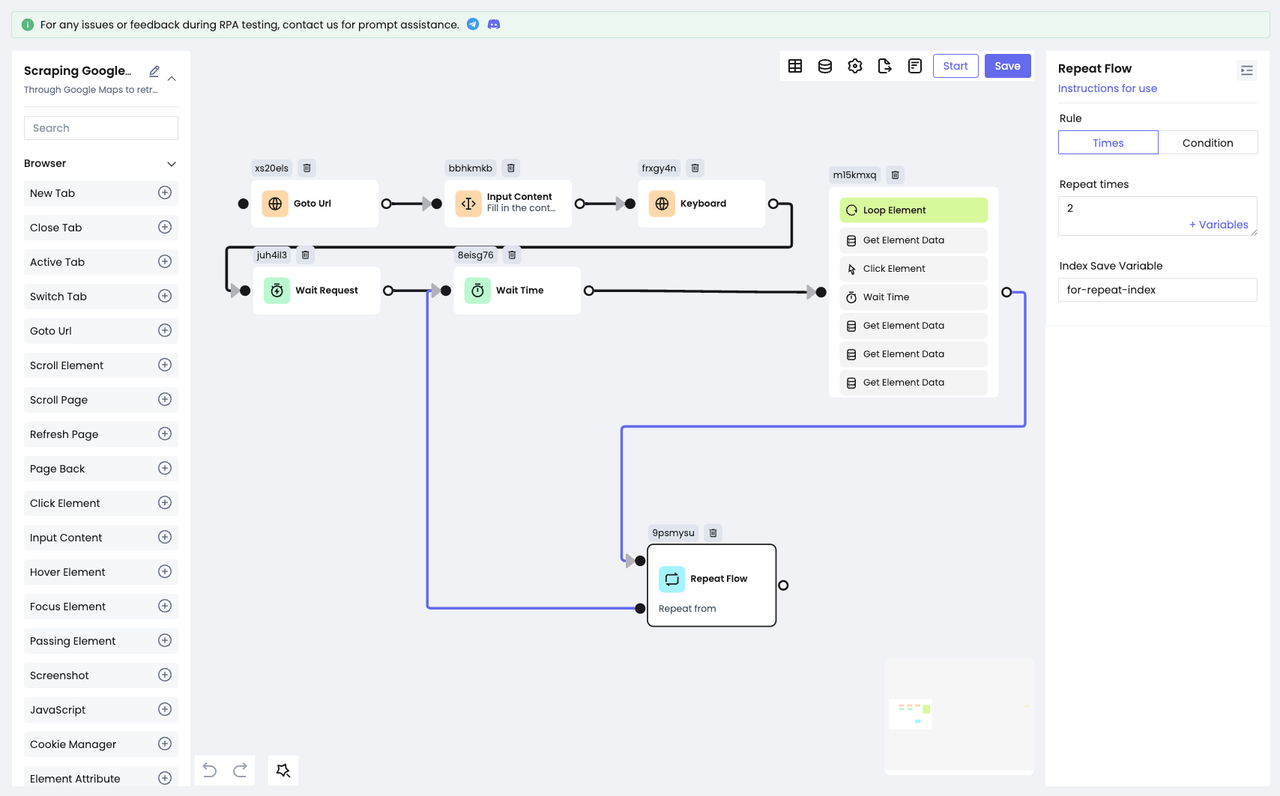
第五步:重复动作
当然了,只搜集一次搜索获取的数据是不够的,我们想要更多的数据。Nstbrowser RPA功能同样提供了便利,让您只需要一个节点就可以重复上面的所有动作!
Repeat Flow节点用于重复执行已存在的节点,只需要配置重复次数或结束条件,就可以根据您的需求来进行重复动作。
假设我们需要再搜集两次请求的数据,那么,我们需要配置重复次数为2:
第六步:保存结果
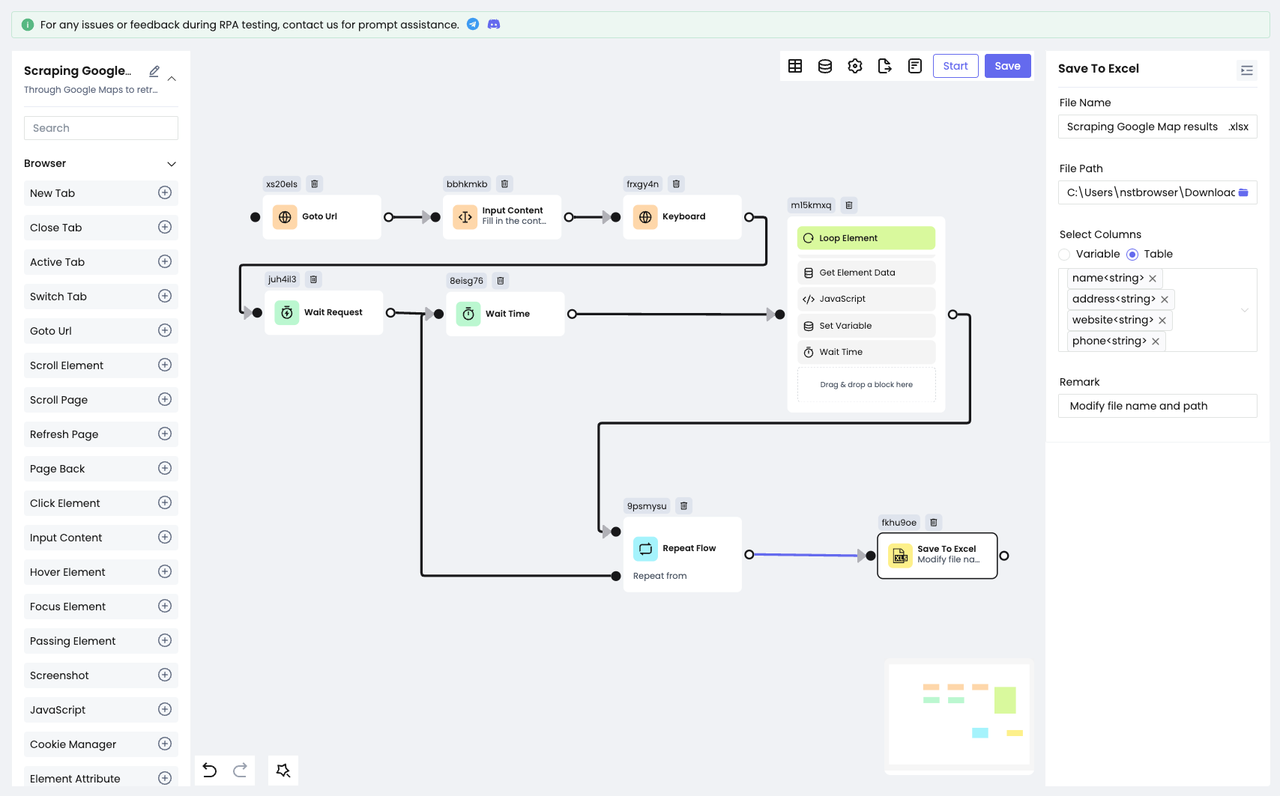
到这里我们已经获取到了我们想要搜集的全部数据,是时候将这些数据保存下来了。
- Nstbrowser RPA提供了两种保存数据的方法:
Save To File、Save To Excel。
Save To File提供了三种文件类型供您选择:.txt、. csv、.json。Save To Excel则只能将数据保存到Excel文件中。
为了方便查看,我们选择将搜集到的数据保存到Excel中。添加Save To Excel节点,配置要保存的文件路径和文件名,选择要保存的表格内容,就大功告成了!
第七步:执行RPA
保存我们配置的workflow,然后新建一个scheduled,点击运行按钮,就可以开始搜集Google地图的数据了!
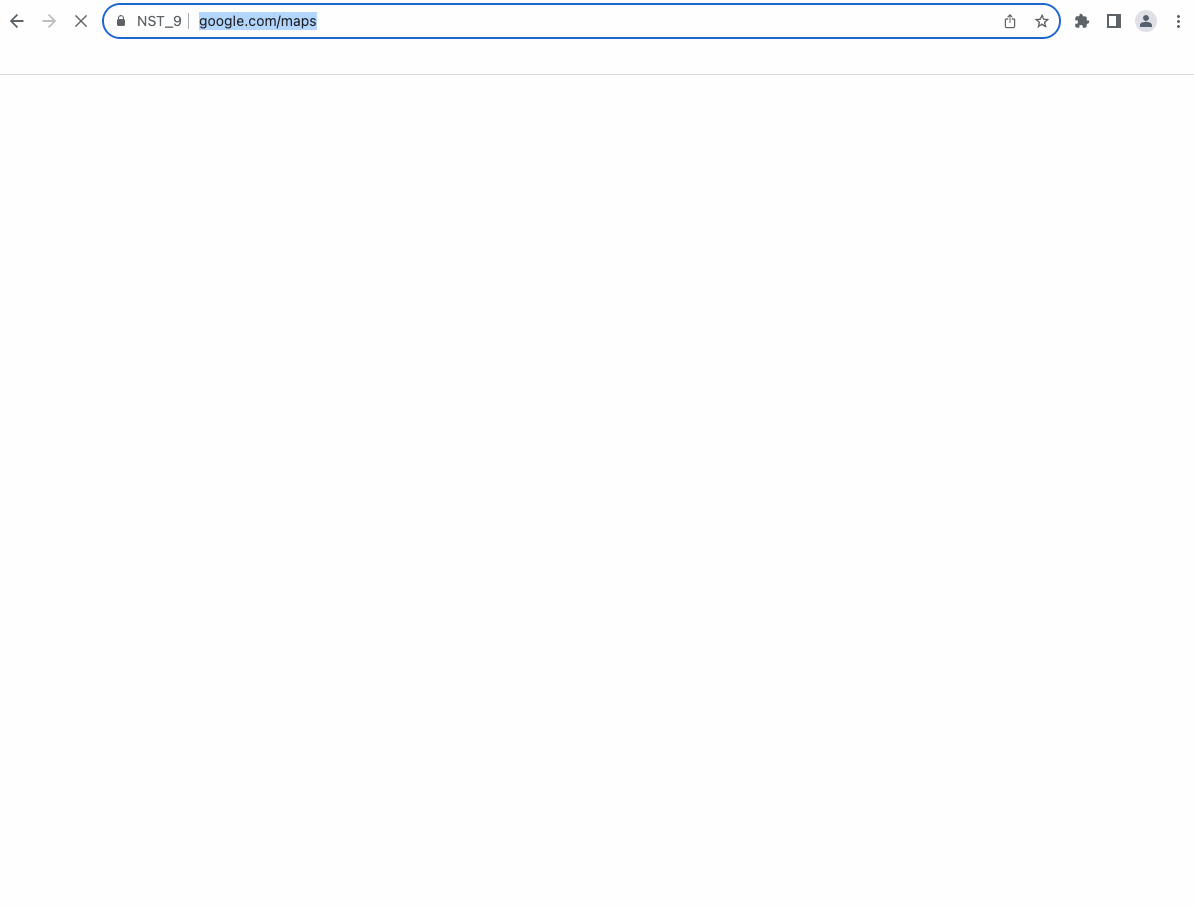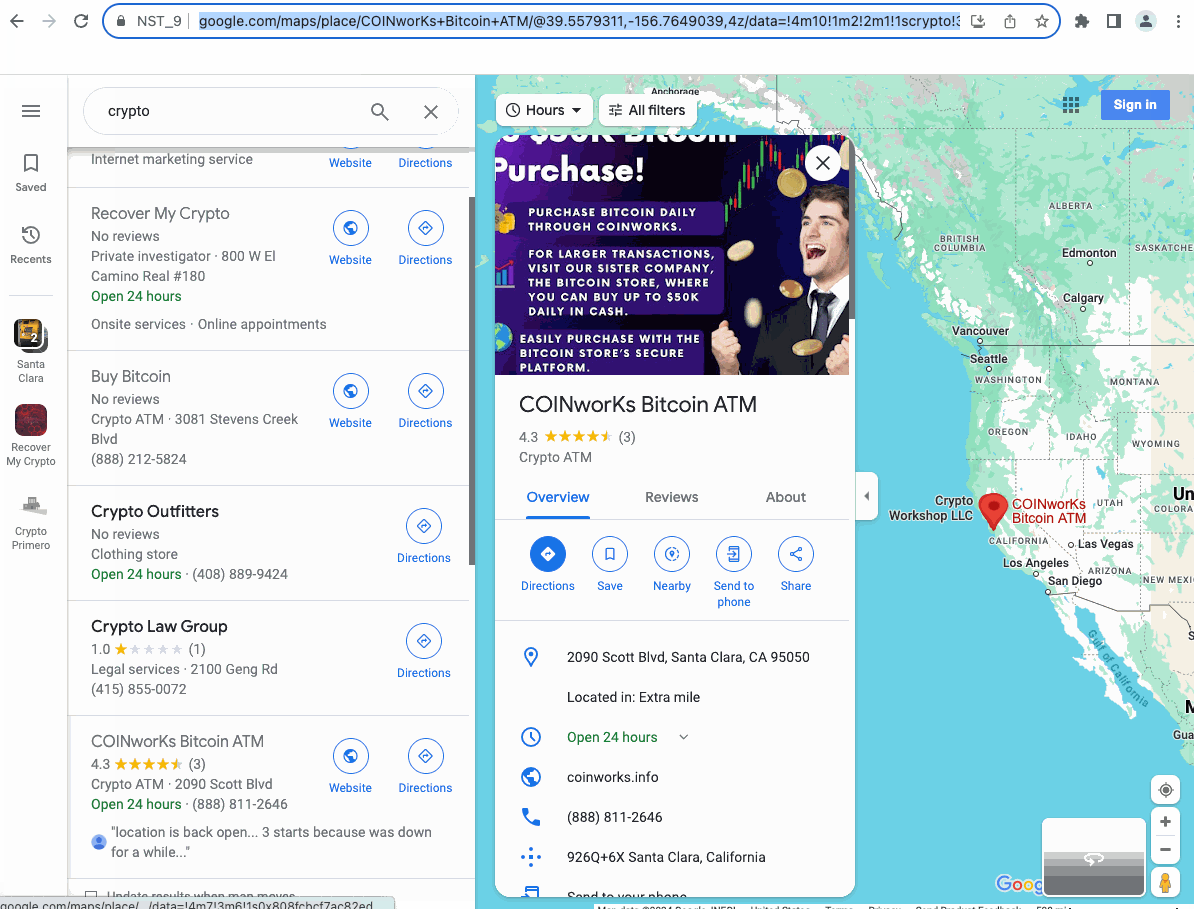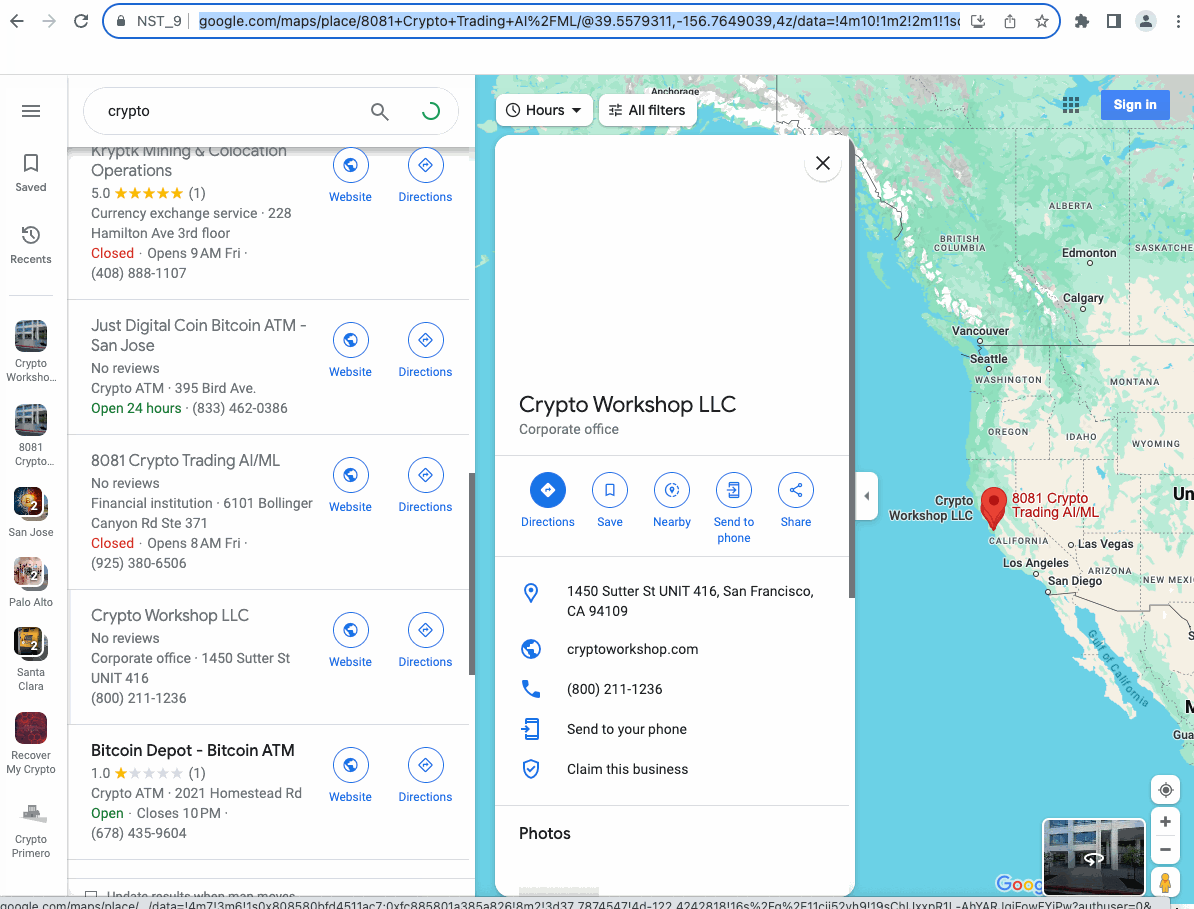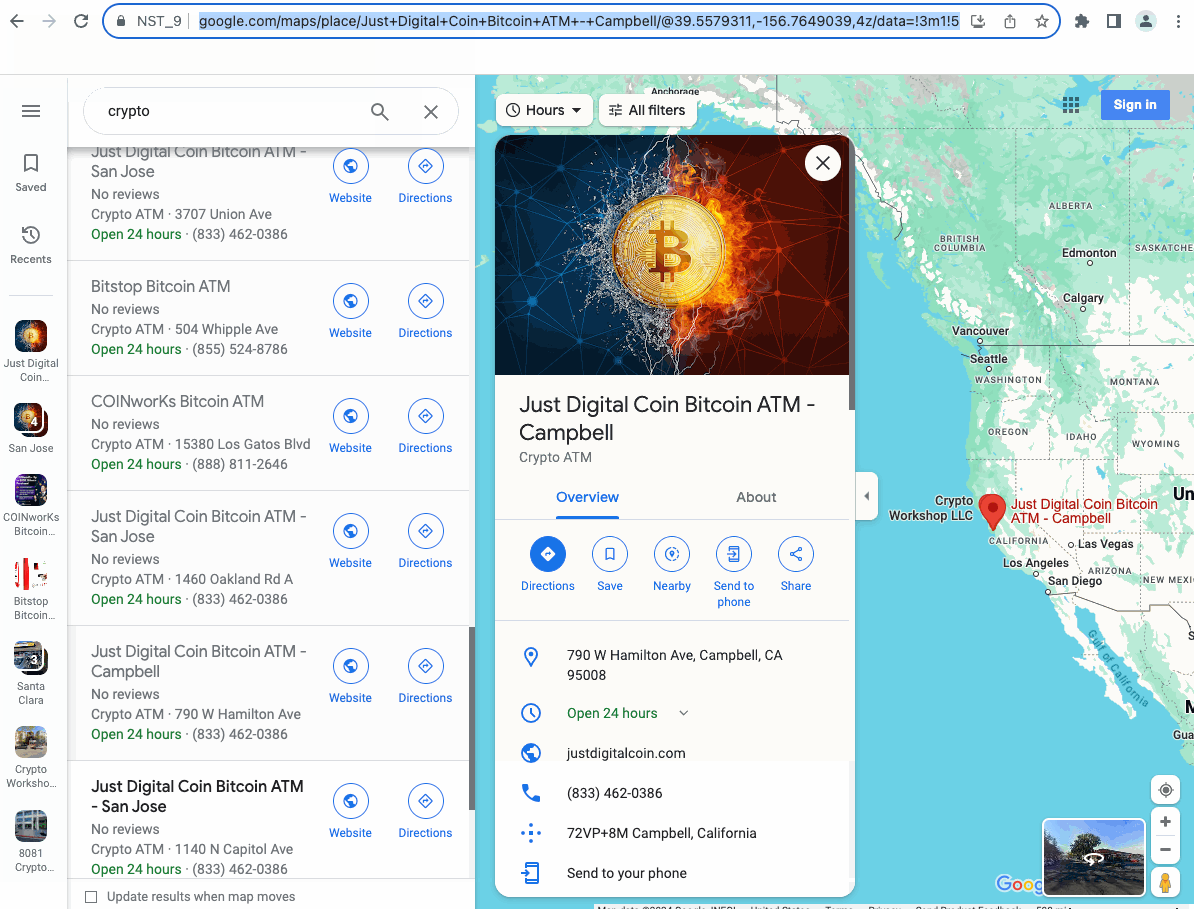
执行完成之后,让我们看看我们搜集的结果:
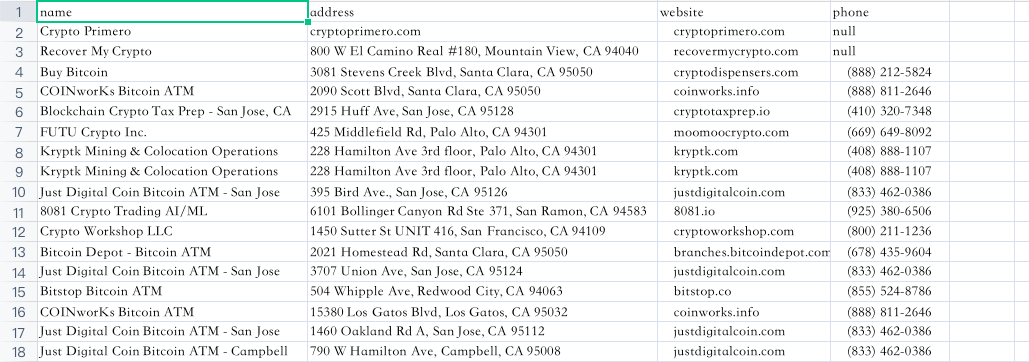
是不是非常炫酷,只需要配置一次workflow,然后随时就可以进行数据爬取了,这就是Nstbrowser RPA的能力。
马上使用Nstbrowser!
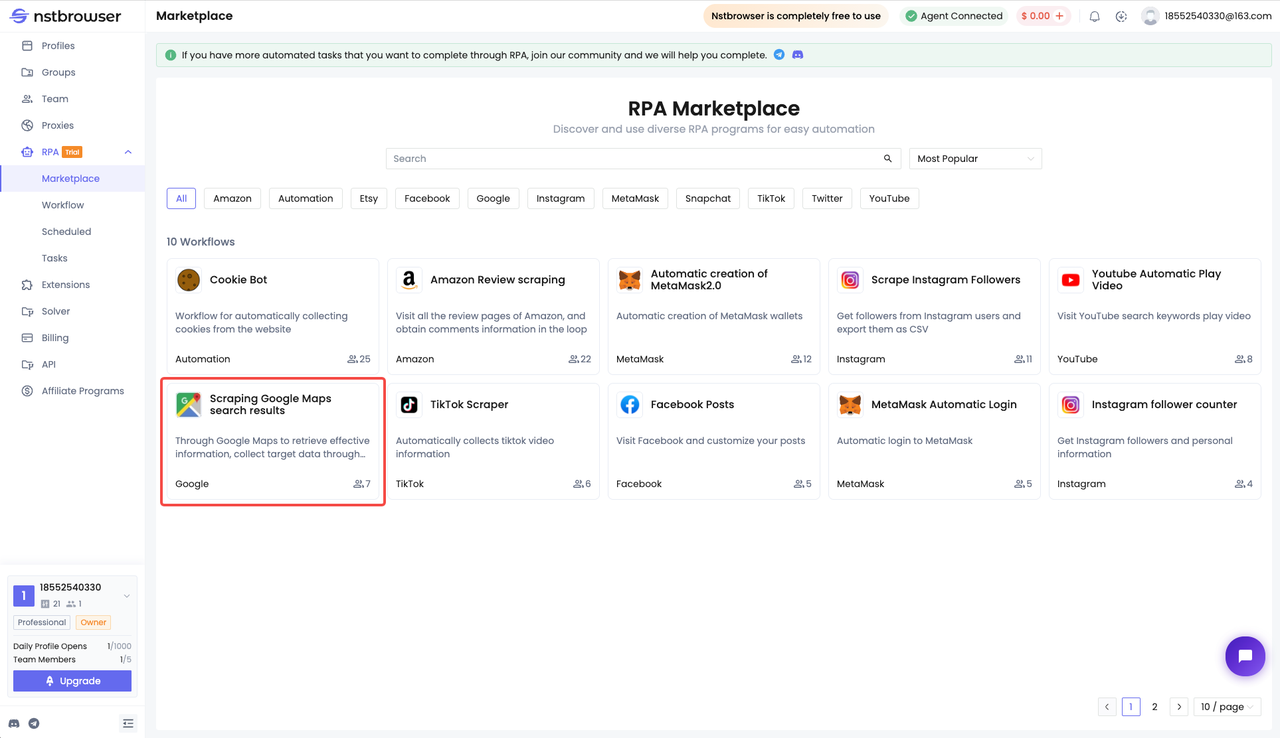
现在Google地图搜索结果爬取的功能已经在Nstbrowser RPA商店中上架,您可以进入RPA商店直接获取它!只需要在获取后修改您想要搜索的内容和您想要保存的文件的路径,就可以开启您的RPA爬虫之旅了。
更多





