
Headless Browser
Trình duyệt không đầu: Làm thế nào để chạy nó trong Puppeteer?
Quét web thật dễ dàng với headlesschrome! Trình duyệt không đầu là gì? Tại sao Puppeteer thích hợp cho việc quét web? Tìm hiểu thông tin cụ thể từ hướng dẫn này.
Jul 18, 2024Tạ Quí Lĩnh
Chrome không đầu là gì?
Chúng ta đều biết rằng giao diện người dùng hoặc UI là phần quan trọng nhất của bất kỳ phần mềm nào. Do đó, phần "không đầu" trong "trình duyệt không đầu" có nghĩa là chúng thiếu một yếu tố chính, đó là giao diện người dùng đồ họa (GUI).
Điều này có nghĩa là trình duyệt có thể hoạt động bình thường ở phía sau (liên lạc với trang web mục tiêu, tải lên/xuống tài liệu, hiển thị thông tin, vv.) nhưng bạn không thể nhìn thấy bất cứ điều gì.
Thay vào đó, kỹ sư kiểm thử phần mềm thích sử dụng giao diện như "dòng lệnh", nơi các lệnh được xử lý dưới dạng các dòng văn bản.
Làm thế nào để phát hiện headlesschrome?
Một trình duyệt chống nhận diện bạn cần.
Ví dụ về các trình duyệt không đầu
- Headlesschrome
- Chromium
- Firefox Headless
- HTML Unit
- Apple Safari (Webkit)
- Zombie.JS
- PhantomJS
- Splash
Tại sao Puppeteer là tốt nhất cho web scraping?
Puppeteer là một thư viện mã nguồn mở dành cho Node.js do Google phát triển, cung cấp một API cấp cao để điều khiển các trình duyệt Chrome hoặc Chromium không đầu. Dưới đây là 7 lợi ích giải thích tại sao các nhà phát triển thích sử dụng nó để thực hiện web scraping.
1. Tự động hóa headlesschrome
Puppeteer vận hành một phiên bản không đầu của Google Chrome, điều này có nghĩa là nó có thể chạy mà không cần giao diện người dùng đồ họa. Điều này cho phép scraping nhanh hơn và hiệu quả hơn vì nó giảm thiểu overhead liên quan đến việc hiển thị cửa sổ trình duyệt đầy đủ.
2. Thực thi JavaScript
Nhiều trang web hiện đại phụ thuộc nặng nề vào JavaScript để tải nội dung một cách động. Các công cụ scraping truyền thống thường gặp khó khăn với các trang web như vậy. Tuy nhiên, Puppeteer có thể thực thi JavaScript giống như một trình duyệt thực sự, đảm bảo rằng tất cả nội dung động được tải hoàn toàn và có sẵn để scraping.
3. API chất lượng cao
Puppeteer cung cấp một API chất lượng cao cho phép kiểm soát chính xác trên trình duyệt. Điều này bao gồm các hành động như nhấp vào nút, điền vào biểu mẫu và điều hướng qua các trang, điều này rất quan trọng đối với việc scraping các trang web phức tạp.
4. Chụp ảnh tự động
Một trong những tính năng của Puppeteer là khả năng chụp ảnh tự động. Điều này có thể hữu ích để gỡ lỗi và xác nhận rằng nội dung đã được tải đúng cách trước khi scraping.
5. Kiểm thử chéo trình duyệt
Puppeteer hỗ trợ kiểm thử chéo trình duyệt, điều này có nghĩa là bạn có thể kiểm tra và scraping các trang web trên các trình duyệt khác nhau như Chrome và Firefox. Điều này giúp đảm bảo rằng các kịch bản scraping của bạn là mạnh mẽ và có thể xử lý các môi trường web khác nhau.
6. Cộng đồng và tiện ích mở rộng
Puppeteer có một cộng đồng mạnh mẽ và tích hợp tốt với các công cụ khác như TeamCity, Jenkins và TravisCI. Điều này làm cho việc tìm kiếm hỗ trợ và các tiện ích mở rộng có thể cải thiện các nhiệm vụ scraping của bạn dễ dàng hơn.
7. Mô phỏng tương tác người dùng thực
Puppeteer có thể mô phỏng các tương tác người dùng thực như di chuyển chuột và nhập từ bàn phím. Điều này làm cho việc các trang web phát hiện và chặn các hoạt động scraping khó hơn, vì các tương tác này trông giống như con người hơn.
Giải pháp web scraping tốt nhất - Miễn phí Nstbrowser
Mở khóa các trang web và vượt qua phát hiện chống bot với nhiều giải pháp.
Truy cập mượt mà vào 99.9% các trang web không bị chặn.
Bạn có suy nghĩ hoặc câu hỏi nào về việc thu thập dữ liệu web và Browseless không?
Hãy đến xem những gì các nhà phát triển khác đang chia sẻ trên Discord và Telegram!
Làm thế nào để scraping một trang web với Puppeteer?
Bây giờ, tôi sẽ chỉ cho bạn cách sử dụng Nstbrowserless để hoàn thành việc scraping!
Ý nghĩa của điều này là gì?
Nói cách khác, chúng ta cần sử dụng Nstbrowser, một trình duyệt chống nhận diện, và thiết lập chế độ không đầu trong container docker để thu thập dữ liệu trang web.
Hãy lấy ví dụ về scraping địa chỉ liên kết video trên trang Trang khám phá của trang chủ Tiktok như sau:
Bạn có thể thích: Làm thế nào để scraping Avatar với Playwright.
Bước 1. Phân tích trang
Chúng ta cần:
- Đi tới trang chủ TikTok.
- Mở trang phần tử console và xác định phần tử trang Khám phá. Phần tử này là thẻ phần tử liên kết
avới thuộc tínhdata-e2e="nav-explore".
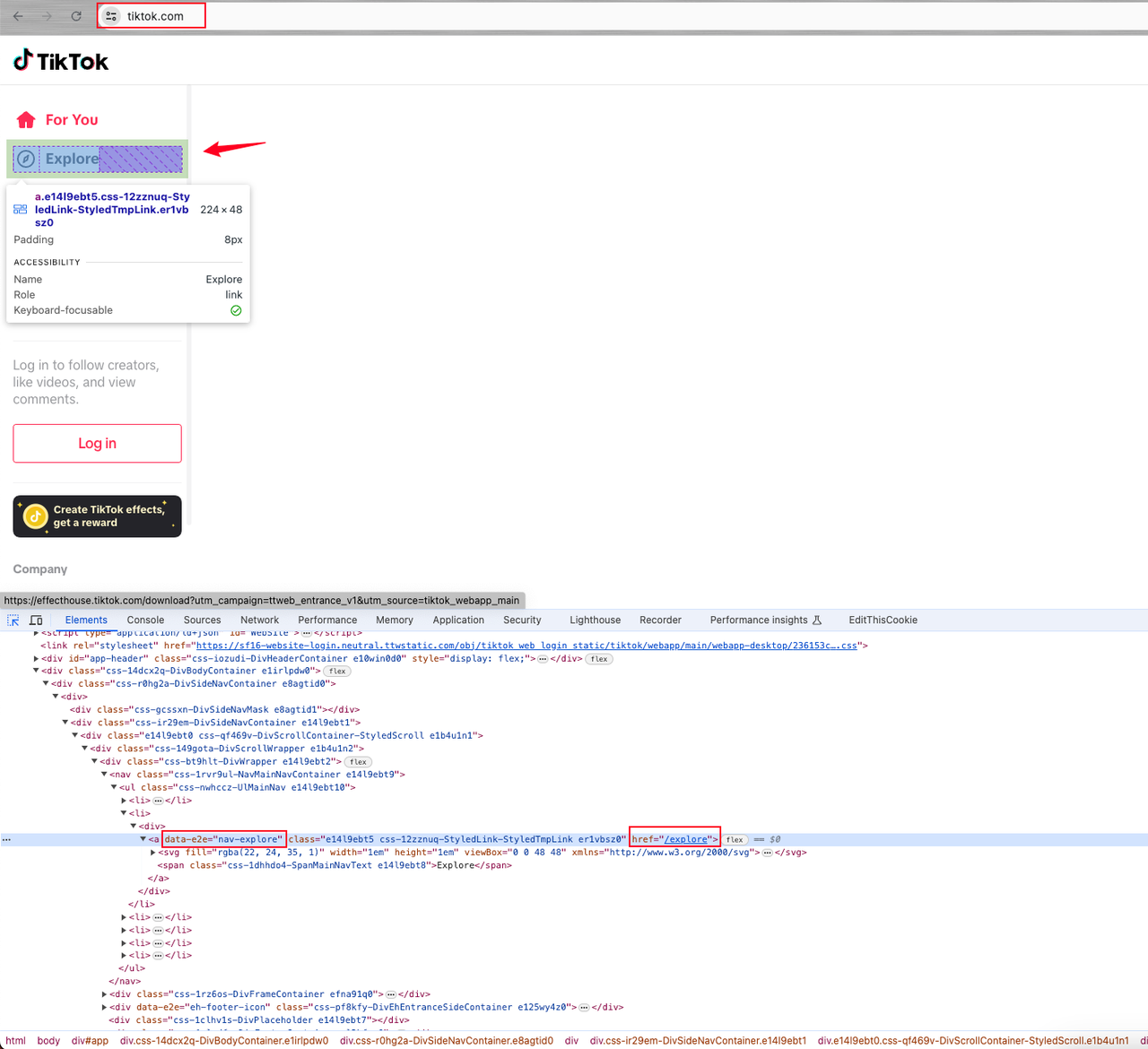
Nhấp vào phần tử trên để vào trang xem trước để phân tích thêm.
Chúng ta có thể thấy rằng dữ liệu mục tiêu chúng ta muốn thuộc về một mục phần tử div dưới một phần tử danh sách có thuộc tính data-e2e="explore-item-list".
Mỗi phần tử video được đại diện bởi data-e2e="explore-item", và liên kết video chúng ta muốn là giá trị thuộc tính href của thẻ liên kết div a dưới đó.
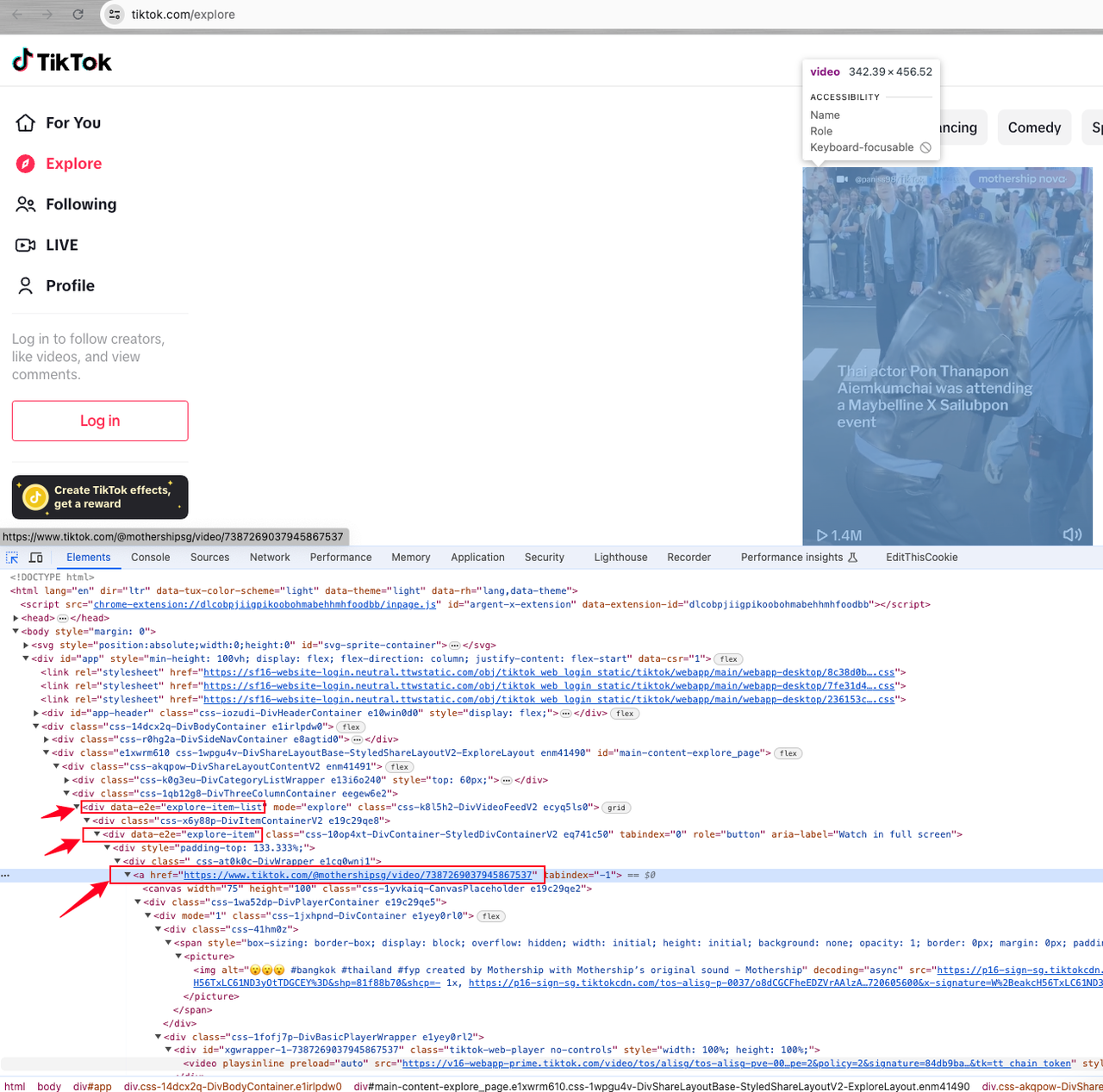
Sau khi thành công trong việc xác định các phần tử chúng ta cần, chúng ta có thể tiến hành quá trình scraping của mình:
Bước 2. Để sử dụng Nstbrowserless, bạn cần cài đặt và chạy Docker trước.
Shell
# kéo hình ảnh
docker pull nstbrowser/browserless:0.0.1-beta
# chạy nstbrowserless
docker run -it -e TOKEN=xxx -e SERVER_PORT=8848 -p 8848:8848 --name nstbrowserless nstbrowser/browserless:0.0.1-betaBước 3. Lập trình (Python-Pyppeteer)
Bây giờ chúng ta cần thiết lập Nstbrowser vào chế độ không đầu
Python
import json
from urllib.parse import urlencode
from pyppeteer import launcher
async def main():
config = {
"once": True,
"headless": True, # hỗ trợ: true hoặc false
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # các đối số trình duyệt phải là một danh sách
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # hỗ trợ: windows, mac, linux
"kernel": 'chromium', # chỉ hỗ trợ: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # hỗ trợ: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # hỗ trợ: 2, 4, 8
},
}
query = {
'config': json.dumps(config)
}
browser = await launcher.connect(
browserWSEndpoint=f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
)
page = await browser.newPage()
await page.goto('chrome://version')
await page.screenshot({'path': 'chrome_version.png'})
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Sau khi chạy mã trên, bạn có thể thấy thông tin sau trên trang chrome://version:

Thêm --headless parameter vào lệnh khởi động kernel chỉ ra rằng kernel đang chạy trong chế độ không đầu.
Hiển thị mã tổng thể:
Python
import json
from urllib.parse import urlencode
from pyppeteer import launcher
async def main():
config = {
"once": True,
"headless": True, # hỗ trợ: true hoặc false
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # các đối số trình duyệt phải là một danh sách
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # hỗ trợ: windows, mac, linux
"kernel": 'chromium', # chỉ hỗ trợ: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # hỗ trợ: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # hỗ trợ: 2, 4, 8
},
"proxy": "", # thiết lập proxy phù hợp nếu bạn không thể khám phá trang web TikTok
}
query = {
'config': json.dumps(config)
}
browser = await launcher.connect(
browserWSEndpoint=f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
)
try:
# Tạo một trang mới
page = await browser.newPage()
await page.goto("https://www.tiktok.com/")
await page.waitForSelector('[data-e2e="nav-explore"]', {'timeout': 30000})
explore_elem = await page.querySelector('[data-e2e="nav-explore"]')
if explore_elem:
await explore_elem.click()
await page.waitForSelector('[data-e2e="explore-item-list"]', {'timeout': 30000})
ul_element = await page.querySelector('[data-e2e="explore-item-list"]')
if ul_element:
li_elements = await ul_element.querySelectorAll('div')
hrefs = []
for li in li_elements:
a_element = await li.querySelector('[data-e2e="explore-item"] div a')
if a_element:
href = await page.evaluate('(element) => element.getAttribute("href")', a_element)
if href:
print(href)
hrefs.append(href)
# TODO
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Kết quả scraping:
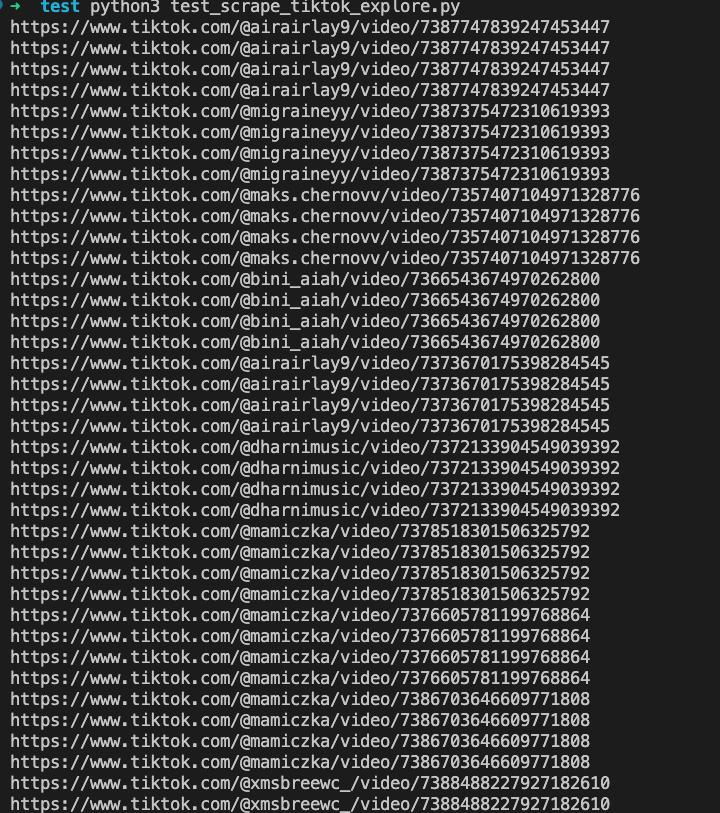
Đến đây, chúng ta đã hoàn thành việc crawling liên kết video TikTok bằng Nstbrowserless. Sau khi nhận được liên kết, bạn có thể tiến hành các thao tác bạn muốn, chẳng hạn như lưu trữ, tải xuống video hoặc chuyển hướng phát lại.
Tất nhiên, đây chỉ là một ví dụ rất đơn giản. Nếu bạn muốn crawling nội dung nhiều hơn, hãy sử dụng Nstbrowser để nghiên cứu và thực hiện mọi thao tác một cách dễ dàng.
Headlesschrome luôn là tốt?
Mặc dù trình duyệt không đầu rất quan trọng trong web scraping và tự động hóa, nhưng thực tế không phải lúc nào cũng tốt. Vui lòng cân nhắc các ưu và nhược điểm sau một cách cẩn thận trước khi sử dụng nó:
Ưu điểm:
- Headlesschrome hiệu quả hơn khi trích xuất các điểm dữ liệu cụ thể từ một trang web mục tiêu, chẳng hạn như giá cả sản phẩm đối thủ.
- Trình duyệt không đầu nhanh hơn so với các trình duyệt thông thường - chúng tải CSS và JavaScript nhanh hơn và không cần mở và render HTML.
- Trình duyệt không đầu tiết kiệm thời gian cho các nhà phát triển, ví dụ như khi thực hiện các thay đổi mã thử nghiệm đơn vị (di động và desktop), có thể thực hiện bằng dòng lệnh.
Nhược điểm:
- Hoạt động của trình duyệt không đầu giới hạn trong các nhiệm vụ backend, điều này có nghĩa là nó không thể giúp đỡ với các vấn đề frontend (ví dụ như tạo ảnh chụp GUI).
- Trình duyệt không đầu tăng tốc, nhưng đôi khi có một số chi phí, ví dụ như việc phát hiện phát hiện khái niệm cho một số các trang web.
Tóm lại
Trình duyệt không đầu cung cấp nhiều lợi ích cho quá trình web scraping, cho phép bạn scrape và tự động hóa quy trình chỉ với vài dòng code. Nó giảm thiểu việc sử dụng bộ nhớ, xử lý JavaScript hoàn hảo và chạy trong môi trường không có giao diện đồ họa.
Trong hướng dẫn này, bạn đã học được:
- Headless là gì?
- Các lợi ích của Puppeteer trong web scraping
- Các bước chi tiết cho web scraping với Puppeteer
Ngoài ra, Nstbrowser có thể dễ dàng tránh phát hiện robot, mở khóa trang web và đơn giản hóa web scraping và tự động hóa.
Hơn





