
Пакет прокси до75% СКИДКИ+15% Бонусс кодом

Использование Node.js для веб-скрепинга является обычной потребностью, независимо от того, хотите ли вы собирать данные с веб-сайта для анализа или отображать их на своем собственном сайте. Node.js - отличный инструмент для этой задачи.
Читая эту статью, вы узнаете:
Веб-скрепинг - это процесс извлечения данных с веб-сайтов. Он включает использование инструментов или программ для имитации поведения браузера и извлечения необходимых данных с веб-страниц. Этот процесс также известен как веб-харвестинг или извлечение веб-данных.
Веб-скрепинг имеет много преимуществ, таких как:
"Node.js" - это среда выполнения JavaScript с открытым исходным кодом, кроссплатформенная, которая выполняет JavaScript-код на стороне сервера. Созданный Райаном Далем в 2009 году, он построен на движке JavaScript V8 Chrome. Node.js предназначен для создания высокопроизводительных, масштабируемых сетевых приложений, особенно тех, которые обрабатывают большое количество одновременных подключений, таких как веб-серверы и приложения реального времени.
Node.js - популярная среда выполнения JavaScript, которая позволяет использовать JavaScript для серверной разработки. Использование Node.js для веб-скрепинга предлагает несколько преимуществ:
Без лишних слов давайте начнем скрапинг данных с Node.js!
Сначала загрузите и установите Node.js с его официального веб-сайта. Следуйте подробным инструкциям по установке для вашей операционной системы.
Node.js предлагает множество библиотек для веб-скрепинга, таких как Request, Cheerio и Puppeteer. Здесь мы будем использовать Puppeteer в качестве примера. Установите Puppeteer с помощью npm следующими командами:
mkdir web-scraping && cd web-scraping
npm init -y
npm install puppeteer-coreСоздайте файл, например, index.js, в каталоге вашего проекта и добавьте следующий код:
goTo используется для открытия веб-страницы. Он принимает два параметра: URL веб-страницы для открытия и объект конфигурации. Мы можем установить различные параметры в этом объекте, такие как waitUntil, который указывает вернуться после завершения загрузки страницы.waitForSelector используется для ожидания появления селектора. Он принимает селектор в качестве параметра и возвращает объект Promise, когда селектор появляется на странице. Мы можем использовать этот объект Promise для определения, появился ли селектор.content используется для получения содержимого страницы. Он возвращает объект Promise, который мы можем использовать для извлечения содержимого страницы.page.$eval используется для получения текстового содержимого селектора. Он принимает два параметра: первый - селектор, а второй - функция, которая будет выполнена в браузере. Эта функция позволяет нам извлекать текстовое содержимое селектора.const puppeteer = require('puppeteer');
async function run() {
const browser = await puppeteer.launch({
headless: false,
ignoreHTTPSErrors: true,
});
const page = await browser.newPage();
await page.goto('https://airbnb.com/experiences/1653933', {
waitUntil: 'domcontentloaded',
});
await page.waitForSelector('h1');
await page.content();
const title = await page.$eval('h1', (el) => el.textContent);
console.log(title);
await browser.close();
}
run();Запустите index.js с помощью следующей команды:
node index.jsПосле запуска сценария вы увидите вывод в терминале:

В этом примере мы используем puppeteer.launch(), чтобы создать экземпляр браузера, browser.newPage(), чтобы создать новую страницу, page.goto(), чтобы открыть веб-страницу, page.waitForSelector(), чтобы дождаться появления селектора, и page.$eval(), чтобы получить текстовое содержимое селектора.
Кроме того, мы можем перейти на обработанный сайт через браузер, открыть инструмент разработчика, а затем использовать селектор для поиска нужного элемента, сравнивая содержимое элемента с тем, что мы получаем в коде, чтобы обеспечить согласованность.
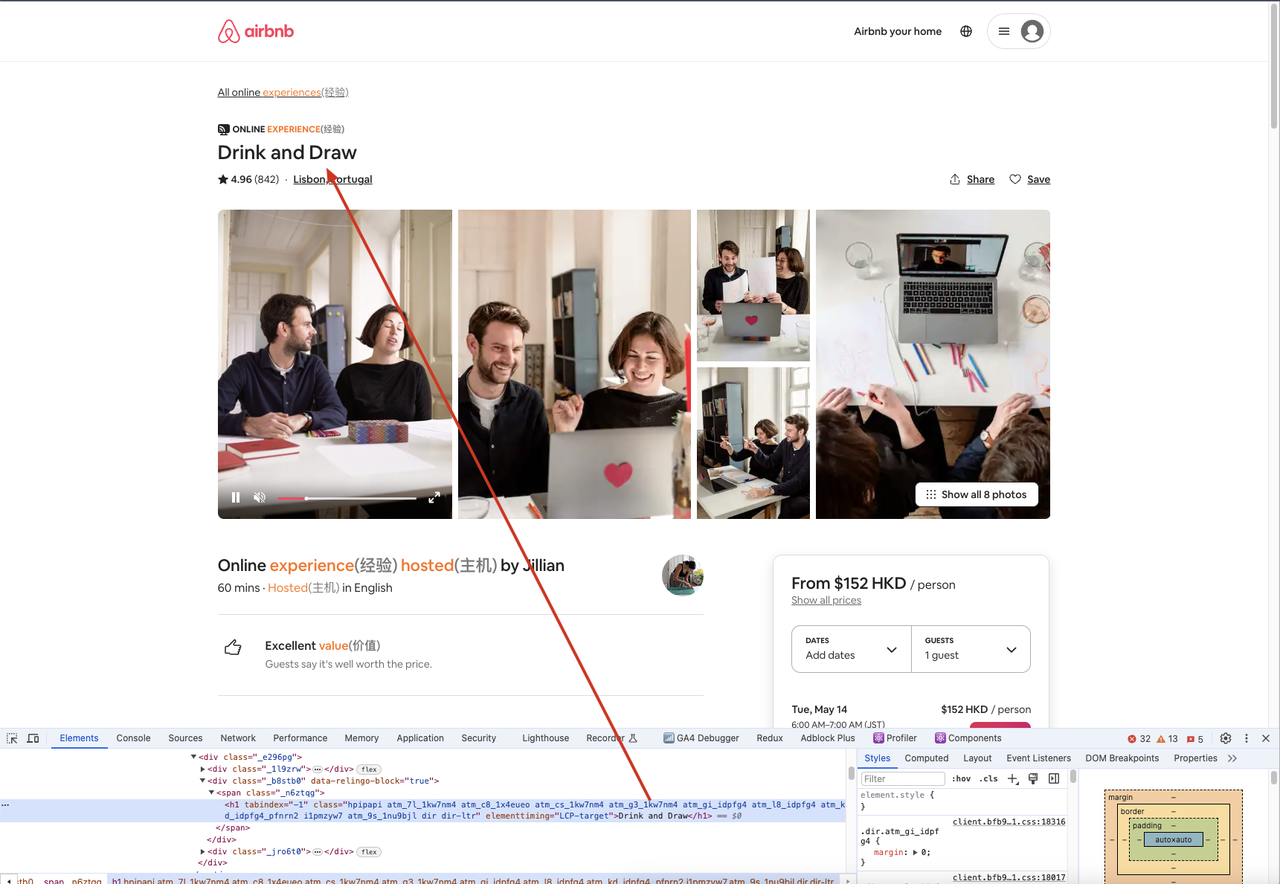
При использовании Puppeteer для веб-скрепинга некоторые веб-сайты могут обнаружить вашу деятельность по скрепингу и вернуть ошибки, такие как 403 Forbidden. Чтобы избежать обнаружения, вы можете использовать различные техники, такие как:
Эти методы помогают обойти обнаружение, позволяя вашим задачам по веб-скрепингу продолжаться без проблем. Для более продвинутых техник противодействия обнаружению рассмотрите использование инструментов, таких как Nstbrowser - продвинутый браузер с антидетекцией.





