
Web Scraping
Как использовать Go для веб-скраппинга?
Язык Go, также известный как Golang, обеспечивает высокую скорость компиляции и производительность во время выполнения. Из этого пошагового руководства вы узнаете, как делать веб-скраппинг с помощью Go.
May 20, 2024
Go, также известный как Golang, — это язык программирования с открытым исходным кодом, разработанный Google для повышения эффективности и скорости программирования, особенно при работе с параллельными задачами. Go сочетает в себе преимущества статически типизированных и динамически типизированных языков, обеспечивая быструю компиляцию и высокую производительность во время выполнения.
Как создать веб-скрейпер с использованием библиотеки Colly на языке программирования Go? Nstbrowser проведет вас через код, чтобы понять каждую часть.
Не будем терять время! Разберем подробные шаги сейчас.
Почему стоит использовать Go для веб-скрейпинга?
- Простой и лаконичный. Синтаксис Go разработан таким образом, чтобы быть простым и легким для изучения и использования, снижая сложность кода.
- Встроенная поддержка параллелизма. Go предоставляет мощные возможности параллельного программирования через горутины и каналы, что облегчает разработку высокопроизводительных параллельных приложений.
- Сборка мусора. Go имеет автоматический механизм сборки мусора, который помогает управлять памятью и повышает эффективность разработки.
Подготовка
Установка Go
Перед тем как начинать скрейпинг, давайте настроим наш проект на Go. Я потрачу несколько секунд на обсуждение того, как его установить. Так что, если вы уже установили Go, проверьте это снова.
В зависимости от вашей операционной системы, вы можете найти инструкции по установке на странице документации Go. Если вы используете macOS и Brew, вы можете выполнить установку в Терминале:
bash
brew install goСборка проекта
Создайте новый каталог для вашего проекта, перейдите в этот каталог и выполните следующую команду, где вы можете заменить слово webscraper на любое название модуля по вашему выбору.
bash
go mod init webscraper- Примечание: Команда
go mod initсоздает новый модуль Go в каталоге, где она выполняется. Она создает новый файлgo.mod, который определяет зависимости и управляет версиями сторонних пакетов, используемых в проекте (аналогично package.json в Node).
Теперь вы можете настроить свои скрипты для веб-скрейпинга на Go. Создайте файл scraper.go и инициализируйте его следующим образом:
go
package main
import (
"fmt"
)
func main() {
// scraping logic...
fmt.Println("Hello, World!")
}Первая строка содержит имя глобального пакета. Затем идут некоторые импорты, за которыми следует функция main(). Это точка входа для любой программы на Go, которая будет содержать логику веб-скрейпинга на Golang. Затем вы можете запустить программу:
bash
go run scraper.goЭто выведет:
PlainText
Hello, World!Теперь, когда вы создали базовый проект на Go, давайте углубимся в создание веб-скрейпера с использованием Golang!
Создание веб-скрейпера с Go
Далее, давайте рассмотрим ScrapeMe как пример того, как выполнять скрейпинг страницы с Go.
Шаг 1. Установка Colly
Для того чтобы упростить создание веб-скрейпера, вам следует использовать одну из ранее представленных библиотек. Однако, в самом начале вам нужно определить, какая библиотека для веб-скрейпинга на Go лучше всего подходит для ваших целей.
Для этого вам нужно:
- Посетить ваш целевой веб-сайт.
- Щелкнуть правой кнопкой мыши на фоне.
- Выбрать опцию Inspect. Это откроет DevTools в вашем браузере.
- Во вкладке Network посмотрите раздел Fetch/XHR.
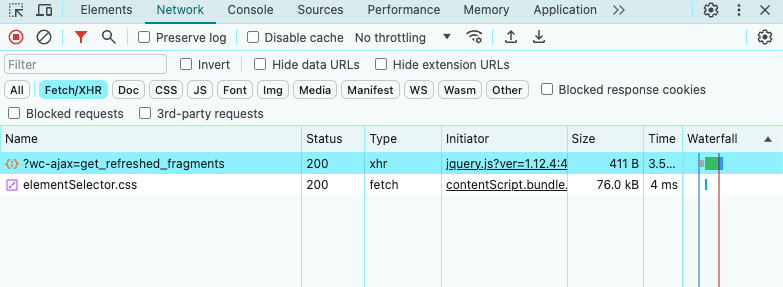
Как видно выше, целевая страница выполняет только несколько AJAX-запросов. Если вы изучите каждый XHR-запрос, вы заметите, что они не возвращают никаких значимых данных. Другими словами, сервер возвращает HTML-документ, который уже содержит все данные. Это обычно происходит с сайтами со статическим контентом.
Это означает, что целевой сайт не полагается на JavaScript для динамического извлечения данных или их отображения. Следовательно, вам не нужна библиотека с возможностями безголового браузера для извлечения данных с целевой страницы. Вы все еще можете использовать Selenium, но это только введет накладные расходы на производительность. По этой причине вы должны предпочесть простой HTML-парсер, такой как Colly.
Теперь давайте установим colly и его зависимости:
bash
go get github.com/gocolly/collyЭта команда также обновит файл go.mod всеми необходимыми зависимостями и создаст файл go.sum.
Colly — это пакет Go, который позволяет вам писать веб-скрейперы и краулеры, построенные на основе пакета net/HTTP для сетевого взаимодействия, и помогает использовать
goquery, который предоставляет синтаксис, похожий на jQuery, для позиционирования HTML-элементов.
Прежде чем начать его использование, вам нужно разобраться с некоторыми ключевыми концепциями Colly:
Основной сущностью в Colly является Collector, объект, который позволяет выполнять HTTP-запросы и осуществлять веб-скрейпинг с помощью следующих обратных вызовов:
OnRequest(): вызывается перед любым HTTP-запросом с использованием Visit().OnError(): вызывается, если в HTTP-запросе происходит ошибка.OnResponse(): вызывается после получения ответа от сервера.OnHTML(): вызывается после OnResponse(), если сервер возвращает допустимый HTML-документ.OnScraped(): вызывается в конце всех вызовов OnHTML().
Каждая из этих функций принимает обратный вызов в качестве параметра. Colly выполняет переданный обратный вызов, когда происходит событие, связанное с функцией. Таким образом, чтобы построить скрейпер данных в Colly, вам нужно следовать подходу, основанному на функциях обратного вызова.
Вы можете использовать функцию NewCollector() для инициализации объекта Collector:
go
c := colly.NewCollector()Импортируйте Colly и создайте Collector, обновив scraper.go следующим образом:
go
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
// scraping logic...
}Шаг 2. Подключение к целевому веб-сайту
Используйте Colly для подключения к целевой странице с помощью:
go
c.Visit("https://scrapeme.live/shop/")В фоновом режиме функция Visit() выполняет HTTP GET-запрос и извлекает целевой HTML-документ с сервера. Конкретно, она вызывает событие onRequest и запускает жизненный цикл функции Colly. Помните, что Visit() должна вызываться после регистрации других обратных вызовов Colly.
Обратите внимание, что HTTP-запрос, сделанный с помощью Visit(), может завершиться неудачей. Когда это происходит, Colly вызывает событие OnError. Причиной этой неудачи может быть временно недоступный сервер или недействительный URL, а веб-скрейперы часто терпят неудачу, когда целевой сайт применяет меры против роботов. Например, такие техники обычно фильтруют запросы, которые не имеют действительного заголовка User-Agent HTTP.
Что вызывает это?
Обычно Colly устанавливает временный User-Agent, который не соответствует прокси, используемому популярными браузерами. Это делает запросы Colly легко идентифицируемыми анти-скрейпинговыми технологиями. Чтобы избежать блокировки, укажите действительный заголовок User-Agent в Colly, как показано ниже:
go
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"Ищете более эффективное решение?
Nstbrowser предоставляет полноценный API для веб-скрейпинга, который поможет вам справиться со всеми препятствиями, связанными с анти-бот системами.
Попробуйте совершенно бесплатно!
Есть ли у вас хорошие идеи или вопросы о веб-скрейпинге и Browserless?
Посмотрите чем делятся другие разработчики в Discord и Telegram!
Любой вызов Visit() теперь будет выполнять запрос с этим заголовком HTTP.
Ваш файл scraper.go теперь должен выглядеть следующим образом:
go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// creating a new Colly instance
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
// visiting the target page
c.Visit("https://scrapeme.live/shop/")
// scraping logic...
}Шаг 3. Изучение HTML-страницы и захват данных
Теперь нам нужно просмотреть и проанализировать DOM целевой веб-страницы, чтобы найти данные, которые мы хотим скрейпить. В результате мы сможем применить эффективную стратегию извлечения данных.
- Щелкните правой кнопкой мыши на одном из HTML-элементов и выберите "Inspect":
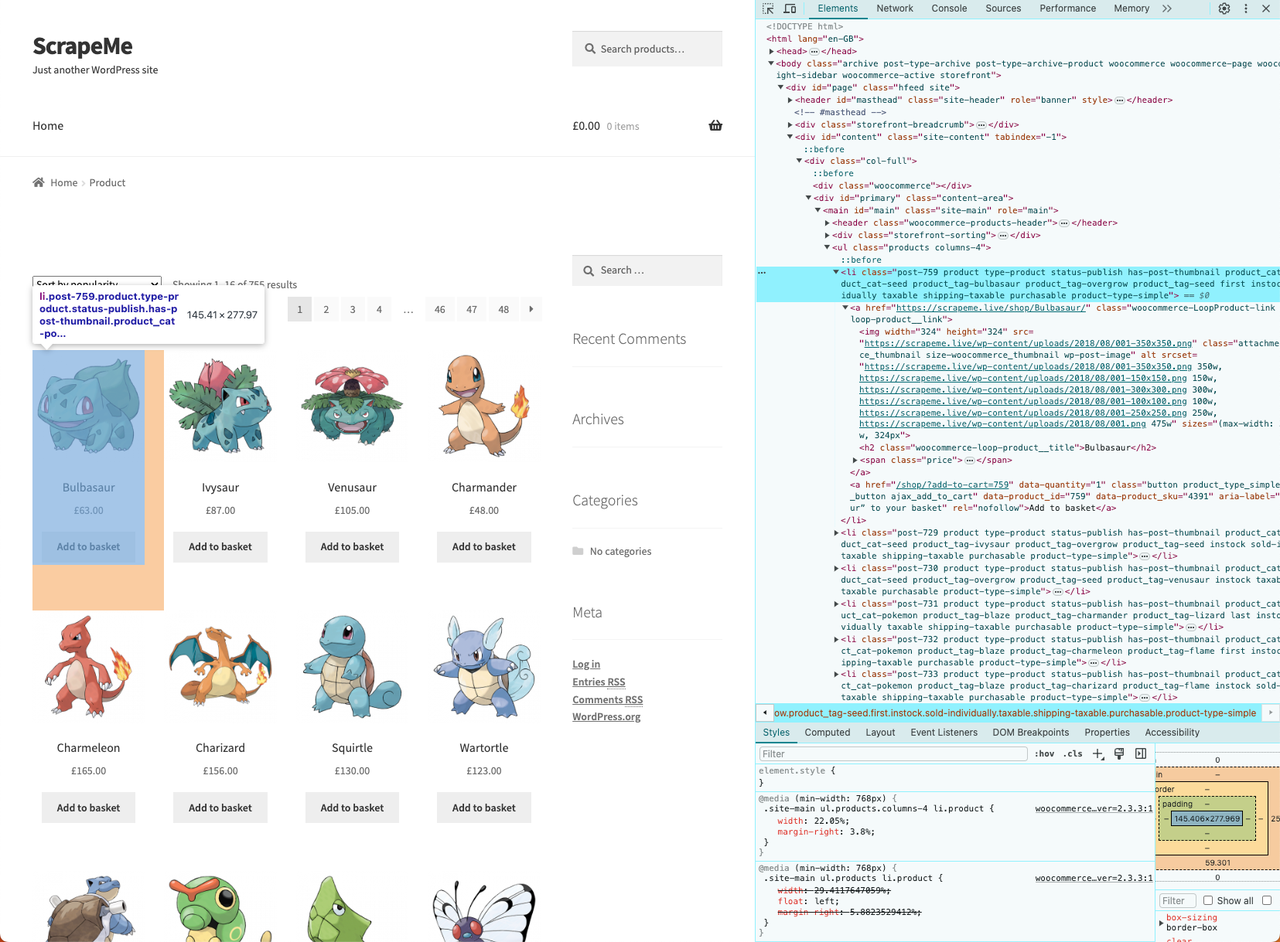
Мы выяснили его HTML-структуру. Перед тем как начинать скрейпинг, нужно создать структуру данных для хранения скрейпнутых данных.
- Определите структуру
PokemonProductследующим образом:
go
// defining a data structure to store the scraped data
type PokemonProduct struct {
url, image, name, price string
}- Затем инициализируйте срез
PokemonProduct, который будет содержать скрейпнутые данные:
go
// initializing the slice of structs that will contain the scraped data
var pokemonProducts []PokemonProductВ Go срезы предоставляют эффективный способ работы с последовательностями типизированных данных. Вы можете рассматривать их как нечто вроде списков.
- Теперь реализуйте логику скрейпинга:
go
// iterating over the list of HTML product elements
c.OnHTML("li.product", func(e *colly.HTMLElement) {
// initializing a new PokemonProduct instance
pokemonProduct := PokemonProduct{}
// scraping the data of interest
pokemonProduct.url = e.ChildAttr("a", "href")
pokemonProduct.image = e.ChildAttr("img", "src")
pokemonProduct.name = e.ChildText("h2")
pokemonProduct.price = e.ChildText(".price")
// adding the product instance with scraped data to the list of products
pokemonProducts = append(pokemonProducts, pokemonProduct)
})Интерфейс HTMLElement предоставляет методы ChildAttr() и ChildText(). Они позволяют извлекать текст соответствующего значения атрибута из дочернего объекта, идентифицированного селектором CSS. Настроив две простые функции, вы реализуете всю логику извлечения данных.
- Наконец, вы можете использовать
append()для добавления нового элемента в срез захваченного элемента.
Шаг 4. Преобразование захваченных данных в CSV
Логика для экспорта скрейпнутых данных в CSV файл с использованием Go выглядит следующим образом:
go
// opening the CSV file
file, err := os.Create("products.csv")
if err != nil {
log.Fatalln("Failed to create output CSV file", err)
}
defer file.Close()
// initializing a file writer
writer := csv.NewWriter(file)
// defining the CSV headers
headers := []string{
"url",
"image",
"name",
"price",
}
// writing the column headers
writer.Write(headers)
// adding each Pokemon product to the CSV output file
for _, pokemonProduct := range pokemonProducts {
// converting a PokemonProduct to an array of strings
record := []string{
pokemonProduct.url,
pokemonProduct.image,
pokemonProduct.name,
pokemonProduct.price,
}
// writing a new CSV record
writer.Write(record)
}
defer writer.Flush()- Примечание: Этот фрагмент кода создает файл products.csv и переименовывает его, используя столбец title. Затем он проходит по срезам захваченных PokemonProduct, преобразует каждый из них в новую запись CSV и добавляет её в CSV файл.
Чтобы этот фрагмент работал, убедитесь, что у вас есть следующие импорты:
go
import (
"encoding/csv"
"log"
"os"
// ...
)Полное представление кода
Вот полный код для scraper.go:
go
package main
import (
"encoding/csv"
"log"
"os"
"github.com/gocolly/colly"
)
// initializing a data structure to keep the scraped data
type PokemonProduct struct {
url, image, name, price string
}
func main() {
// initializing the slice of structs to store the data to scrape
var pokemonProducts []PokemonProduct
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
// creating a new Colly instance
c := colly.NewCollector()
// visiting the target page
c.Visit("https://scrapeme.live/shop/")
// scraping logic
c.OnHTML("li.product", func(e *colly.HTMLElement) {
pokemonProduct := PokemonProduct{}
pokemonProduct.url = e.ChildAttr("a", "href")
pokemonProduct.image = e.ChildAttr("img", "src")
pokemonProduct.name = e.ChildText("h2")
pokemonProduct.price = e.ChildText(".price")
pokemonProducts = append(pokemonProducts, pokemonProduct)
})
// opening the CSV file
file, err := os.Create("products.csv")
if err != nil {
log.Fatalln("Failed to create output CSV file", err)
}
defer file.Close()
// initializing a file writer
writer := csv.NewWriter(file)
// writing the CSV headers
headers := []string{
"url",
"image",
"name",
"price",
}
writer.Write(headers)
// writing each Pokemon product as a CSV row
for _, pokemonProduct := range pokemonProducts {
// converting a PokemonProduct to an array of strings
record := []string{
pokemonProduct.url,
pokemonProduct.image,
pokemonProduct.name,
pokemonProduct.price,
}
// adding a CSV record to the output file
writer.Write(record)
}
defer writer.Flush()
}Запустите ваш Go скрейпер данных с:
bash
go run scraper.goЗатем вы найдете файл products.csv в корневом каталоге вашего проекта. Откройте его, и там будет содержаться:
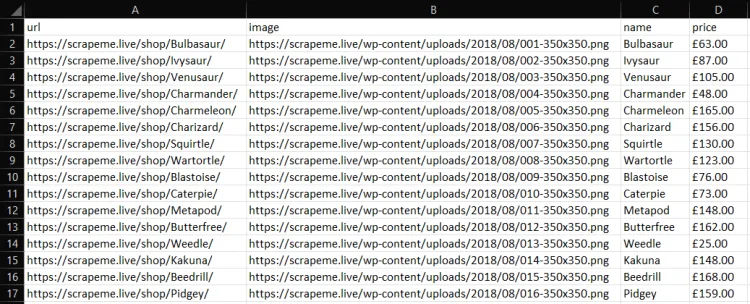
Другие эффективные библиотеки для веб-скрейпинга
- Nstbrowser: Оснащен комплексным API для веб-скрейпинга, он справляется со всеми препятствиями анти-бот систем для вас. Также разработан с использованием безголового браузера, обходом капчи и многими другими функциями.
- Chromedp: Более быстрый и простой способ управления браузерами, поддерживающими протокол Chrome DevTools.
- GoQuery: Библиотека Go, предлагающая синтаксис и набор функций, похожих на jQuery. Вы можете использовать её для веб-скрейпинга так же, как делали бы это в JQuery.
- Selenium: Вероятно, самый известный безголовый браузер, идеально подходящий для скрейпинга динамического контента. Он не предлагает официальную поддержку, но есть порт для использования его в Go.
- Ferret: Портативная, расширяемая и быстрая система для веб-скрейпинга, целью которой является упрощение извлечения данных из интернета. Ferret позволяет пользователям сосредоточиться на данных и основан на уникальном декларативном языке.
Выводы
В этом уроке вы:
- не только узнали, что такое веб-скрейпер,
- но и поняли, как создать собственное приложение для веб-скрейпинга, используя Colly и стандартные библиотеки Go.
Как видно из этого урока, веб-краулинг с Go можно выполнить с помощью нескольких строк чистого и эффективного кода.
Однако важно понимать, что извлечение данных из интернета не всегда просто. Существует множество проблем, с которыми вы можете столкнуться в процессе. Многие веб-сайты приняли анти-скрейпинг и анти-бот решения, которые могут обнаружить и заблокировать ваши скрипты для краулинга на Go.
Лучшая практика — использовать API для веб-скрейпинга, такой как Nstbrowser, совершенно бесплатное решение, которое позволяет вам обойти все анти-бот системы одним вызовом API, избавляя вас от проблем блокировки при выполнении задач по скрейпингу.
Больше





