
Paquete de Proxies hasta75% DTO+15% Bonocon

Todos sabemos que la interfaz de usuario (UI) es la parte más importante de cualquier software. Así, la palabra "sin cabeza" en "navegador sin cabeza" significa que realmente les falta un componente clave, es decir, la interfaz gráfica de usuario (GUI).
Esto significa que el propio navegador puede ejecutarse en segundo plano (conectarse al sitio web de destino, descargar/cargar documentos, renderizar información, etc.), pero no verás nada.
En cambio, los ingenieros de pruebas de software prefieren utilizar interfaces como la "línea de comandos", donde los comandos se manejan en forma de cadenas de texto.
¿Cómo detectar Chrome sin cabeza?
Necesitarás un navegador anti-detección.
Puppeteer es una biblioteca de Node.js de código abierto desarrollada por Google que proporciona una API de alto nivel para controlar el navegador sin cabeza Chrome o Chromium. Aquí hay 7 ventajas que explican por qué los desarrolladores prefieren usarlo para web scraping.
Puppeteer controla una versión sin cabeza de Google Chrome, lo que significa que puede ejecutarse sin una interfaz gráfica de usuario. Esto permite realizar el scraping de manera más rápida y eficiente, ya que se reduce la carga asociada con el renderizado de una ventana completa del navegador.
Muchos sitios modernos dependen en gran medida de JavaScript para cargar contenido dinámico. A las herramientas de scraping tradicionales les resulta difícil manejar estos sitios. Sin embargo, Puppeteer puede ejecutar JavaScript como un navegador real, asegurando que todo el contenido dinámico esté completamente cargado y sea accesible para el scraping.
Puppeteer proporciona una API de alta calidad que permite un control preciso del navegador. Esto incluye acciones como hacer clic en botones, rellenar formularios y navegar entre páginas, lo cual es especialmente importante para el scraping de sitios complejos.
Una de las funciones de Puppeteer es la capacidad de tomar capturas de pantalla automáticamente. Esto es útil para la depuración y para verificar que el contenido se cargue correctamente antes de realizar el scraping.
Puppeteer admite pruebas entre navegadores, lo que significa que puedes probar y hacer scraping en sitios web en diferentes navegadores (por ejemplo, Chrome y Firefox). Esta flexibilidad asegura la confiabilidad de tus scripts de scraping y su capacidad para funcionar en diversos entornos de red.
Puppeteer tiene una comunidad sólida y se integra bien con otras herramientas como TeamCity, Jenkins y TravisCI. Esto facilita encontrar soporte y extensiones para mejorar las tareas de scraping.
Puppeteer puede simular interacciones del usuario, como movimientos del ratón y entrada del teclado. Esto dificulta la detección y el bloqueo de las acciones de scraping, ya que estas interacciones parecen más humanas.
La mejor solución para web scraping: el navegador gratuito Nstbrowser
Usa múltiples soluciones para desbloquear sitios web y eludir las verificaciones anti-bot.
Acceso sin restricciones al 99.9% de los sitios no bloqueados.
¿Tienes ideas y dudas interesantes sobre el web scraping y el Browserless?
¡Veamos qué comparten otros desarrolladores en Discord y Telegram!
Ahora te mostraré cómo hacer scraping usando Nstbrowserless.
¿Qué significa esto?
En otras palabras, necesitamos usar Nstbrowser, un navegador anti-detección, y configurar el modo sin cabeza en un contenedor Docker para scraping de datos web.
Para el ejemplo, haremos scraping de enlaces de video en la página de Explore en la página principal de TikTok:
También te puede interesar: Cómo usar Playwright para hacer scraping de avatares.
Necesitamos:
a con el atributo data-e2e="nav-explore".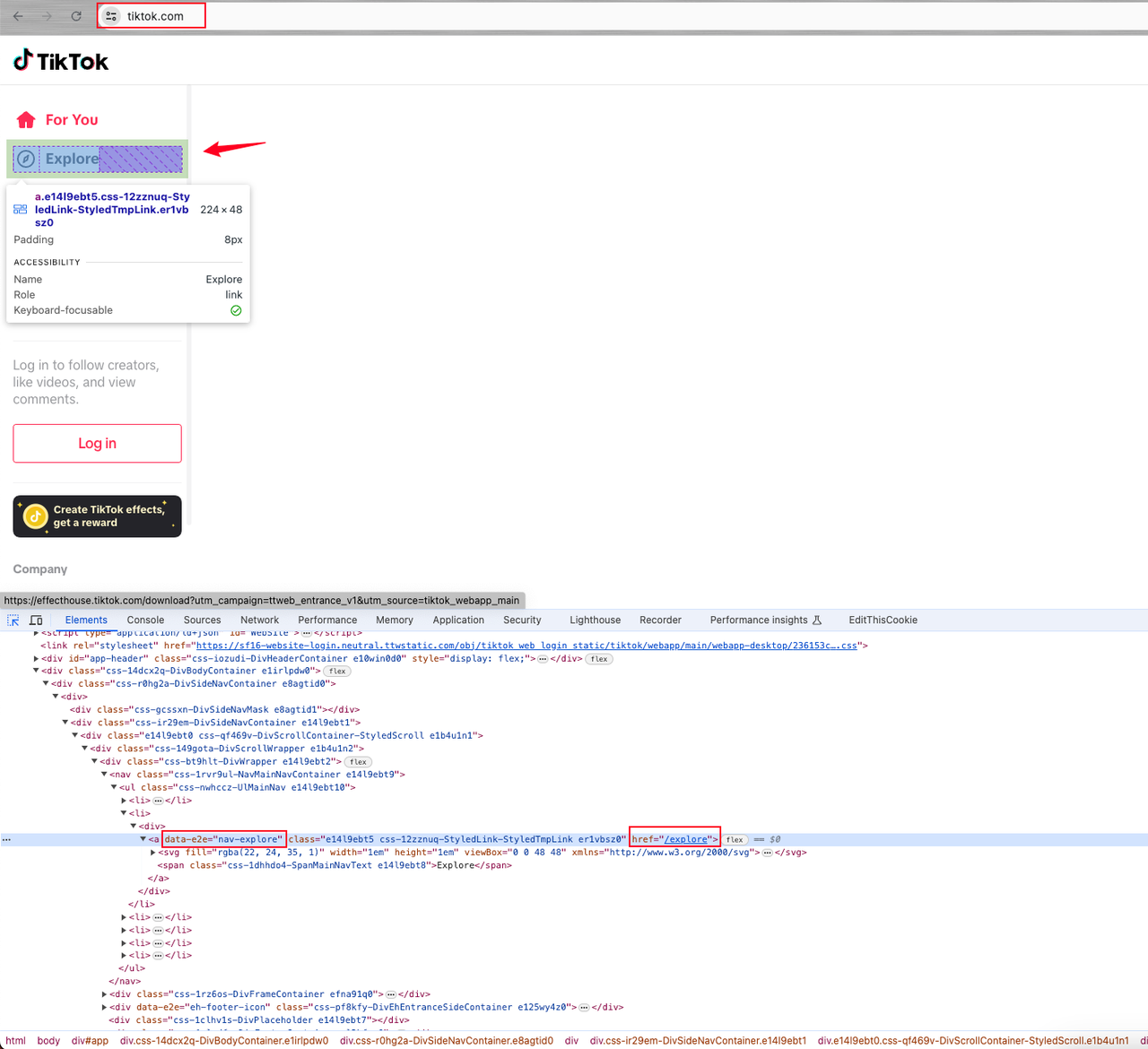
Haz clic en el elemento anterior para ir a la página de vista previa para un análisis más detallado.
Podemos ver que los datos objetivo se encuentran en un elemento de lista con el atributo data-e2e="explore-item-list", que contiene elementos div.
Cada elemento de video está marcado con data-e2e="explore-item", y el enlace de video que necesitamos está en el atributo href de la etiqueta a dentro del div.
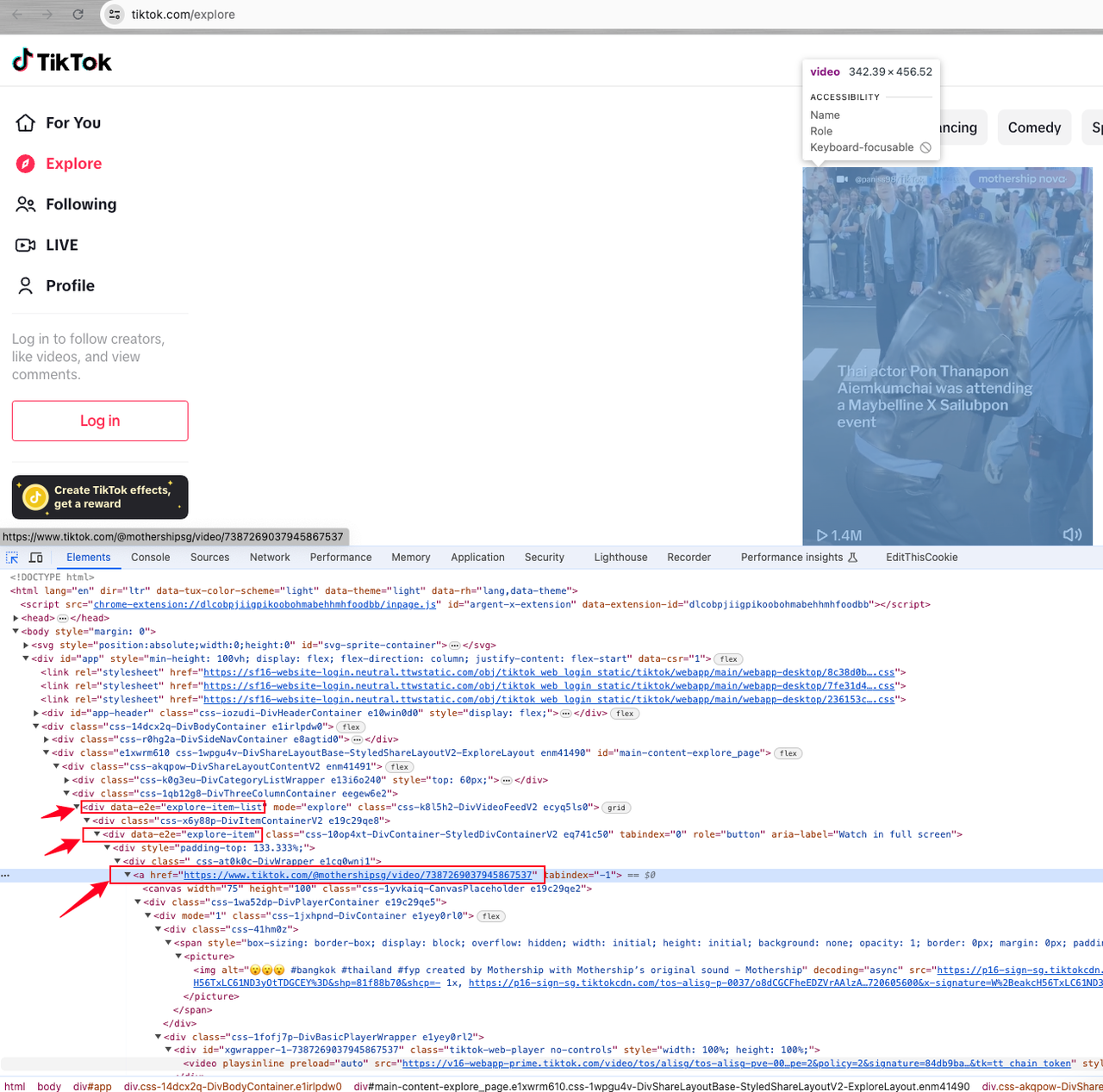
Después de identificar con éxito los elementos necesarios, podemos proceder con el scraping:
# Descargar la imagen
docker pull nstbrowser/browserless:0.0.1-beta
# Ejecutar nstbrowserless
docker run -it -e TOKEN=xxx -e SERVER_PORT=8848 -p 8848:8848 --name nstbrowserless nstbrowser/browserless:0.0.1-betaAhora necesitamos configurar Nstbrowser en modo sin cabeza
import json
from urllib.parse import urlencode
from pyppeteer import launcher
async def main():
config = {
"once": True,
"headless": True, # admite: true o false
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # Los parámetros del navegador deben estar en forma de lista
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # admite: windows, mac, linux
"kernel": 'chromium', # solo admite: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # admite: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # admite: 2, 4, 8
},
}
query = {
'config': json.dumps(config)
}
browser = await launcher.connect(
browserWSEndpoint=f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
)
page = await browser.newPage()
await page.goto('chrome://version')
await page.screenshot({'path': 'chrome_version.png'})
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Después de ejecutar este código, puedes ver la siguiente información en la página chrome://version:

Agregar el parámetro --headless al comando de inicio del núcleo indica que el núcleo se ejecuta en modo sin cabeza.
Código completo:
import json
from urllib.parse import urlencode
from pyppeteer import launcher
async def main():
config = {
"once": True,
"headless": True, # admite: true o false
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # Los parámetros del navegador deben estar en forma de lista
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # admite: windows, mac, linux
"kernel": 'chromium', # solo admite: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # admite: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # admite: 2, 4, 8
},
}
query = {
'config': json.dumps(config)
}
browser = await launcher.connect(
browserWSEndpoint=f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
)
page = await browser.newPage()
try:
await page.goto('https://www.tiktok.com/explore
')
await page.waitForSelector('[data-e2e="explore-item-list"]')
await page.waitFor(3000)
ul_element = await page.querySelector('[data-e2e="explore-item-list"]')
li_elements = await page.querySelectorAll('[data-e2e="explore-item"]')
hrefs = []
if li_elements:
s = []
for li in li_elements:
a_element = await li.querySelector('[data-e2e="explore-item"] div a')
if a_element:
href = await page.evaluate('(element) => element.getAttribute("href")', a_element)
if href:
print(href)
hrefs.append(href)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Resultado del scraping:
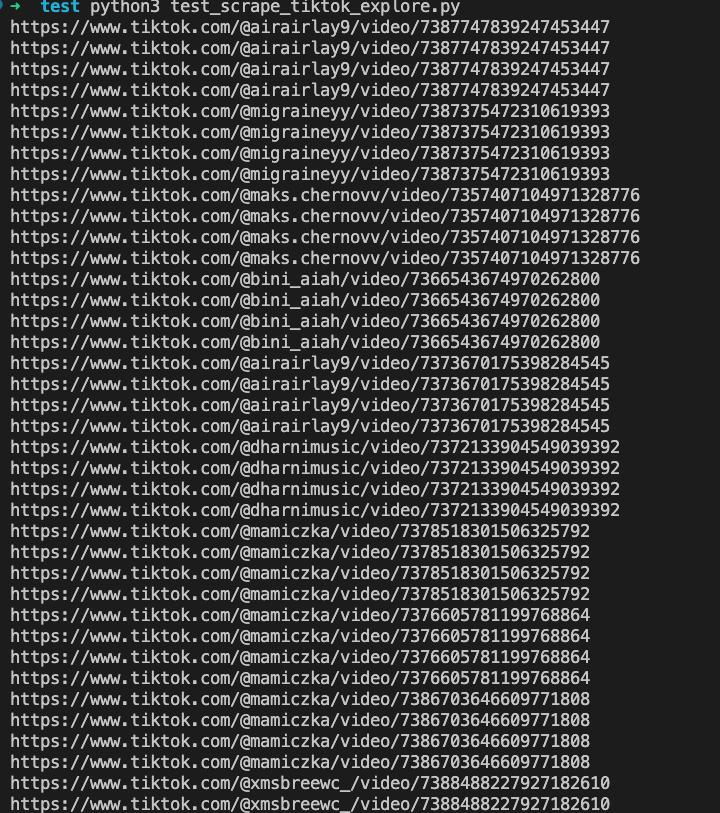
En este momento, hemos completado la operación de scraping de enlaces de videos de TikTok utilizando Nstbrowserless. Después de obtener los enlaces, puedes realizar cualquier acción necesaria, como guardarlos, descargar los videos o redirigirlos para su reproducción.
Por supuesto, este fue un ejemplo muy simple. Si deseas realizar un scraping de más datos, utiliza Nstbrowser para explorar y operar fácilmente para completar esta tarea.
Aunque el navegador sin cabeza es importante para web scraping y automatización, no siempre es ideal. Antes de usarlo, considera cuidadosamente las siguientes ventajas y desventajas:
Chrome sin cabeza ofrece muchas ventajas para el proceso de scraping web y se puede configurar para automatizar con solo unas pocas líneas de código. Minimiza el uso de memoria, maneja JavaScript perfectamente y opera en un entorno sin GUI.
En esta guía has aprendido:
Además, Nstbrowser facilita evitar la detección de bots, desbloquear sitios y simplificar el proceso de scraping web y automatización.





