
Paquete de Proxies hasta75% DTO+15% Bonocon

Los navegadores tradicionales con interfaz gráfica de usuario (GUI) suelen consumir muchos recursos del sistema cuando la carga de trabajo aumenta. Además, necesitan una ventana visible para renderizar las páginas web, lo que ralentiza la ejecución de las pruebas y limita la escalabilidad.
Un navegador sin cabeza (headless) es una herramienta que puede extraer contenido dinámico sin necesidad de un navegador visible.
Puede resolver el problema de las pruebas intensivas en recursos, mejorando así la eficiencia de la ejecución de las pruebas y la escalabilidad.
¿Cómo se ejecuta un navegador sin cabeza en Python y Selenium?
¡Vamos a comenzar a leer este artículo!
Un navegador es un programa informático que permite a los usuarios navegar e interactuar con páginas web. Por otro lado, un navegador sin cabeza no tiene una interfaz gráfica de usuario. ¿Qué puede hacer entonces? ¿Hay mucha diferencia? ¡Sí! Esta característica ayuda a Python headlesschrome a:
¡Oh, espera! Podrías preguntarte cómo interactuamos con un navegador sin cabeza. ¡No hay GUI!
No te preocupes. Déjame mostrarte Web Driver.
Otra pregunta— ¿Qué es eso? Web Driver es un marco que nos permite controlar varios navegadores web mediante programación.
¿Algún ejemplo típico? Sí, todos conocemos Selenium. Lo usamos con frecuencia, pero ¿sabías que también es un importante navegador sin cabeza?
¡Nstbrowser puede simular altamente el comportamiento humano para evitar la detección de robots y desbloquear sitios web!
¡Prueba gratuita ahora!
¿Tienes ideas y dudas interesantes sobre el web scraping y el Browserless?
¡Veamos qué comparten otros desarrolladores en Discord y Telegram!
¡Selenium es muy poderoso! ¿Cuántos navegadores sin cabeza soporta? ¡Vamos a averiguar ahora los 6! Principalmente se controlan y operan a través de Web Driver.
¡Python Selenium headlesschrome no es el único navegador sin cabeza!
Veamos otras alternativas. Algunas solo proporcionan un lenguaje de programación, mientras que otras pueden proporcionar enlaces a varios lenguajes.
Puppeteer es una biblioteca de Node.js desarrollada por Google. Proporciona una API de alto nivel para controlar navegadores Chrome o Chromium sin cabeza. Puppeteer ofrece potentes funciones para automatizar tareas del navegador, generar capturas de pantalla y PDF, y ejecutar código JavaScript en páginas web.
Playwright es otra herramienta de automatización web desarrollada por contribuyentes de Microsoft. Esencialmente, también es una biblioteca de Node.js para la automatización del navegador, pero proporciona API para otros lenguajes (como Python, .NET y Java). En comparación con Python Selenium, es relativamente rápido.
Nstbrowser es un navegador anti-detección completamente gratuito. Implementa la extracción web en la nube en modo sin cabeza, sin estar limitado por recursos locales. Realiza fácilmente la extracción web y los procesos de automatización.
A continuación, se muestra cómo usar Nstbrowserless para ejecutar el navegador anti-detección Nstbrowser en un contenedor Docker y configurar el modo sin cabeza para extraer datos de la página de inicio de TikTok Explorar, específicamente los avatares de los usuarios:
Paso 1: Análisis de página
Luego, puedes descubrir que el elemento es una etiqueta de enlace a con el atributo data-e2e="nav-explore".
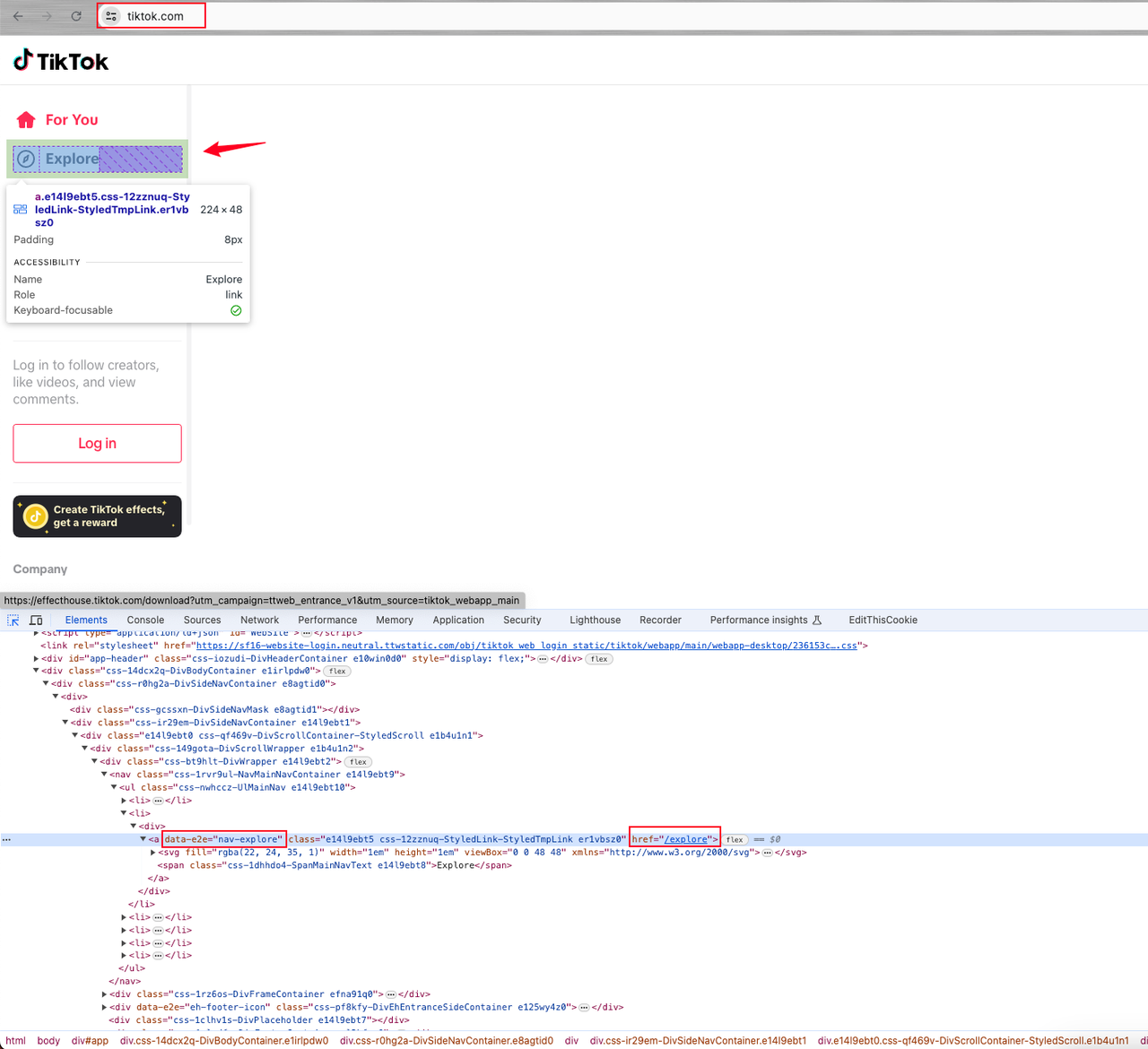
Al hacer clic en el elemento Explorar, descubrimos que la página no tiene avatares de usuario, solo podemos obtener los apodos de los usuarios.
¿Por qué es así?
Esto se debe a que necesitamos hacer clic en el apodo para ingresar a la página de inicio del usuario y obtener el avatar del usuario.
Entonces, debemos ingresar a la página de inicio de cada usuario y luego encontrar el elemento data-e2e="explore-item-list", que es la lista dinámica de usuarios:
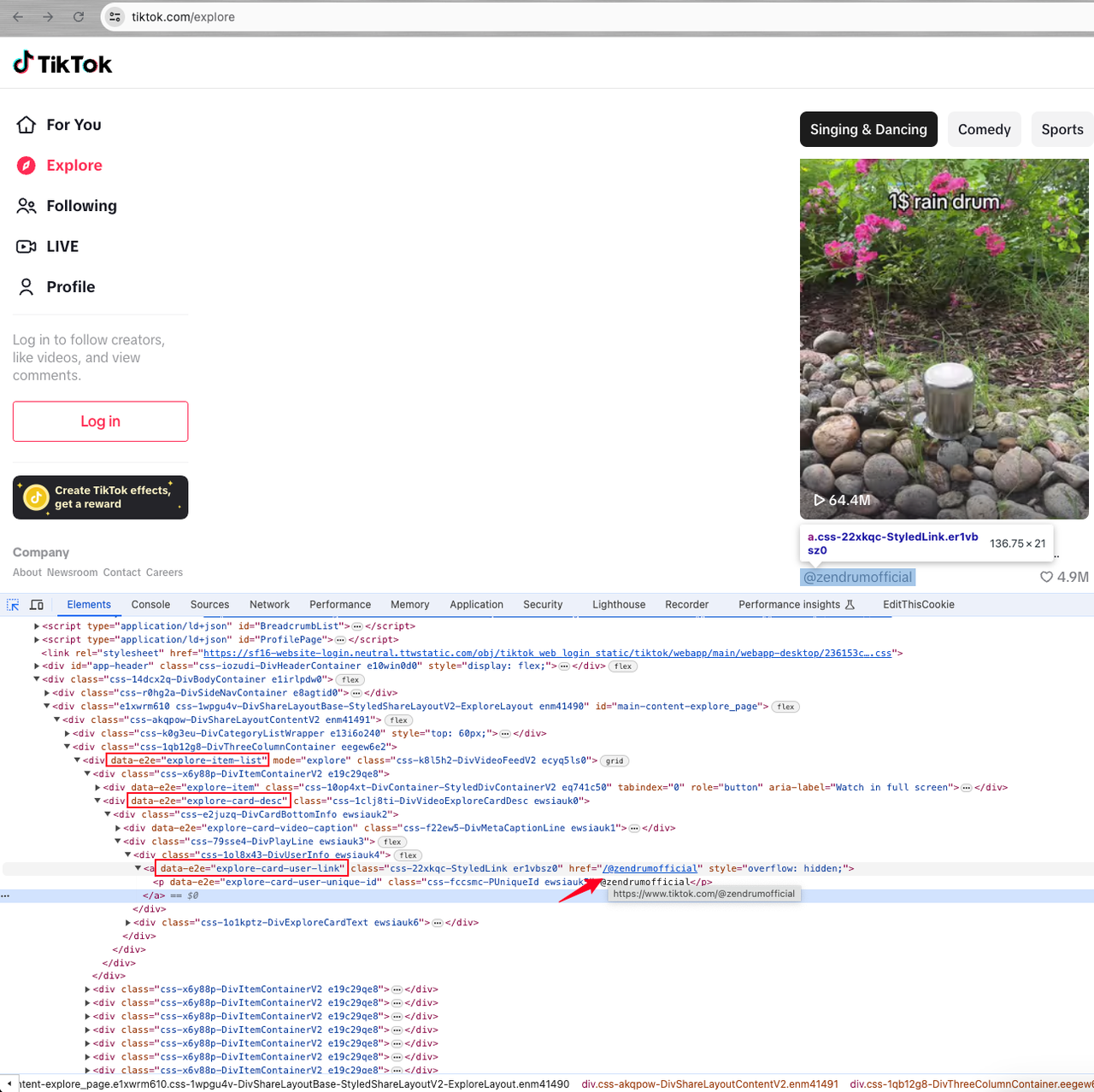
Ahora, necesitamos realizar un análisis adicional.
En el elemento div bajo la lista, hay un elemento con el atributo data-e2e="explore-card-desc", que contiene una etiqueta a con el atributo data-e2e="explore-card-user-link".
El valor del atributo href de la etiqueta a es el ID del usuario, y al agregar el prefijo del dominio de TikTok, obtenemos la página de inicio del usuario.
Vamos a la página de inicio del usuario y continuamos el análisis:
Luego podemos encontrar un elemento div[data-e2e="user-page"] con el atributo div[data-e2e="user-avatar"], el avatar del usuario es el valor del atributo src del elemento span img img dentro del.
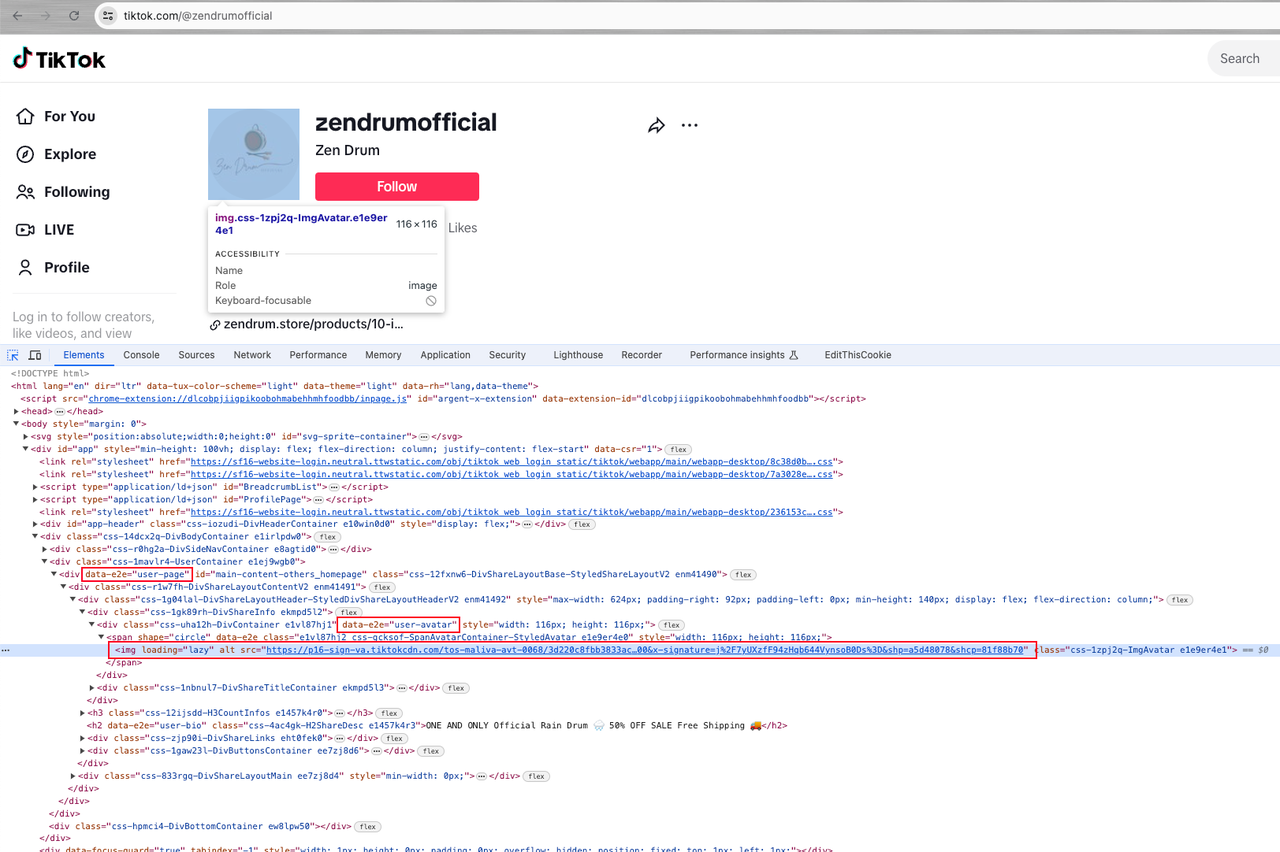
A continuación, es hora de usar Nstbrowserless para obtener los datos que queremos.
Paso 2: Antes de usar Nstbrowserless, primero debes instalar y ejecutar Docker.
# Extraer imagen
docker pull nstbrowser/browserless:0.0.1-beta
# Ejecutar nstbrowserless
docker run -it -e TOKEN=xxx -e SERVER_PORT=8848 -p 8848:8848 --name nstbrowserless nstbrowser/browserless:0.0.1-betaPaso 3. Codificación (Python-Playwright) y configuración del modo sin cabeza.
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # configurar modo sin cabeza
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # los argumentos del navegador deben ser un diccionario
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # soporte: windows, mac, linux
"kernel": 'chromium', # solo soporte: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # soporte: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # soporte: 2, 4, 8
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("Profile URL: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("chrome://version")
await page.wait_for_load_state('networkidle')
await page.screenshot(path="chrome_version.png")
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Ejecuta el código anterior y luego podrás obtener la siguiente información en la página de versión de chrome:

El parámetro --headless en el comando de inicio del kernel indica que el kernel se está ejecutando en modo sin cabeza.
Código de raspado de datos:
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def scrape_user_profile(browser, user_home_page):
# ir a la página de inicio del usuario y extraer el avatar del usuario
user_page = await browser.new_page()
try:
await user_page.goto(user_home_page)
await user_page.wait_for_load_state('networkidle')
user_avatar_element = await user_page.query_selector(
'div[data-e2e="user-page"] div[data-e2e="user-avatar"] span img')
if user_avatar_element:
user_avatar = await user_avatar_element.get_attribute('src')
if user_avatar:
print(user_avatar)
# TODO
finally:
await user_page.close()
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # soporte: verdadero o falso
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # los argumentos del navegador deben ser un diccionario
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # soporte: windows, mac, linux
"kernel": 'chromium', # solo soporte: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # soporte: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # soporte: 2, 4, 8
},
"proxy": "", # establece un proxy adecuado si no puedes explorar el sitio web de TikTok
}
query = {
'config': json.dumps(config)
}
profile_url = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profile_url)
tiktok_url = "https://www.tiktok.com"
try:
page = await browser.new_page()
await page.goto(tiktok_url)
await page.wait_for_load_state('networkidle')
explore_elem = await page.query_selector('[data-e2e="nav-explore"]')
if explore_elem:
await explore_elem.click()
ul_element = await page.query_selector('[data-e2e="explore-item-list"]')
if ul_element:
li_elements = await ul_element.query_selector_all('div')
tasks = []
for li in li_elements:
# encontrar enlaces a la página de inicio del usuario
a_element = await li.query_selector('[data-e2e="explore-card-desc"]')
if a_element:
user_link = await li.query_selector('a[data-e2e="explore-card-user-link"]')
if user_link:
href = await user_link.get_attribute('href')
if href:
tasks.append(scrape_user_profile(browser, tiktok_url + href))
await asyncio.gather(*tasks)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Ejecuta el programa:
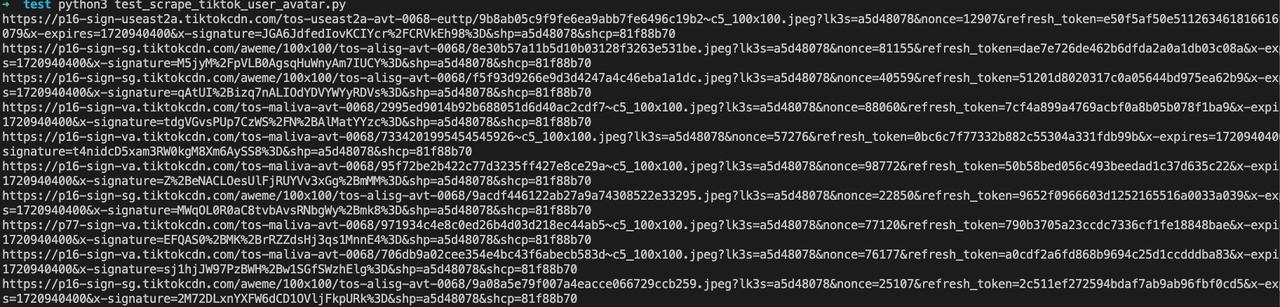
Hasta ahora, hemos completado la captura de los datos del avatar de los usuarios en la página de Exploración de la página de inicio de TikTok usando Python-Playwright a través de Nstbrowserless.
Los navegadores sin cabeza tienen funciones poderosas y métodos de uso convenientes. Pueden completar fácilmente y rápidamente tareas de raspado web y automatización.
En este artículo, aprendimos:
¡Comienza a usar el Nstbrowser gratuito ahora para hacer todo el trabajo!





