
Headless Browser
Cómo usar Nstbrowser docker para rastrear videos de YouTube?
Este tutorial usa la imagen Docker Nstbrowser para demostrar cómo rastrear enlaces de videos de YouTube
Jan 08, 2025Carlos Rivera
¡Tenemos una increíble Oferta de Suscripción con 90% de descuento solo para ti! Ahora, puedes disfrutar de los siguientes precios imbatibles:
- Plan Profesional: Solo **29.9/mes** (precio original 299)
- Plan Enterprise: Solo **59.9/mes** (precio original 599)
Además, ¡seguirás disfrutando de estos descuentos con la renovación automática! No se necesitan pasos adicionales; tu descuento se aplicará automáticamente en la renovación.
Requisitos previos
Antes de comenzar oficialmente, necesitamos comprender Nstbrowser.
Nstbrowser es un potente navegador de huellas digitales que se puede configurar con múltiples huellas digitales, lo que resulta útil para evitar algunos dolores de cabeza en tareas de rastreo a gran escala, como la detección de robots, el reconocimiento de códigos de verificación y el bloqueo de IP, y puede prevenir eficazmente la identificación y el seguimiento de los sitios visitados.
Primero, necesitamos obtener la clave API en Nstbrowser.
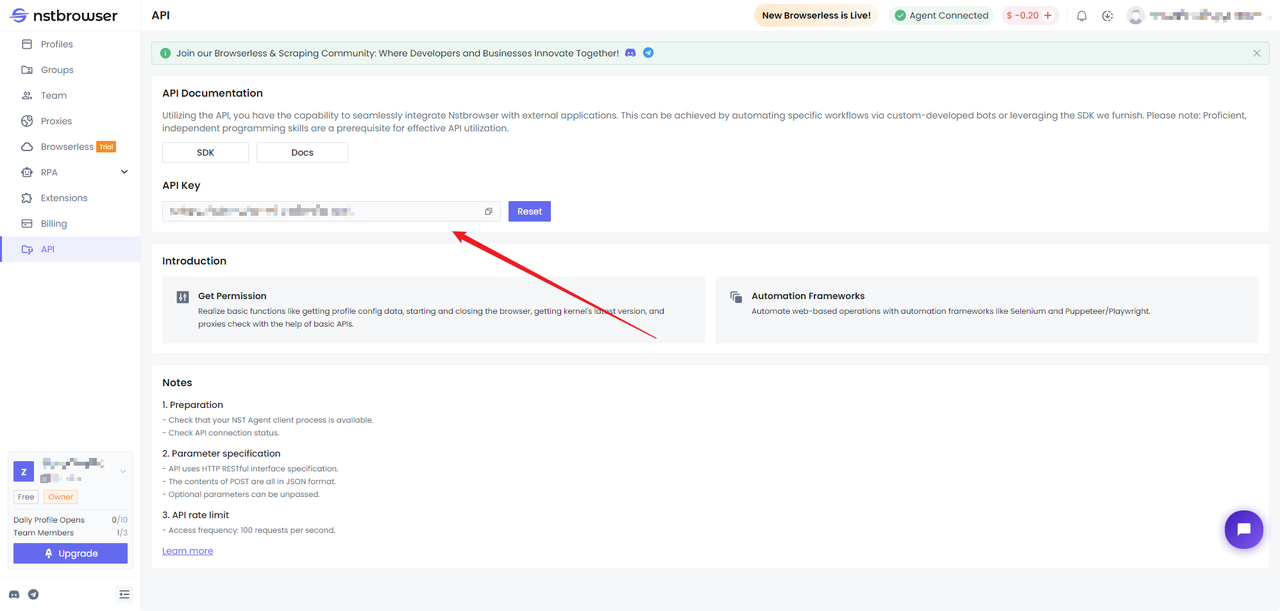
Paso 1. Extraer la imagen Docker de Nstbrowser
Bash
docker pull docker.io/nstbrowser/browserless:latestPaso 2. Ejecutar el contenedor
Bash
docker run -d -it \
-e TOKEN="TU CLAVE API" \
-p 8848:8848 \
--name nstbrowserless \
nstbrowser/browserless:latestPaso 3. Crear un script de rastreo
Aquí usamos puppeteer-core para la demostración
- Instalar
puppeteer-core:
Bash
# pnpm
pnpm i puppeteer-core
# yarn
yarn add puppeteer-core
# npm
npm i --save puppeteer-core- Preparar la configuración de Docker de Nstbrowser
Aquí solo se muestra una lista parcial de la configuración. Para todas las configuraciones, consulta la documentación de la API de Nstbrowser: https://apidocs.nstbrowser.io/api-10293510.
JavaScript
async function start() {
const config = {
"name": "testProfile",
"platform": "windows",
"kernel": "chromium",
// "proxy": "http://127.0.0.1:8000", //Nstbrowser Docker admite el uso de proxy para el acceso a la red
// "doProxyChecking": false,
// "fingerprint": { // configurar la información de huella digital requerida para evitar el seguimiento al visitar sitios
// "flags": {
// "timezone": "BasedOnIp",
// "screen": "Custom"
// },
// "screen": {
// "width": 1000,
// "height": 1000
// },
// "userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.6723.60 Safari/537.36"
// },
// "args": { // admite la configuración de parámetros de inicio del navegador
// "--proxy-bypass-list": "*.nstbrowser.io"
// }
};
const query = new URLSearchParams({
config: encodeURIComponent(JSON.stringify((config))),
});
const browserWSEndpoint = `ws://localhost:8848/connect?${query.toString()}`;
await execPuppeteer(browserWSEndpoint);
}- Comenzar a obtener los elementos de video en YouTube
- Primero, usamos las herramientas para desarrolladores del navegador (F12) para obtener el elemento de la barra de búsqueda y el elemento del botón de búsqueda en YouTube:
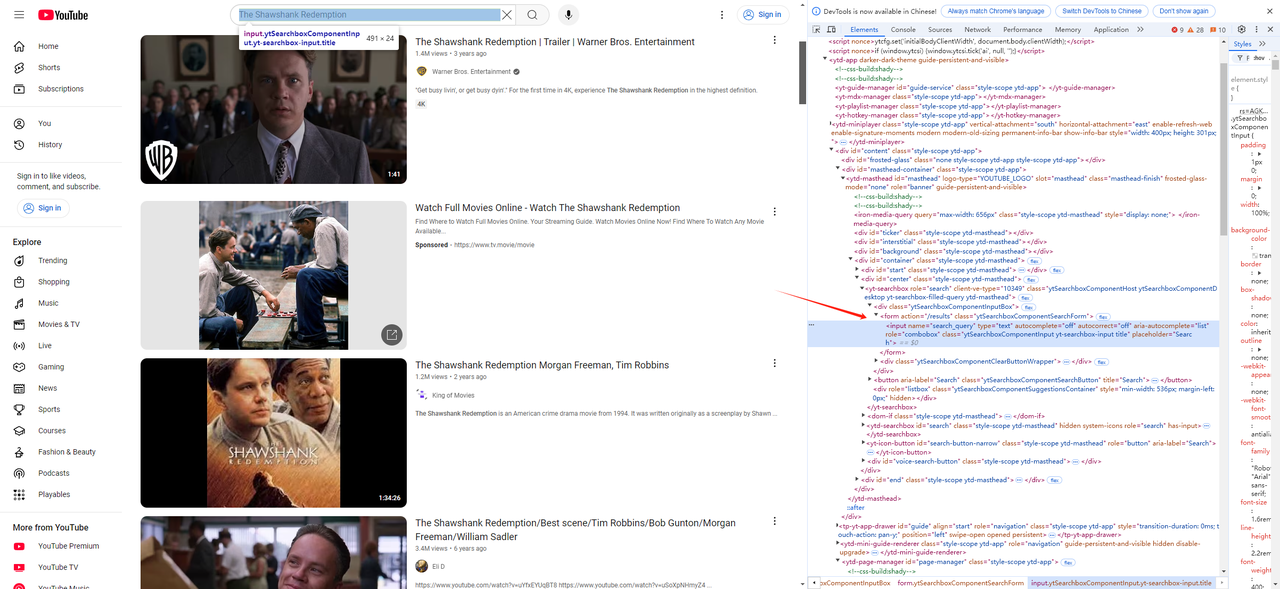
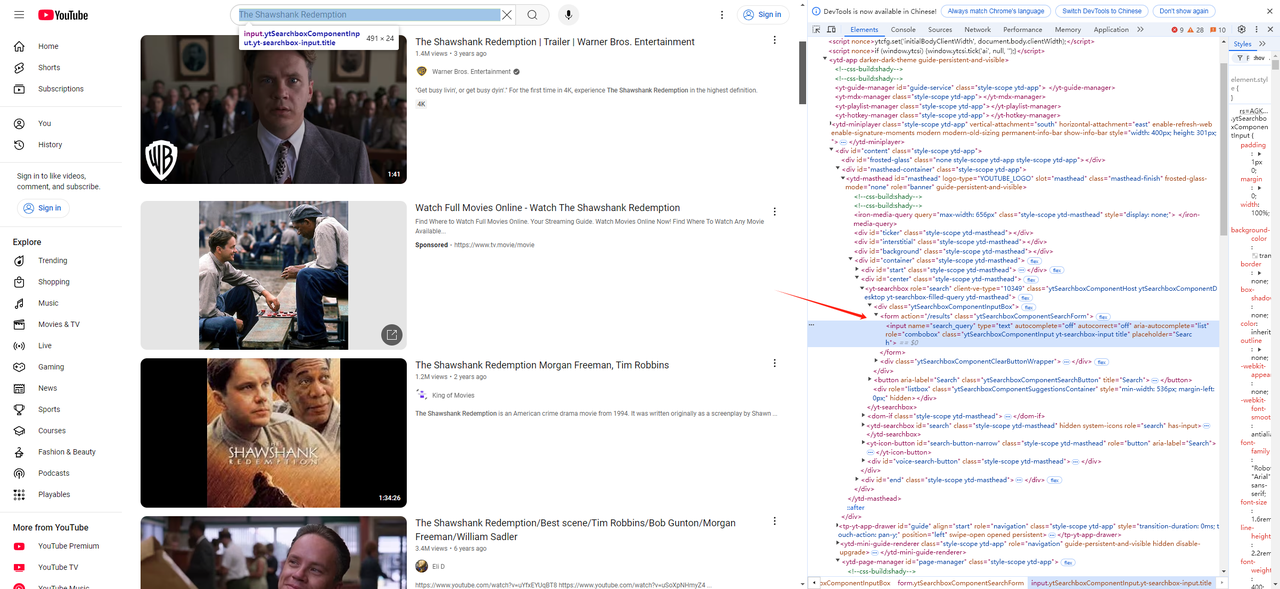
Luego, escribe el script de búsqueda de entrada y el script de clic de búsqueda:
JavaScript
async function execPuppeteer(browserWSEndpoint) {
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
});
const page = await browser.newPage();
// visitar YouTube
await page.goto('https://www.youtube.com');
// ingresar un término de búsqueda
await page.type('#center > yt-searchbox > div.ytSearchboxComponentInputBox > form > input', 'The Shawshank Redemption', { delay: '100' }) // Aquí, delay se usa para retrasar el evento de intervalo de cada entrada de carácter para simular la escena de la entrada de usuario real.
// hacer clic en el botón de búsqueda
await page.click('yt-searchbox button[aria-label=Search]')
// esperar a que se renderice un elemento de página
await page.waitForSelector('ytd-video-renderer ytd-thumbnail >a')- Usa el mismo método para encontrar la información del video que necesitas:
JavaScript
// la etiqueta ytd-video-renderer es un elemento de elemento por video
const videoElement = await page.$$('ytd-video-renderer')- Extraer el título del video, el número de canal, el enlace y otra información de las etiquetas:
JavaScript
const renderList = []
for (const element of videoElement) {
const link = await element.$('ytd-thumbnail > a').then((el) => {
return el.evaluate((ele) => {
return `https://www.youtube.com${ele.getAttribute('href')}`;
})
})
const title = await element.$('ytd-thumbnail + div yt-formatted-string').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
const channel = await element.$('ytd-thumbnail + div > div[id=channel-info] yt-formatted-string >a').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
renderList.push({
channel,
title,
link
})
}
console.log("renderList:", renderList)- Ejecuta el script anterior, podemos obtener los datos del video en YouTube:
JavaScript
renderList: [
{
channel: 'Warner Bros. Entertainment',
title: 'The Shawshank Redemption | Trailer | Warner Bros. Entertainment',
link: 'https://www.youtube.com/watch?v=PLl99DlL6b4&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
{
channel: 'King of Movies',
title: 'The Shawshank Redemption Morgan Freeman, Tim Robbins',
link: 'https://www.youtube.com/watch?v=XIv97tIImz8&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
{
channel: 'Eli D',
title: 'The Shawshank Redemption/Best scene/Tim Robbins/Bob Gunton/Morgan Freeman/William Sadler',
link: 'https://www.youtube.com/watch?v=0spucxvMfjE&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
.......
{
channel: 'BBC Global',
title: 'How The Shawshank Redemption went from flop to hit | BBC Global',
link: 'https://www.youtube.com/watch?v=jbn9IgCIeB4&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
{
channel: 'Turner Classic Movies',
title: 'Tim Robbins and Morgan Freeman reflect on 30 years of THE SHAWSHANK REDEMPTION | TCMFF 2024',
link: 'https://www.youtube.com/watch?v=pYmAy3H0s3Q&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
}
]El código completo:
JavaScript
import puppeteer from 'puppeteer-core';
import express from "express";
async function execPuppeteer(browserWSEndpoint, search) {
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
});
const page = await browser.newPage();
await page.goto('https://www.youtube.com');
await page.type('#center > yt-searchbox > div.ytSearchboxComponentInputBox > form > input', search, { delay: '100' })
await page.click('yt-searchbox button[aria-label=Search]')
await page.waitForSelector('ytd-video-renderer ytd-thumbnail >a')
const videoElement = await page.$$('ytd-video-renderer')
const renderList = []
for (const element of videoElement) {
const link = await element.$('ytd-thumbnail > a').then((el) => {
return el.evaluate((ele) => {
return `https://www.youtube.com${ele.getAttribute('href')}`;
})
})
const title = await element.$('ytd-thumbnail + div yt-formatted-string').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
const channel = await element.$('ytd-thumbnail + div > div[id=channel-info] yt-formatted-string >a').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
renderList.push({
channel,
title,
link
})
}
console.log(renderList);
await browser.close();
return renderList;
} catch (err) {
console.log(`Error fetching ${selector}:`, e);
}
}
async function start(search) {
const config = {
"name": "testProfile",
"platform": "windows",
"kernel": "chromium",
"kernelMilestone": "130",
// "proxy": "http://127.0.0.1:8000",
// "doProxyChecking": false,
// "fingerprint": {
// "flags": {
// "timezone": "BasedOnIp",
// "screen": "Custom"
// },
// "screen": {
// "width": 1000,
// "height": 1000
// },
// "userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.6613.85 Safari/537.36"
// },
// "args": {
// "--proxy-bypass-list": "*.nstbrowser.io"
// }
};
const query = new URLSearchParams({
config: encodeURIComponent(JSON.stringify((config))),
});
const browserWSEndpoint = `ws://localhost:8838/connect?${query.toString()}`;
return await execPuppeteer(browserWSEndpoint, search);
}
const app = express();
app.get("/youtube/:search", async (req, resp) => {
const search = req.params.search;
const renderList = await start(search);
resp.send({ "code": 200, "data": renderList })
})
app.listen(8080, () => console.log("Listening on PORT: 8080"))Uso de la API de Nstbrowser Docker
Durante el proceso de ejecución, también puedes llamar a otras API en el servicio del contenedor para operar el navegador en el contenedor
- http://localhost:8848/start
- Método: POST
Paso 1. Iniciar una nueva instancia del navegador:
JavaScript
request:
{
"name": "testProfile",
"once": true,
"platform": "windows",
"kernel": "chromium",
"kernelMilestone": "130",
"fingerprint": {
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.6613.85 Safari/537.36"
}
}
response:
{
"data": {
"profileId": "4a9911a9-6d28-41b9-8bf4-cc08592afcbd",
"port": 31685,
"webSocketDebuggerUrl": "ws://127.0.0.1:31685/devtools/browser/19df3c03-2b13-49db-ac1d-989bb68a353f"
},
"err": false,
"msg": "success",
"code": 200
}Paso 2. Una vez completado el inicio, puedes conectarte directamente al navegador que acabas de iniciar a través de la URL del parámetro webSocketDebuggerUrl para ejecutar otros comandos de script.
- http://localhost:8848/stop/{profileId}
- Método: GET
Cerrar la instancia del navegador del profileId especificado:
JavaScript
response:
{
"data": null,
"err": false,
"msg": "success",
"code": 200
}- http://localhost:8848/stopAll
- Método: GET
Cerrar todas las instancias del navegador:
JavaScript
response:
{
"data": null,
"err": false,
"msg": "success",
"code": 200
}- http://localhost:8848/running
- Método: GET
Obtener todas las instancias del navegador en ejecución:
JavaScript
response:
{
"data": [
{
"profileId": "605ffe1f-7bdf-4ac7-b0bb-70746cb92a0f",
"remoteDebuggingPort": 26192,
"running": true,
"starting": false,
"stopping": false
},
{
"profileId": "8693f526-5a9f-4669-86db-c48866921ffc",
"remoteDebuggingPort": 45850,
"running": true,
"starting": false,
"stopping": false
}
],
"err": false,
"msg": "success",
"code": 200
}- http://localhost:8848/json/list/{profileId}
- Método: GET
Obtener la lista de páginas abiertas por la instancia del navegador. A través de la lista de páginas, podemos verificar el estado de funcionamiento del navegador en cualquier momento:
JavaScript
response:
{
"data": [
{
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=127.0.0.1:45850/devtools/page/401571FE7D5A477074F539B39AEE0EC6",
"id": "401571FE7D5A477074F539B39AEE0EC6",
"title": "tiktok - Google Search",
"type": "page",
"url": "https://www.google.com/search?q=tiktok&oq=tikto&gs_lcrp=EgZjaHJvbWUqDQgAEAAYgwEYsQMYgAQyDQgAEAAYgwEYsQMYgAQyBggBEEUYOTINCAIQABiDARixAxiABDIKCAMQABixAxiABDIKCAQQABixAxiABDIKCAUQABixAxiABDIHCAYQABiABDIHCAcQABiABDIKCAgQABixAxiABDINCAkQLhiDARixAxiABNIBCTgyMzJqMGoxNagCALACAA&sourceid=chrome&ie=UTF-8",
"webSocketDebuggerUrl": "ws://127.0.0.1:45850/devtools/page/401571FE7D5A477074F539B39AEE0EC6"
},
{
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=127.0.0.1:45850/devtools/page/293BECFB09421FE88DB74CB222AFDCA6",
"id": "293BECFB09421FE88DB74CB222AFDCA6",
"title": "The Shawshank Redemption - YouTube",
"type": "page",
"url": "https://www.youtube.com/results?search_query=The+Shawshank+Redemption",
"webSocketDebuggerUrl": "ws://127.0.0.1:45850/devtools/page/293BECFB09421FE88DB74CB222AFDCA6"
}
],
"err": false,
"msg": "success",
"code": 200
}Reflexiones finales
Nstbrowser Docker proporciona un conveniente servicio de navegador de huellas digitales Nstbrowser. A través de la tecnología de contenedores Docker, puede aislar bien el complejo entorno en la máquina host y admite la ejecución de servicios de navegador Nstbrowser en diferentes plataformas. El aislamiento del contenedor puede ejecutar varias instancias localmente, rastrear datos en diferentes sitios web y lograr la anti-seguimiento del usuario.
Más





