
Headless Browser
Prueba de navegador sin cabeza: ¿Qué es y cómo hacerlo?
Las pruebas de navegador sin cabeza son una forma más rápida, confiable y eficiente de probar aplicaciones web en navegadores. Lea este blog y encuentre la guía detallada sobre las pruebas de navegador sin cabeza.
Sep 12, 2024Robin Brown
¿Qué es la prueba sin cabeza?
Todos los desarrolladores deben estar familiarizados con las pruebas impulsadas por la interfaz de usuario. Esto asegura que nuestros programas funcionen correctamente durante mucho tiempo. Sin embargo, hay muchos problemas con las pruebas impulsadas por la interfaz de usuario. El que más me molesta es la estabilidad. A veces, las pruebas impulsadas por la interfaz de usuario no pueden interactuar con el navegador.
La respuesta a este problema es la prueba de navegador sin cabeza.
Con la prueba de navegador sin cabeza, realiza pruebas de extremo a extremo donde el navegador no carga la interfaz de usuario de la aplicación. Por lo tanto, todo funciona más rápido y las pruebas interactúan directamente con la página, eliminando cualquier posibilidad de inestabilidad. Sus pruebas se vuelven más confiables, rápidas y eficientes.
¿Qué significa "sin cabeza" para el software?
Esencialmente, una solución "sin cabeza" separa el frontend y el backend de un sistema:
Por ejemplo, puede cambiar el software que impulsa un chatbot de servicio al cliente (el backend) sin cambiar la forma en que se presenta la interfaz del bot a los clientes (el frontend). En los sistemas acoplados tradicionales, los cambios deben realizarse a través de ambos, lo cual es lento, costoso y potencialmente riesgoso.
A medida que las empresas ven la mayor flexibilidad y escalabilidad de las soluciones sin cabeza, su popularidad está creciendo rápidamente:
- Los sitios de comercio electrónico están separando la capa de presentación del frontend de las funciones de comercio del backend;
- Las plataformas CMS tienen una capa de contenido separada orientada al cliente que no interrumpe su infraestructura empresarial;
- Las plataformas de automatización del servicio al cliente están desarrollando agentes virtuales de IA que se encuentran detrás de los chatbots de servicio al cliente o sistemas de tickets orientados al cliente.
¿Tiene alguna idea o duda maravillosa sobre el scraping web y Browserless?
Veamos qué están compartiendo otros desarrolladores en Discord y Telegram!
Ventajas y desventajas de los navegadores sin cabeza
Los navegadores sin cabeza tienen ventajas significativas en rendimiento, eficiencia de automatización y gestión de recursos, pero tienen ciertas limitaciones en la depuración y la simulación de la experiencia del usuario real.
Ventajas:
1. Rendimiento más rápido:
No es necesario renderizar una interfaz gráfica, lo que reduce el consumo de recursos, por lo que la velocidad de ejecución suele ser más rápida que un navegador con interfaz, especialmente en escenarios de rastreo web y pruebas.
2. Bajo uso de recursos:
Los navegadores sin cabeza consumen menos memoria y CPU, y son adecuados para tareas de automatización a gran escala y escenarios de ejecución paralela.
3. Alta eficiencia de las tareas de automatización:
Adecuado para tareas como rastreo web, pruebas automatizadas, simulación de operaciones de usuario, y a menudo se utiliza en pruebas de QA, monitoreo de SEO, recopilación de datos, etc.
4. Fácil integración:
Los navegadores sin cabeza a menudo se combinan con herramientas de automatización como Puppeteer, Selenium, Playwright, etc., y se pueden integrar fácilmente en el proceso de integración y entrega continuas (CI/CD).
5. Soporte multiplataforma:
Los navegadores sin cabeza son compatibles con diferentes sistemas operativos y núcleos de navegador, como Chrome, Firefox, etc., y se pueden aplicar de forma flexible en diversos entornos de desarrollo y pruebas.
6. Altamente ocultado:
Los navegadores sin cabeza no tienen interfaz de usuario, son adecuados para tareas automatizadas y no son fáciles de descubrir, especialmente al rastrear páginas web, lo que puede reducir el riesgo de ser detectados por los sitios web.
Desventajas:
1. Depuración difícil:
Debido a que no hay GUI, el proceso de depuración de los navegadores sin cabeza es más difícil que los navegadores normales. Los desarrolladores no pueden ver intuitivamente el estado de renderizado de las páginas web y generalmente necesitan confiar en los registros o capturas de pantalla.
2. No completamente consistente con la experiencia del usuario real:
Aunque los navegadores sin cabeza son similares a los navegadores de interfaz en términos de funcionalidad, es posible que no simulen con precisión la experiencia interactiva de los usuarios reales en algunos escenarios (como elementos de IU complejos o animaciones).
3. Algunos sitios web detectan navegadores sin cabeza:
Algunos sitios web tienen mecanismos anti-automatización que pueden identificar y bloquear las solicitudes de navegadores sin cabeza, especialmente en escenarios de rastreo de datos donde pueden ser bloqueados.
4. Incapaz de manejar algunas funciones de frontend:
Aunque los navegadores sin cabeza son poderosos, es posible que no funcionen tan bien como los navegadores de interfaz en algunas funciones avanzadas de frontend (como animaciones complejas y renderizado 3D).
5. Difícil para principiantes:
Para los principiantes que son nuevos en las pruebas automatizadas o el rastreo web, la curva de aprendizaje para configurar y usar navegadores sin cabeza es pronunciada y puede llevar más tiempo dominarla.
Cuándo usar las pruebas de navegador sin cabeza?
Las pruebas de navegador sin cabeza son realmente una herramienta muy útil, especialmente en escenarios donde los recursos son limitados o las tareas automatizadas deben ejecutarse de manera eficiente. Puede utilizar las pruebas de navegador sin cabeza en las siguientes situaciones:
1. Interacción HTML automatizada:
Prueba los comportamientos de interacción del usuario, como el envío de formularios, los clics de botones y las selecciones de menús desplegables. Con un navegador sin cabeza, puede simular estas operaciones y verificar si la respuesta es correcta.
2. Pruebas de ejecución de JavaScript:
Los navegadores sin cabeza pueden ayudar a probar el efecto de ejecución de JavaScript en las páginas web y verificar la exactitud del contenido dinámico. Es particularmente adecuado para aplicaciones con una gran cantidad de lógica de renderizado del lado del cliente.
3. Rastreo web:
Los navegadores sin cabeza pueden evitar los mecanismos simples contra el rastreo, cargar contenido web dinámico y rastrear datos de las páginas web. Los navegadores sin cabeza son muy eficientes para las tareas de rastreo que requieren un renderizado de página complejo en el frontend.
4. Monitoreo de red y pruebas de rendimiento:
Los navegadores sin cabeza pueden monitorear las solicitudes de red, el tiempo de carga, etc., ayudan a analizar los cuellos de botella de rendimiento de las páginas y son adecuados para las tareas de optimización y monitoreo del rendimiento del sitio web.
5. Manejar llamadas Ajax:
Cuando una página web depende de Ajax para cargar datos, un navegador sin cabeza puede capturar y manejar estas solicitudes y garantizar que se carguen y se muestren correctamente.
6. Generar capturas de pantalla de páginas web:
En las pruebas automatizadas, generar capturas de pantalla de páginas ayuda a detectar errores, se utiliza para la generación de documentos y es adecuado para verificar visualmente el diseño y el contenido de la página.
Cómo configurar Selenium para pruebas sin cabeza con Browserless?
Paso 1. Instalar las dependencias de Selenium
Primero, asegúrese de tener Selenium instalado en su entorno de desarrollo. Puede instalarlo con el siguiente comando:
Bash
pip install seleniumPaso 2. Obtener la clave API
Nstbrowser proporciona servicios en la nube que integran Browserless. Debe obtener la clave API correspondiente de Nstbrowser. Inicie sesión en la plataforma Nstbrowser y busque la clave API de Browserless en el panel de control o obtenga la clave API en la sección Browserless del cliente.
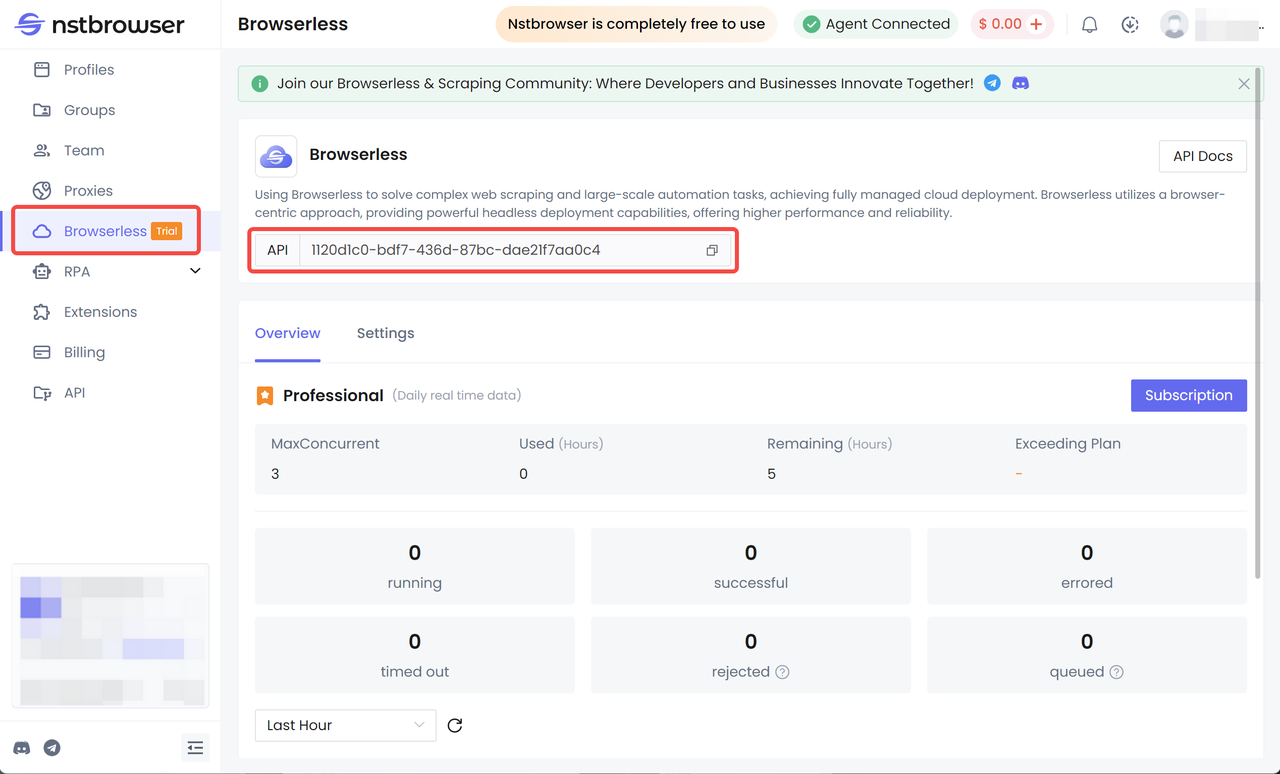
Paso 3. Configurar Selenium para integrarse con Browserless
Selenium necesita usar la API de Browserless para las pruebas de navegador sin cabeza. Puede configurar el command_executor de WebDriver en la URL de WebSocket proporcionada por Nstbrowser.
El siguiente es un código de muestra de Python que muestra cómo usar Browserless para las pruebas de navegador sin cabeza de Selenium:
Python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# Establecer opciones del navegador Chrome
chrome_options = Options()
chrome_options.add_argument('--headless') # Habilitar el modo sin cabeza
chrome_options.add_argument('--disable-gpu') # Si está utilizando Windows
# URL de WebSocket de Browserless de Nstbrowser
nstbrowser_url = 'wss://chrome.nstbrowser.com/webdriver?token=YOUR_NSTBROWSER_API_KEY'
# Configurar WebDriver remoto para conectarse a Browserless de Nstbrowser
driver = webdriver.Remote(
command_executor=nstbrowser_url,
options=chrome_options
)
# Visitar la página web de prueba
driver.get("https://www.example.com")
# Imprimir el título de la página web
print(driver.title)
# Cerrar el navegador
driver.quit()Cómo configurar Cypress para pruebas sin cabeza con Browserless?
Paso 1. Registrar Nstbrowser y obtener la clave API
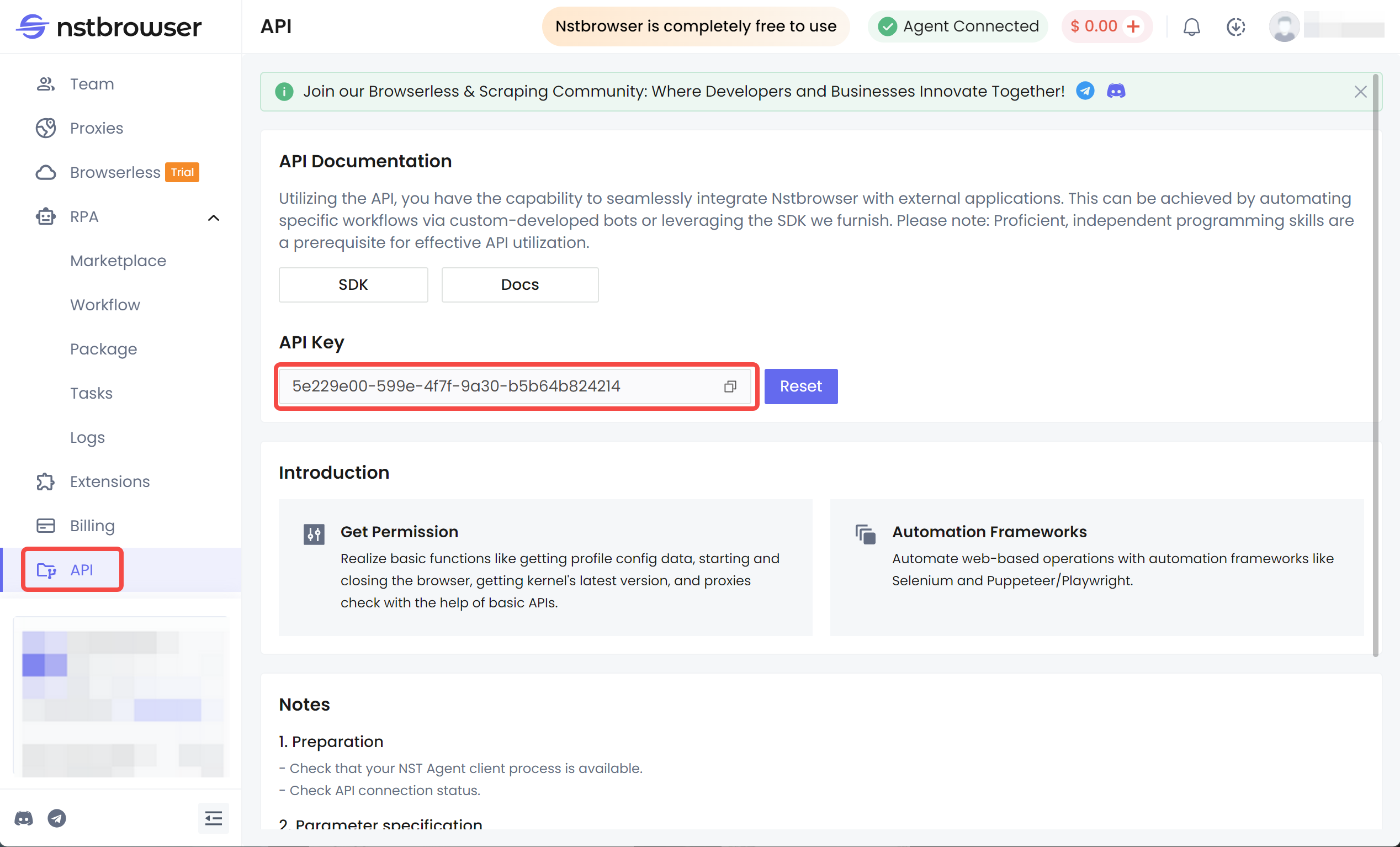
Paso 2. Instalar Cypress
Bash
npm install cypressPaso 3. Configurar Cypress para conectarse a Browserless
Cree o modifique el archivo de configuración de Cypress cypress.json o cypress.config.js en el directorio raíz del proyecto y agregue la configuración de Browserless al archivo. Especifique la instancia remota de Browserless a través de la opción de configuración browser de Cypress:
JSON
{
"browser": "chrome",
"chromeWebSecurity": false,
"baseUrl": "https://your-application-url.com",
"video": false
}Paso 4. Configurar Cypress para conectarse a su instancia de Browserless
Configure Cypress para conectarse a su instancia de la nube de Browserless a través de una clave API. En su script de prueba, puede conectarse mediante:
- Establecer una variable de entorno o usar un archivo .env para almacenar su clave API:
Bash
CYPRESS_REMOTE_BROWSER_WS=ws://your-browserless-api-url
CYPRESS_API_KEY=your-api-keyPaso 5. Ejecutar pruebas de Cypress
- Ejecute el script de prueba de Cypress desde la línea de comandos y asegúrese de que se conecte a la instancia de Browserless:
Bash
npx cypress run --browser chrome --headlessEsto aprovechará Browserless de Nstbrowser para las pruebas sin cabeza, haciendo que las pruebas sean más eficientes y ejecutando múltiples instancias de navegador en la nube.
Cómo configurar Puppeteer para pruebas sin cabeza con Browserless?
Configurar Puppeteer para pruebas sin cabeza con Browserless es muy simple. Puede integrarse con Puppeteer a través de la API de Browserless para evitar instalar y ejecutar Chrome o Chromium localmente.
Paso 1. Instalar Puppeteer
Primero, asegúrese de tener Node.js instalado en su sistema. Luego, instale Puppeteer en su proyecto:
Bash
npm install puppeteerPaso 2. Obtener la clave API de Browserless
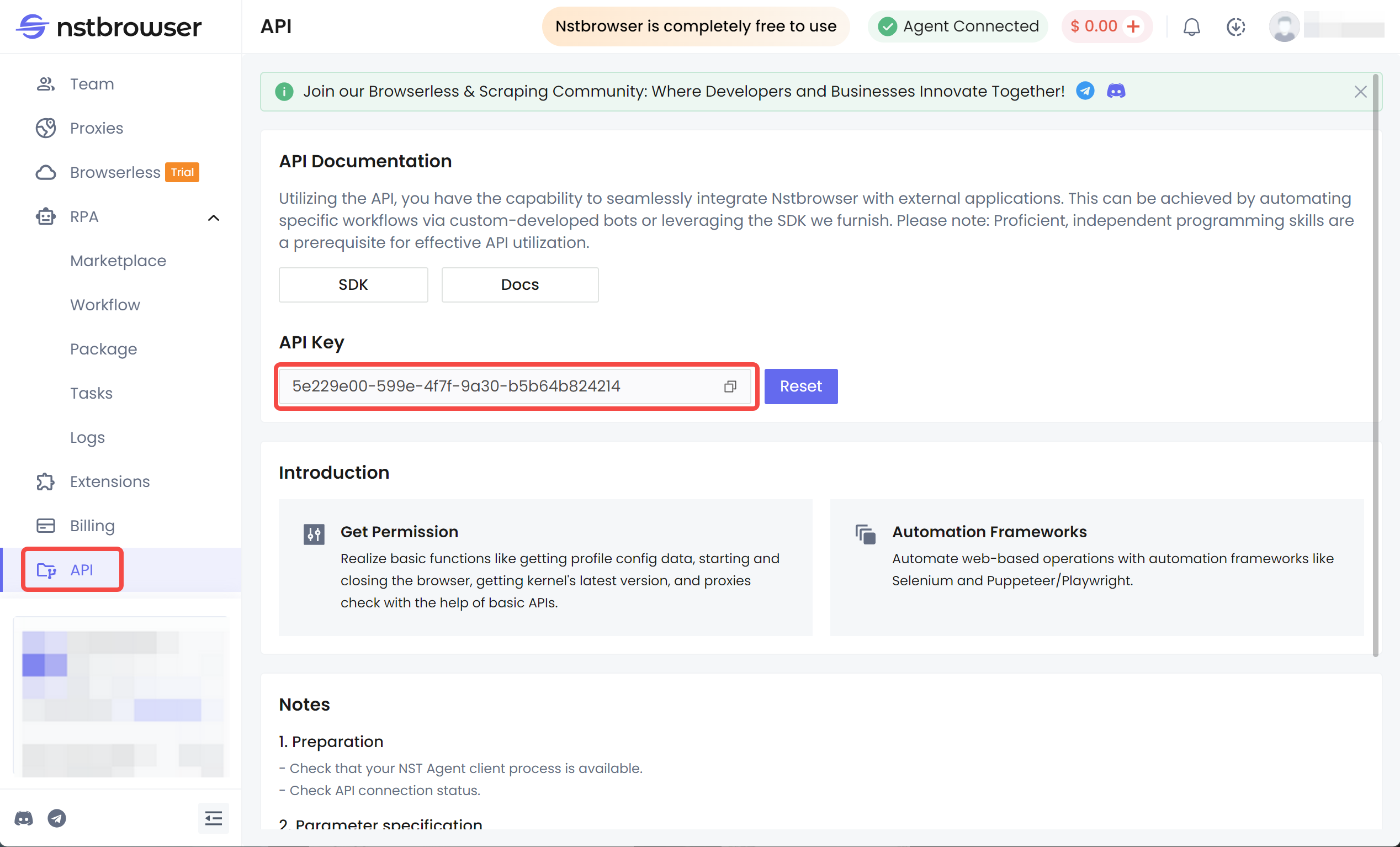
Paso 3. Configurar Puppeteer Browserless con Nstbrowser
Puppeteer puede conectarse al servicio de navegador sin cabeza a través de una URL de WebSocket. Aquí hay un código de muestra de cómo usar Browserless para las pruebas de navegador sin cabeza:
JavaScript
const puppeteer = require('puppeteer-core');
(async () => {
// URL de WebSocket de Browserless
const browser = await puppeteer.connect({
browserWSEndpoint: 'wss://chrome.nstbrowser.com/webdriver?token=YOUR_NSTBROWSER_API_KEY'
});
// Abrir una nueva página
const page = await browser.newPage();
// Visitar el sitio web
await page.goto('https://www.example.com');
// Imprimir el título de la página
const title = await page.title();
console.log(`Page title is: ${title}`);
// Ejemplo de captura de pantalla
await page.screenshot({ path: 'example.png' });
// Cerrar la instancia del navegador
await browser.close();
})();Paso 4. Ejecutar el script
Puede ejecutar este script a través de Node.js, que realizará pruebas de navegador sin cabeza a través de Browserless de Nstbrowser y realizará las acciones que especifique. Aquí está el comando para ejecutar el script:
Bash
node your-script.jsPaso 5. Ver el panel de Nstbrowser
En el panel de Nstbrowser, puede monitorear el estado de ejecución del navegador sin cabeza en tiempo real, incluidos los registros, el recuento de llamadas API y la información detallada sobre la instancia del navegador. Esto es muy útil para depurar y optimizar las tareas de automatización.
Notas adicionales:
- Modo sin cabeza de Puppeteer: En Puppeteer, se ejecuta en modo sin cabeza (
headless: true) de forma predeterminada, es decir, no se muestra ninguna interfaz de usuario. Si necesita cambiar al modoheadless, puede configurar headless enfalse. - Ventajas proporcionadas por Nstbrowser: Con Browserless, no necesita instalar un navegador localmente, y puede usar su rotación de IP, proxy, evitación automática de bloqueos y otras funciones, que son muy útiles para las tareas de automatización a gran escala.
Cómo configurar Playwright para pruebas sin cabeza con Browserless?
Paso 1. Registrar Nstbrowser y obtener una clave API
Visite Nstbrowser para registrar su cuenta y obtener una clave API para integrar Browserless. Esta clave se utilizará para conectarse al clúster de navegador sin cabeza basado en la nube de Nstbrowser.
Paso 2. Instalar Playwright
Bash
npm install playwrightPaso 3. Configurar Playwright para conectarse a Browserless
En el proyecto Playwright, use el método connect proporcionado por Playwright para configurarlo para conectarse a la instancia de la nube de Browserless de Nstbrowser.
Cree o modifique un script de prueba Playwright y agregue la URL de conexión de WebSocket de Browserless y la clave API al script.
JavaScript
const { chromium } = require('playwright');
// Usar la URL de WebSocket y la clave API proporcionada por Browserless
(async () => {
const browser = await chromium.connect({
wsEndpoint: 'wss://your-nstbrowserless-api-url?token=your-api-key'
});
const context = await browser.newContext();
const page = await context.newPage();
// Abrir el sitio web que desea probar
await page.goto('https://your-application-url.com');
// Realizar acciones en la página, como hacer clic, escribir, etc.
await page.click('button#submit');
// Cerrar el navegador
await browser.close();
})();Paso 4. Ejecutar pruebas sin cabeza de Playwright
Ejecute su script Playwright en la terminal y asegúrese de que esté conectado a la instancia de Browserless de Nstbrowser:
Bash
node your-playwright-script.jsPaso 5. Pruebas concurrentes y optimización de recursos
Playwright admite la ejecución concurrente de pruebas en múltiples instancias de navegador. Con la infraestructura en la nube de Browserless de Nstbrowser, puede ejecutar múltiples sesiones de Playwright simultáneamente para una automatización de pruebas eficiente:
JavaScript
const { chromium } = require('playwright');
(async () => {
// Conéctese a Browserless y use múltiples instancias de navegador para pruebas concurrentes
const browser = await chromium.connect({
wsEndpoint: 'wss://your-nstbrowserless-api-url?token=your-api-key'
});
// Cree múltiples contextos de navegador para paralelizar las pruebas
const context1 = await browser.newContext();
const context2 = await browser.newContext();
const page1 = await context1.newPage();
const page2 = await context2.newPage();
await page1.goto('https://example1.com');
await page2.goto('https://example2.com');
// Ejecutar operaciones de página
await page1.click('#button1');
await page2.click('#button2');
// Cerrar la instancia del navegador
await browser.close();
})();En resumen
Las pruebas de navegador sin cabeza son una forma más rápida, confiable y eficiente de probar aplicaciones web en navegadores.
En este artículo, puede aprender fácilmente:
- ¿Qué significa sin cabeza?
- Ventajas y desventajas de los navegadores sin cabeza
- ¿Cómo usar Browserless para pruebas sin cabeza?
Para garantizar una interrupción técnica mínima y maximizar el ROI, las soluciones sin cabeza son la mejor manera de adelantarse a la competencia.
¡Comience a usar Browserless ahora para resolver el problema!
Más





