
Headless Browser
Web Scraping with a Headless Browser: Scraping Dynamic Websites 2024
With the increasing reliance on JavaScript frameworks like React, Angular, Vue.js, and others, many websites have transitioned to dynamic content loaded through Ajax requests. This poses a significant challenge for traditional web scrapers.
Apr 23, 2024Robin Brown
In this journey, we shift our focus to the utilization of headless browsers for scraping dynamic websites. A headless browser is a browser without a graphical user interface that can mimic user interactions such as clicking, scrolling, and form filling. This functionality allows us to scrape websites that require user engagement. What are the available tools for this purpose, and how can we effectively employ them? Along the way, we will encounter various challenges, as well as discover valuable tips and tricks to overcome them.
What is a dynamic web page?
One of the most common website scraping questions is: "Why isn't my scraper able to see the data I'm seeing in my web browser?
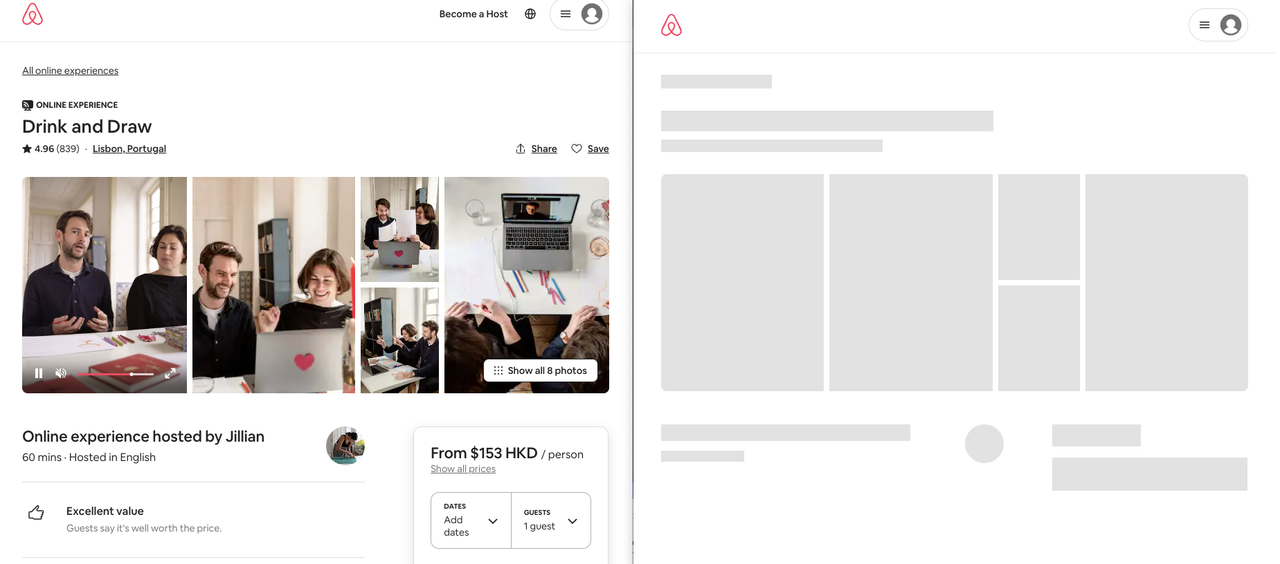
On the left side is what we see in the browser, while on the right side is what our scraper retrieves. So, where does the rest of the data go?
Dynamic web pages utilize complex JavaScript-driven web technologies to offload processing to the client-side. In other words, they provide users with data and logic but require them to be assembled to visualize the complete page. This is why our scraper only sees a blank page.
Here's a simple example:
html
<!DOCTYPE html
<html>
<head>
<title>Dynamic page example</title>
</head>
<body>
<div id="content"loading...</div
<script>
var data = {
name: "John Doe",
age: 30,
city: "New York",
};
document.addEventListener("DOMContentLoaded", function () {
var content = document.getElementById("content");
content.innerHTML = "<h1>" + data.name + "</h1>";
content.innerHTML += "<p>Age: " + data.age + "</p>";
content.innerHTML += "<p>City: " + data.city + "</p>";
});
</script>
</body>
</html>When we open the page and disable JavaScript, we see "loading...". But when JavaScript is enabled, we see "John Doe", "Age: 30", and "City: New York". This is because JavaScript executes after the page is loaded, so our scraper only sees "loading...". Therefore, the scraper doesn't see the fully rendered page as it lacks the capability to load the page using JavaScript like a web browser does.
How can we scrape dynamic websites?
We can scrape dynamic websites by integrating a real browser and manipulating it. There are several tools available for this purpose, such as Puppeteer, Selenium, and Playwright. These tools provide APIs for controlling the browser, allowing us to simulate user behavior.
How does an automated browser work?
Modern browsers like Chrome and Firefox come with built-in automation protocols that allow other programs to control them.
Currently, there are two automation protocols for browsers:
- The newer Chrome DevTools Protocol (CDP): This is the automation protocol for Chrome, which enables other programs to control the Chrome browser.
- The older WebDriver protocol: This is a protocol for controlling browsers, intercepting action requests and issuing browser control commands.
Scraping example
To illustrate this challenge, let's take a real-world webpage scraping example. We will scrape an online website, such as Airbnb experiences. We will briefly describe the demonstration task and explore how to fully render an experience page, for example, https://www.airbnb.com/experiences/1653933, and retrieve the fully rendered content for further processing.
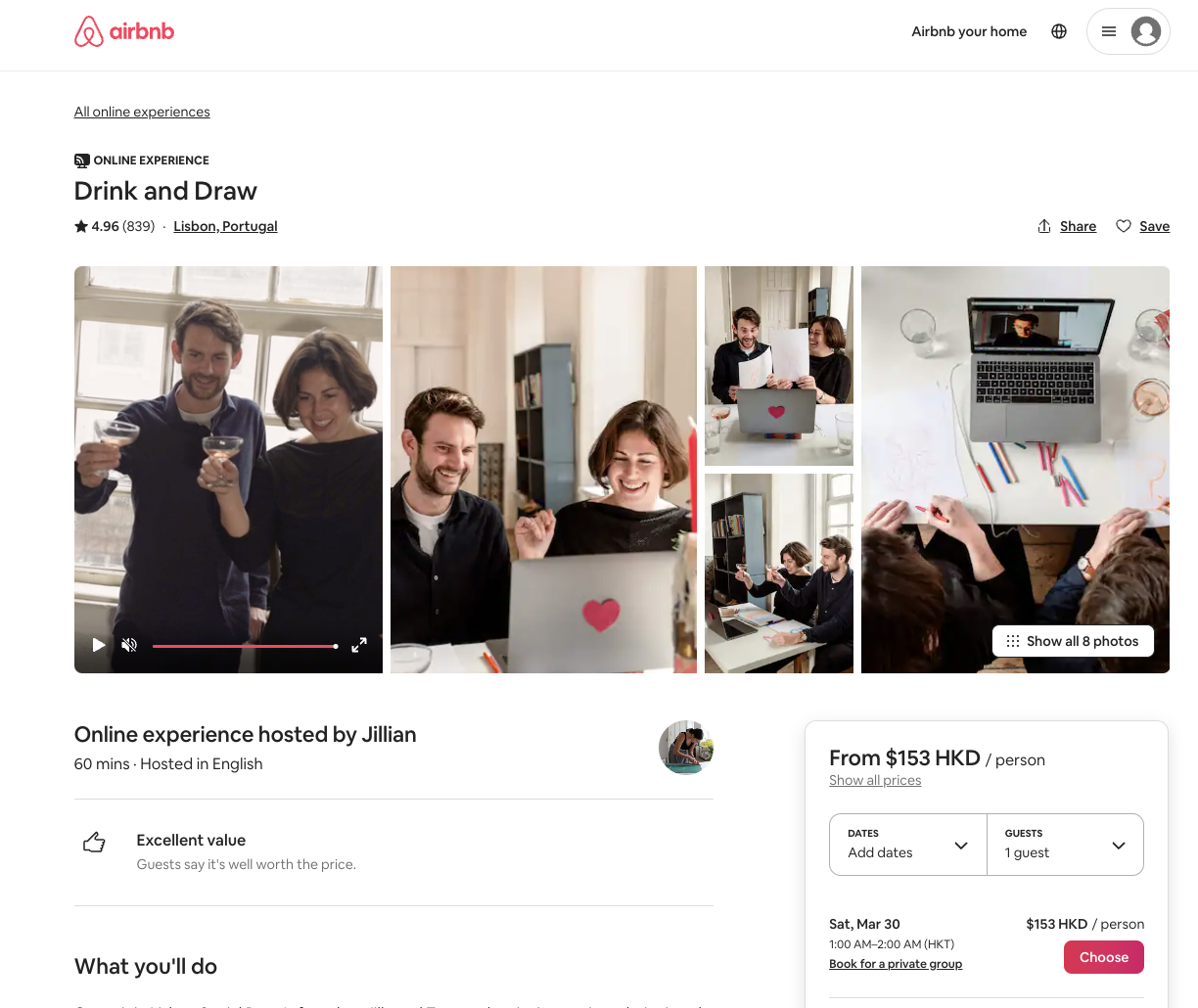
Airbnb is one of the dynamically generated websites built with React worldwide. This means that our crawler won't be able to see the fully rendered page. Without a headless browser, we'd have to reverse engineer the website's code to scrape its complete HTML content. However, with the emergence of headless browsers, we can simulate user behavior to scrape dynamic websites, making our process much simpler.
- Launch a browser (such as Chrome or Firefox).
- Go to the website https://www.airbnb.com/experiences/1653933.
- Wait for the page to load completely.
- Get the entire page's source code and parse the content using the BeautifulSoup parsing library.
Let's now try using four different browser automation tools: Puppeteer, Selenium, Playwright, and Nstbrowser.
Puppeteer
Puppeteer is a Node.js library developed by the Google Chrome team that provides a high-level API to control Chrome or Chromium via the DevTools protocol. It is a headless browser, meaning it has no graphical user interface but can simulate user behavior.
Compared to Selenium, Puppeteer supports fewer languages and browsers, but it fully implements the CDP protocol and benefits from Google's strong team behind it.
Puppeteer also describes itself as a generic browser automation client rather than niche-market suited for web testing—good news since web scraping issues receive official support.
Let's see how our airbnb.com example looks in Puppeteer and JavaScript:
javascript
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://airbnb.com/experiences/1653933');
await page.waitForSelector("h1");
await page.content();
await browser.close();
})();Selenium
Selenium was one of the first large-scale automation clients created for automating website testing. It supports two browser control protocols: WebDriver and CDP (only since Selenium V4+).
Being the oldest tool on today's list means Selenium has a fairly large community and many features. It's supported in almost every programming language and can run on nearly every web browser:
python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.expected_conditions import visibility_of_element_located
chrome_options = Options()
chrome_options.add_argument("--headless")
browser = webdriver.Chrome(chrome_options) # start a web browser
browser.get("https://www.airbnb.com/experiences/1653933") # navigate to URL
# wait for page to load
# by waiting for <h1> element to appear on the page
title = (
WebDriverWait(driver=browser, timeout=10)
.until(visibility_of_element_located((By.CSS_SELECTOR, "h1")))
.text
)
# retrieve fully rendered HTML content
content = browser.page_source
browser.close()
# we then could parse it with beautifulsoup
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, "html.parser")
print(soup.find("h1").text) # you will see the "Drink and Draw"
Above, we first start a web browser window, then navigate to an Airbnb experience page. Next, we wait for the page to load by waiting for the first h1 element to appear on the page. Finally, we extract the HTML content of the page and parse it with BeautifulSoup.
Playwright
Playwright is a synchronous and asynchronous web browser automation library provided by Microsoft in multiple languages.
The main goal of Playwright is reliable end-to-end modern web application testing, although it still implements all common browser automation features (like Puppeteer and Selenium) and has a growing web scraping community.
python
from playwright.sync_api import sync_playwright
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=True)
context = browser.new_context(viewport={"width": 1920, "height": 1080})
page = context.new_page()
page.goto("https://airbnb.com/experiences/1653933") # go to url
page.wait_for_selector('h1')
title = page.inner_text('h1')
print(title) # you will see "Drink and Draw"In the above code, we first launch a Chromium browser, then navigate to an Airbnb experience page. Next, we wait for the page to load, and then extract the HTML content of the page.
Nstbrowser
Nstbrowser is a powerful anti-detection browser designed for professionals managing multiple accounts, enabling secure and efficient management of multiple accounts. Nstbrowser incorporates a range of advanced technologies, including anti-detection browsers, multi-accounts, virtual browsers, browser fingerprints, and account management, providing users with a new browsing experience. Below, we'll use its browser to retrieve webpage content in Headless mode.
Prerequisites
- You need to register as an Nstbrowser user. Register here.
- Obtain an API Key. How to get an API Key? After logging into Nstbrowser, go to the API menu and copy your API Key.
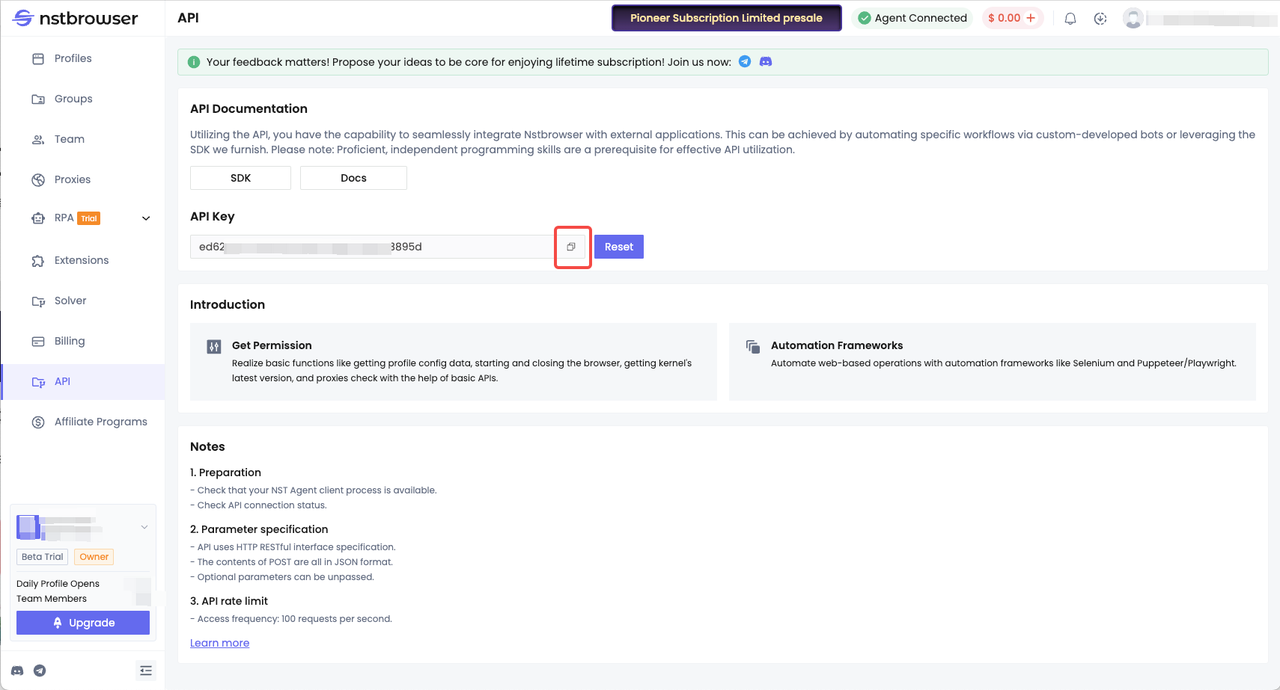
- Based on the Playwright technology we learned above, we continue to use Nstbrowser to retrieve webpage content.
python
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui
import WebDriverWait
from selenium.webdriver.support.expected_conditions import visibility_of_element_located
from selenium.webdriver.chrome.service import Service as ChromeService
# get_debugger_port: Get the debugger port
def get_debugger_port(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
port = resp['data']['port']
return port
except HTTPError:
raise Exception(HTTPError.response)
def exec_selenium(debugger_address: str):
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", debugger_address)
# Replace with the corresponding version of WebDriver path.
chrome_driver_path = r'/Users/xxx/Desktop/chrome_web_driver/chromedriver_mac_arm64/chromedriver'
service = ChromeService(chrome_driver_path)
driver = webdriver.Chrome(service=service, options=options)
driver.get("https://www.airbnb.com/experiences/1653933")
# wait for page to load
# by waiting for <h1> element to appear on the page
title = (
WebDriverWait(driver=driver, timeout=10)
.until(visibility_of_element_located((By.CSS_SELECTOR, "h1")))
.text
)
content = driver.page_source
# we then could parse it with beautifulsoup
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, "html.parser")
print(soup.find("h1").text) # you will see the "Drink and Draw"
driver.close()
driver.quit()
def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'Your API Key Here' # got it from https://app.nstbrowser.io/
config = {
'headless': True, # open browser in headless mode
'remoteDebuggingPort': 9222,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
# userAgent supportted since v0.15.0
'fingerprint': { # required
'name': 'custom browser',
'platform': 'mac', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '113', # support: 113, 115, 118, 120
'hardwareConcurrency': 4, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # support: 2, 4, 8
'proxy': '', # input format: schema://user:password@host:port eg: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # required
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
print('devtool url: ' + url)
port = get_debugger_port(url)
debugger_address = f'{host}:{port}'
print("debugger_address: " + debugger_address)
exec_selenium(debugger_address)
create_and_connect_to_browser()After running successfully, we will see the following results in the console:
Why Use Nstbrowser?
- Real fingerprint browser environment, with a data fingerprint library containing a large amount of real browser fingerprint data, which can simulate the behavior of real users.
- Many times during the crawling process, we encounter CAPTCHA recognition problems. Nstbrowser utilizes artificial intelligence technology to achieve automatic CAPTCHA recognition, allowing you to access any website smoothly.
- It provides an automatic proxy pool rotation function, which can determine the most effective proxy for specific targets.
- Strong compatibility, compatible with Puppeteer, Playwright, and Selenium, with built-in proxy and unlocking technology, much more powerful than automatic browsers and headless browsers.
Summary
Hopefully, through this tutorial, you've learned the following two key points:
- The principle of scraping dynamic websites in Headless mode.
- How to use Puppeteer, Selenium, Playwright, and Nstbrowser.
More





