
Headless Browser
Headless Browser: How to Run It in Playwright?
What is a headlesschrome? How about its advantages and disadvantages? In this blog, we can find all the information about it and learn how to use Nstbrowserless with Playwright to do web scraping.
Jul 15, 2024Carlos Rivera
A traditional browser with a GUI typically consumes a large amount of system resources as the workload expands. In addition, it requires a visible window to render web pages, which slows down test execution and limits scalability.
A headlesschrome is a tool that can smoothly crawl dynamic content without the need for a real browser.
It can resolve the problem of resource-intensive testing, and then allow for more efficient test execution and improved scalability.
So how to run a headless browser in Python and Selenium?
Start reading this article now!
What Is Python Headlesschrome?
Our browser is a computer program that allows users to browse and interact with web pages. On the other hand, the headless browser has no graphical user interface. So what can it do? Is it very different? Yes! This feature helps a Python headlesschrome:
- Navigate to any website on the Internet.
- Render JavaScript files provided by a website.
- Interact with the components of that web page.
Oh, wait! You may have a question about how we can interact with Headlesschrome. There is no GUI at all!
Never mind, dear. Let me show you the Web Driver.
Another question - what's that? The web drive is a framework. It allows us to control various web browsers through programming.
Is there a typical one? Yes, we must all be familiar with Selenium. We use it often but do you know it also is an important headless browser?
Pros of Python headlesschrome:
- Automated tasks. A headless browser can automatically perform browser actions such as clicking, filling forms, submitting, etc. It is suitable for automated testing and task automation.
- Uses less storage. It does not need to draw graphical elements for the browser and website.
- Very fast. The headlesschrome does not need to wait for the page to load out completely, which can significantly speed up the scraping process.
- Simulate real user behavior. It can simulate the user's browser environment and behavior. It helps bypass anti-bot detection.
- Flexibility. It can effortlessly control the behavior of the browser through programming, such as setting request headers, handling cookies, processing page elements, etc. It is really helpful for complex data collection or operations.
- Adaptable. Headlesschrome is able to handle a wide range of websites and dynamic content, such as single-page applications (SPAs) or pages that require JavaScript rendering.
Cons of Python headlesschrome:
- Lack of visual rendering for debugging and testing. Headless browsers do not render pages visually during test execution. So, it becomes more challenging for debugging and testing.
- Stability and reliability issues. Due to changes in the structure of the website or network issues, headlesschrome needs to be handled in due time.
- Update maintenance. Rely on third-party libraries and browser version updates, may need to update the code periodically to adapt to new browser features or fix bugs.
- Anti-crawler measures. Websites always detect and block automated access. So you have to apply several measures to anti-bot detection, such as setting up appropriate request headers, simulating human behavior, and so on.
Nstrowser can highly simulate human behavior to bypass anti-bot and unblock websites!
Try It for Free Now!
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
6 headless browsers supported by Python Selenium
How powerful Selenium is! So, how many headless browsers it supports? Let's finger 6 of them out now! They are controlled and manipulated primarily through WebDriver.
- Chrome
- Firefox
- Edge
- Safari
- Opera
- Chromium
3 best alternatives to Python headlesschromes?
Python Selenium headlesschrome is not the only headless browser!
Let's see other alternatives. Some of them offer only one programming language, and others can offer bindings to multiple languages.
1. Puppeteer
Puppeteer is a Node.js library developed by Google. It provides a high-level API for controlling a headless Chrome or Chromium browser. Puppeteer offers powerful features for automating browser tasks, generating screenshots and PDFs, and executing JavaScript code within web pages.
2. Playwright
Playwright is another web automation tool developed by Microsoft contributors. It is essentially also a Node.js library for browser automation, but it provides APIs for other languages such as Python, .NET, and Java. It is relatively fast compared to Python Selenium.
3. Nstbrowser
What is Nstbrowser?
Nstbrowser is a completely free anti-detect browser. It enables cloud web scraping in headless mode, totally free from local resource constraints. Easily implement web crawling and automation processes.
- Easily perform massively concurrent tasks, effectively saving resources and time.
- Run any script and perform complex browser operations or web crawling tasks with a headless browser.
- Track RAM, CPU, and GPU usage to ensure that the browser is consuming the right amount of resources.
- Respond to sudden increases in traffic by dynamically allocating resources to balance and scale loads.
- Provide dedicated server instances to enjoy higher performance, more flexible configuration options, and better isolation.
How to use Nstbrowserless to achieve Headless?
The following shows how to use Nstbrowserless, use the Nstbrowser anti-detect browser in the docker container and set Headless mode to crawl web data, specifically to crawl Tiktok home page Explore page user avatars as an example:
Step 1. Page analysis
- Enter the TikTok home page.
- Open the console element page.
- Locate the Explore page element.
Then, you can find that the element is an a link element tag with attribute data-e2e="nav-explore".
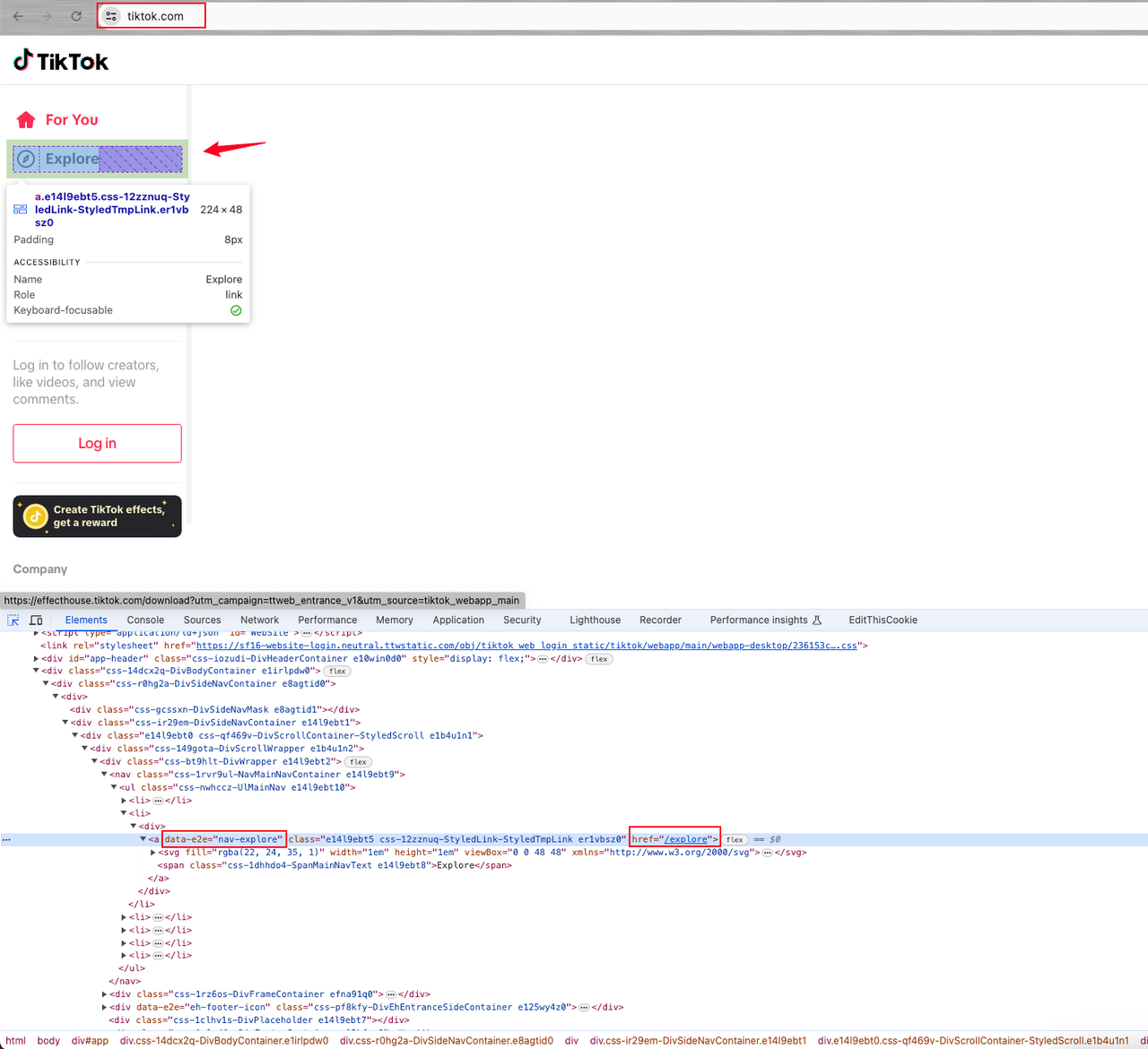
After clicking on the Explore element, we find that the page does not have the user's avatar and we can only get the user's nickname.
Why is that?
That's because we need to click on the nickname to enter the user's home page before we can get the user's avatar.
So, we have to enter the home page of each user, and then find the element with attribute data-e2e="explore-item-list", which is the dynamic list of users:
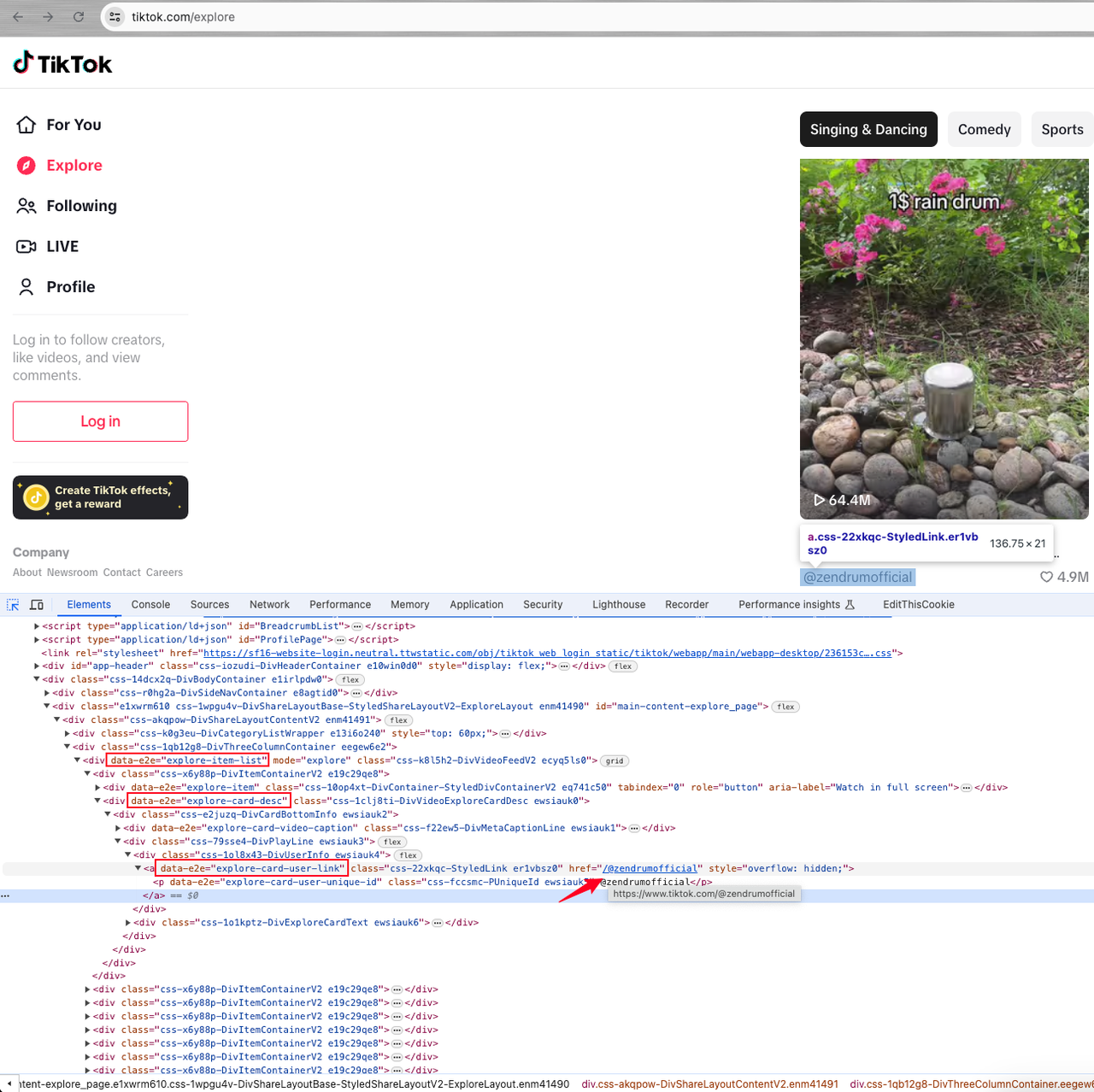
Now, we need to finish some further analysis.
In the div element under the list, there is an element with the attribute data-e2e="explore-card-desc", which contains an a tag with the attribute data-e2e="explore-card-user-link".
The href attribute value of the a tag is the user's id. Adding the TikTok domain name prefix is the user's homepage.
Let's go to the user's homepage and continue the analysis:
Then we can find a div[data-e2e="user-avatar"] with the attribute of div[data-e2e="user-page"], where the user avatar is the src attribute value of the span img element below it.
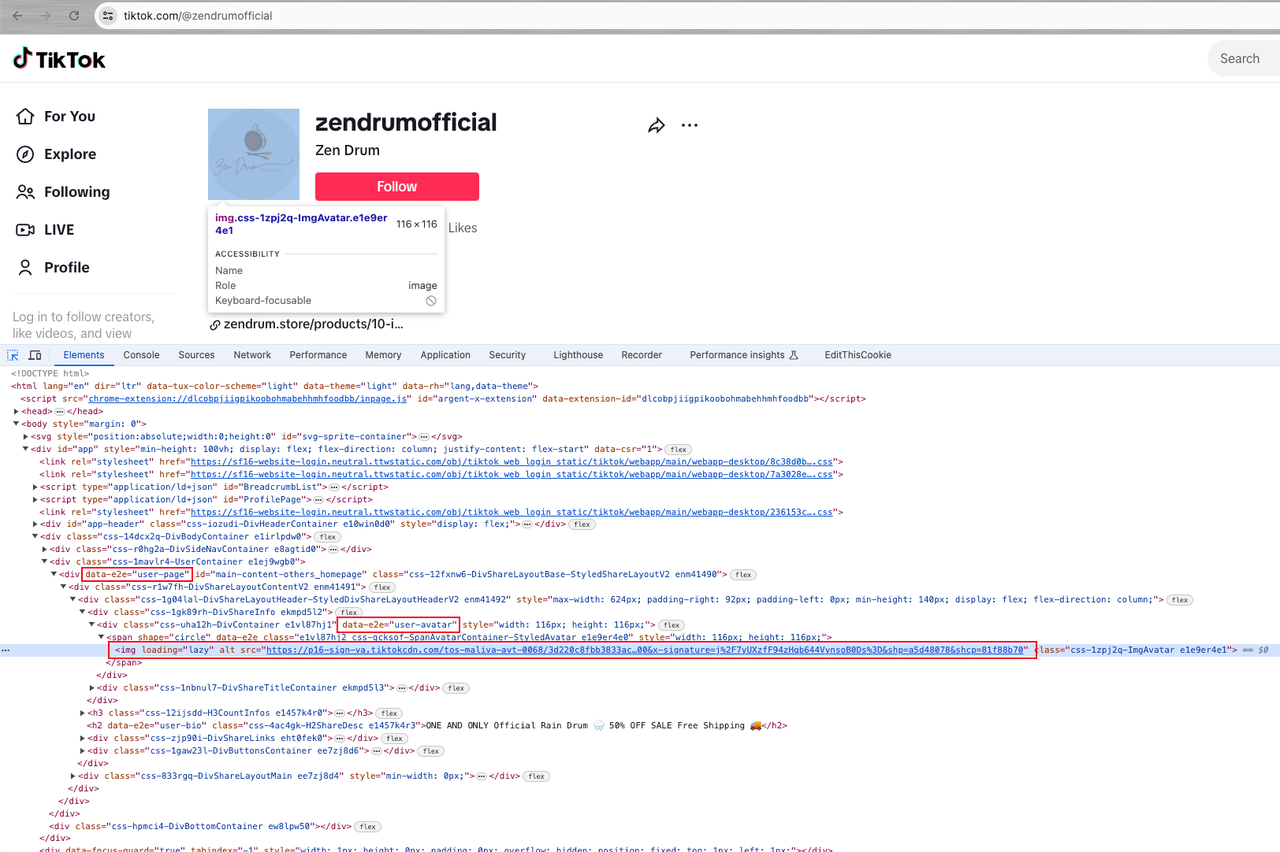
Next, it's time to use Nstbrowserless to get the data we want.
Step 2. Before using Nstbrowserless, you must install and run Docker in advance.
Shell
# pull image
docker pull nstbrowser/browserless:0.0.1-beta
# run nstbrowserless
docker run -it -e TOKEN=xxx -e SERVER_PORT=8848 -p 8848:8848 --name nstbrowserless nstbrowser/browserless:0.0.1-betaStep 3. Coding (Python-Playwright) and set the Headless mode.
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # set headless mode
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # browser args should be a dictionary
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # support: windows, mac, linux
"kernel": 'chromium', # only support: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # support: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # support: 2, 4, 8
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("Profile URL: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("chrome://version")
await page.wait_for_load_state('networkidle')
await page.screenshot(path="chrome_version.png")
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Run the above code and then you can get the following information in chrome://versionpage:

The --headless parameter in the kernel startup command indicates that the kernel is running in headless mode.
Data crawling code:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def scrape_user_profile(browser, user_home_page):
# goto user homepage and scrape user avatar
user_page = await browser.new_page()
try:
await user_page.goto(user_home_page)
await user_page.wait_for_load_state('networkidle')
user_avatar_element = await user_page.query_selector(
'div[data-e2e="user-page"] div[data-e2e="user-avatar"] span img')
if user_avatar_element:
user_avatar = await user_avatar_element.get_attribute('src')
if user_avatar:
print(user_avatar)
# TODO
finally:
await user_page.close()
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # support: true or false
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # browser args should be a dictionary
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # support: windows, mac, linux
"kernel": 'chromium', # only support: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # support: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # support: 2, 4, 8
},
"proxy": "", # set a proper proxy if you can't explore TikTok website
}
query = {
'config': json.dumps(config)
}
profile_url = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profile_url)
tiktok_url = "https://www.tiktok.com"
try:
page = await browser.new_page()
await page.goto(tiktok_url)
await page.wait_for_load_state('networkidle')
explore_elem = await page.query_selector('[data-e2e="nav-explore"]')
if explore_elem:
await explore_elem.click()
ul_element = await page.query_selector('[data-e2e="explore-item-list"]')
if ul_element:
li_elements = await ul_element.query_selector_all('div')
tasks = []
for li in li_elements:
# find user homepage url links
a_element = await li.query_selector('[data-e2e="explore-card-desc"]')
if a_element:
user_link = await li.query_selector('a[data-e2e="explore-card-user-link"]')
if user_link:
href = await user_link.get_attribute('href')
if href:
tasks.append(scrape_user_profile(browser, tiktok_url + href))
await asyncio.gather(*tasks)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Run the program:
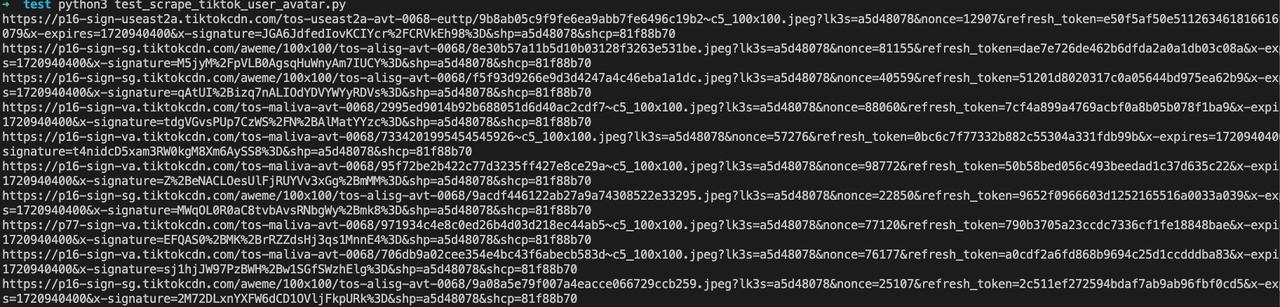
So far, we have completed scraping the user avatar data on the Explore page of the TikTok homepage using Python-Playwright through Nstbrowserless.
The Bottom Lines
Headless browsers have powerful functions and convenient methods of use. They can easily and quickly complete web scraping and automation.
In this article, we learned:
- What is Python headlesschrome?
- The advantages and disadvantages of Python headless chrome.
- How to use Nstbrowserless for fast and efficient web scraping.
More





