
Headless Browser
Headless Browser: How to Run it in Puppeteer?
Web scraping is easy with headlesschrome! What is a headless browser? Why is Puppeteer suitable for web scraping? Find out specific information from this tutorial.
Jul 18, 2024Carlos Rivera
What Is a headless browser?
We all know that the user interface or UI is the most integral part of any software. Therefore, the “headless” part of “headless browsers” means that they are really missing a key element, namely the graphical user interface (GUI).
This means that the browser itself can run normally in the backend (contacting the target website, uploading/downloading documents, presenting information, etc.) but you can't see anything.
Instead, software test engineers prefer to use an interface like a “command line”, where commands are processed as lines of text.
How to detect a headlesschrome?
An anti-detect browser you must need.
Examples of Headless Browsers
- Headlesschrome
- Chromium
- Firefox Headless
- HTML Unit
- Apple Safari (Webkit)
- Zombie.JS
- PhantomJS
- Splash
Why is Puppeteer Best for Web Scraping?
Puppeteer is an open-source Node.js library developed by Google that provides a high-level API to control headless Chrome or Chromium browsers. 7 advantages following described why developers prefer using it to do web scraping.
1. Headlesschrome automation
Puppeteer operates a headless version of Google Chrome, which means it can run without a graphical user interface. This allows for faster and more efficient scraping as it reduces the overhead associated with rendering a full browser window.
2. JavaScript execution
Many modern websites rely heavily on JavaScript to load content dynamically. Traditional scraping tools often struggle with such sites. Puppeteer, however, can execute JavaScript just like a real browser, ensuring that all dynamic content is fully loaded and accessible for scraping.
3. High-quality API
Puppeteer provides a high-quality API that allows for precise control over the browser. This includes actions like clicking buttons, filling out forms, and navigating through pages, which are essential for scraping complex websites.
4. Automated screenshots
One of Puppeteer's features is the ability to take automated screenshots. This can be useful for debugging and verifying that the content has been loaded correctly before scraping.
5. Cross-browser testing
Puppeteer supports cross-browser testing, which means you can test and scrape websites on different browsers like Chrome and Firefox. This flexibility ensures that your scraping scripts are robust and can handle various web environments.
6. Community and extensions
Puppeteer has a strong community and is well-integrated with other tools like TeamCity, Jenkins, and TravisCI. This makes it easier to find support and extensions that can enhance your scraping tasks.
7. Simulates real user interaction
Puppeteer can simulate real user interactions such as mouse movements and keyboard inputs. This makes it harder for websites to detect and block scraping activities, as interactions appear more human-like.
Best Web Scraping Solution - Free Nstbrowser
Unblock websites and bypass anti-bot detection with numerous solutions.
Seamless access to 99.9% unblocked websites.
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
How to Scrape a Website with Puppeteer?
Now, I will show you how to use Nstbrowserless to finish scraping!
What does it mean?
In other words, we need to use Nstbrowser, an anti-detect browser, and set the headless mode in the docker container to crawl the web page data.
Let's take scraping the video link address on the Explore page of the Tiktok homepage as an example specifically:
You may also like: How to Scrape the Avatar with Playwright.
Step 1. Page Analysis
We need to:
- Go to the TikTok homepage.
- Open the console element page and locate the Explore page element. This element is
alink element tag with the attributedata-e2e="nav-explore".
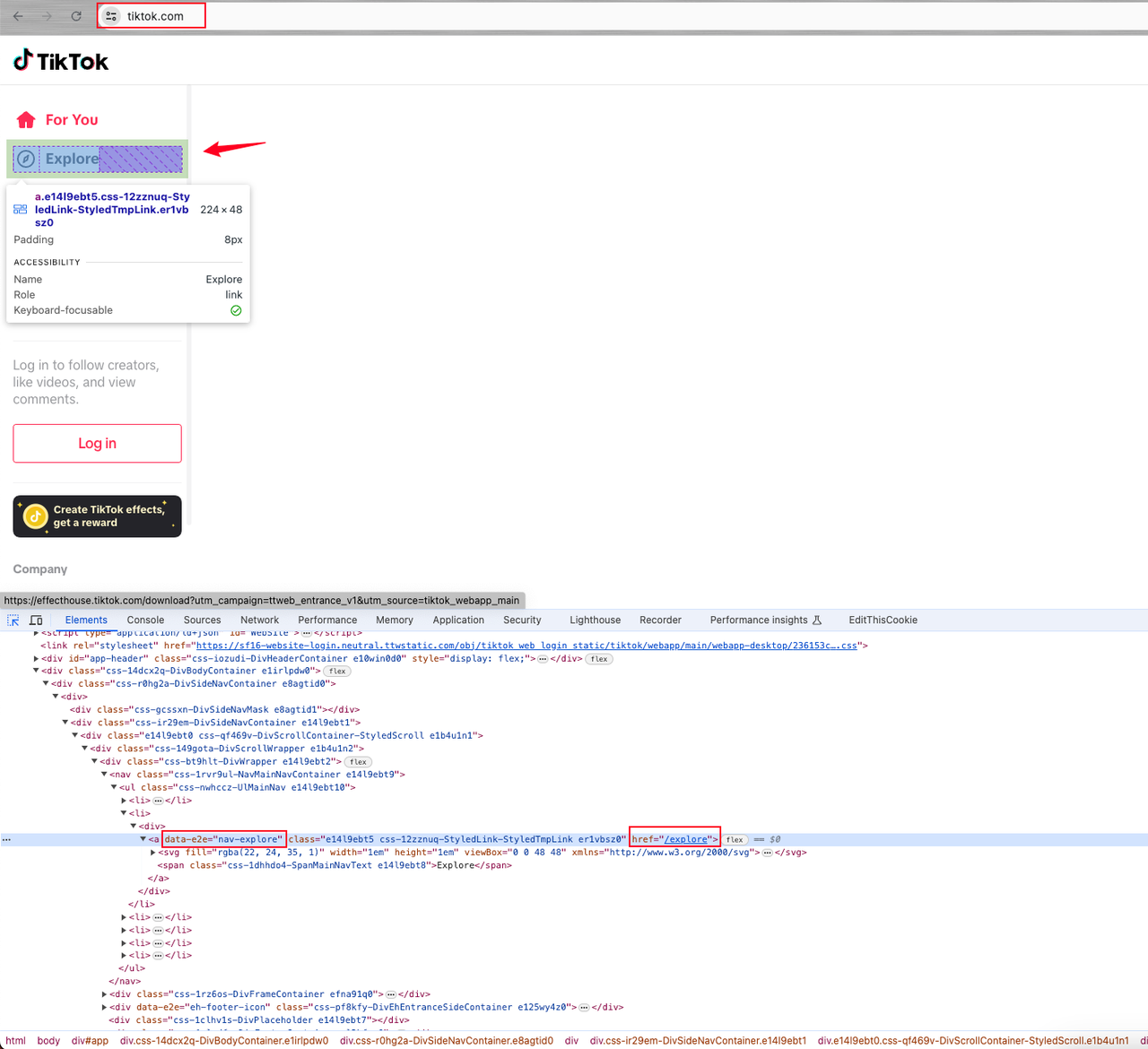
Click the element above to enter the preview page for further analysis.
We can find that the target data we want belongs to a div element item under a list element with the attribute data-e2e="explore-item-list".
Each video element is represented by a data-e2e="explore-item", and the video link we want is the href attribute value of the div a link tag under it.
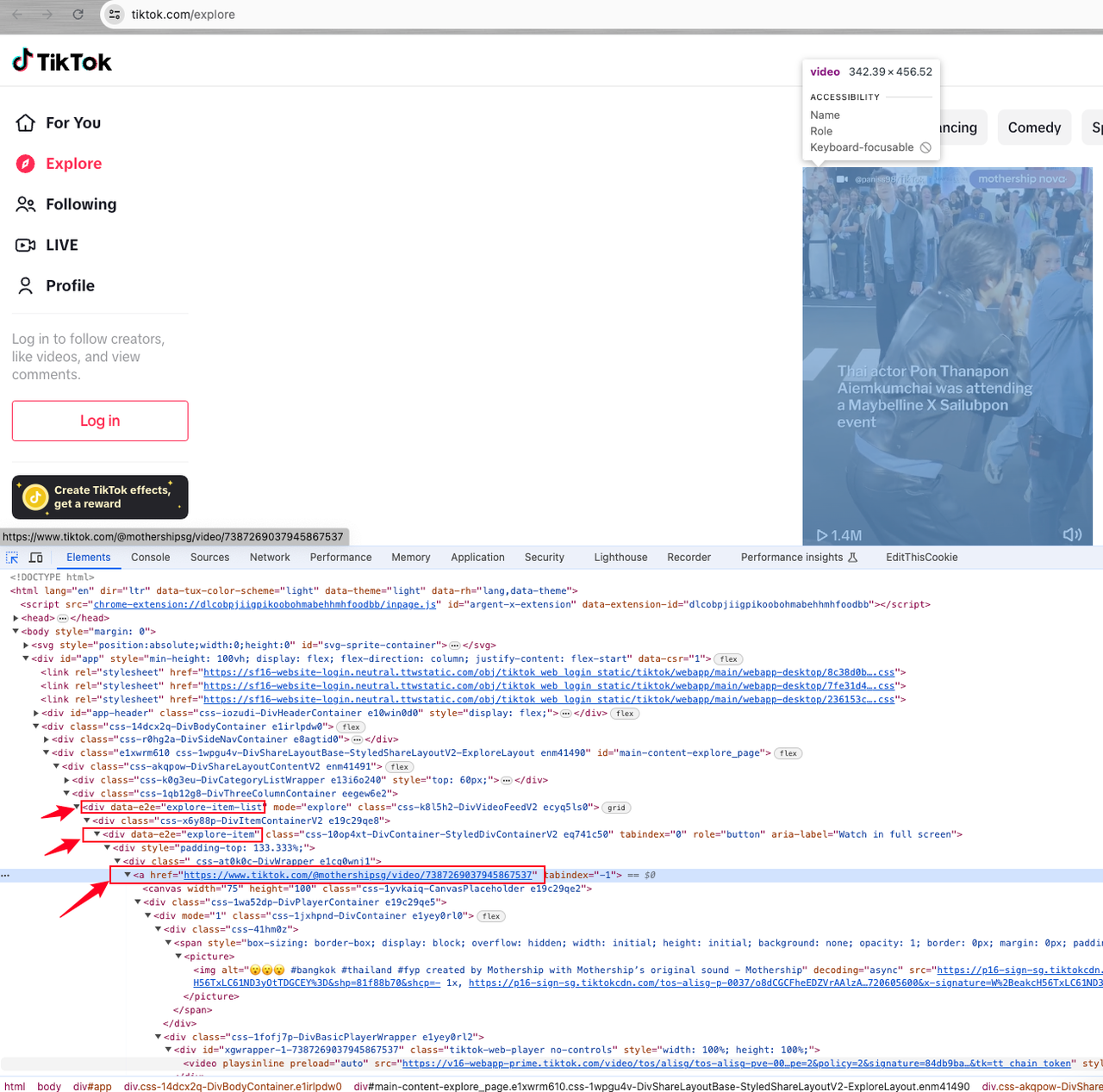
After successfully locating the elements we need, we can enter our scraping process:
Step 2. To use Nstbrowserless, you must install and run Docker in advance.
Shell
# pull image
docker pull nstbrowser/browserless:0.0.1-beta
# run nstbrowserless
docker run -it -e TOKEN=xxx -e SERVER_PORT=8848 -p 8848:8848 --name nstbrowserless nstbrowser/browserless:0.0.1-betaStep 3. Coding (Python-Pyppeteer)
Now we need to set Nstbrowser to headless mode
Python
import json
from urllib.parse import urlencode
from pyppeteer import launcher
async def main():
config = {
"once": True,
"headless": True, # support: true or false
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # browser args should be a list
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # support: windows, mac, linux
"kernel": 'chromium', # only support: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # support: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # support: 2, 4, 8
},
}
query = {
'config': json.dumps(config)
}
browser = await launcher.connect(
browserWSEndpoint=f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
)
page = await browser.newPage()
await page.goto('chrome://version')
await page.screenshot({'path': 'chrome_version.png'})
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())After running the above code, you can see the following information on the chrome://version page:

Adding the --headless parameter to the kernel startup command indicates that the kernel is running in a headless mode.
Overall code display:
Python
import json
from urllib.parse import urlencode
from pyppeteer import launcher
async def main():
config = {
"once": True,
"headless": True, # support: true or false
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # browser args should be a list
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # support: windows, mac, linux
"kernel": 'chromium', # only support: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # support: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # support: 2, 4, 8
},
"proxy": "", # set a proper proxy if you can't explore TikTok website
}
query = {
'config': json.dumps(config)
}
browser = await launcher.connect(
browserWSEndpoint=f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
)
try:
# Create a new page
page = await browser.newPage()
await page.goto("https://www.tiktok.com/")
await page.waitForSelector('[data-e2e="nav-explore"]', {'timeout': 30000})
explore_elem = await page.querySelector('[data-e2e="nav-explore"]')
if explore_elem:
await explore_elem.click()
await page.waitForSelector('[data-e2e="explore-item-list"]', {'timeout': 30000})
ul_element = await page.querySelector('[data-e2e="explore-item-list"]')
if ul_element:
li_elements = await ul_element.querySelectorAll('div')
hrefs = []
for li in li_elements:
a_element = await li.querySelector('[data-e2e="explore-item"] div a')
if a_element:
href = await page.evaluate('(element) => element.getAttribute("href")', a_element)
if href:
print(href)
hrefs.append(href)
# TODO
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Scraping results:
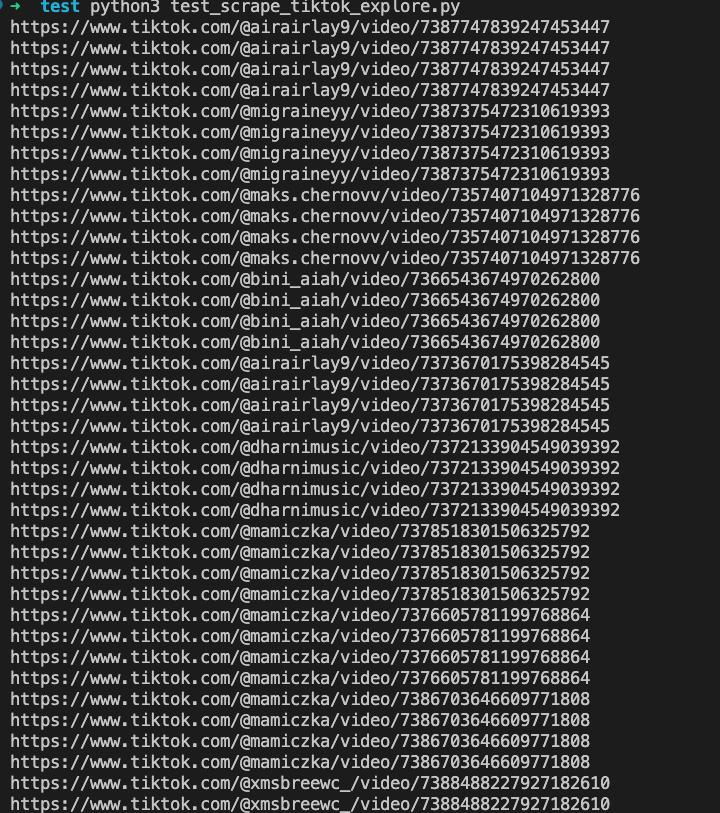
So far, we have completed crawling TikTok video links using the Nstbrowserless. After getting the link, you can further complete the operations you want, such as storing, downloading videos, or redirecting playback.
Of course, this is just a very simple demonstration. If you want to crawl more content, please use Nstbrowser for research and operation effortlessly.
Is Headlesschrome always Good?
While headless browsers are so important in web scraping and automation, it's not all good actually. Please consider the following pros and cons carefully before using it:
Pros:
- A headlesschrome is more efficient when extracting specific data points from a target website, such as competitor product pricing.
- Headless browsers are faster than regular browsers - they load CSS and JavaScript faster and don't need to open and render HTML.
- Headless browsers save developers time, for example, when executing unit test code changes (mobile and desktop), which can be done using the command line.
Cons:
- Headless browser operation is limited to back-end tasks, which means it can't help with front-end issues (e.g. generating GUI screenshots).
- Headless browsers increase speed, but sometimes at a cost, e.g. debugging issues becomes more difficult.
Take Away Notes
A headlesschrome provides many benefits to the web scraping process, allowing you to scrape and automate the process with just a few lines of code. It minimizes memory usage, handles JavaScript perfectly, and runs in a GUI-less environment.
In this guide, you have learned:
- What is a Headless browser?
- The advantages of puppeteers for web scraping
- Detail steps for puppeteer web scraping
In addition, Nstbrowser can easily avoid robot detection, unblock websites, and simplify web scraping and automation.
More





