
Browserless
Browserless:最佳AI驱动浏览器,简化您的网络互动
本文探讨了AI代理与Browserless强大集成以简化和增强网页抓取的方式。
Jan 24, 2025Robin Brown
浏览器自动化和网页抓取已成为开发者、研究人员和企业架构师的工具。人工智能 (AI) 也正在改变这些工具并彻底改变其功能,实现交互式动态、智能数据提取和高级任务自动化。
AI 解决方案可以适应实时变化,即使网站不断发展也能确保一致的性能。本综合指南探讨了 AI 代理和 Browserless 的强大功能,并解释了将两者结合使用带来的所有好处。
什么是 AI 代理?

AI 代理是使用 AI 技术自主执行任务或做出决策而无需直接人工干预的软件系统。这些代理可以模拟类似人类的决策过程,并通过从经验、交互或预定义规则中学习来适应动态环境。
它们可以帮助您执行特定任务、回答问题和根据需要自动化流程。它们可以是简单的基于规则的机器人或复杂的 AI 系统。AI 代理并非自主的,但如果需要,可以是自主的。AI 自主代理也可以在几乎无需人工干预的情况下处理这些任务。
AI 代理的类型
根据复杂性和工作流程,以下是几种最常见的 AI 代理类型:
1. 简单反射代理
简单反射代理基于当前输入或环境状态运行。它们遵循一组预定义的条件-动作规则来决定其响应。这些代理会立即对它们感知到的条件做出反应,而不会考虑过去的经验。
**示例:**基本的电子邮件垃圾邮件过滤器,用于阻止某些邮件。这些过滤器会分析传入电子邮件的内容,并阻止那些包含被识别为垃圾邮件的特定关键字或模式的邮件。
2. 基于模型的反射代理
这些代理维护一个关于世界的内部模型,这有助于它们跟踪事件的历史记录。与简单反射代理不同,它们可以考虑之前的状态以做出更好的决策。它们会根据从环境中收到的反馈来更新其模型。
**示例:**调节温度的恒温器。它不仅对当前温度做出反应,还使用之前的读数来随着时间的推移保持所需的温度。
3. 基于目标的代理
基于目标的代理比反射代理更进一步,因为它具有特定的目标。它们采取行动以实现预定义的目标,并且可以根据情况选择不同的行动。这些代理会预先计划其行动,方法是评估可能使它们更接近目标的行动。
**示例:**导航系统根据当前交通状况、路障和其他因素计算到达目的地的最佳路线。
4. 基于效用的代理
基于效用的代理根据效用概念选择行动,效用衡量的是一项行动对实现目标的益处有多大。这些代理会根据不同行动的结果评估它们,并选择最大化效用或满意度的行动。
**示例:**购物推荐系统根据购买可能性、用户偏好和过去行为推荐产品。它根据其对用户的预期效用对建议进行排名。
5. 学习代理
学习代理可以通过从其环境和经验中学习来随着时间的推移提高其性能。它们使用机器学习算法根据反馈来调整其行为,这有助于它们将来做出更好的决策。
**示例:**虚拟助手随着时间的推移学习用户偏好,例如识别经常提出的问题并调整响应或行动以更好地满足用户的需求。
6. 自主代理
自主代理非常先进,可以在没有人为干预的情况下自行做出决策并执行任务。它们可以适应复杂的环境、规划自己的行动并在实时解决问题。这些代理具有高度的自主性和智能性,通常与高级 AI 模型相结合。
**示例:**在道路上行驶、识别障碍物、遵守交通规则并在没有人为输入的情况下做出驾驶决策的自动驾驶汽车。
7. 协作代理
协作代理旨在与其他代理(AI 或人类)合作以实现共同目标。这些代理共享信息、协调行动并共同解决问题。
它们通常相互交流以共享信息/目标,协调行动和决策,并根据其他代理的行动调整其行为。
**示例:**智能交通管理系统使用多个 AI 代理来优化交通流量。由于每个路口都有一个控制交通灯的代理,因此它可以协调行动以决定显示哪个信号。
什么是 Browserless?
Browserless 是一种基于云的服务,可让您运行无头浏览器,而无需本地设备的限制。它旨在使开发人员能够大规模执行网页抓取任务、自动化测试和其他基于浏览器的自动化任务。
作为一个强大的 AI 网页抓取工具, Nstbrowser Browserless 允许这些网页代理与基于 Web 的系统交互,而无需完整的浏览器界面。例如,您可以使用 Playwright 或 Puppeteer 进行测试生成或可视化分析。主要好处是您可以提高这些代理的速度并使用更少的资源。
然而,它理解自然语言的能力使其有别于其他 AI 网页抓取工具。因为它可以生成类似人类的响应(文本和语音),所以它可以帮助您卸载繁琐的任务。就像人工代理一样,它们可以适应意外情况,例如添加错误的输入或使用错误处理机制。
由于它是全渠道的,它可以处理跨多个渠道(电话、电子邮件、聊天等)的查询,而不会丢失上下文。所有这些都实时发生——最终模拟正常的用户交互。
为什么我们要集成 AI 和 Browserless?
虽然 AI 网页抓取工具在自动化任务方面已经显示出相当大的潜力,但在使用 AI 代理进行页面交互时,仍然需要考虑一些技术挑战和障碍:
动态内容
当今的网站通常依赖 JavaScript 来异步加载数据,传统的代理可能难以捕获或与仅在页面完全呈现后才出现的元素进行交互。
Browserless 可以通过运行完全呈现 JavaScript 的无头浏览器来处理这些动态页面,从而允许 AI 代理像人类用户一样与元素进行交互。
缺少 Web API
许多网站或服务不提供公共 API 来轻松访问其数据。因此,抓取或自动化交互通常需要直接网页抓取和处理复杂的 HTML 结构。这可能导致复杂性增加,并且需要 AI 代理更智能地“理解”和导航网站。
通过将 AI 与 Browserless 相结合,即使 API 不可用,您也可以模拟真实用户的交互。AI 可以智能地识别页面上的关键元素,使代理更容易绕过对正式 API 的需求,并有效地提取或交互数据。Browserless 确保这些交互不会触发机器人检测系统,即使在没有 API 的情况下也是如此。
不可预测的行为
AI 代理通过与第三方系统(如网站、API 或其他外部工具)交互,可能会遇到系统行为不可预测的情况。
您可能会遇到服务中断或 UI 更改,或者可能对下游产生影响的 API。当您大规模运行数百个任务时,这就会成为一个问题,因为它很难准确查明问题所在。
假设您正在使用代理预订航班,并且代理必须处理航空公司网站上出现的一个新弹出窗口,该窗口要求提供有关疫苗信息或优惠券代码的详细信息。如果您没有在工作流程中添加必要的步骤来处理这些弹出窗口,则预订可能无法完成,或者您最终可能会出现预订错误。
通过将 AI 与 Browserless 集成,您可以构建错误处理机制和回退解决方案。AI 可以智能地适应网页布局的变化,识别新元素(例如弹出窗口),并触发特定操作来处理它们。此外,Browserless 允许在没有 GUI 的情况下运行浏览器实例,从而减少识别和响应此类更改的复杂性。
多步骤工作流程
复杂的工作流程通常涉及跨多个系统(每个系统都需要仔细协调和决策)的多个步骤。
在这些情况下,维护跨各种交互的上下文可能具有挑战性,尤其是在涉及多个用户或系统时。
例如,如果您的代理正在帮助用户进行抵押贷款申请,该申请需要从多个系统中提取财务数据,则需要正确的上下文和决策流程才能实现此目的。它可能正在通过信用检查、承销和您自己的申请系统收集数据。
集成 Browserless 允许 AI 代理在浏览器交互稳定且易于扩展的环境中执行这些工作流程,而无需担心因外部系统更改而导致的错误。
优化令牌使用和响应时间
随着 AI 使用规模的增加,令牌使用(在大型语言模型的情况下)和响应时间可能成为问题。随着您扩展任务,每个操作可能需要更多资源,从而增加运营成本和响应延迟。
随着网络流量的增加,在大型网站上运行复杂的查询将涉及解析更多数据,消耗更多资源并增加响应时间。
这就是为什么您需要确保您的工作流程只包含必要的步骤。以下是一些其他优化令牌使用的方法:
- 缓存常用信息
- 使用分层响应系统
- 在适当的情况下使用更小、更特定于任务的模型
- 使用更短、更精确的提示
- 请求更高效的输出格式(项目符号、表格)
如何使用 Browserless 实现 AI 网页抓取?
步骤 1:准备
Browserless 采用以浏览器为中心的方法,提供强大的无头部署功能,并确保更高的性能和可靠性。有关通过 Browserless 开始 AI 网页抓取的更多信息,您可以 获取文档 以了解更多信息。
获取 API 密钥 并转到 Nstbrowser 客户端的 Browserless 菜单页面,或者您可以转到 Nstbrowser 客户端 进行访问
您对网页抓取和 Browserless 有什么精彩的想法和疑问?
让我们看看其他开发者在 Discord 和 Telegram 上分享的内容!
步骤 2:确认爬取目标
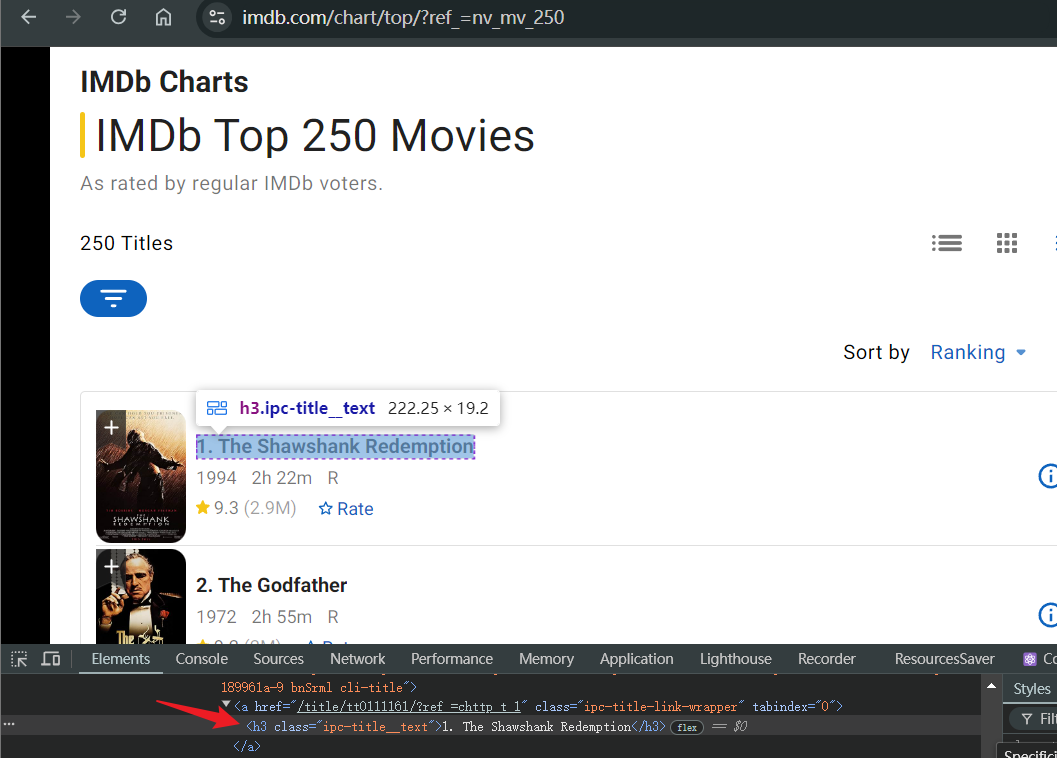
在开始之前,我们需要确保我们要爬取什么。在下面的示例中,我们尝试爬取 IMDb 前 250 部电影 中的电影标题。打开页面后:
- 等待页面正常加载并将页面定位到 IMDb 前 250 部电影下的电影标题
- 打开调试控制台并识别电影标题的 html 元素
- 使用您最喜欢的库获取电影标题
步骤 3:开始爬取
一切准备就绪,开始爬取!我们选择使用 Nstbrowser 提供的强大的云端 Browserless 来爬取上述内容。下面我们将列出一些常用的库。
Puppeteer
如果您还没有选择库,我们强烈推荐 Puppeteer,因为它非常活跃并且有很多维护者。它也是由 Chrome 开发人员构建的,因此它是质量最高的库之一。
- 安装 puppeteer-core
Bash
# pnpm
pnpm i puppeteer-core
# yarn
yarn add puppeteer-core
# npm
npm i --save puppeteer-core- 代码脚本
JavaScript
import puppeteer from "puppeteer-core";
const token = "your api key"; // 'your proxy'
const config = {
proxy: 'your proxy', // required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
// platform: 'windows', // support: windows, mac, linux
// kernel: 'chromium', // only support: chromium
// kernelMilestone: '128', // support: 128
// args: {
// "--proxy-bypass-list": "detect.nstbrowser.io"
// }, // browser args
// fingerprint: {
// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent supportted since v0.15.0
// },
};
const query = new URLSearchParams({
token: token, // required
config: JSON.stringify(config),
});
const browserWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;
// Connect browserless
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
})
console.info('Connected!');
// Create new page
const page = await browser.newPage()
// Visit IMDb top 250 page
await page.goto('https://www.imdb.com/chart/top/?ref_=nv_mv_250')
// Wait for the movie list to load
await page.waitForSelector('.ipc-metadata-list')
// Get a list of movie titles
const moviesList = await page.$$eval('.ipc-metadata-list h3.ipc-title__text', nodes => nodes.map(node => node.textContent));
console.log('[IMDb Top 250 Movies]===>', moviesList);
// Close browser
await browser.close();恭喜!我们完成了抓取任务。您可以在控制台中看到 250 部电影的结果:
Playwright
- 安装 Playwright
Bash
pip install pytest-playwright- 代码脚本
Python
from playwright.sync_api import sync_playwright
from urllib.parse import urlencode
import json
token = "your api key" # 'your proxy'
config = {
"proxy": "your proxy", # required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
# platform: 'windows', // support: windows, mac, linux
# kernel: 'chromium', // only support: chromium
# kernelMilestone: '128', // support: 128
# args: {
# "--proxy-bypass-list": "detect.nstbrowser.io"
# }, // browser args
# fingerprint: {
# userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent supportted since v0.15.0
# },
}
query = urlencode({"token": token, "config": json.dumps(config)})
browser_ws_endpoint = f"ws://less.nstbrowser.io/connect?{query}"
def scrape_imdb_top_250():
with sync_playwright() as p:
# Connect browserless
browser = p.chromium.connect_over_cdp(browser_ws_endpoint)
print("Connected!")
# Create new page
page = browser.new_page()
# Visit IMDb top 250 page
page.goto("https://www.imdb.com/chart/top/?ref_=nv_mv_250")
# Wait for movie list to load
page.wait_for_selector(".ipc-metadata-list")
# Get a list of movie titles
movies_list = page.eval_on_selector_all(
".ipc-metadata-list h3.ipc-title__text",
"nodes => nodes.map(node => node.textContent)",
)
print("[IMDb Top 250 Movies]===>", movies_list)
# Close browser
browser.close()
scrape_imdb_top_250()当然,以下是抓取结果:

选择您喜欢的语言和库,执行相应的脚本,您就可以看到抓取的结果!
3 个热门技术趋势
1. 生成式 AI:
- 生成式 AI 将增强自动化技术,使 AI 能够生成更复杂和个性化的操作策略,从而提高自动化任务的智能化水平。
- AI 可以根据网页内容和用户行为生成最合适的交互解决方案,并自动适应不同类型的反爬虫技术和动态页面。
2. 大型语言模型 (LLM)(GPT、ClaudeAI 等)
- 大型语言模型可以让 AI 代理在执行任务时理解和操作更复杂的网页元素,包括通过自然语言处理技术提取信息和分析网页内容。
- 通过集成 LLM,AI 代理可以在执行自动化任务时进行语言理解、信息提取和分析决策,从而提高任务的灵活性和智能化水平。
3. 行为模拟
- 行为模拟技术使 AI 能够准确模拟真实用户的交互行为,提高隐蔽性并绕过检测系统。
- AI 可以模拟每个用户的独特行为模式,包括鼠标移动、点击习惯和浏览器设置,以防止被识别为机器操作。
AI 代理和 Browserless — 简化您的 Web 自动化
您已经完全理解了 AI 代理的全部内容。AI 代理和 Browserless 的结合将为网页操作带来全面的智能化。
从绕过反爬虫到模拟复杂的用户行为,再到未来的全自动化网页操作平台,AI 和 Browserless 将成为智能网页交互的核心。
更多





