
Browserless
Browserless: Лучший браузер на основе ИИ для упрощения взаимодействия с веб-сайтами
Эта статья исследует мощную интеграцию агентов ИИ с Browserless для оптимизации и улучшения веб-скрапинга.
Jan 24, 2025Robin Brown
Автоматизация браузеров и веб-скрейпинг стали инструментами для разработчиков, исследователей и корпоративных архитекторов. Искусственный интеллект (ИИ) также преобразует эти инструменты и революционизирует их возможности, обеспечивая интерактивную динамику, интеллектуальное извлечение данных и расширенную автоматизацию задач.
Решения на основе ИИ могут адаптироваться к изменениям в реальном времени, обеспечивая стабильную производительность даже при эволюции веб-сайтов. В этом подробном руководстве рассматривается потенциал агента ИИ и Browserless, а также объясняются все преимущества их сочетания.
Что такое агент ИИ?

Агенты ИИ — это программные системы, которые используют технологии ИИ для автономного выполнения задач или принятия решений без прямого вмешательства человека. Эти агенты могут имитировать процессы принятия решений, подобные человеческим, и адаптироваться к динамичным средам, обучаясь на своем опыте, взаимодействиях или предопределенных правилах.
Они могут помочь вам выполнять определенные задачи, отвечать на вопросы и автоматизировать процессы по мере необходимости. Они могут быть простыми роботами на основе правил или сложными системами ИИ. Агенты ИИ не являются автономными, но могут быть автономными, если это необходимо. Автономные агенты ИИ также могут обрабатывать эти задачи с минимальным участием человека.
Типы агентов ИИ
В зависимости от сложности и рабочего процесса, наиболее распространенными типами агентов ИИ являются:
1. Простые рефлекторные агенты
Простые рефлекторные агенты работают на основе текущего входного сигнала или состояния среды. Они следуют набору предопределенных правил «условие-действие», чтобы определять свои ответы. Эти агенты реагируют немедленно на воспринимаемые ими условия, не принимая во внимание прошлый опыт.
Пример: Базовые фильтры спама электронной почты, блокирующие определенные сообщения. Эти фильтры анализируют содержимое входящих писем и блокируют те, которые содержат определенные ключевые слова или шаблоны, идентифицированные как спам.
2. Рефлекторные агенты на основе модели
Эти агенты поддерживают внутреннюю модель мира, которая помогает им отслеживать историю событий. В отличие от простых рефлекторных агентов, они могут учитывать предыдущие состояния для принятия более обоснованных решений. Они обновляют свою модель на основе обратной связи, полученной из окружающей среды.
Пример: Термостат, который регулирует температуру. Он не просто реагирует на текущую температуру, но также использует предыдущие показания для поддержания желаемой температуры в течение времени.
3. Целевые агенты
Целевые агенты идут дальше, чем рефлекторные агенты, имея конкретные цели. Они предпринимают действия для достижения предопределенной цели и могут выбирать различные действия в зависимости от ситуации. Эти агенты планируют свои действия заранее, оценивая возможные действия, которые приближают их к своей цели.
Пример: Навигационная система, которая рассчитывает оптимальный маршрут до пункта назначения на основе текущих условий дорожного движения, дорожных препятствий и других факторов.
4. Агенты на основе полезности
Агенты на основе полезности выбирают действия на основе концепции полезности, которая измеряет, насколько выгодно действие способствует достижению цели. Эти агенты оценивают различные возможные действия на основе их результатов и выбирают то, которое максимизирует полезность или удовлетворение.
Пример: Система рекомендаций покупок, которая предлагает товары на основе вероятности покупки, предпочтений пользователя и прошлого поведения. Она ранжирует предложения в соответствии с их ожидаемой полезностью для пользователя.
5. Агенты, способные к обучению
Агенты, способные к обучению, могут улучшать свою производительность с течением времени, обучаясь на своей среде и опыте. Они используют алгоритмы машинного обучения для адаптации своего поведения на основе обратной связи, что помогает им принимать лучшие решения в будущем.
Пример: Виртуальный помощник, который со временем узнает предпочтения пользователя, например, распознает часто задаваемые вопросы и адаптирует ответы или действия для лучшего соответствия потребностям пользователя.
6. Автономные агенты
Автономные агенты являются высокоразвитыми и могут принимать решения и выполнять задачи самостоятельно без вмешательства человека. Они могут адаптироваться к сложным средам, планировать свои действия и решать проблемы в реальном времени. Эти агенты обладают высокой степенью автономии и интеллекта, часто в сочетании с передовыми моделями ИИ.
Пример: Автономные транспортные средства, которые перемещаются по дорогам, распознают препятствия, следуют правилам дорожного движения и принимают решения о вождении без участия человека.
7. Коллаборативные агенты
Коллаборативные агенты предназначены для работы с другими агентами (ИИ или людьми) для достижения общей цели. Эти агенты обмениваются информацией, координируют действия и совместно решают проблемы.
Они обычно общаются друг с другом для обмена информацией/целями, координации действий и решений, а также корректировки своего поведения в зависимости от действий других агентов.
Пример: Интеллектуальные системы управления дорожным движением используют несколько агентов ИИ для оптимизации потока транспорта. Поскольку на каждом перекрестке есть агент, управляющий светофорами, он может координировать действия для определения того, какой сигнал отображать.
Что такое Browserless?
Browserless — это облачная служба, которая позволяет запускать браузер без графического интерфейса без ограничений локального устройства. Он предназначен для того, чтобы позволить разработчикам выполнять задачи веб-скрейпинга, автоматизированного тестирования и другой автоматизации на основе браузера в масштабе.
Как мощный веб-скрейпер на основе ИИ, Nstbrowser Browserless позволяет этим веб-агентам взаимодействовать с веб-системами без необходимости использования полного интерфейса браузера. Например, вы можете использовать Playwright или Puppeteer для генерации тестов или визуального анализа. Основное преимущество заключается в том, что вы можете увеличить скорость этих агентов и использовать меньше ресурсов.
Тем не менее, его способность понимать естественный язык отличает его от других веб-скрейперов на основе ИИ. Поскольку он может генерировать ответы, похожие на человеческие (как текстовые, так и голосовые), он может помочь вам снять с себя рутинные задачи. Подобно агентам-людям, они могут адаптироваться к неожиданным ситуациям, таким как добавление ошибочных входных данных или использование механизмов обработки ошибок.
Поскольку он является омниканальным, он может обрабатывать запросы по нескольким каналам (телефон, электронная почта, чат и т. д.) без потери контекста. Все это происходит в реальном времени — в конечном итоге имитируя обычное человеческое взаимодействие.
Почему мы должны интегрировать ИИ и Browserless?
Хотя инструменты веб-скрейпинга на основе ИИ продемонстрировали значительный потенциал в автоматизации задач, при использовании агентов ИИ для взаимодействия со страницами все еще необходимо учитывать несколько технических проблем и препятствий:
Динамический контент
Современные веб-сайты часто используют JavaScript для асинхронной загрузки данных, и традиционные агенты могут испытывать трудности с захватом или взаимодействием с элементами, которые появляются только после полной отрисовки страницы.
Browserless может обрабатывать эти динамические страницы, запуская браузеры без графического интерфейса, которые полностью отображают JavaScript, позволяя агентам ИИ взаимодействовать с элементами так же, как это делал бы пользователь.
Отсутствие веб-API
Многие веб-сайты или службы не предоставляют общедоступных API для легкого доступа к своим данным. В результате для извлечения данных или автоматизации взаимодействий часто требуется прямой веб-скрейпинг и работа со сложными структурами HTML. Это может привести к увеличению сложности и необходимости для агентов ИИ «понимать» и ориентироваться на веб-сайтах более интеллектуально.
Комбинируя ИИ с Browserless, вы можете имитировать взаимодействие реальных пользователей, даже если API недоступен. ИИ может интеллектуально идентифицировать ключевые элементы на странице, упрощая агентам обход необходимости в формальных API и эффективное извлечение или взаимодействие с данными. Browserless гарантирует, что эти взаимодействия происходят без срабатывания систем обнаружения ботов, даже при отсутствии API.
Непредсказуемое поведение
Агенты ИИ, взаимодействуя с системами третьих сторон (такими как веб-сайты, API или другие внешние инструменты), могут сталкиваться с ситуациями, когда поведение системы непредсказуемо.
Вы можете столкнуться с перебоями в работе сервиса или изменением пользовательского интерфейса, или API, которые могут иметь последствия. Это становится проблемой, когда вы выполняете сотни задач в масштабе, поскольку может быть сложно точно определить, что пошло не так.
Допустим, вы используете агента для бронирования рейса, и агенту приходится обрабатывать новое всплывающее окно на веб-сайте авиакомпании, в котором запрашиваются данные о вакцинации или купонном коде. Если вы не добавите необходимые шаги в свой рабочий процесс для обработки этих всплывающих окон, бронирование может не состояться, или вы можете получить ошибку бронирования.
Интегрируя ИИ с Browserless, вы можете создавать механизмы обработки ошибок и резервные решения. ИИ может интеллектуально адаптироваться к изменениям в макете веб-страницы, идентифицировать новые элементы (например, всплывающие окна) и запускать определенные действия для их обработки. Кроме того, Browserless позволяет запускать экземпляры браузера без графического интерфейса, что снижает сложность идентификации и реагирования на такие изменения.
Многошаговые рабочие процессы
Сложные рабочие процессы часто включают в себя несколько шагов, которые охватывают несколько систем, каждый из которых требует тщательной координации и принятия решений.
В этих случаях поддержание контекста во время различных взаимодействий может стать сложной задачей, особенно когда задействовано несколько пользователей или систем.
Например, если ваш агент помогает пользователю с ипотечным заявлением, которому необходимо извлечь финансовые данные из нескольких систем, необходим правильный контекст и поток принятия решений для реализации этого. Это может быть сбор данных через проверку кредитоспособности, андеррайтинг и вашу собственную систему заявок.
Интеграция Browserless позволяет агентам ИИ выполнять эти рабочие процессы в среде, где взаимодействие с браузером стабильно и может легко масштабироваться, без риска ошибок из-за изменений во внешних системах.
Оптимизация использования токенов и времени отклика
По мере увеличения масштаба использования ИИ использование токенов (в случае больших языковых моделей) и время отклика могут стать проблематичными. По мере масштабирования задач каждая операция может требовать больше ресурсов, увеличивая операционные затраты и задержки отклика.
По мере увеличения веб-трафика выполнение сложных запросов на больших веб-сайтах будет включать в себя анализ больших объемов данных, потребление большего количества ресурсов и увеличение времени отклика.
Поэтому вам необходимо убедиться, что ваш рабочий процесс содержит только необходимые шаги. Вот несколько других способов оптимизации использования токенов:
- Кэширование часто используемой информации
- Использование многоуровневой системы ответов
- Использование меньших, специализированных моделей, когда это уместно
- Использование более коротких и точных запросов
- Запрос более эффективных форматов вывода (маркеры, таблицы)
Как достичь веб-скрейпинга на основе ИИ с помощью Browserless?
Шаг 1: Подготовка
Browserless использует браузерно-ориентированный подход, обеспечивает мощные возможности развертывания без графического интерфейса и обеспечивает более высокую производительность и надежность. Для получения дополнительной информации о начале работы с веб-скрейпингом на основе ИИ через Browserless вы можете получить документ, чтобы узнать больше.
Получите API KEY и перейдите на страницу меню Browserless клиента Nstbrowser, или вы можете перейти к клиенту Nstbrowser для доступа.
Есть ли у вас замечательные идеи и сомнения по поводу веб-скрейпинга и Browserless?
Давайте посмотрим, что другие разработчики делятся на Discord и Telegram!
Шаг 2: Подтверждение цели обхода
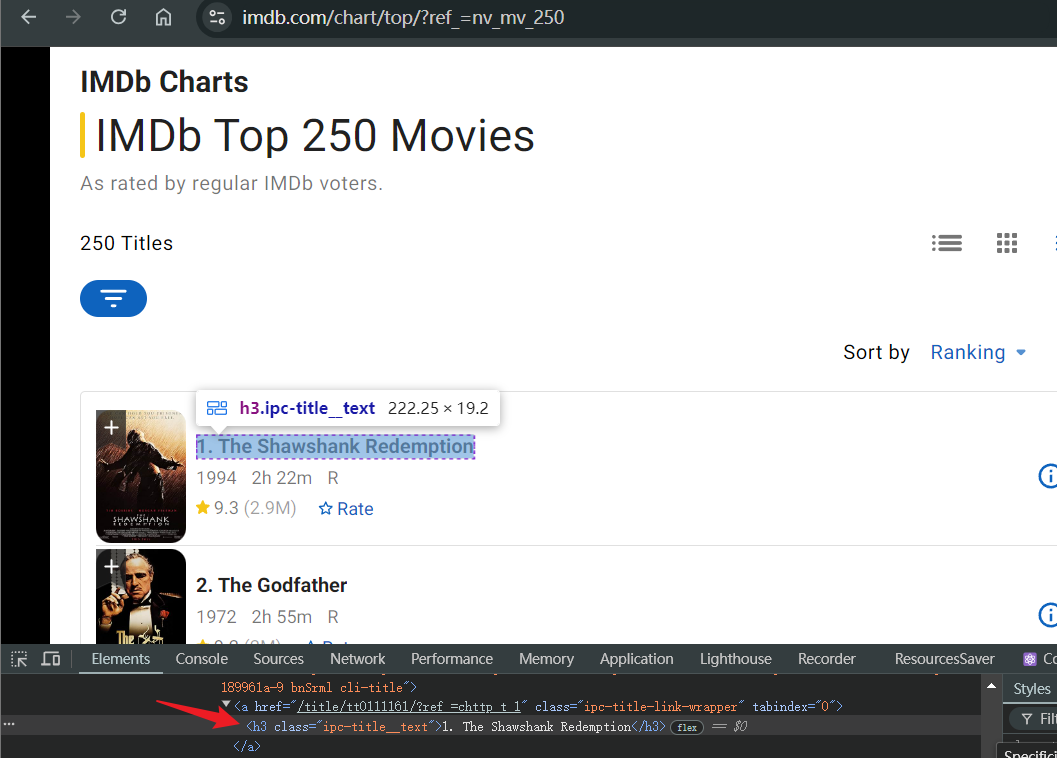
Прежде чем начать, нам нужно убедиться, что мы собираемся обходить. В следующем примере мы пытаемся извлечь названия фильмов в IMDb's Top 250 Movies. После открытия страницы:
- Дождитесь обычной загрузки страницы и найдите страницу с названием фильма в списке IMDb Top 250 Movies
- Откройте консоль отладки и определите HTML-элемент названия фильма
- Используйте свою любимую библиотеку для получения названия фильма
Шаг 3: Начало обхода
Все готово, начните обход! Мы решили использовать мощный облачный Browserless, предоставляемый Nstbrowser, для обхода указанного выше содержимого. Ниже мы перечислим некоторые из часто используемых библиотек.
Puppeteer
Если вы еще не выбрали библиотеку, мы настоятельно рекомендуем Puppeteer, поскольку она очень активна и имеет много разработчиков. Она также создана разработчиками Chrome, поэтому является одной из самых качественных библиотек.
- Установите puppeteer-core
Bash
# pnpm
pnpm i puppeteer-core
# yarn
yarn add puppeteer-core
# npm
npm i --save puppeteer-core- Скрипт кода
JavaScript
import puppeteer from "puppeteer-core";
const token = "ваш api ключ"; // 'ваш прокси'
const config = {
proxy: 'ваш прокси', // необходимо; формат ввода: schema://user:password@host:port например: http://user:password@localhost:8080
// platform: 'windows', // поддерживает: windows, mac, linux
// kernel: 'chromium', // поддерживает только: chromium
// kernelMilestone: '128', // поддерживает: 128
// args: {
// "--proxy-bypass-list": "detect.nstbrowser.io"
// }, // аргументы браузера
// fingerprint: {
// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent поддерживается с версии v0.15.0
// },
};
const query = new URLSearchParams({
token: token, // необходимо
config: JSON.stringify(config),
});
const browserWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;
// Подключение browserless
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
})
console.info('Подключено!');
// Создание новой страницы
const page = await browser.newPage()
// Посещение страницы IMDb top 250
await page.goto('https://www.imdb.com/chart/top/?ref_=nv_mv_250')
// Ожидание загрузки списка фильмов
await page.waitForSelector('.ipc-metadata-list')
// Получение списка названий фильмов
const moviesList = await page.$$eval('.ipc-metadata-list h3.ipc-title__text', nodes => nodes.map(node => node.textContent));
console.log('[IMDb Top 250 Movies]===>', moviesList);
// Закрытие браузера
await browser.close();Поздравляем! Мы завершили задачу по извлечению данных. Вы можете увидеть результат из 250 фильмов в консоли:
Playwright
- Установите Playwright
Bash
pip install pytest-playwright- Скрипт кода
Python
from playwright.sync_api import sync_playwright
from urllib.parse import urlencode
import json
token = "ваш api ключ" # 'ваш прокси'
config = {
"proxy": "ваш прокси", # необходимо; формат ввода: schema://user:password@host:port например: http://user:password@localhost:8080
# platform: 'windows', // поддерживает: windows, mac, linux
# kernel: 'chromium', // поддерживает только: chromium
# kernelMilestone: '128', // поддерживает: 128
# args: {
# "--proxy-bypass-list": "detect.nstbrowser.io"
# }, // аргументы браузера
# fingerprint: {
# userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent поддерживается с версии v0.15.0
# },
}
query = urlencode({"token": token, "config": json.dumps(config)})
browser_ws_endpoint = f"ws://less.nstbrowser.io/connect?{query}"
def scrape_imdb_top_250():
with sync_playwright() as p:
# Подключение browserless
browser = p.chromium.connect_over_cdp(browser_ws_endpoint)
print("Подключено!")
# Создание новой страницы
page = browser.new_page()
# Посещение страницы IMDb top 250
page.goto("https://www.imdb.com/chart/top/?ref_=nv_mv_250")
# Ожидание загрузки списка фильмов
page.wait_for_selector(".ipc-metadata-list")
# Получение списка названий фильмов
movies_list = page.eval_on_selector_all(
".ipc-metadata-list h3.ipc-title__text",
"nodes => nodes.map(node => node.textContent)",
)
print("[IMDb Top 250 Movies]===>", movies_list)
# Закрытие браузера
browser.close()
scrape_imdb_top_250()Конечно, вот результат извлечения данных:

Выберите свой любимый язык и библиотеку, запустите соответствующий скрипт, и вы увидите результаты извлечения данных!
3 горячих технологических тренда
1. Генеративный ИИ:
- Генеративный ИИ расширит возможности технологий автоматизации, позволяя ИИ генерировать более сложные и персонализированные стратегии работы, тем самым повышая интеллект автоматизированных задач.
- ИИ может генерировать наиболее подходящие решения для взаимодействия на основе веб-контента и поведения пользователей и автоматически адаптироваться к различным типам анти-краулерных технологий и динамическим страницам.
2. Большие языковые модели (GPT, ClaudeAI и т. д.)
- Большие языковые модели позволяют агентам ИИ понимать и обрабатывать более сложные веб-элементы при выполнении задач, включая извлечение информации и анализ веб-контента, с помощью технологии обработки естественного языка.
- Интегрируя большие языковые модели, агенты ИИ могут выполнять понимание языка, извлечение информации и аналитическое принятие решений при выполнении автоматизированных задач, повышая гибкость и интеллект задач.
3. Моделирование поведения
- Технология моделирования поведения позволяет ИИ точно имитировать интерактивное поведение реальных пользователей, повышать скрытность и обходить системы обнаружения.
- ИИ может имитировать уникальные модели поведения каждого пользователя, включая движения мыши, привычки кликов и настройки браузера, чтобы предотвратить идентификацию как машинные операции.
Агент ИИ и Browserless — упрощают вашу веб-автоматизацию
Вы полностью поняли все содержимое агента ИИ. Сочетание агента ИИ и Browserless обеспечит всесторонний интеллект для работы с веб-страницами.
От обхода анти-краулеров до имитации сложного поведения пользователей и до будущей полностью автоматизированной платформы работы с веб-страницами, ИИ и Browserless станут ядром интеллектуального взаимодействия с веб-страницами.
Больше





