
Browserless
Browserless: El mejor navegador impulsado por IA para simplificar tus interacciones web
Este artículo explora la potente integración de agentes de IA con Browserless para optimizar y mejorar el raspado web.
Jan 24, 2025Robin Brown
La automatización de navegadores y el web scraping se han convertido en herramientas para desarrolladores, investigadores y arquitectos empresariales. La inteligencia artificial (IA) también está transformando estas herramientas y revolucionando sus capacidades, permitiendo dinámicas interactivas, extracción inteligente de datos y automatización avanzada de tareas.
Las soluciones de IA pueden adaptarse a los cambios en tiempo real, asegurando un rendimiento consistente incluso a medida que los sitios web evolucionan. Esta guía completa examina el poder del agente de IA y Browserless, y explica todos los beneficios de combinarlos.
¿Qué es un agente de IA?

Los agentes de IA son sistemas de software que utilizan la tecnología de IA para realizar tareas de forma autónoma o tomar decisiones sin intervención humana directa. Estos agentes pueden simular procesos de toma de decisiones similares a los humanos y adaptarse a entornos dinámicos aprendiendo de su experiencia, interacciones o reglas predefinidas.
Pueden ayudarlo a realizar tareas específicas, responder preguntas y automatizar procesos según sea necesario. Pueden ser robots simples basados en reglas o sistemas de IA complejos. Los agentes de IA no son autónomos, pero pueden serlo si es necesario. Los agentes autónomos de IA también pueden manejar estas tareas con muy poca intervención humana.
Tipos de agentes de IA
Según la complejidad y el flujo de trabajo, los siguientes son los tipos más comunes de agentes de IA:
1. Agentes de reflejo simple
Los agentes de reflejo simple operan en función de la entrada o estado actual del entorno. Siguen un conjunto de reglas de condición-acción predefinidas para decidir sus respuestas. Estos agentes reaccionan inmediatamente a las condiciones que perciben sin tener en cuenta la experiencia pasada.
Ejemplo: Filtros básicos de correo electrónico no deseado que bloquean ciertos mensajes. Estos filtros analizan el contenido de los correos electrónicos entrantes y bloquean aquellos que contienen palabras clave o patrones específicos identificados como correo no deseado.
2. Agentes de reflejo basados en modelos
Estos agentes mantienen un modelo interno del mundo, que les ayuda a realizar un seguimiento del historial de eventos. A diferencia de los agentes de reflejo simple, pueden tener en cuenta estados anteriores para tomar mejores decisiones. Actualizan su modelo en función de los comentarios recibidos del entorno.
Ejemplo: Un termostato que ajusta la temperatura. No solo reacciona a la temperatura actual, sino que también utiliza lecturas anteriores para mantener la temperatura deseada a lo largo del tiempo.
3. Agentes basados en objetivos
Los agentes basados en objetivos van un paso más allá que los agentes de reflejo al tener objetivos específicos. Realizan acciones para lograr un objetivo predefinido y pueden elegir diferentes acciones según la situación. Estos agentes planifican sus acciones con anticipación evaluando posibles acciones que los acerquen a su objetivo.
Ejemplo: Un sistema de navegación que calcula la mejor ruta a un destino en función de las condiciones actuales del tráfico, los bloqueos de carreteras y otros factores.
4. Agentes basados en la utilidad
Los agentes basados en la utilidad eligen acciones en función del concepto de utilidad, que mide cuánto beneficio proporciona una acción para lograr un objetivo. Estos agentes evalúan diferentes acciones posibles en función de sus resultados y seleccionan la que maximiza la utilidad o satisfacción.
Ejemplo: Un sistema de recomendación de compras que sugiere productos en función de la probabilidad de compra, las preferencias del usuario y el comportamiento pasado. Clasifica las sugerencias según su utilidad esperada para el usuario.
5. Agentes de aprendizaje
Los agentes de aprendizaje pueden mejorar su rendimiento con el tiempo aprendiendo de su entorno y experiencias. Utilizan algoritmos de aprendizaje automático para adaptar su comportamiento en función de los comentarios, lo que les ayuda a tomar mejores decisiones en el futuro.
Ejemplo: Un asistente virtual que aprende las preferencias del usuario con el tiempo, como reconocer preguntas frecuentes y adaptar las respuestas o acciones para satisfacer mejor las necesidades del usuario.
6. Agentes autónomos
Los agentes autónomos son muy avanzados y pueden tomar decisiones y realizar tareas por sí mismos sin intervención humana. Pueden adaptarse a entornos complejos, planificar sus propias acciones y resolver problemas en tiempo real. Estos agentes tienen un alto nivel de autonomía e inteligencia, a menudo combinados con modelos de IA avanzados.
Ejemplo: Vehículos autónomos que navegan por carreteras, reconocen obstáculos, siguen las normas de tráfico y toman decisiones de conducción sin intervención humana.
7. Agentes colaborativos
Los agentes colaborativos están diseñados para trabajar con otros agentes (IA o humanos) para lograr un objetivo común. Estos agentes comparten información, coordinan acciones y resuelven problemas juntos.
Por lo general, se comunican entre sí para compartir información/objetivos, coordinar acciones y decisiones, y ajustar su comportamiento en función de las acciones de otros agentes.
Ejemplo: Los sistemas inteligentes de gestión del tráfico utilizan múltiples agentes de IA para optimizar el flujo del tráfico. Dado que hay un agente que controla los semáforos en cada intersección, puede coordinar acciones para decidir qué señal mostrar.
¿Qué es Browserless?
Browserless es un servicio basado en la nube que permite ejecutar un navegador sin cabeza sin las limitaciones de un dispositivo local. Está diseñado para permitir a los desarrolladores realizar tareas de web scraping, pruebas automatizadas y otra automatización basada en navegador a escala.
Como un potente raspador web de IA, Nstbrowser Browserless permite que estos agentes web interactúen con sistemas basados en web sin necesidad de una interfaz de navegador completa. Por ejemplo, puede usar Playwright o Puppeteer para la generación de pruebas o el análisis visual. El principal beneficio es que puede aumentar la velocidad de estos agentes y utilizar menos recursos.
Sin embargo, su capacidad para comprender el lenguaje natural es lo que lo diferencia de otros raspadores web de IA. Dado que puede generar respuestas similares a las humanas (tanto de texto como de voz), puede ayudarlo a descargar tareas tediosas. Al igual que los agentes humanos, pueden adaptarse a situaciones inesperadas, como agregar entradas erróneas o utilizar mecanismos de manejo de errores.
Como es omnicanal, puede manejar consultas a través de múltiples canales (teléfono, correo electrónico, chat, etc.) sin perder el contexto. Todo esto sucede en tiempo real, imitando en última instancia las interacciones humanas normales.
¿Por qué deberíamos integrar IA y Browserless?
Si bien las herramientas de raspado web de IA han demostrado un potencial considerable en la automatización de tareas, todavía hay varios desafíos y obstáculos técnicos que considerar al usar agentes de IA para las interacciones de página:
Contenido dinámico
Los sitios web actuales a menudo se basan en JavaScript para cargar datos de forma asincrónica, y los agentes tradicionales pueden tener dificultades para capturar o interactuar con elementos que solo aparecen después de que la página se haya renderizado completamente.
Browserless puede manejar estas páginas dinámicas ejecutando navegadores sin cabeza que renderizan completamente JavaScript, permitiendo que los agentes de IA interactúen con los elementos como lo haría un usuario humano.
Falta de API web
Muchos sitios web o servicios no proporcionan API públicas para acceder fácilmente a sus datos. Como resultado, el raspado o la automatización de interacciones a menudo requieren raspado web directo y el manejo de estructuras HTML complejas. Esto puede provocar un aumento de la complejidad y la necesidad de que los agentes de IA "entiendan" y naveguen por los sitios web de manera más inteligente.
Al combinar IA con Browserless, puede simular interacciones de usuario reales, incluso cuando no hay una API disponible. La IA puede identificar inteligentemente elementos clave en la página, lo que facilita que los agentes eludan la necesidad de API formales y extraigan o interactúen con los datos de manera eficiente. Browserless garantiza que estas interacciones ocurran sin activar sistemas de detección de bots, incluso en ausencia de una API.
Comportamiento impredecible
Los agentes de IA, al interactuar con sistemas de terceros (como sitios web, API u otras herramientas externas), pueden encontrar situaciones en las que el comportamiento del sistema es impredecible.
Es posible que experimente una interrupción del servicio o un cambio en su interfaz de usuario, o una API que pueda tener impactos posteriores. Esto se convierte en un problema cuando ejecuta cientos de tareas a escala, ya que puede ser difícil determinar exactamente qué salió mal.
Digamos que está utilizando un agente para reservar un vuelo, y el agente tiene que manejar una nueva ventana emergente en el sitio web de la aerolínea que solicita detalles sobre la información de la vacuna o un código de cupón. Si no agrega los pasos necesarios en su flujo de trabajo para manejar estas ventanas emergentes, es posible que la reserva no se realice o que termine con un error de reserva.
Al integrar IA con Browserless, puede crear mecanismos de manejo de errores y soluciones alternativas. La IA puede adaptarse inteligentemente a los cambios en el diseño de la página web, identificar nuevos elementos (como ventanas emergentes) y activar acciones específicas para manejarlos. Además, Browserless permite ejecutar instancias de navegador sin una GUI, lo que reduce la complejidad de identificar y responder a dichos cambios.
Flujos de trabajo de varios pasos
Los flujos de trabajo complejos a menudo implican varios pasos que abarcan varios sistemas, cada uno de los cuales requiere una cuidadosa coordinación y toma de decisiones.
En estos casos, mantener el contexto en varias interacciones puede ser un desafío, especialmente cuando participan varios usuarios o sistemas.
Por ejemplo, si su agente está ayudando a un usuario con una solicitud de hipoteca que necesita extraer datos financieros de múltiples sistemas, se necesita el flujo de contexto y decisión correcto para que esto suceda. Podría estar recopilando datos a través de la verificación de crédito, la suscripción y su propio sistema de aplicación.
La integración de Browserless permite a los agentes de IA ejecutar estos flujos de trabajo en un entorno donde las interacciones del navegador son estables y se pueden escalar fácilmente, sin el riesgo de errores debido a cambios en el sistema externo.
Optimización del uso de tokens y tiempo de respuesta
A medida que aumenta la escala del uso de IA, el uso de tokens (en el caso de los LLM) y el tiempo de respuesta pueden volverse problemáticos. A medida que aumenta la escala de las tareas, cada operación puede requerir más recursos, lo que aumenta el costo operativo y los retrasos en la respuesta.
A medida que aumenta el tráfico web, la ejecución de consultas complejas en sitios web grandes implicará analizar más datos, consumir más recursos y aumentar los tiempos de respuesta.
Por eso debe asegurarse de que su flujo de trabajo solo contenga los pasos necesarios. Aquí hay algunas otras formas de optimizar el uso de tokens:
- Almacenar en caché la información de uso común
- Usar un sistema de respuesta por capas
- Usar modelos más pequeños y específicos de la tarea cuando sea apropiado
- Usar indicaciones más cortas y precisas
- Solicitar formatos de salida más eficientes (viñetas, tablas)
¿Cómo lograr el web scraping de IA usando Browserless?
Paso 1: Preparación
Browserless adopta un enfoque centrado en el navegador, proporciona potentes capacidades de implementación sin cabeza y garantiza un mayor rendimiento y confiabilidad. Para obtener más información sobre cómo comenzar con el raspado web de IA a través de Browserless, puede obtener el documento para obtener más información.
Obtenga la CLAVE API y vaya a la página del menú Browserless del cliente Nstbrowser, o puede ir al cliente Nstbrowser para acceder
¿Tiene alguna idea maravillosa y dudas sobre el web scraping y Browserless?
¡Veamos lo que otros desarrolladores están compartiendo en Discord y Telegram!
Paso 2: Confirmar el objetivo de rastreo
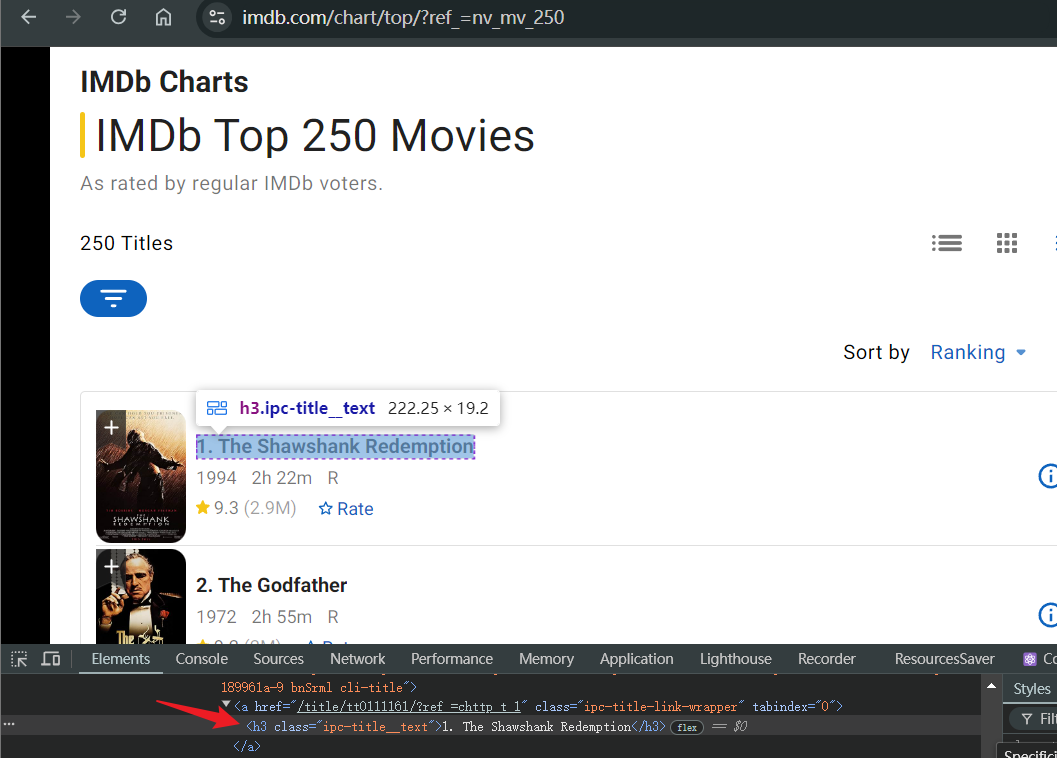
Antes de comenzar, debemos asegurarnos de lo que vamos a rastrear. En el siguiente ejemplo, intentamos rastrear los títulos de las películas en Las 250 mejores películas de IMDb. Después de abrir la página:
- Espere a que la página se cargue normalmente y ubique la página en el título de la película en las 250 mejores películas de IMDb
- Abra la consola de depuración e identifique el elemento html del título de la película
- Use su biblioteca favorita para obtener el título de la película
Paso 3: Comenzar el rastreo
¡Todo está listo, comienza el rastreo! Elegimos usar el poderoso Browserless en la nube proporcionado por Nstbrowser para rastrear el contenido anterior. A continuación, enumeraremos algunas de las bibliotecas comunes que se utilizan juntas.
Puppeteer
Si aún no ha elegido una biblioteca, le recomendamos encarecidamente Puppeteer porque es muy activo y tiene muchos mantenedores. También está desarrollado por los desarrolladores de Chrome, por lo que es una de las bibliotecas de mayor calidad.
- Instalar puppeteer-core
Bash
# pnpm
pnpm i puppeteer-core
# yarn
yarn add puppeteer-core
# npm
npm i --save puppeteer-core- Script de código
JavaScript
import puppeteer from "puppeteer-core";
const token = "your api key"; // 'your proxy'
const config = {
proxy: 'your proxy', // required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
// platform: 'windows', // support: windows, mac, linux
// kernel: 'chromium', // only support: chromium
// kernelMilestone: '128', // support: 128
// args: {
// "--proxy-bypass-list": "detect.nstbrowser.io"
// }, // browser args
// fingerprint: {
// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent supportted since v0.15.0
// },
};
const query = new URLSearchParams({
token: token, // required
config: JSON.stringify(config),
});
const browserWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;
// Conectar browserless
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
})
console.info('¡Conectado!');
// Crear una nueva página
const page = await browser.newPage()
// Visitar la página de las 250 mejores películas de IMDb
await page.goto('https://www.imdb.com/chart/top/?ref_=nv_mv_250')
// Esperar a que se cargue la lista de películas
await page.waitForSelector('.ipc-metadata-list')
// Obtener una lista de títulos de películas
const moviesList = await page.$$eval('.ipc-metadata-list h3.ipc-title__text', nodes => nodes.map(node => node.textContent));
console.log('[Las 250 mejores películas de IMDb]===>', moviesList);
// Cerrar el navegador
await browser.close();¡Felicidades! Hemos terminado nuestra tarea de raspado. Puede ver el resultado de 250 películas en la consola:
Playwright
- Instalar Playwright
Bash
pip install pytest-playwright- Script de código
Python
from playwright.sync_api import sync_playwright
from urllib.parse import urlencode
import json
token = "your api key" # 'your proxy'
config = {
"proxy": "your proxy", # required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
# platform: 'windows', // support: windows, mac, linux
# kernel: 'chromium', // only support: chromium
# kernelMilestone: '128', // support: 128
# args: {
# "--proxy-bypass-list": "detect.nstbrowser.io"
# }, // browser args
# fingerprint: {
# userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent supportted since v0.15.0
# },
}
query = urlencode({"token": token, "config": json.dumps(config)})
browser_ws_endpoint = f"ws://less.nstbrowser.io/connect?{query}"
def scrape_imdb_top_250():
with sync_playwright() as p:
# Conectar browserless
browser = p.chromium.connect_over_cdp(browser_ws_endpoint)
print("¡Conectado!")
# Crear una nueva página
page = browser.new_page()
# Visitar la página de las 250 mejores películas de IMDb
page.goto("https://www.imdb.com/chart/top/?ref_=nv_mv_250")
# Esperar a que se cargue la lista de películas
page.wait_for_selector(".ipc-metadata-list")
# Obtener una lista de títulos de películas
movies_list = page.eval_on_selector_all(
".ipc-metadata-list h3.ipc-title__text",
"nodes => nodes.map(node => node.textContent)",
)
print("[Las 250 mejores películas de IMDb]===>", movies_list)
# Cerrar el navegador
browser.close()
scrape_imdb_top_250()Por supuesto, el siguiente es el resultado del raspado:

Seleccione su idioma y biblioteca favoritos, ejecute el script correspondiente y podrá ver los resultados rastreados.
3 tendencias tecnológicas de actualidad
1. IA generativa:
- La IA generativa potenciará la tecnología de automatización, permitiendo que la IA genere estrategias de operación más complejas y personalizadas, mejorando así la inteligencia de las tareas automatizadas.
- La IA puede generar las soluciones de interacción más apropiadas en función del contenido web y el comportamiento del usuario, y adaptarse automáticamente a diferentes tipos de tecnologías anti-rastreadores y páginas dinámicas.
2. LLM (GPT, ClaudeAI, etc.)
- Los modelos de lenguaje grandes pueden permitir que los agentes de IA comprendan y operen elementos web más complejos al realizar tareas, incluida la extracción de información y el análisis de contenido web, a través de la tecnología de procesamiento del lenguaje natural.
- Al integrar LLM, los agentes de IA pueden realizar la comprensión del lenguaje, la extracción de información y la toma de decisiones analíticas al realizar tareas automatizadas, mejorando la flexibilidad e inteligencia de las tareas.
3. Simulación de comportamiento
- La tecnología de simulación de comportamiento permite a la IA simular con precisión el comportamiento interactivo de los usuarios reales, mejorar el ocultamiento y evitar los sistemas de detección.
- La IA puede simular los patrones de comportamiento únicos de cada usuario, incluidos los movimientos del ratón, los hábitos de clic y la configuración del navegador, para evitar ser identificada como operaciones de máquina.
Agente de IA y Browserless: simplifica tu automatización web
Ha comprendido completamente todo el contenido del agente de IA. La combinación del agente de IA y Browserless aportará inteligencia integral a las operaciones de páginas web.
Desde evitar anti-rastreadores hasta simular comportamientos de usuario complejos, hasta la futura plataforma de operación de páginas web totalmente automatizada, la IA y Browserless se convertirán en el núcleo de la interacción inteligente de páginas web.
Más





