
Browserless
使用 Browserless 在 Puppeteer 中运行并行测试的方法
并行运行测试总是需要访问多个平台和浏览器,这增加了我们的测试成本。看看 Browserless 如何在这个博客中简化测试。
Oct 15, 2024Carlos Rivera
什么是并行测试?
什么是并行化?
并行测试也称为并行执行。在并行测试中,我们在多个浏览器上并行测试不同的模块或应用程序,而不是一个接一个地测试它们。
并行化与顺序测试不同,顺序测试是指我们一个接一个地测试不同的模块或功能。即使在多个浏览器上测试应用程序时,测试也是在每个浏览器上顺序执行的。这种测试方法非常耗时。
并行执行有助于减少执行时间和工作量,从而缩短交付时间。它在跨浏览器测试、兼容性测试、本地化和国际化测试中特别有用。在我们需要检查两个版本的软件的稳定性和兼容性的情况下,我们可以同时运行这两个版本,并以更快的速度发现问题。
并行化与序列化 - 哪个更好?
1. 并行化
并行化意味着同时运行多个任务,这通常可以显著提高速度,尤其是在测试或执行任务时。
优点:
- 更快: 并行化允许多个任务同时进行,减少了总的运行时间。可以并发执行的任务可以显著提高效率。
- 充分利用资源: 并行化可以最大程度地利用多核 CPU 和多线程环境的优势,尤其适用于多任务处理以及需要处理大量 I/O 操作的情况(例如网络请求、页面加载等)。
- 适用于大规模测试: 对于大型测试套件,可以通过并行执行快速完成多个测试场景。
缺点:
- 高资源消耗: 并行化会占用更多系统资源(例如 CPU 和内存)。当启动太多浏览器实例或页面时,可能会导致系统资源耗尽或性能下降。
- 复杂性增加: 管理并行任务的结果、同步和错误处理变得更加复杂。测试中的共享资源(例如数据库和文件系统)需要特别注意,以防止出现竞争条件或冲突。
- 不适用于依赖于顺序的任务: 如果任务之间存在依赖关系(例如,任务 A 必须在任务 B 完成之前完成),则并行化可能会导致问题。
适用场景:
- 存在大量可以同时执行的独立任务或测试的场景。
- 存在强大的硬件资源来支持并发操作。
- 需要快速完成大规模任务。
2. 序列化
序列化是指任务按顺序一个接一个地执行,直到所有任务都完成。
优点:
- 低资源要求: 由于一次只运行一个任务,资源使用相对较低,系统稳定性更高,避免了资源竞争和耗尽。
- 易于管理: 任务的顺序清晰,调试和错误处理相对简单。尤其是在任务之间存在依赖关系时,序列化可以确保任务按预期顺序执行。
- 适用于依赖性任务: 当任务具有顺序或依赖关系时,序列化执行可以避免出现竞争条件。
缺点:
- 速度较慢: 由于一次只执行一个任务,无法利用系统的多核处理能力,总的执行时间将比并行化更长。
- 资源浪费: 即使有更多可用的资源,序列化仍然只使用一部分资源,导致硬件性能不足。
适用场景:
- 任务之间存在依赖关系,并且必须按顺序完成。
- 系统资源有限,或者并行化会导致性能下降。
- 任务复杂度高,错误率高,需要逐步排查问题。
简而言之
- 如果您追求速度,并且任务之间没有依赖关系,则并行化更好,可以提高效率。
- 如果任务之间存在依赖关系,或者系统资源有限,则序列化更安全,尽管速度可能较慢。
使用 Browserless 在 Puppeteer 中运行并行执行
第 1 步:获取 API 密钥
在开始之前,有必要拥有 Browserless 服务。Browserless 可以解决复杂的网页抓取和大型自动化任务,并且现在已经实现了完全托管的云部署。
Browserless 采用以浏览器为中心的 approach,提供了强大的无头部署能力,并提供了更高的性能和可靠性。有关 Browserless 的更多信息,您可以点击这里 了解更多。
- 获取 API 密钥并进入 Nstbrowser 客户端的 Browserless 菜单页面,或者您可以点击这里 访问:
第 2 步:安装 puppeteer-cluster-connect
为什么要使用 Puppeteer?
Puppeteer 有很多维护者并且非常活跃。它也是由 Chrome 开发人员构建的,因此它是质量最高的库之一。因此,接下来我们将使用 Puppeteer 连接 Browserless 进行并行测试。
Puppeteer-cluster 可以创建多个 puppeteer 工作进程。这个库通过 Puppeteer 生成一个 Chromium 实例池,并帮助跟踪操作和错误。它可以帮助我们很好地进行并行测试,但这个库目前还不支持 puppeteer.connect,因此无法连接到外部浏览器端口。
因此,在下面的示例中,我们将使用puppeteer-cluster-connect 代替:
Bash
npm install --save puppeteer
npm install --save puppeteer-cluster-connect第 3 步:使用 puppeteer-cluster-connect 连接到 Browserless
我们需要准备以下函数。只需填写您的 API 密钥和代理即可开始连接到 Browserless:
JavaScript
async function getBrowserWSEndpoint() {
const token = "您的 API 密钥"; // '您的代理'
const config = {
proxy: '您的代理', // 必填; 输入格式: schema://user:password@host:port 例如: http://user:password@localhost:8080
// platform: 'windows', // 支持: windows, mac, linux
// kernel: 'chromium', // 仅支持: chromium
// kernelMilestone: '128', // 支持: 128
// args: {
// "--proxy-bypass-list": "detect.nstbrowser.io"
// }, // 浏览器参数
// fingerprint: {
// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent 支持从 v0.15.0 开始
// },
};
const query = new URLSearchParams({
token: token, // 必填
config: JSON.stringify(config),
});
return `https://less.nstbrowser.io/connect?${query.toString()}`;
}接下来,我们需要使用 puppeteer-cluster-connect 的连接方法连接到 Browserless;
Concurrency是并发实现的类型。这里我们设置Cluster.CONCURRENCY_CONTEXT,这意味着每个 URL 将创建一个不共享数据的隐形页面(BrowserContext);MaxConcurrency是最大并发数。RestartFunction是端口崩溃时重启端口的方法。
此时,我们的 Browserless 集群已准备就绪!
JavaScript
import puppeteer from "puppeteer-core";
import { Cluster } from "puppeteer-cluster-connect"
const cluster = await Cluster.connect({
concurrency: Cluster.CONCURRENCY_CONTEXT,
maxConcurrency: 3,
// 提供 puppeteer-core 库
puppeteer,
puppeteerOptions: {
browserWSEndpoint: await getBrowserWSEndpoint(),
defaultViewport: null
},
// 在这里放入重启函数回调
restartFunction: getBrowserWSEndpoint,
});
console.log('cluster is Connected!');第 4 步:开始并行测试
接下来,我们将进行一个简单的并行测试。我们希望能够快速并行地批量访问多个站点,记录这些站点的标题,并在页面加载后进行截图,以测试这些站点是否可以正常访问。
- 使用上一步骤中获取的集群的
task方法创建一个任务。此任务包含每个浏览器实例对应的操作函数:
JavaScript
await cluster.task(async ({ page, data }) => {
const { url, name } = data
// 访问目标站点
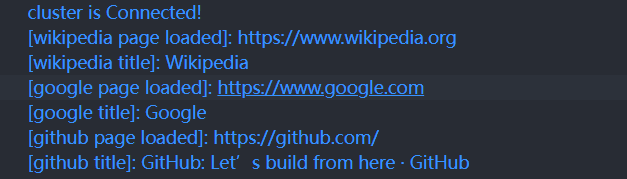
await page.goto(url);
console.log(`[${name} page loaded]:`, url);
// 获取文档标题
const documentTitle = await page.evaluate(() => document.title)
console.log(`[${name} title]:`, documentTitle);
// 拍摄截图
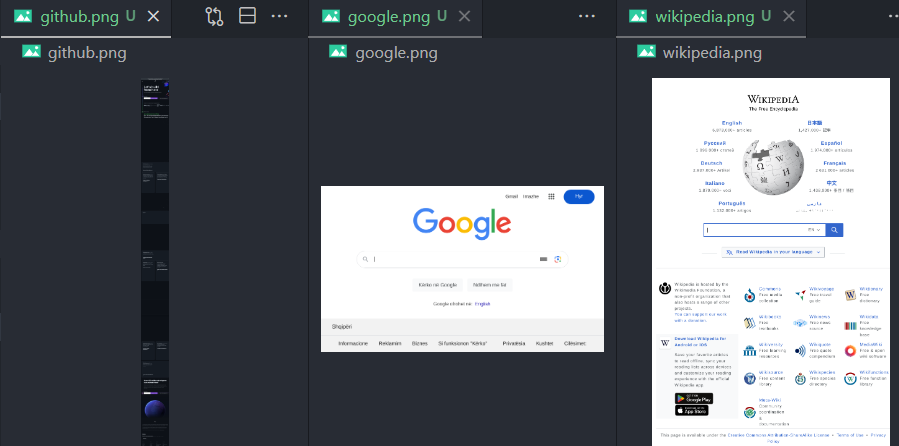
await page.screenshot({ fullPage: true, path: `${name}.png` });
});queue方法应该用于将需要并行测试的数据添加到集群中- 然后,请使用
idle和close方法关闭集群和所有打开的浏览器实例:
JavaScript
cluster.queue({ url: "https://www.google.com", name: 'google' });
cluster.queue({ url: "https://www.wikipedia.org", name: 'wikipedia' });
cluster.queue({ url: "https://github.com/", name: 'github' });
await cluster.idle();
await cluster.close();- 现在,我们可以运行上面的脚本来查看上面并行测试的结果:
- 您也可以在执行脚本的路径中看到相应的截图:
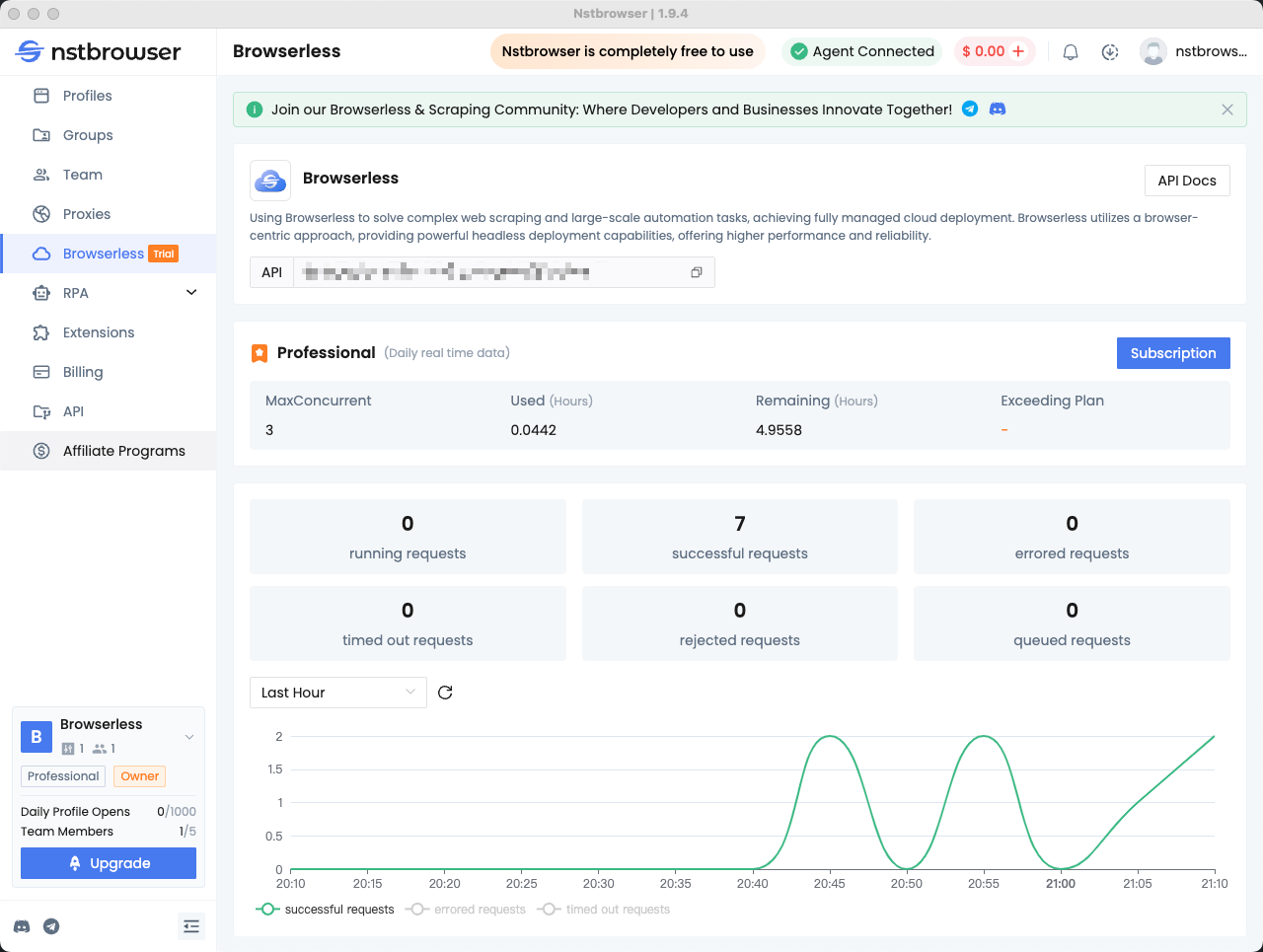
第 5 步:查看 Browserless 仪表板
您可以在 Nstbrowser 客户端的 Browserless 菜单中查看最近请求的统计信息和剩余会话时间。
总结
您是否总是需要将工作并行化?并行运行测试总是需要访问多个平台和浏览器,这会增加我们的测试成本。
此外,我们可能会遇到无法访问所有浏览器和版本的 situation。Browserless 可以轻松帮助您解决上述问题。只需 4 个简单的步骤,即可轻松完成并行测试。
更多





