
Web Scraping
如何使用Go进行网页抓取?
Go也称为Golang,它结合了静态类型和动态类型语言的优点,提供高效的编译速度和运行性能。通过分步介绍,你将了解如何用Go进行网页抓取。
May 20, 2024
Go 也称为 Golang,指的是由 Google 开发的一种开源编程语言,旨在提高编程的效率和速度,特别是在处理并发任务时。Go 结合了静态类型和动态类型语言的优点,提供高效的编译速度和运行性能。如何使用 Go 编程语言中的 Colly 库来构建网页抓取器?Nstbrowser 将逐步为你介绍代码以理解每个部分。
不要浪费时间了!是时候开始了解具体步骤。
为什么要用Go进行网页抓取?
- 简洁明了。Go的语法设计简洁,易于学习和使用,减少了代码的复杂性。
- 内置并发支持。通过goroutines和channels,Go提供了强大的并发编程能力,方便开发高性能并发应用。
- 垃圾回收。Go有自动垃圾回收机制,帮助管理内存,提高开发效率。
准备工作
安装 Go
首先,让我们建立我们的 Go 项目。我将花几秒钟的时间与您讨论如何安装 Go,如果您已经安装了它,请再一次核对。
根据您的操作系统,您可以在 Go 文档页面上找到安装指南。如果您是 macOS 用户并且使用 brew ,则可以在终端中运行它:
bash
brew install go组建项目
为你的项目创建一个新的目录,移动到这个目录,然后运行下面的命令,在这里你可以用任何你想命名的模块来替换单词 webscraper。
bash
go mod init webscraper- Note:
go mod init命令在执行它的目录中创建一个新的 Go 模块。它创建了一个新的go.mod文件,用于定义依赖项和管理项目中使用的第三方包的版本(如果使用 node,则类似于 package.json)。
现在可以设置 Web 抓取 Go 脚本了。创建一个 scraper.go 文件并初始化它,如下所示:
Go
package main
import (
"fmt"
)
func main() {
// scraping logic...
fmt.Println("Hello, World!")
}第一行包含全局包的名称。然后,有一些导入,然后是 main() 函数。这代表了任何 Go 程序的入口点,并将包含 Golang 网络抓取逻辑。这样你就可以启动这个程序了:
bash
go run scraper.go这将打印:
PlainText
Hello, World!现在你已经建立了一个基本的 Go 项目,让我们更深入地研究如何使用 Golang 构建一个数据抓取器。
使用 Go 构建一个 Web Scraper
接下来,我们以ScrapeMe为例深入讲解如何用 Go 进行页面抓取。
Step 1. 安装 Colly
为了更容易地构建一个 Web Scraper,你应该使用前面介绍的一个包。但首先,你需要弄清楚哪个 Golang 网页抓取库最适合你的目标。为此你需要:
- 访问目标网站。
- 右键单击背景。
- 选择“检查”选项。这将打开浏览器的 DevTools。
- 在“Network”选项卡中,查看“Fetch/XHR”部分。
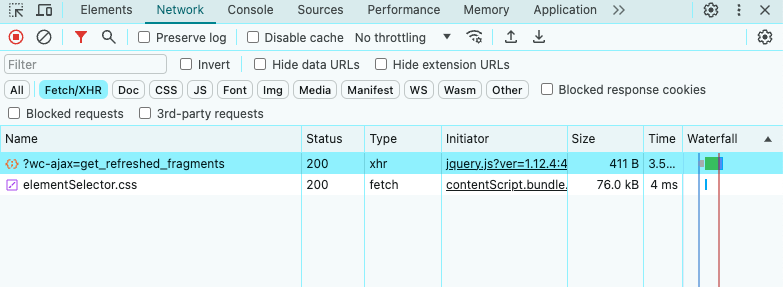
正如你在上面看到的,目标网页只执行几个 AJAX 请求。如果您研究每个 XHR 请求,您会注意到它们没有返回任何有意义的数据。换句话说,服务器返回的 HTML 文档已经包含了所有的数据。这就是静态内容网站通常发生的情况。
这表明目标站点不依赖于 JavaScript 来动态检索数据或进行呈现。因此,您不需要具有无头浏览器功能的库来从目标网页检索数据。您仍然可以使用 Selenium,但这只会引入性能开销。出于这个原因,你应该更喜欢一个简单的 HTML 解析器,如 Colly。
现在让我们安装 colly 及其依赖项:
bash
go get github.com/gocolly/colly此命令还将使用所有必需的依赖项更新 go.mod 文件,并创建 go.sum 文件。
Colly 是一个 Go 软件包,允许你编写 Web Scraper 和 crawler。它构建在 Go 的 net/HTTP 包之上,用于网络通信,以及
goquery,它提供了一个“类似jQuery”的语法来定位 HTML 元素。
在开始使用它之前,您需要深入研究 Colly 的一些关键概念:
Colly 的主要实体是 Collector。此对象允许您执行 HTTP 请求并通过以下回调执行 Web 抓取:
OnRequest(): 在使用 Visit() 进行任何HTTP请求之前调用。OnError(): 如果 HTTP 请求中发生错误,则调用。OnResponse(): 在从服务器获得响应后调用。OnHTML(): 如果服务器返回有效的 HTML 文档,则在 OnResponse() 之后调用。OnScraped(): 在所有 OnHTML() 调用结束后调用。
这些函数中的每一个都接受一个回调作为参数。当引发与函数关联的事件时,Colly 执行输入回调。因此,要在 Colly 中构建数据抓取器,您需要遵循基于回调的函数方法。
可以使用 NewCollector()函数初始化 Collector 对象:
Go
c := colly.NewCollector()导入 Colly 并通过更新 scraper 创建 Collector。如下所示:
Go
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
// scraping logic...
}Step 2. 连接到目标网站
使用 Colly 连接到目标页面:
Go
c.Visit("https://scrapeme.live/shop/")在后台,Visit() 函数执行 HTTP GET 请求并从服务器检索目标 HTML 文档。具体来说,它触发 onRequest 事件并启动 Colly 功能生命周期。请记住,Visit() 必须在注册其他 Colly 回调之后调用。
请注意,Visit() 发出的HTTP请求可能会失败。发生这种情况时,Colly 会引发 OnError 事件。失败的原因可能是暂时不可用的服务器或无效的 URL。与此同时,当目标网站采取反机器人措施时,网络抓取器通常也会失败。例如,这些技术通常会过滤掉不具有有效 User-Agent HTTP 标头的请求。
为什么会这样呢?
通常情况下,Colly 设置的占位符 User-Agent 与流行浏览器使用的代理不匹配。这使得 Colly 请求很容易被反抓取技术识别。为了避免被阻止,请在 Colly 中指定一个有效的 User-Agent 头,如下所示:
Go
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"寻找更有效的解决方案?
Nstbrowser 拥有完整的网页抓取 API,为您处理所有反机器人障碍。
Try It for Totally Free!
您对网页抓取和 Browseless 有什么好的想法或疑惑吗?
快来看看其他开发人员在 Discord 和 Telegram 上分享了什么!
现在,任何 Visit() 调用都将执行带有该HTTP头的请求。
你的 scraper.go 文件现在看起来应该像下面这样:
Go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// creating a new Colly instance
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
// visiting the target page
c.Visit("https://scrapeme.live/shop/")
// scraping logic...
}Step 3. 检查 HTML 页面并抓取
现在我们需要对目标 Web 页面的 DOM 进行浏览和分析,以此对我们需要抓取的数据进行定位。然后采取有效的数据检索策略。
- 右键单击其中一个 HTML 卡并选择 "Inspect":
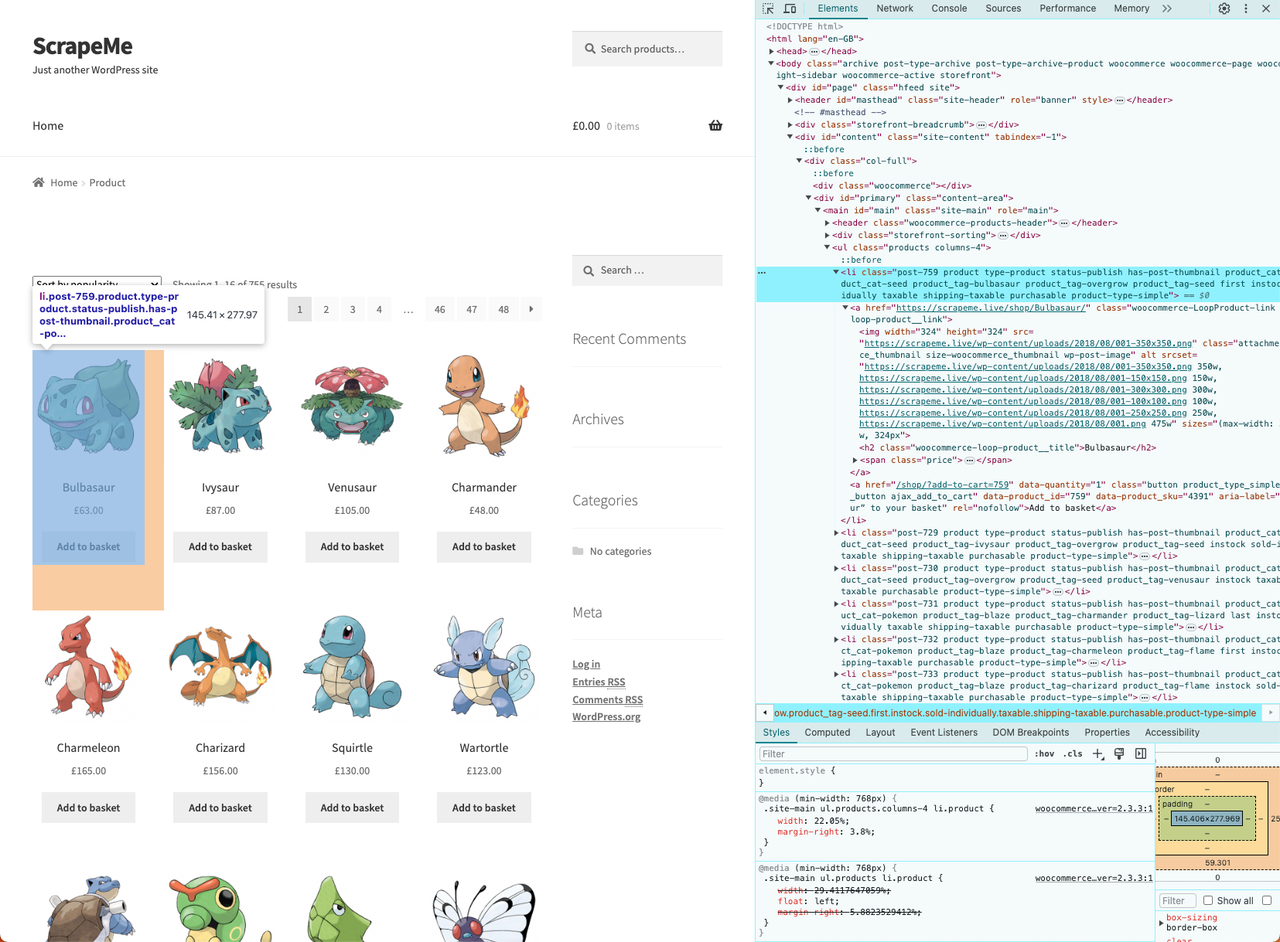
我们已经看到了其 HTML 结构,在开始抓取之前,您需要一个数据结构来存储抓取的数据。
- 定义
PokemonProductStruct 如下:
Go
// defining a data structure to store the scraped data
type PokemonProduct struct {
url, image, name, price string
}- 然后,初始化
PokemonProduct的一个切片,它将包含抓取的数据:
Go
// initializing the slice of structs that will contain the scraped data
var pokemonProducts []PokemonProduct- 现在,实现爬取逻辑:
Go
// iterating over the list of HTML product elements
c.OnHTML("li.product", func(e *colly.HTMLElement) {
// initializing a new PokemonProduct instance
pokemonProduct := PokemonProduct{}
// scraping the data of interest
pokemonProduct.url = e.ChildAttr("a", "href")
pokemonProduct.image = e.ChildAttr("img", "src")
pokemonProduct.name = e.ChildText("h2")
pokemonProduct.price = e.ChildText(".price")
// adding the product instance with scraped data to the list of products
pokemonProducts = append(pokemonProducts, pokemonProduct)
})HTMLElement 接口公开了 ChildAttr() 和 ChildText() 方法。它们分别允许您从CSS选择器标识的子对象中提取对应属性值的文本。通过设置两个简单的函数,您实现了整个数据提取逻辑。
- 最后,您可以使用
append()将一个新元素附加到所抓取元素的切片中。
Step 4. 将抓取的数据转换为 CSV
使用 Go 将抓取的数据导出到 CSV 文件,逻辑如下:
Go
// opening the CSV file
file, err := os.Create("products.csv")
if err != nil {
log.Fatalln("Failed to create output CSV file", err)
}
defer file.Close()
// initializing a file writer
writer := csv.NewWriter(file)
// defining the CSV headers
headers := []string{
"url",
"image",
"name",
"price",
}
// writing the column headers
writer.Write(headers)
// adding each Pokemon product to the CSV output file
for _, pokemonProduct := range pokemonProducts {
// converting a PokemonProduct to an array of strings
record := []string{
pokemonProduct.url,
pokemonProduct.image,
pokemonProduct.name,
pokemonProduct.price,
}
// writing a new CSV record
writer.Write(record)
}
defer writer.Flush()- Note: 此代码片段创建了一个
products.csv文件,并使用标题列对其进行重命名。然后,它迭代抓取的PokemonProduct的切片,将它们中的每一个转换为新的 CSV 记录,并将其附加到 CSV 文件。
要使此代码段工作,请确保您具有以下导入:
Go
import (
"encoding/csv"
"log"
"os"
// ...
)整体代码展示
下面是 scraper.go 的完整代码:
Go
package main
import (
"encoding/csv"
"log"
"os"
"github.com/gocolly/colly"
)
// initializing a data structure to keep the scraped data
type PokemonProduct struct {
url, image, name, price string
}
func main() {
// initializing the slice of structs to store the data to scrape
var pokemonProducts []PokemonProduct
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
// creating a new Colly instance
c := colly.NewCollector()
// visiting the target page
c.Visit("https://scrapeme.live/shop/")
// scraping logic
c.OnHTML("li.product", func(e *colly.HTMLElement) {
pokemonProduct := PokemonProduct{}
pokemonProduct.url = e.ChildAttr("a", "href")
pokemonProduct.image = e.ChildAttr("img", "src")
pokemonProduct.name = e.ChildText("h2")
pokemonProduct.price = e.ChildText(".price")
pokemonProducts = append(pokemonProducts, pokemonProduct)
})
// opening the CSV file
file, err := os.Create("products.csv")
if err != nil {
log.Fatalln("Failed to create output CSV file", err)
}
defer file.Close()
// initializing a file writer
writer := csv.NewWriter(file)
// writing the CSV headers
headers := []string{
"url",
"image",
"name",
"price",
}
writer.Write(headers)
// writing each Pokemon product as a CSV row
for _, pokemonProduct := range pokemonProducts {
// converting a PokemonProduct to an array of strings
record := []string{
pokemonProduct.url,
pokemonProduct.image,
pokemonProduct.name,
pokemonProduct.price,
}
// adding a CSV record to the output file
writer.Write(record)
}
defer writer.Flush()
}使用以下命令运行 scraper.go:
bash
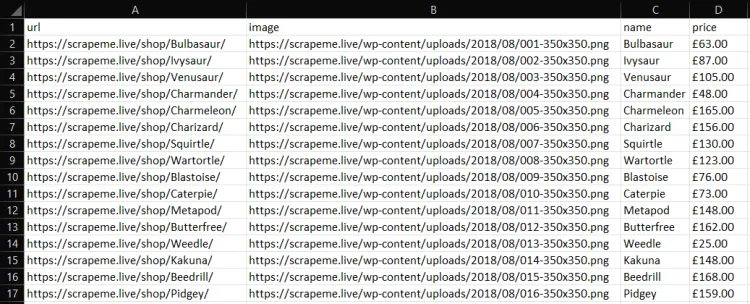
go run scraper.go然后,您将在项目的根目录中找到 products.csv 文件。打开它,它应该包含:
其他爬取库
- Nstbrowser: 拥有完整的网页抓取 API,为您处理所有反机器人障碍。它具有无头浏览器功能,captcha 绕过和更多功能。
- Chromedp: A faster, simpler way to drive browsers supporting the Chrome DevTools Protocol.
- GoQuery: 一个提供语法和一组类似于 jQuery 的特性的 Go 库。你可以用它来执行网页抓取,就像你在 JQuery 中做的那样。
- Selenium: 可能是最著名的无头浏览器,非常适合抓取动态内容。它不提供官方支持,但有一个在 Go 中使用它的端口。
- Ferret: 一个便携的,可扩展的和快速的网页抓取系统,旨在简化数据提取从网络。Ferret 允许用户专注于数据,并且基于一种独特的声明性语言。
总结
在本教程中,您不仅
- 了解了什么是 Web Scraper
- 还学习了如何利用 Colly 和 Go 的标准库来构建自己的 Web 抓取应用程序。
通过这个教程,您可以看到,使用 Go 进行 Web 抓取只需几行简洁而高效的代码即可完成任务。
然而,我们也应该认识到,从互联网提取数据并不是一帆风顺的。在这个过程中,您可能会遇到各种各样的挑战。许多网站采取了反抓取和反机器人的解决方案,这些方案能够检测并阻止您的 Go 抓取脚本。
最佳实践是使用网络抓取 API,例如 Nstbrowser,该免费的解决方案使您能够通过单个 API 调用绕过所有反机器人系统,以此来解决你执行抓取任务时被阻止的烦恼。
更多





