
Browserless
Pyppeteer: Cách sử dụng Puppeteer trong Python với Browserless?
Pyppeteer là gì? Làm cách nào chúng ta có thể tích hợp Pyppeteer vào Browserless? Trong blog này, bạn có thể tìm thấy các bước chi tiết để tận dụng tối đa Pyppeteer.
Oct 09, 2024Tạ Quí Lĩnh
Pyppeteer trong Python là gì?
Pyppeteer là một cổng Python của thư viện Node.js phổ biến Puppeteer, được sử dụng để điều khiển trình duyệt Chrome hoặc Chromium không đầu theo cách lập trình.
Về cơ bản, Pyppeteer cho phép các nhà phát triển Python tự động hóa các tác vụ trong trình duyệt web, chẳng hạn như thu thập dữ liệu trang web, kiểm tra ứng dụng web hoặc tương tác với các trang web giống như một người dùng thực sự đang làm, nhưng không có giao diện đồ họa.
Browserless là gì?
Browserless là một giải pháp trình duyệt dựa trên đám mây cho phép tự động hóa trình duyệt hiệu quả, thu thập dữ liệu trang web và kiểm tra.
Nó sử dụng thư viện dấu vân tay của Nstbrowser để cho phép chuyển đổi dấu vân tay ngẫu nhiên, dẫn đến việc thu thập dữ liệu và tự động hóa liền mạch. Cơ sở hạ tầng đám mây mạnh mẽ của Browserless giúp dễ dàng quản lý các hoạt động tự động bằng cách cho phép truy cập đồng thời vào nhiều phiên bản trình duyệt.
Bạn có bất kỳ ý tưởng tuyệt vời nào và nghi ngờ về thu thập dữ liệu trang web và Browserless?
Hãy xem những gì các nhà phát triển khác đang chia sẻ trên Discord và Telegram!
Pyppeteer có thể được sử dụng để làm gì?
Ảnh chụp màn hình bằng Pyppeteer
Khi sử dụng Browserless, bạn không thể nhìn thấy bất kỳ màn hình nào, vì vậy khi chúng ta cần biết màn hình cụ thể của trình duyệt trong một số liên kết, bạn nên sử dụng API ảnh chụp màn hình để lấy ảnh chụp màn hình.
Thực thi tập lệnh sau sẽ tạo ra một ảnh chụp màn hình có tên youtube_screenshot.png trong đường dẫn tập lệnh hiện tại:
Python
import asyncio
from pyppeteer import connect
async def main():
# Kết nối với trình duyệt
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Kết nối thành công!")
# Tạo một trang mới
page = await browser.newPage()
# Truy cập youtube
await page.goto("https://www.youtube.com/")
# chụp màn hình
await page.screenshot({"path": "youtube_screenshot.png"})
await page.close()
asyncio.run(main())Tương tác với các trang động
Trên các trang web hiện đại, JavaScript được dựa vào để cập nhật nội dung một cách động. Ví dụ, các nền tảng truyền thông xã hội thường sử dụng cuộn vô hạn trên các bài đăng của họ và việc tải dữ liệu trang cũng yêu cầu chờ phản hồi từ phía back-end, cũng như nhiều hoạt động của biểu mẫu và các sự kiện trình duyệt khác nhau.
Có, Pyppeteer cũng có thể làm điều tương tự: chờ tải, nhấp vào nút, nhập biểu mẫu và các hoạt động trình duyệt khác.
1. Chờ trang tải
Các API được sử dụng phổ biến để chờ tải trang là waitForSelector và waitFor.
waitForSelectorchủ yếu được sử dụng để đảm bảo rằng một phần tử nhất định trong trang được tải bình thườngwaitForchỉ đơn giản là chờ trong một khoảng thời gian nhất định.
Python
import asyncio
from pyppeteer import connect
async def main():
# Kết nối với trình duyệt
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Kết nối thành công!")
# Truy cập nasa
page = await browser.newPage()
await page.goto("https://www.disney.com/")
# Chờ tin tức tải
await page.waitForSelector('.content-body')
# chờ thêm 2 giây
await page.waitFor(2000)
# chụp màn hình
await page.screenshot({"path": "disney.png"})
await page.close()
asyncio.run(main())2. Cuộn trang
Trên page.evaluate, bạn có thể đặt vị trí của thanh cuộn bằng cách gọi API cửa sổ, điều này rất thuận tiện.
Python
import asyncio
from pyppeteer import connect
async def main():
# Kết nối với trình duyệt
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Kết nối thành công!")
# Truy cập HBO Max
page = await browser.newPage()
await page.goto('https://www.max.com/');
# Cuộn xuống cuối
await page.evaluate("window.scrollTo(0, document.documentElement.scrollHeight)");
# chụp màn hình
await page.screenshot({"path": "HBOMax.png"})
await page.close()
asyncio.run(main())3. Nhấp vào nút
Trong Python Pyppeteer, chúng ta có thể sử dụng page.click để nhấp vào nút hoặc liên kết siêu văn bản. Việc đặt độ trễ đầu vào làm cho nó giống với hoạt động của người dùng thực hơn.
Dưới đây là một ví dụ đơn giản.
Python
import asyncio
from pyppeteer import connect
async def main():
# Kết nối với trình duyệt
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Kết nối thành công!")
page = await browser.newPage()
await page.goto("https://example.com/")
# nhấp vào liên kết
await page.click("p > a", {"delay": 200})
# chụp màn hình
await page.screenshot({"path": "example.png"})
await page.close()
asyncio.run(main())4. Nhập biểu mẫu
Làm cách nào để nhập dữ liệu bằng Python Pyppeteer? Hãy sử dụng page.type để nhập nội dung vào hộp nhập đã chỉ định.
Python
import asyncio
from pyppeteer import connect
async def main():
# Kết nối với trình duyệt
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Kết nối thành công!")
# Tạo một trang mới
page = await browser.newPage()
# Truy cập nhà phát triển chrome
await page.goto("https://developer.chrome.com/")
await page.setViewport({"width": 1920, "height": 1080})
# Nhập nội dung vào hộp tìm kiếm
await page.type(".devsite-search-field", "headless", {"delay": 200})
# chụp màn hình
await page.screenshot({"path": "developer.png"})
await page.close()
asyncio.run(main())Đăng nhập bằng Pyppeteer
Sau những ví dụ trên, chúng ta có thể dễ dàng nghĩ đến các tương tác liên quan đến đăng nhập, chẳng hạn như hoạt động nhập loại và hoạt động nhấp vào nút.
Vì vậy, trong ví dụ sau, hãy thay đổi phương thức viết. Chúng ta sẽ cố gắng đăng nhập vào Nstbrowser Client. Sau khi đăng nhập, tôi sẽ chụp màn hình để xác minh xem nó có thành công hay không.
Python
import asyncio
from pyppeteer import connect
async def main():
# Kết nối với trình duyệt
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Kết nối thành công!")
# Truy cập Nstbrowser Client
page = await browser.newPage()
await page.goto("https://app.nstbrowser.io/account/login")
await page.waitForSelector("input")
inputs = await page.querySelectorAll("input")
# Nhập địa chỉ email của bạn vào hộp nhập đầu tiên
await inputs[0].type("[email protected]", delay=100)
# Nhập mật khẩu của bạn vào hộp nhập thứ hai
await inputs[1].type("9KLYUWn3GmrzHPRGQl0EZ1QP3OWPFwcB", delay=100)
buttons = await page.querySelectorAll("button")
# Nhấp vào nút đăng nhập
await buttons[1].click()
# Chờ phản hồi yêu cầu đăng nhập
login_url = "https://api.nstbrowser.io/api/v1/passport/login"
await page.waitForResponse(lambda res: res.url == login_url)
await page.waitFor(2000)
# chụp màn hình
await page.screenshot({"fullPage": True, "path": "./nstbrowser.png"})
await page.close()
asyncio.run(main())- Kết quả chạy:
Chúng ta có thể thấy rằng dự án của chúng ta đã được chuyển hướng đến trang chủ, điều này cho thấy chúng ta đã đăng nhập vào Nstbrowser thành công!
Cách sử dụng Pyppeteer trong Browserless?
Liệu Pyppeteer có thể hoạt động với Browserless?
Chắc chắn rồi, bạn có thể tìm thấy các bước cụ thể để tích hợp Pyppeteer vào Browserless!
Bước 1: Nhận API KEY
Trước khi chúng ta bắt đầu, chúng ta cần có một dịch vụ Browserless. Sử dụng Browserless có thể giải quyết các tác vụ thu thập dữ liệu trang web phức tạp và tự động hóa quy mô lớn và hiện nó đã đạt được việc triển khai đám mây được quản lý đầy đủ.
Browserless áp dụng phương pháp tập trung vào trình duyệt, cung cấp khả năng triển khai không đầu mạnh mẽ và mang lại hiệu suất và độ tin cậy cao hơn. Để biết thêm thông tin về Browserless, bạn có thể nhấp vào đây để tìm hiểu thêm.
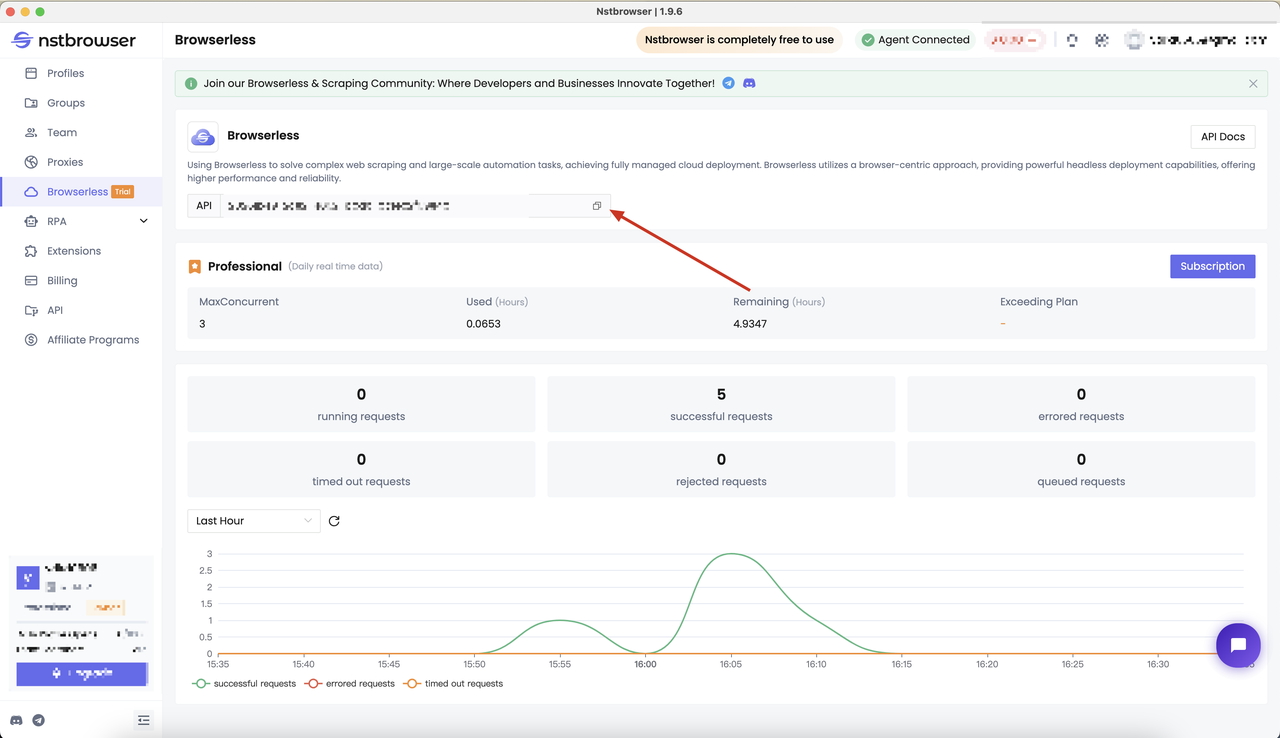
Nhận API KEY và đi đến trang menu Browserless của Nstbrowser client, hoặc bạn có thể nhấp vào đây để truy cập
Bước 2: Cài đặt Pyppeteer
Pyppeteer là phiên bản Python của Puppeteer, cung cấp chức năng tương tự và cho phép các nhà phát triển điều khiển trình duyệt không đầu bằng cách sử dụng các tập lệnh Python. Nó cho phép các nhà phát triển tự động hóa các tương tác với trang web thông qua mã Python và được sử dụng rất phổ biến trong các trường hợp như trình thu thập dữ liệu, kiểm tra và thu thập dữ liệu.
Plain Text
pip install pyppeteerBước 3: Kết nối Pyppeteer với Browserless
Chúng ta cần chuẩn bị mã sau. Chỉ cần điền API key và proxy của bạn để kết nối với Browserless.
Python
from urllib.parse import urlencode
import json
token = "your api key" # 'required'
config = {
"proxy": "your proxy", # required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
# "platform": "windows", # support: windows, mac, linux
# "kernel": 'chromium', # only support: chromium
# "kernelMilestone": '128', # support: 128
# "args": {
# "--proxy-bypass-list": "detect.nstbrowser.io"
# }, # browser args
# "fingerprint": {
# userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', # userAgent supportted since v0.15.0
# },
}
query = urlencode({"token": token, "config": json.dumps(config)})
browser_ws_endpoint = f"ws://less.nstbrowser.io/connect?{query}"Kết nối và hãy bắt đầu thu thập dữ liệu!
Python
import asyncio
from pyppeteer import connect
async def main():
# Kết nối với trình duyệt
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Kết nối thành công!")
asyncio.run(main())Bước 4: Sử dụng Pyppeteer trong Browserless
Trong blog này, chúng ta sẽ đi vào một trường hợp đơn giản để giúp bạn nhanh chóng bắt đầu với Browserless - thu thập dữ liệu Books to Scrape.
Trong ví dụ sau, chúng ta cố gắng thu thập tất cả tiêu đề sách trên trang hiện tại:
- Mở trang
- Chờ trang tải bình thường
- Mở bảng điều khiển gỡ lỗi
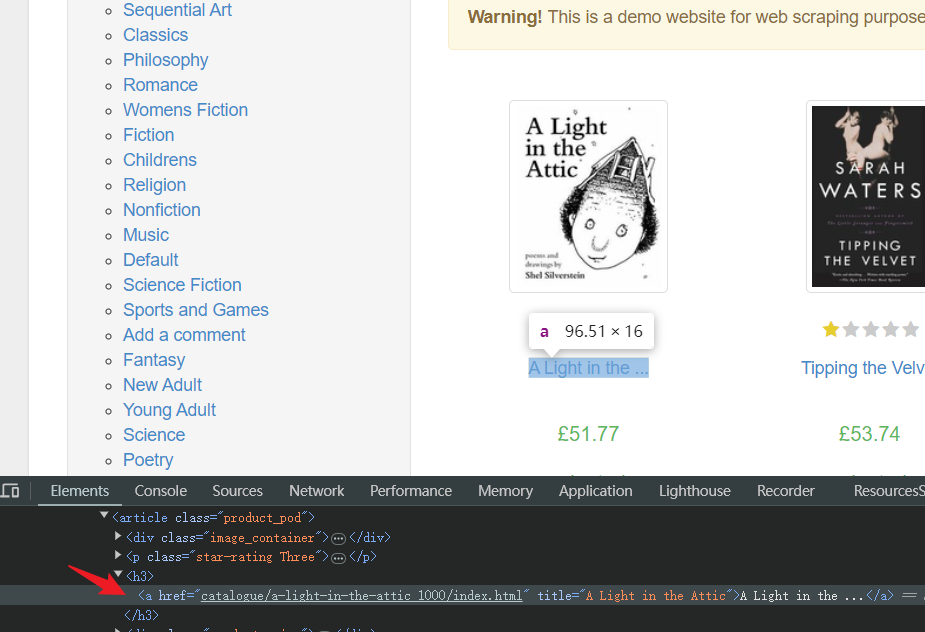
- Xác định phần tử HTML tương ứng với tiêu đề sách ở bất kỳ vị trí nào:
- Tập lệnh:
Python
import asyncio
from pyppeteer import connect
async def main():
# Kết nối với trình duyệt
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Kết nối thành công!")
# Tạo một trang mới
page = await browser.newPage()
# Truy cập Books to Scrape
await page.goto("http://books.toscrape.com/")
# Chờ danh sách sách tải
await page.waitForSelector("section")
# Chọn tất cả các phần tử tiêu đề sách
books = await page.querySelectorAll("article.product_pod > h3 > a")
# lặp qua tất cả các phần tử để trích xuất tiêu đề
for book in books:
title_element = await book.getProperty("textContent")
title = await title_element.jsonValue()
print(f"[{title}]")
await page.close()
# Chạy tập lệnh
asyncio.run(main())- Kết quả:
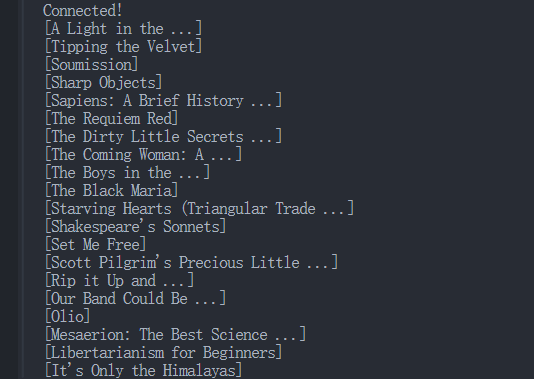
Chạy tập lệnh trên sẽ xuất ra tất cả dữ liệu thu thập được trong bảng điều khiển:
Bước 5: Kiểm tra dữ liệu trong bảng điều khiển Browserless
Bạn có thể xem thống kê cho các yêu cầu gần đây và thời gian phiên còn lại trong menu Browserless của Nstbrowser client.
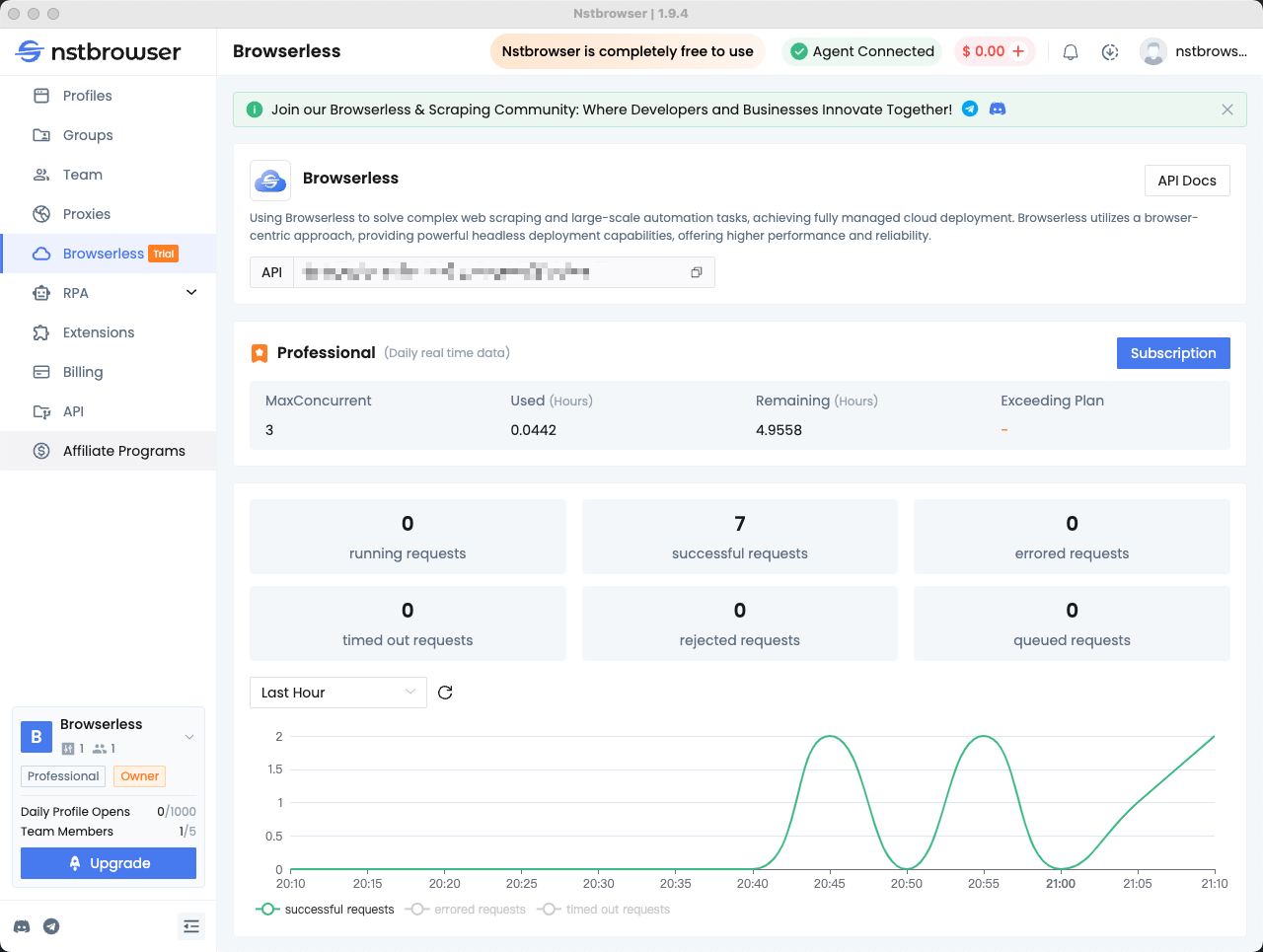
Lỗi thường gặp khi sử dụng Pyppeteer
Hầu hết các nhà phát triển có thể gặp phải một số lỗi trong khi thiết lập và sử dụng Pyppeteer. Đừng lo lắng! Bạn có thể tìm hiểu cách khắc phục chúng ở đây.
Lỗi 1: Không thể cài đặt Pyppeteer
Trong khi cài đặt Pyppeteer, bạn có thể gặp lỗi "Không thể cài đặt Pyppeteer".
Hãy kiểm tra phiên bản Python trên hệ thống của bạn. Pyppeteer chỉ hỗ trợ Python 3.6 trở lên. Do đó, hãy thử nâng cấp Python và cài đặt lại Pyppeteer.
Lỗi 2: Trình duyệt Pyppeteer đóng bất ngờ
Bạn có thể gặp lỗi này: pyppeteer.errors.BrowserError: Browser closed unexpectedly khi bạn thực thi một tập lệnh Python Pyppeteer lần đầu tiên sau khi cài đặt.
Điều này có nghĩa là tất cả các phụ thuộc của Chromium chưa được cài đặt đầy đủ. Hãy cài đặt trình điều khiển Chrome thủ công bằng lệnh sau:
Plain Text
pyppeteer-installGhi chú quan trọng
Pyppeteer là một cổng Python không chính thức của thư viện Puppeteer Node.js cổ điển. Nó là một gói dễ cài đặt, nhẹ và nhanh chóng cho tự động hóa web và thu thập dữ liệu trang web động.
Trong blog này, bạn đã học được:
- Pyppeteer là gì?
- Các bước cụ thể để tích hợp Pyppeteer với Browserless.
- Các trường hợp sử dụng khác của Pyppeteer.
Nếu bạn muốn biết thêm về các tính năng của Browserless, hãy xem hướng dẫn chính thức. Nstbrowser cung cấp cho bạn trình duyệt đám mây tốt nhất để giải quyết các hạn chế cục bộ của công việc tự động hóa.
Hơn





