
Browserless
Phân tích dấu vân tay HTTP/2 và cách vượt qua nó?
Tìm hiểu cách vượt qua dấu vân tay HTTP/2 trong thu thập dữ liệu web với sáu phương pháp mạnh mẽ, từ việc sử dụng trình duyệt thực tế đến Browserless dựa trên đám mây. Tránh bị phát hiện bởi các biện pháp chống bot hiện đại.
Jun 03, 2025Carlos Rivera
Trong bối cảnh công nghệ web scraping và chống scraping phát triển nhanh chóng như ngày nay, các kỹ thuật truyền thống như giả mạo User-Agent và bỏ qua JavaScript không còn đủ để đối phó với các cơ chế phát hiện ngày càng tinh vi. Khi ngày càng nhiều trang web chuyển sang giao thức HTTP/2 hiệu quả, việc nhận dạng dấu vân tay HTTP/2 đã âm thầm nổi lên như một vũ khí chống scraping mạnh mẽ.
Bài viết này, bạn sẽ học được:
- HTTP/2 là gì và hoạt động như thế nào
- Sáu phương pháp thực tế để bỏ qua việc nhận dạng dấu vân tay HTTP/2
Hãy làm theo lời tôi và tìm hiểu thêm!
HTTP/2 là gì?
HTTP/2 là thế hệ thứ hai của giao thức HTTP. Kể từ khi phát hành vào năm 2015, khoảng một nửa số trang web đã áp dụng nó. Ví dụ:
- Google (bao gồm Gmail, Tìm kiếm, Drive, v.v.)
- YouTube
- Amazon
- Netflix
Bạn có thể kiểm tra xem một yêu cầu sử dụng HTTP/1.1 hay HTTP/2 (h2) bằng cách nhấn F12 trong trình duyệt của bạn và xem tab Network.
HTTP/2 cải thiện hiệu suất tải trang thông qua đa luồng, nén tiêu đề (HPACK) và sử dụng lại kết nối. Không giống như bản chất tuần tự của HTTP/1.1, HTTP/2 xử lý nhiều yêu cầu và phản hồi đồng thời trên một kết nối duy nhất.
Các tính năng chính bao gồm:
- Đa luồng: Nhiều yêu cầu chia sẻ một kết nối TCP
- Nén tiêu đề: Sử dụng HPACK để giảm sự dư thừa
- Giao thức nhị phân: Cấu trúc hiệu quả hơn để truyền dữ liệu
- Điều khiển ưu tiên: Tối ưu hóa lập lịch trình tài nguyên
Nhận dạng dấu vân tay HTTP/2 là gì?
Nhận dạng dấu vân tay HTTP/2 là một kỹ thuật xác định khách hàng bằng cách phân tích sự khác biệt tinh tế trong hành vi của họ khi sử dụng giao thức HTTP/2. Những khác biệt này thường nằm ở cách giao thức được triển khai. Các trình duyệt, thư viện scraping và công cụ tự động khác nhau sẽ hiển thị các đặc điểm riêng biệt ở mức thấp.
Nói một cách đơn giản:
Thay vì xác định bạn thông qua User-Agent của bạn, nó quan sát cách khách hàng của bạn hoạt động ở lớp HTTP/2 để xác định xem bạn có phải là "script giả làm trình duyệt" hay không.
HTTP/2 truyền các khung nhị phân bao gồm nhiều trường.

Mỗi khách hàng triển khai các khung này — giá trị, thứ tự, tổ hợp — khác nhau. Hệ thống chống scraping xây dựng cơ sở dữ liệu dấu vân tay dựa trên điều này để xác định:
- Bạn có đang sử dụng
requests + httpxcủa Python không - Bạn có đang sử dụng Playwright + Node.js không
- Bạn có phải là người dùng trình duyệt Chrome thực sự không
Bạn có thể xem dấu vân tay HTTP/2 của mình trên trang kiểm tra HTTP/2 của BrowserLeaks.
Các chỉ số dấu vân tay phổ biến bao gồm:
- Nội dung SETTINGS: Mỗi khách hàng đặt các tham số khác nhau
- Thứ tự HEADERS: Trình tự của :method, :path, user-agent, v.v.
- Khung PRIORITY: Thường bị bỏ qua bởi các thư viện nhưng được sử dụng bởi các trình duyệt
- Hành vi WINDOW_UPDATE: Tần suất và cách sử dụng có thể cho biết
- Tổ hợp khung ban đầu: Một số khách hàng gửi nhiều khung SETTINGS
- Dấu vân tay TLS (JA3): Không phải là một phần của HTTP/2 nhưng thường được phân tích cùng nhau
Tại sao đây là mối đe dọa đối với người dùng Scraping?
Bởi vì nhận dạng dấu vân tay HTTP/2 đi sâu vào lớp giao thức, nên việc giả mạo nó khó hơn nhiều so với việc phát hiện dựa trên User-Agent hoặc JavaScript. Bằng cách phân tích khung SETTINGS, thứ tự khung, cập nhật cửa sổ và khung ưu tiên, máy chủ có thể xác định chính xác xem bạn có đang sử dụng công cụ scraping hay không.
Tệ hơn nữa, việc phát hiện thường xảy ra trước khi nội dung yêu cầu của bạn thậm chí còn được gửi — nghĩa là bạn có thể bị chặn trước khi gửi bất kỳ dữ liệu nào.
Nhận dạng dấu vân tay HTTP/2 so với nhận dạng dấu vân tay trình duyệt
Nhận dạng dấu vân tay trình duyệt sử dụng JavaScript phía trước để phân tích phiên bản trình duyệt, plugin, phông chữ và hơn thế nữa. Ngược lại, nhận dạng dấu vân tay HTTP/2 tập trung vào các chi tiết giao thức cấp thấp như thứ tự khung SETTINGS, kích thước cửa sổ và cài đặt ưu tiên. Những điều này gắn liền với hệ điều hành, thư viện TLS và hành vi ở cấp độ kernel — làm cho chúng khó giả mạo hơn nhiều.
Kết quả là, nhận dạng dấu vân tay HTTP/2 kín đáo hơn và khó bỏ qua hơn so với nhận dạng dấu vân tay trình duyệt.
Chúng ta thực sự có thể bỏ qua nó không?
Có! Chỉ cần tìm hiểu thêm từ 6 phương pháp tiếp theo của chúng tôi.
Sáu cách thực tế để bỏ qua việc nhận dạng dấu vân tay HTTP/2
Phương pháp 1: Sử dụng trình duyệt thực để tái tạo hành vi HTTP/2 thực sự
Điều khiển một trình duyệt Chromium thực bằng Puppeteer hoặc Playwright. Bộ xử lý HTTP/2 và quá trình bắt tay TLS của nó vốn đã bắt chước hành vi của con người, làm cho việc phát hiện trở nên khó khăn hơn.
Quá trình bắt tay TLS liên quan đến một loạt các bước cho phép máy khách và máy chủ xác thực và đồng ý về các tiêu chuẩn mã hóa trước khi truyền dữ liệu.
Thiết lập được đề xuất:
- Sử dụng Playwright ở chế độ headful
- Thêm
--enable-features=NetworkServiceInProcessđể thực thi HTTP/2 gốc - Cài đặt
puppeteer-extra-plugin-stealth - Cấu hình biến môi trường trình duyệt (ngôn ngữ, múi giờ, kích thước màn hình)
- Xoay các proxy IP và tiêu đề User-Agent
Ưu điểm: Hành vi giống người vốn có
Nhược điểm: Tiêu thụ tài nguyên cao, năng suất scraping hạn chế
Phương pháp 2: Xây dựng một máy khách HTTP/2 tùy chỉnh bắt chước hành vi của trình duyệt
Đối với độ đồng thời cao, bạn có thể tự động xây dựng một máy khách HTTP/2 bắt chước hành vi của trình duyệt — từ quá trình bắt tay TLS đến cấu trúc khung ban đầu.
Các điểm mô phỏng chính:
- Dấu vân tay TLS
- Thứ tự đàm phán ALPN
- Trình tự và trường khung SETTINGS
- Thứ tự tiêu đề và độ nhạy trường hợp
- Sử dụng chính xác các tiêu đề
:authorityvàhost
Các công cụ được đề xuất: undici, http2-wrapper, hyper, curl, nghttp2
Ưu điểm: Hiệu suất cao, nhẹ
Nhược điểm: Cực kỳ khó triển khai; yêu cầu kiến thức giao thức sâu sắc
Phương pháp 3: Sử dụng dịch vụ proxy dấu vân tay HTTP/2
Sử dụng proxy lớp trung gian biến đổi các yêu cầu tiêu chuẩn thành các yêu cầu có đặc điểm giống trình duyệt — ví dụ: TLS-Proxy.
Cách hoạt động:
- Máy khách gửi yêu cầu thông qua
httpxhoặc tương tự - Proxy ghi lại các khung HTTP/2 và sửa đổi quá trình bắt tay TLS
- Máy chủ đích nhận thấy một yêu cầu bắt chước Chrome
Phương pháp 4: Phát lại các yêu cầu của trình duyệt thực
Xuất NetLog hoặc ghi lại lưu lượng truy cập bằng Wireshark để ghi nhật ký các tương tác HTTP/2 của trình duyệt thực, sau đó phát lại các phiên đó.
Các công cụ được đề xuất: nghttp2, h2, chrome://net-export, Wireshark
Ưu điểm: Mô phỏng gần như hoàn hảo các yêu cầu thực
Nhược điểm: Quá trình phức tạp, phù hợp nhất cho việc sử dụng quy mô nhỏ
Phương pháp 5: Phối hợp dấu vân tay TLS
Trước khi đàm phán HTTP/2, trình duyệt thực hiện quá trình bắt tay TLS ClientHello cũng tạo ra dấu vân tay.
Các công cụ được đề xuất:
tls-client(Node.js)uTLS(Go)mitmproxy(Python)
Đảm bảo cấu hình TLS và ALPN khớp với trình duyệt mục tiêu để ngụy trang hoàn toàn.
Phương pháp 6: Sử dụng Nstbrowser Browserless
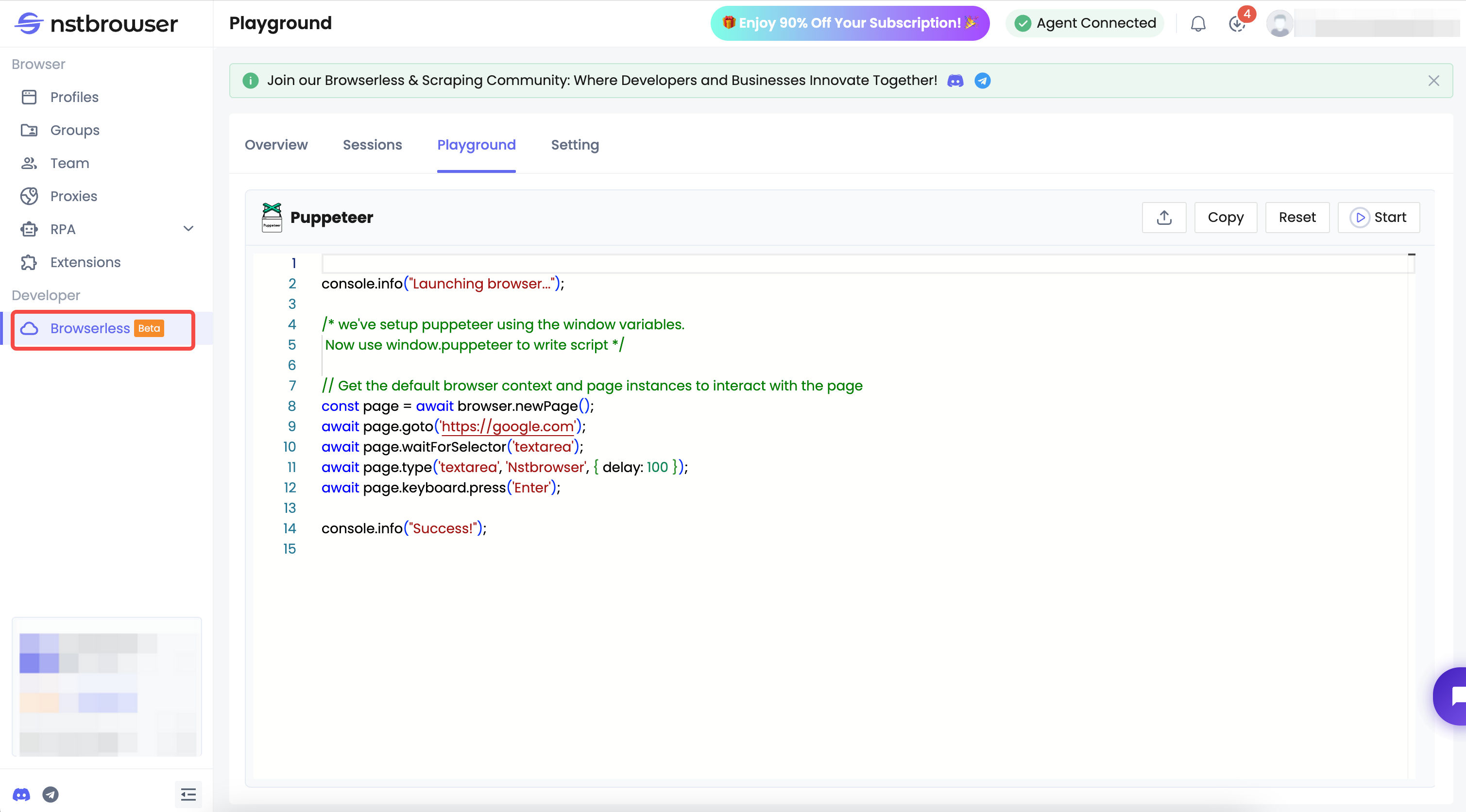
Nếu bạn đang tìm kiếm một giải pháp scraping ổn định, hiệu quả và hầu như không thể phát hiện, Browserless của Nstbrowser - một dịch vụ trình duyệt đám mây là một trong những lựa chọn tốt nhất hiện có.
Những ưu điểm chính của Browserless bao gồm:
- Môi trường trình duyệt thực: Dựa trên Chromium, nó mô phỏng hành vi người dùng thực sự để tăng độ bí mật.
- Làm mờ dấu vân tay: Sử dụng thư viện dấu vân tay của Nstbrowser để luân phiên danh tính và hiệu quả bỏ qua hầu hết các cơ chế chống bot — bao gồm cả dấu vân tay TLS và HTTP/2.
- Dựa trên đám mây: Không yêu cầu tài nguyên cục bộ, hỗ trợ các tác vụ scraping độ đồng thời cao, dễ tích hợp và mở rộng.
- Giám sát tài nguyên: Theo dõi thời gian thực về việc sử dụng RAM, CPU và GPU đảm bảo cân bằng tải hiệu quả.
- Tích hợp linh hoạt: Hỗ trợ API, Puppeteer, Playwright và hơn thế nữa — phù hợp với nhiều quy trình tự động khác nhau.
Browserless có khả năng chống bot và mở khóa mạnh mẽ được tích hợp sẵn. Nó sử dụng dấu vân tay trình duyệt thực và hành vi giống người để dễ dàng bỏ qua các phát hiện ở cấp độ trình duyệt và HTTP.
Khám phá phiên bản dùng thử miễn phí ngay bây giờ!
Suy nghĩ cuối cùng
Nhận dạng dấu vân tay HTTP/2 đã trở thành công nghệ chống bot thế hệ tiếp theo không thể thiếu. Các phương pháp truyền thống, chẳng hạn như chỉ dựa vào việc giả mạo user agent hoặc bỏ qua JavaScript, không còn hoàn toàn hiệu quả. Để nổi bật trong các hệ thống chống bot hiện đại, chiến lược phù hợp đòi hỏi phải mô phỏng toàn diện - từ ngăn xếp giao thức và TLS đến hành vi của trình duyệt.
Nếu bạn đang tìm kiếm một giải pháp bỏ qua hiệu suất cao, rủi ro thấp, Nstbrowser Browserless cung cấp các khả năng mô phỏng giống người nhất hiện có. Nó là sự lựa chọn hàng đầu cho các kỹ sư dữ liệu, những người làm tăng trưởng và nhà nghiên cứu bảo mật.
Hơn





