
Browserless
Как парсить динамические сайты с помощью Browserless?
Скрапинг динамических веб-страниц – это действительно сложно! Как же сделать это легко? Узнайте лучший способ в этом руководстве.
Oct 18, 2024Vasilisa Samsonova
Что такое динамическая веб-страница?
Динамическая веб-страница - это страница, где контент не полностью вставлен в статический HTML, а генерируется с помощью серверного или клиентского рендеринга.
Она может отображать данные в режиме реального времени на основе действий пользователя, например, загружать больше контента при нажатии пользователем кнопки или прокрутке вниз по странице (например, бесконечная прокрутка). Такая конструкция улучшает пользовательский опыт и позволяет пользователям получать релевантную информацию без перезагрузки всей страницы.
Чтобы определить, является ли сайт динамической веб-страницей, вы можете отключить JavaScript в своем браузере. Если сайт динамичный, большая часть контента исчезнет.
Проблемы при парсинге динамических сайтов
Отпечатки пальцев и блокировка
-
Техники отпечатков пальцев: Многие сайты используют техники отпечатков пальцев для обнаружения и блокировки автоматических парсеров. Эти техники создают уникальный "отпечаток пальца" для каждого посетителя, анализируя информацию, такую как поведение в браузере, разрешение экрана, плагины, часовой пояс и т. д. Если обнаруживаются аномалии или несоответствия обычному поведению пользователя, сайт может заблокировать доступ.
-
Механизмы блокировки: Чтобы защитить свой контент, сайты реализуют различные механизмы блокировки, такие как:
- Блокировка IP: Когда частые запросы поступают с одного и того же IP-адреса, сайт может временно или навсегда запретить доступ с этого IP-адреса.
- Проверка CAPTCHA: Сайты могут вводить CAPTCHA при обнаружении автоматического трафика, чтобы подтвердить, что посетитель является человеком.
- Ограничение трафика: Устанавливает лимит частоты запросов, и когда частота запросов превышает установленный порог, сайт отклоняет дальнейшие запросы.
Проблемы локальной загрузки
- Потребление ресурсов: Динамические страницы обычно требуют больше системных ресурсов для рендеринга и сбора данных. При использовании таких инструментов, как Puppeteer или Selenium, это может привести к высокому использованию памяти и процессора, особенно при парсинге нескольких страниц.
- Задержка и временные затраты: Из-за необходимости ждать полной загрузки страницы (включая выполнение JavaScript и AJAX-запросов) временные затраты на парсинг динамических страниц могут быть высокими, что повлияет на эффективность всего парсера.
- Одновременная обработка: При высоких нагрузках одновременная обработка нескольких задач парсинга может привести к перегрузке системы, что приведет к сбоям запросов или тайм-ауту. Это требует разумных стратегий планирования задач и управления ресурсами.
Есть ли у вас какие-либо замечательные идеи или сомнения по поводу веб-парсинга и Browserless?
Давайте посмотрим, чем делятся другие разработчики на Discord и Telegram!
6 эффективных способов парсинга динамических сайтов
1. Перехват XHR/Fetch запросов
Эффективный способ перехвата XHR (XMLHttpRequest) и Fetch запросов во время процесса парсинга - это проверка вкладки Network браузера, чтобы определить конечные точки API, которые предоставляют динамический контент. После идентификации этих конечных точек HTTP-клиенты, такие как библиотека Requests, могут использоваться для отправки запросов непосредственно к этим API для получения данных.
- Плюсы: Этот метод обычно быстрый и может эффективно извлекать данные, поскольку он получает только необходимый контент, а не всю веб-страницу.
- Минусы: Это может быть проблематично, если данные хранятся в DOM в виде JSON, а не возвращаются API. Кроме того, процесс имитации запросов API может быть затронут изменениями API, ограничениями частоты и требованиями к аутентификации, что приводит к плохой масштабируемости.
2. Использование headless-браузера
Использование headless-браузера, такого как Puppeteer или Selenium, позволяет полностью имитировать поведение пользователя, включая загрузку страницы и взаимодействие. Эти инструменты способны обрабатывать JavaScript и парсить динамически генерируемый контент.
- Плюсы: Этот метод позволяет парсить очень динамичные сайты и поддерживать сложное взаимодействие с пользователем.
- Минусы: высокое потребление ресурсов, медленная скорость парсинга, а также может потребоваться работа со сложными структурами страниц и динамическим контентом.
3. Запрос API
Запрос данных непосредственно из API сайта - это эффективный способ парсинга. Анализируйте сетевые запросы сайта, находите конечную точку API и используйте HTTP-клиент для запроса данных.
- Плюсы: Возможность получения непосредственно необходимых данных и избежание сложности парсинга HTML.
- Минусы: Если API требует аутентификации или имеет ограничение частоты запросов, это может повлиять на эффективность парсинга.
4. Парсинг AJAX запросов
Отслеживая сетевые запросы, идентифицируя AJAX-вызовы и воспроизводя их, можно извлекать динамически загруженные данные.
- Плюсы: Получение непосредственно источников данных и сокращение ненужной загрузки.
- Минусы: Требуется определенное понимание параметров и формата AJAX-запросов, а также могут возникнуть проблемы с аутентификацией и ограничениями частоты.
5. Прокси и ротация IP
Чтобы избежать блокировки сайтом, использование прокси-сервисов и ротации IP - это важная стратегия. Это поможет распределить запросы и снизить риск обнаружения.
- Плюсы: Снижение вероятности блокировки и возможность поддержания эффективности при большом количестве запросов.
- Минусы: Использование прокси-сервисов может увеличить затраты на парсинг и потребовать поддержания списка прокси.
6. Имитация поведения пользователя
Написание скриптов для имитации поведения пользователя при просмотре, например, добавление задержек между запросами, рандомизация порядка операций и т. д., может помочь снизить риск того, что сайт идентифицирует вас как парсер.
- Плюсы: Парсинг данных может выполняться более естественно, снижая риск обнаружения.
- Минусы: Реализация относительно сложная, и требуется время на настройку и оптимизацию имитируемого поведения.
Что такое Browserless?
Browserless - это облачный сервис headlesschrome, который работает с онлайн-приложениями и автоматизирует скрипты без графического интерфейса. Он особенно полезен для таких задач, как веб-парсинг и другие автоматизированные операции.
Browserless упрощает парсинг динамических веб-страниц
Browserless - это также мощный headless-браузер. Далее мы будем использовать Browserless в качестве примера для парсинга динамических веб-страниц.
Предварительные условия
Прежде чем начать, нам нужно иметь сервис Browserless. Использование Browserless может решить сложные задачи веб-парсинга и крупномасштабной автоматизации, и теперь достигнуто полное управление развертыванием в облаке.
Browserless использует стратегию, ориентированную на браузер, предоставляет мощные возможности headless-развертывания и обеспечивает более высокую производительность и надежность. Вы можете щелкнуть здесь, чтобы узнать больше о настройке сервисов Browserless.
В самом начале нам нужно было получить API KEY от Nstbrowser. Вы можете перейти на страницу меню Browserless в клиенте Nstbrowser, или вы можете щелкнуть здесь, чтобы перейти.
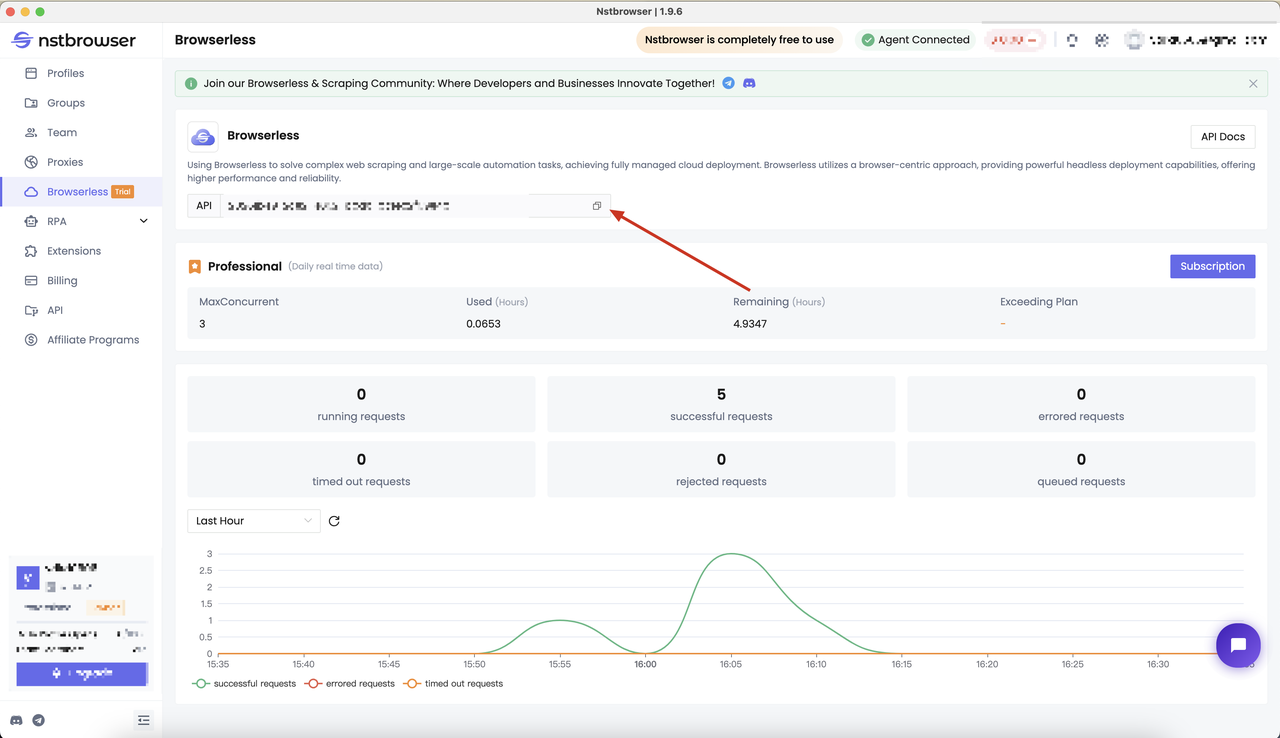
Определение цели парсинга
Прежде чем начать, определим цель этого теста. Мы будем использовать Puppeteer и Playwright, чтобы получить контент заголовка страницы динамических сайтов:
- Посетите целевой сайт: https://www.nstbrowser.io/en
- Получите контент динамического заголовка страницы
Инициализация проекта
Выполните следующие шаги, чтобы установить зависимости:
- Шаг 1: Создайте новую папку в Vs code
- Шаг 2: Откройте терминал Vs code и выполните следующие команды, чтобы установить соответствующие зависимости
SQL
npm init -y
pnpm add playwright puppeteer-coreПарсинг динамических веб-страниц с использованием Playwright и Browserless
- Создайте скрипт парсинга
TypeScript
const { chromium } = require('playwright');
async function createBrowser() {
const token = ''; // required
const config = {
proxy:
'', // required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
// platform: 'windows', // support: windows, mac, linux
// kernel: 'chromium', // only support: chromium
// kernelMilestone: '124', // support: 113, 120, 124
// args: {
// '--proxy-bypass-list': 'detect.nstbrowser.io',
// }, // browser args
// fingerprint: {
// userAgent:
// 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36',
// },
};
const query = new URLSearchParams({
token: token, // required
config: JSON.stringify(config),
});
const browserWSEndpoint = `ws://less.nstbrowser.io/connect?${query.toString()}`;
const browser = await chromium.connectOverCDP(browserWSEndpoint);
const context = await browser.newContext();
const page = await context.newPage();
page.goto('https://www.nstbrowser.io/en');
// sleep for 5 seconds
await new Promise((resolve) => setTimeout(resolve, 5000));
const h1Element = await page.$('h1');
const content = await h1Element?.textContent();
console.log(`Playwright: The content of the h1 element is: ${content}`)
await page.close();
await page.context().close();
}
createBrowser().then();- Проверьте результат парсинга

Парсинг динамических веб-страниц с использованием Puppeteer и Browserless
- Создайте скрипт парсинга
TypeScript
const puppeteer = require('puppeteer-core');
async function createBrowser() {
const token = ''; // required
const config = {
proxy:
'', // required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
// platform: 'windows', // support: windows, mac, linux
// kernel: 'chromium', // only support: chromium
// kernelMilestone: '124', // support: 113, 120, 124
// args: {
// '--proxy-bypass-list': 'detect.nstbrowser.io',
// }, // browser args
// fingerprint: {
// userAgent:
// 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36',
// },
};
const query = new URLSearchParams({
token: token, // required
config: JSON.stringify(config),
});
const browserWSEndpoint = `ws://less.nstbrowser.io/connect?${query.toString()}`;
const browser = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto('https://www.nstbrowser.io/en');
// sleep for 5 seconds
await new Promise((resolve) => setTimeout(resolve, 5000));
const h1Element = await page.$('h1');
if (h1Element) {
const content = await page.evaluate((el) => el.textContent, h1Element); // use page.evaluate to get the text content of the h1 element
console.log(`Puppeteer: The content of the h1 element is: ${content}`);
} else {
console.log('No h1 element found.');
}
await page.close();
}
createBrowser().then();- Проверьте результат парсинга

Заключение
Парсинг динамических веб-страниц всегда сложнее, чем парсинг обычных веб-страниц. Во время процесса парсинга легко столкнуться с различными проблемами. Благодаря представленной в этом блоге информации вы должны были узнать:
- 6 эффективных способов парсинга динамических веб-страниц
- Использование Browserless для простого парсинга динамических веб-страниц
Больше





