
Browserless
Pyppeteer: Как использовать Puppeteer в Python с Browserless?
Что такое Pyppeteer? Как мы можем интегрировать Pyppeteer в Browserless? В этом блоге вы можете найти подробные шаги по полному использованию Pyppeteer.
Oct 09, 2024Luke Ulyanov
Что такое Pyppeteer в Python?
Pyppeteer — это порт популярной библиотеки Puppeteer для Node.js на Python, который используется для программного управления браузерами Chrome или Chromium без графического интерфейса.
По сути, Pyppeteer позволяет разработчикам на Python автоматизировать задачи в веб-браузере, такие как скрапинг веб-страниц, тестирование веб-приложений или взаимодействие с сайтами, как если бы это делал реальный пользователь, но без графического интерфейса.
Что такое Browserless?
Browserless — это облачное решение для браузера, которое позволяет эффективно автоматизировать браузер, скрапить сайты и тестировать.
Он использует библиотеку отпечатков пальцев Nstbrowser для включения случайного переключения отпечатков пальцев, что приводит к беспроблемному сбору данных и автоматизации. Надежная облачная инфраструктура Browserless упрощает управление автоматизированными действиями, позволяя одновременно получать доступ к нескольким экземплярам браузера.
Есть ли у вас замечательные идеи и сомнения по поводу веб-скрапинга и Browserless?
Давайте посмотрим, чем делятся другие разработчики на Discord и Telegram!
Для чего можно использовать Pyppeteer?
Скриншот с использованием Pyppeteer
При использовании Browserless вы не видите экран, поэтому, когда нам нужно знать конкретный экран браузера по некоторым ссылкам, рекомендуется использовать API скриншотов для получения скриншота.
Выполнение следующего скрипта создаст скриншот с именем youtube_screenshot.png в текущем пути к скрипту:
Python
import asyncio
from pyppeteer import connect
async def main():
# Подключение к браузеру
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Подключено!")
# Создание новой страницы
page = await browser.newPage()
# Посещение youtube
await page.goto("https://www.youtube.com/")
# сделать скриншот
await page.screenshot({"path": "youtube_screenshot.png"})
await page.close()
asyncio.run(main())Взаимодействие с динамическими страницами
На современных сайтах для динамического обновления контента используется JavaScript. Например, социальные сети часто используют бесконечную прокрутку для своих постов, а загрузка данных страницы также требует ожидания ответа бэкэнда, а также различных операций с формами и различных событий браузера.
Да, Pyppeteer также может выполнять это: ожидание загрузки, щелчок кнопок, ввод в формы и другие операции с браузером.
1. Ожидание загрузки страницы
Обычно используемые API для ожидания загрузки страницы — это waitForSelector и waitFor.
waitForSelectorв основном используется для того, чтобы убедиться, что определенный элемент на странице загружен правильноwaitForпросто ждет заданное время.
Python
import asyncio
from pyppeteer import connect
async def main():
# Подключение к браузеру
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Подключено!")
# Посещение nasa
page = await browser.newPage()
await page.goto("https://www.disney.com/")
# Ожидание загрузки новостей
await page.waitForSelector('.content-body')
# подождите еще 2 секунды
await page.waitFor(2000)
# сделать скриншот
await page.screenshot({"path": "disney.png"})
await page.close()
asyncio.run(main())2. Прокрутка страницы
В page.evaluate вы можете задать положение полосы прокрутки, вызвав API окна, что очень удобно.
Python
import asyncio
from pyppeteer import connect
async def main():
# Подключение к браузеру
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Подключено!")
# Посещение HBO Max
page = await browser.newPage()
await page.goto('https://www.max.com/');
# Прокрутка до конца
await page.evaluate("window.scrollTo(0, document.documentElement.scrollHeight)");
# сделать скриншот
await page.screenshot({"path": "HBOMax.png"})
await page.close()
asyncio.run(main())3. Нажмите кнопку
В Python Pyppeteer мы можем использовать page.click, чтобы щелкнуть кнопку или гиперссылку. Установка задержки ввода делает ее больше похожей на действия реального пользователя.
Ниже приведен простой пример.
Python
import asyncio
from pyppeteer import connect
async def main():
# Подключение к браузеру
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Подключено!")
page = await browser.newPage()
await page.goto("https://example.com/")
# щелкнуть ссылку
await page.click("p > a", {"delay": 200})
# сделать скриншот
await page.screenshot({"path": "example.png"})
await page.close()
asyncio.run(main())4. Ввод в форму
Как ввести данные с помощью Python Pyppeteer? Используйте page.type, чтобы ввести текст в указанное поле ввода.
Python
import asyncio
from pyppeteer import connect
async def main():
# Подключение к браузеру
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Подключено!")
# Создание новой страницы
page = await browser.newPage()
# Посещение разработчика Chrome
await page.goto("https://developer.chrome.com/")
await page.setViewport({"width": 1920, "height": 1080})
# Ввод текста в поле поиска
await page.type(".devsite-search-field", "headless", {"delay": 200})
# сделать скриншот
await page.screenshot({"path": "developer.png"})
await page.close()
asyncio.run(main())Вход с использованием Pyppeteer
После приведенных выше примеров мы можем легко представить себе взаимодействия, участвующие в входе, такие как операция ввода типа и операция щелчка кнопки.
Итак, в следующем примере давайте изменим способ написания. Мы попробуем войти в Nstbrowser Client. После входа я сделаю скриншот, чтобы проверить, был ли вход успешным.
Python
import asyncio
from pyppeteer import connect
async def main():
# Подключение к браузеру
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Подключено!")
# Посещение Nstbrowser Client
page = await browser.newPage()
await page.goto("https://app.nstbrowser.io/account/login")
await page.waitForSelector("input")
inputs = await page.querySelectorAll("input")
# Введите свой адрес электронной почты в первое поле ввода
await inputs[0].type("[email protected]", delay=100)
# Введите свой пароль во второе поле ввода
await inputs[1].type("9KLYUWn3GmrzHPRGQl0EZ1QP3OWPFwcB", delay=100)
buttons = await page.querySelectorAll("button")
# Нажмите кнопку входа
await buttons[1].click()
# Ожидание ответа на запрос входа
login_url = "https://api.nstbrowser.io/api/v1/passport/login"
await page.waitForResponse(lambda res: res.url == login_url)
await page.waitFor(2000)
# сделать скриншот
await page.screenshot({"fullPage": True, "path": "./nstbrowser.png"})
await page.close()
asyncio.run(main())- Результат выполнения:
Мы видим, что наш проект перенаправлен на домашнюю страницу, что означает, что мы успешно вошли в Nstbrowser!
Как использовать Pyppeteer в Browserless?
Может ли Pyppeteer работать с Browserless?
Конечно, вы можете найти конкретные шаги по интеграции Pyppeteer в Browserless!
Шаг 1: Получите API KEY
Прежде чем начать, нам нужна служба Browserless. Использование Browserless может решить сложные задачи веб-скрапинга и крупномасштабной автоматизации, и сейчас оно достигло полностью управляемого облачного развертывания.
Browserless использует браузерно-ориентированный подход, обеспечивает мощные возможности развертывания без графического интерфейса, а также обеспечивает более высокую производительность и надежность. Чтобы узнать больше о Browserless, вы можете нажать здесь, чтобы узнать больше.
Получите API KEY и перейдите на страницу меню Browserless в клиенте Nstbrowser, или вы можете нажать здесь, чтобы получить доступ
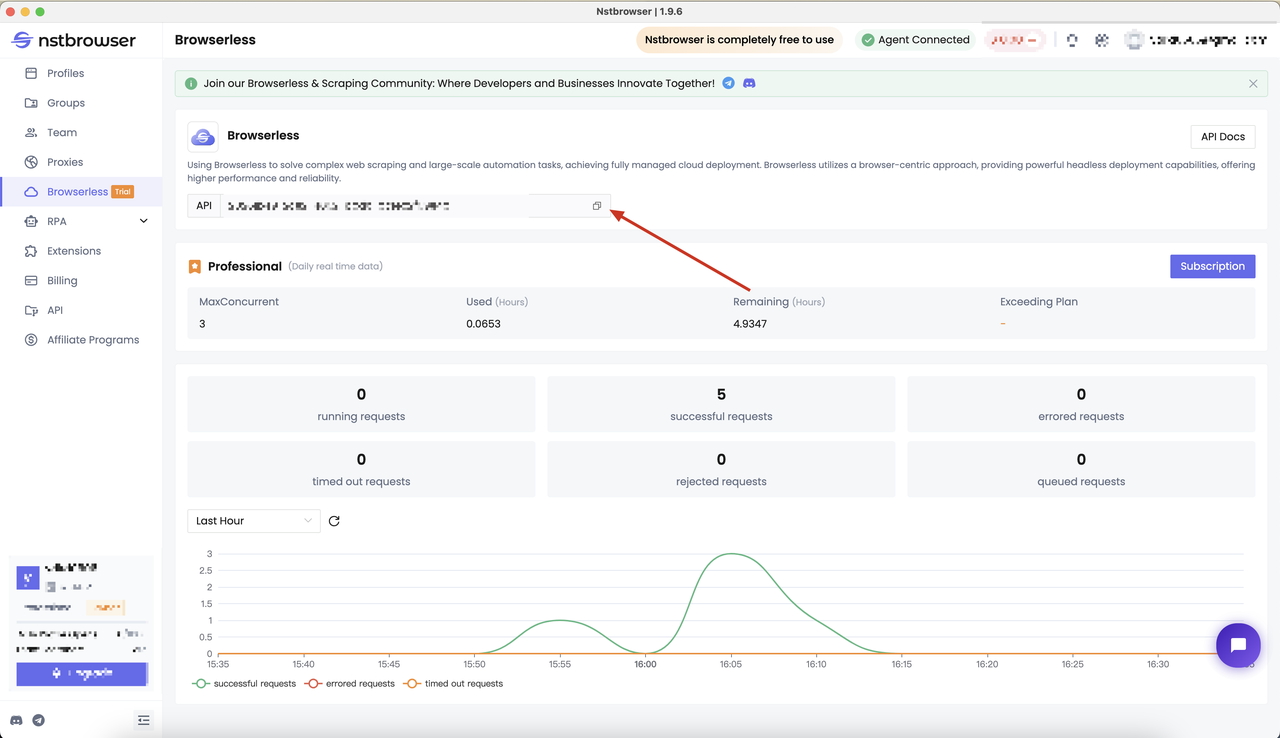
Шаг 2: Установите Pyppeteer
Pyppeteer — это версия Puppeteer для Python, которая предоставляет аналогичные функции и позволяет разработчикам управлять браузерами без графического интерфейса с помощью скриптов Python. Он позволяет разработчикам автоматизировать взаимодействие с веб-страницами с помощью кода Python и очень широко используется в таких сценариях, как краулеры, тестирование и захват данных.
Plain Text
pip install pyppeteerШаг 3: Подключите Pyppeteer к Browserless
Нам нужно подготовить следующий код. Просто введите свой API-ключ и прокси, чтобы подключиться к Browserless.
Python
from urllib.parse import urlencode
import json
token = "ваш api ключ" # 'необходимо'
config = {
"proxy": "ваш прокси", # необходимо; формат ввода: схема://пользователь:пароль@хост:порт например: http://пользователь:пароль@localhost:8080
# "platform": "windows", # поддержка: windows, mac, linux
# "kernel": 'chromium', # только поддержка: chromium
# "kernelMilestone": '128', # поддержка: 128
# "args": {
# "--proxy-bypass-list": "detect.nstbrowser.io"
# }, # аргументы браузера
# "fingerprint": {
# userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', # userAgent поддерживается с версии 0.15.0
# },
}
query = urlencode({"token": token, "config": json.dumps(config)})
browser_ws_endpoint = f"ws://less.nstbrowser.io/connect?{query}"Подключено, давайте начнем скрапинг!
Python
import asyncio
from pyppeteer import connect
async def main():
# Подключение к браузеру
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Подключено!")
asyncio.run(main())Шаг 4: Использование Pyppeteer в Browserless
В этом блоге мы рассмотрим простой пример, который поможет вам быстро начать работу с Browserless - скрапинг Books to Scrape.
В следующем примере мы пытаемся собрать все названия книг на текущей странице:
- Открыть страницу
- Дождитесь нормальной загрузки страницы
- Открыть консоль отладки
- Определите HTML-элемент, соответствующий названию книги в любом месте:
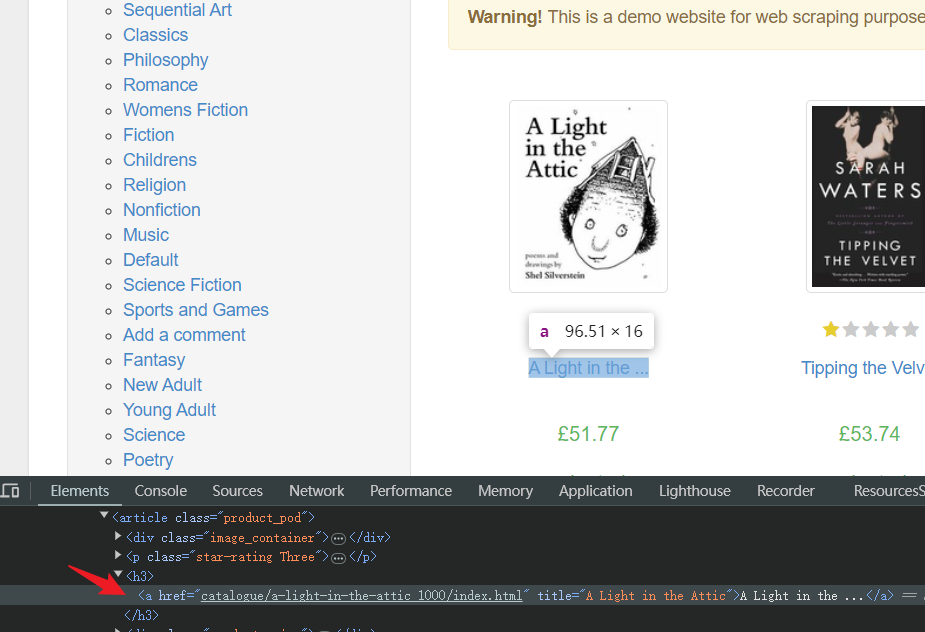
- Скрипты:
Python
import asyncio
from pyppeteer import connect
async def main():
# Подключение к браузеру
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("Подключено!")
# Создание новой страницы
page = await browser.newPage()
# Посещение Books to Scrape
await page.goto("http://books.toscrape.com/")
# Ожидание загрузки списка книг
await page.waitForSelector("section")
# Выбор всех элементов названия книги
books = await page.querySelectorAll("article.product_pod > h3 > a")
# цикл по всем элементам для извлечения названий
for book in books:
title_element = await book.getProperty("textContent")
title = await title_element.jsonValue()
print(f"[{title}]")
await page.close()
# Запуск скрипта
asyncio.run(main())- Результаты:
Выполнение приведенного выше скрипта выведет все собранные данные в консоль:
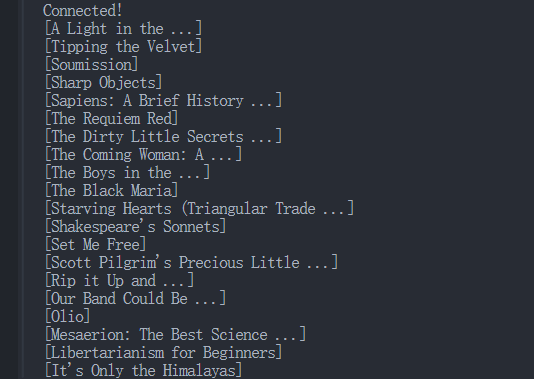
Шаг 5: Проверьте данные на панели инструментов Browserless
Вы можете просмотреть статистику по недавним запросам и оставшемуся времени сеанса в меню Browserless клиента Nstbrowser.
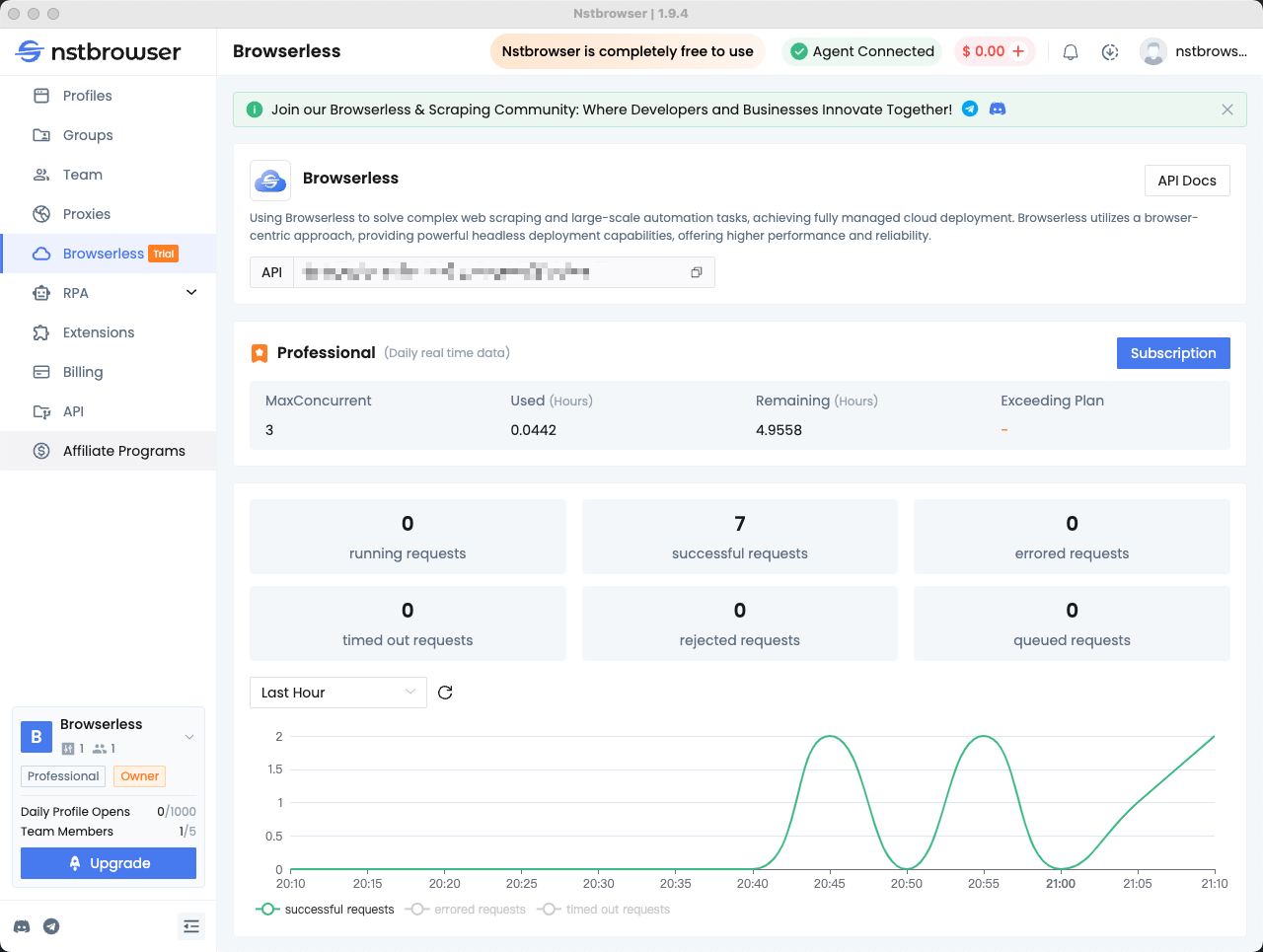
Распространенные ошибки при использовании Pyppeteer
Большинство разработчиков могут столкнуться с некоторыми ошибками при настройке и использовании Pyppeteer. Не волнуйтесь! Здесь вы можете узнать, как их исправить.
Ошибка 1: Pyppeteer не удается установить
При установке Pyppeteer вы можете столкнуться с ошибкой "Не удалось установить Pyppeteer".
Проверьте версию Python в вашей системе. Pyppeteer поддерживает только Python 3.6 и выше. Поэтому попробуйте обновить Python и переустановить Pyppeteer.
Ошибка 2: Браузер Pyppeteer неожиданно закрылся
Вы можете столкнуться с этой ошибкой: pyppeteer.errors.BrowserError: Browser closed unexpectedly, когда вы впервые запускаете скрипт Pyppeteer Python после установки.
Это означает, что все зависимости Chromium не установлены полностью. Установите драйвер Chrome вручную с помощью следующей команды:
Plain Text
pyppeteer-installВыводы
Pyppeteer — это неофициальный порт классической библиотеки Node.js Puppeteer для Python. Это простой в установке, легкий и быстрый пакет для веб-автоматизации и скрапинга динамических сайтов.
В этом блоге вы узнали:
- Что такое Pyppeteer?
- Конкретные шаги по интеграции Pyppeteer с Browserless.
- Другие варианты использования Pyppeteer.
Если вы хотите узнать больше о функциях Browserless, ознакомьтесь с официальным руководством. Nstbrowser предоставляет вам лучший облачный браузер, чтобы решить локальные ограничения работы с автоматизацией.
Больше





