
Browserless
Browserless веб-скрейпинг: NodeJS в Playwright
Что такое Playwright? Как он скрейпит веб-сайт с помощью NodeJS? Этот блог полностью посвящен тому, как делать скрейпинг Playwright с помощью NodeJS. Кроме того, здесь вы можете узнать секрет Browserless!
Aug 19, 2024Luke Ulyanov
Что такое Playwright?
Playwright — это открытая платформа для тестирования и автоматизации веб-приложений. Основан на Node.js и разработан Microsoft, он поддерживает Chromium, Firefox и WebKit через единый API. Он может работать на Windows, Linux и macOS, а также совместим с TypeScript, JavaScript, Python, .NET и Java.
Каковы преимущества использования NodeJS для веб-скрейпинга в Playwright?
Playwright — это не просто инструмент, а комплексное решение для веб-скрейпинга, сочетающее мощные функции, гибкость и эффективность в Node.js для удовлетворения самых строгих требований современного веб-автоматизации.
- Мощная обработка взаимодействий с страницей
- Автоматическая обработка динамического контента
- Устойчивость к анти-скрейпинг технологиям
В режиме без головы в Node.js Playwright предоставляет значительное преимущество. Он позволяет запускать браузер без графического интерфейса, ускоряя процесс скрейпинга и идеально подходя для масштабных задач.
Playwright хорошо справляется со сложными веб-взаимодействиями, такими как загрузка динамического контента, управление пользовательским вводом и обработка асинхронных операций. Это делает его идеальным для извлечения данных с современных сайтов, зависящих от JavaScript. Функция перехвата сетевых запросов — еще одно преимущество. Она позволяет контролировать запросы и ответы, помогая обойти меры против скрейпинга и оптимизировать процесс скрейпинга.
Еще одним преимуществом Playwright является его простая интеграция с проектами на Node.js. Вы можете легко интегрировать его в существующие рабочие процессы и использовать вместе с другими библиотеками JavaScript или TypeScript. Кроме того, так как он работает на Windows, Linux и macOS, вы можете развертывать скрипты скрейпинга на разных платформах без лишних проблем.
Что такое Browserless?
Browserless — это облачный сервис безголового браузера, разработанный Nstbrowser для выполнения веб-операций и автоматизационных скриптов без графического интерфейса.
Ключевая особенность Nstbrowserless — это возможность обхода распространенных препятствий, таких как CAPTCHA и блокировки IP, благодаря интегрированным Anti-detect, Web Unblocker и интеллектуальной системе прокси. Эти инструменты гарантируют, что ваши автоматизационные скрипты будут работать без сбоев даже на сайтах с жесткими мерами безопасности.
Browserless поддерживает облачные контейнерные кластеры, что позволяет легко масштабировать операции. Независимо от того, работаете ли вы на Windows, Linux или macOS, наша платформа предоставляет единое корпоративное решение для ваших веб-автоматизационных потребностей. Она спроектирована для бесшовной интеграции с вашим существующим рабочим процессом, предлагая мощную и надежную среду для высокопроизводительных веб-операций.
Есть замечательные идеи и вопросы о веб-скрейпинге и Browserless?
Посмотрите, что другие разработчики обсуждают в Discord и Telegram!
Как использовать Playwright и NodeJS для веб-скрейпинга?

Шаг 1: Установка и настройка Playwright
Во-первых, убедитесь, что на вашем компьютере установлен Node.js. Если нет, загрузите и установите LTS-версию. Затем используйте менеджер пакетов Node.js npm для установки Playwright.
Bash
npm init playwright@latestВыполните команду установки и сделайте следующие выборы для начала:
- Выберите между TypeScript и JavaScript (по умолчанию TypeScript).
- Назовите вашу папку с тестами (если папка с тестами уже существует, по умолчанию будет
testилиe2e). - Выберите, хотите ли вы добавить рабочие процессы GitHub Actions для запуска тестов в CI.
- Определите, хотите ли вы немедленно установить браузеры Playwright (по умолчанию да, но вы также можете установить их позже вручную с помощью
npx playwright install).
Шаг 2: Запуск браузера с помощью Playwright
Как обычный браузер, Playwright также может рендерить JavaScript, изображения и т. д., что позволяет извлекать данные, загружаемые динамически. Поскольку он имитирует нормальное поведение пользователя, скрипты труднее обнаружить и заблокировать.
JavaScript
import { chromium } from 'playwright';
const browser = await chromium.launch({ headless: false }); // Открыть браузер и создать новую вкладку
const page = await browser.newPage();
await page.goto('https://developer.chrome.com/'); // Перейти по указанному URL
await page.setViewportSize({ width: 1080, height: 1024 }); // Установить размер окна
console.log('[Браузер открыт!]');По умолчанию Playwright работает в режиме без головы. В предоставленном коде мы отключаем режим без головы, установив headless: false, чтобы визуализировать тестовый скрипт. Поскольку в package.json включена настройка "type": "module", позволяющая выполнять ES-модули, пример и следующий код не требуют асинхронных функций.
Шаг 3: Начало скрейпинга
Мы начнем с базовой задачи веб-скрейпинга, чтобы вы быстро познакомились с Playwright. Давайте извлечем отзывы о Apple AirPods Pro на Amazon!
Эффективный веб-скрейпинг начинается с анализа страницы. Вам нужно определить, где расположены данные, которые вы хотите извлечь. Консоль отладки браузера будет нам очень полезна:
После открытия веб-страницы откройте консоль отладки, нажав Ctrl + Shift + I (Windows/Linux) или Cmd + Option + I (Mac).
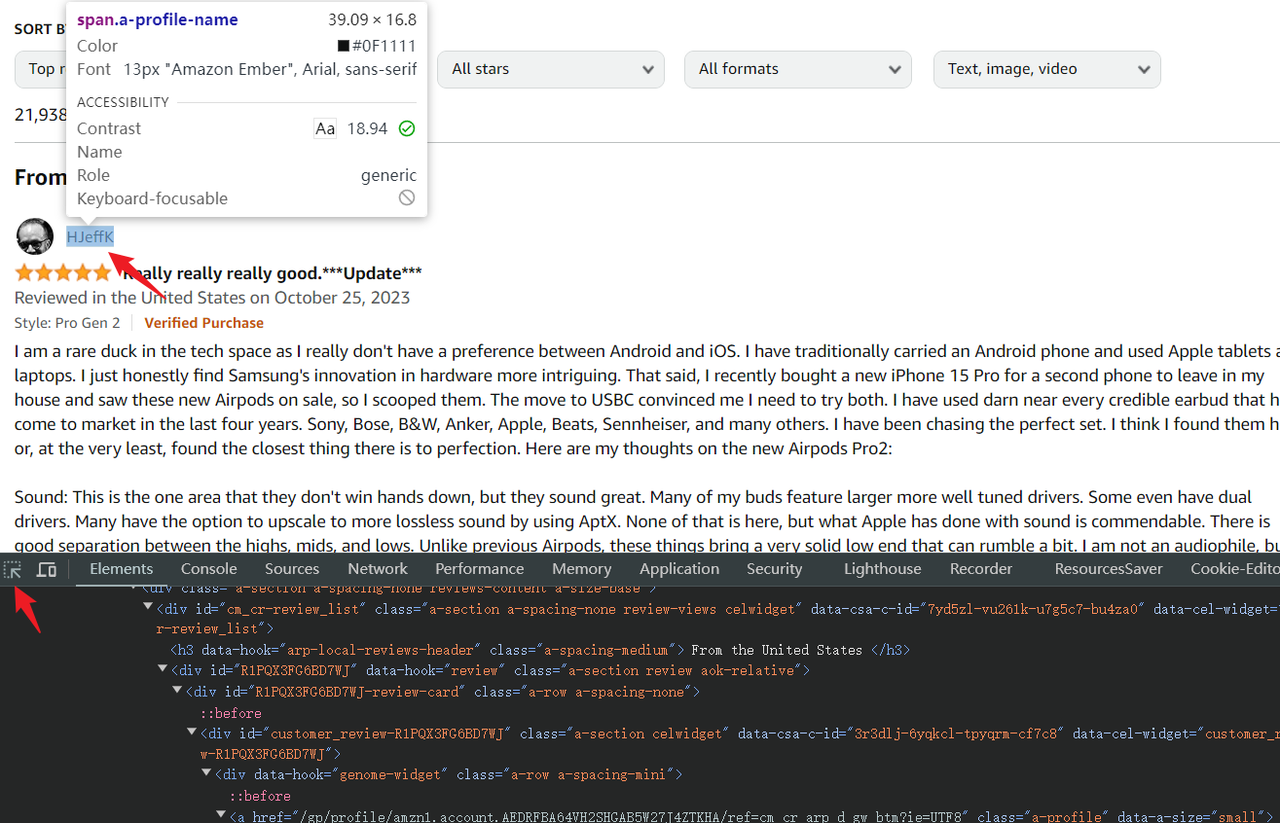
- Выберите инструмент выбора элементов в верхнем левом углу консоли.
- Наведите курсор на элемент, который вы хотите скрейпить, и соответствующий HTML-код будет подсвечен в консоли.
Playwright поддерживает различные методы выбора элементов, но использование простых CSS-селекторов обычно является самым простым способом для новичков. Примером CSS-селектора является .devsite-search-field, который использовался ранее.
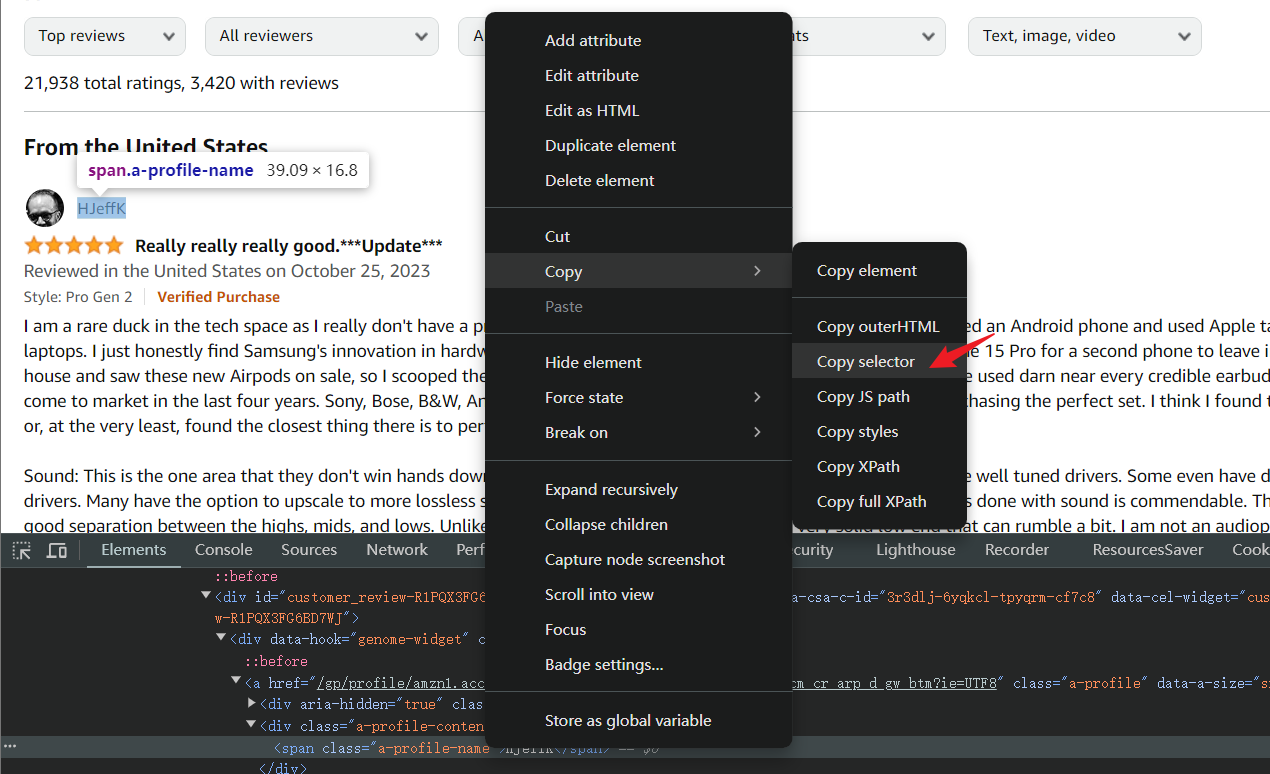
Для сложных CSS-структур консоль отладки может напрямую скопировать CSS-селектор. Щелкните правой кнопкой мыши на HTML-элементе, который вы хотите скопировать, и выберите Открыть меню > Копировать > Копировать селектор.
Теперь, когда селектор определен, мы можем использовать Playwright, чтобы попытаться получить имя пользователя, которое я выбрал выше.
JavaScript
import { chromium } from 'playwright'; // Вы также можете использовать 'firefox' или 'webkit'
// Запустите новый экземпляр браузера
const browser = await chromium.launch();
// Создайте новую страницу
const page = await browser.newPage();
// Перейдите по указанному URL
await page.goto('https://www.amazon.com/Apple-Generation-Cancelling-Transparency-Personalized/product-reviews/B0CHWRXH8B/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews');
// Подождите загрузки узла, не более 10 секунд
await page.waitForSelector('div[data-hook="genome-widget"] .a-profile-name', { timeout: 10000 });
// Извлеките имя пользователя
const username = await page.$eval('div[data-hook="genome-widget"] .a-profile-name', node => node.textContent);
console.log('[Имя пользователя]===>', username);
// Закройте браузер
await browser.close();Вы можете настроить код, чтобы извлечь не только одно имя пользователя, но и полный список отзывов:
- Используйте
page.waitForSelectorдля ожидания полной загрузки элементов отзывов. - Используйте
page.$$для выбора всех элементов, соответствующих заданному селектору.
Затем пройдитесь по списку элементов отзывов и извлеките необходимую информацию из каждого элемента. Предоставленный код захватит заголовок, рейтинг, имя пользователя, текст и атрибут data-src для аватарки (включая URL аватарки).
Как показано, код:
page.gotoиспользуется для навигации на нужную страницу.waitForSelectorиспользуется для ожидания правильного отображения целевого узла.page.$evalиспользуется для получения первого соответствующего элемента и извлечения конкретного атрибута с помощью функции обратного вызова.
JavaScript
await page.waitForSelector('div[data-hook="review"]');
const reviewList = await page.$$('div[data-hook="review"]');Следующим шагом будет перебор списка элементов отзывов и извлечение нужной информации из каждого элемента.
В следующем коде мы получаем заголовок, рейтинг, имя пользователя и текст отзыва, а также значение атрибута data-src элемента аватара, которое является URL адресом аватара.
JavaScript
for (const review of reviewList) {
const title = await review.$eval(
'a[data-hook="review-title"] > span:nth-of-type(2)',
node => node.textContent,
);
const rate = await review.$eval(
'i[data-hook="review-star-rating"] .a-icon-alt',
node => node.textContent,
);
const username = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-name',
node => node.textContent,
);
const avatar = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-avatar img',
node => node.getAttribute('data-src'),
);
const content = await review.$eval(
'span[data-hook="review-body"] span',
node => node.textContent,
);
console.log('[log]===>', { title, rate, username, avatar, content });
}Шаг 4: Экспорт данных
После выполнения вышеуказанного кода вы должны увидеть вывод информации в терминале.
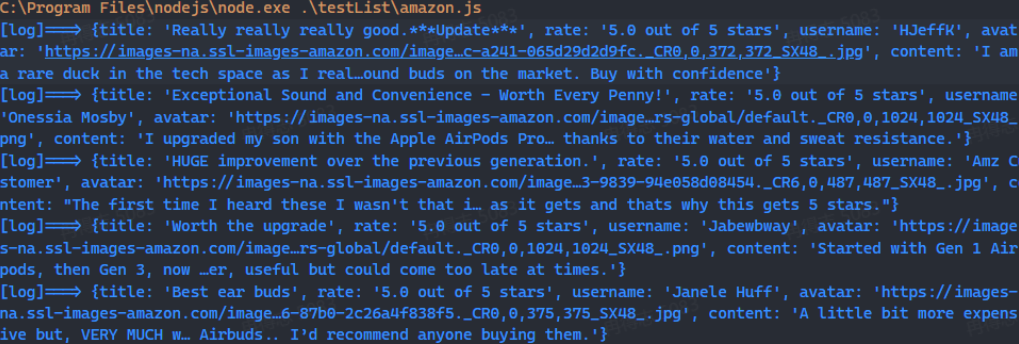
Если вы хотите сохранить эти данные для последующего анализа, вы можете использовать стандартный модуль Node.js fs для записи данных в файл JSON. Вот простой вспомогательный метод:
JavaScript
import fs from 'fs';
// Сохранение в JSON файл
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2);
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`Файл сохранен: ${filename}`);
});
}Полный код выглядит следующим образом. После выполнения вы можете найти файл amazon_reviews_log.json в текущем каталоге выполнения скрипта, который содержит все собранные результаты!
JavaScript
import { chromium } from 'playwright';
import fs from 'fs';
// Запуск браузера
const browser = await chromium.launch();
const page = await browser.newPage();
// Открытие страницы
await page.goto(
`https://www.amazon.com/Apple-Generation-Cancelling-Transparency-Personalized/product-reviews/B0CHWRXH8B/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews`
);
// Ожидание загрузки элементов отзывов
await page.waitForSelector('div[data-hook="review"]');
// Получение всех элементов отзывов
const reviewList = await page.$$('div[data-hook="review"]');
const reviewLog = [];
// Перебор списка отзывов
for (const review of reviewList) {
const title = await review.$eval(
'a[data-hook="review-title"] > span:nth-of-type(2)',
node => node.textContent.trim()
);
const rate = await review.$eval(
'i[data-hook="review-star-rating"] .a-icon-alt',
node => node.textContent.trim()
);
const username = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-name',
node => node.textContent.trim()
);
const avatar = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-avatar img',
node => node.getAttribute('data-src')
);
const content = await review.$eval(
'span[data-hook="review-body"] span',
node => node.textContent.trim()
);
console.log('[log]===>', { title, rate, username, avatar, content });
reviewLog.push({ title, rate, username, avatar, content });
}
// Сохранение в JSON файл
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2);
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`Файл сохранен: ${filename}`);
});
}
saveObjectToJson(reviewLog, 'amazon_reviews_log.json');
await browser.close();Использование Playwright для других веб-операций
Нажатие кнопки
Используйте page.click для нажатия на кнопку, установите задержку, чтобы сделать действие более похожим на человеческое. Вот простой пример.
JavaScript
import { chromium } from 'playwright'
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://example.com/'); // Открытие указанного URL
await page.waitForTimeout(3000)
await page.click('p > a', { delay: 200 })Прокрутка страницы
В page.evaluate можно использовать API Window для установки положения полосы прокрутки. page.evaluate — это очень полезный API:
JavaScript
import { chromium } from 'playwright'
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://www.nstbrowser.io/'); // Открытие указанного URL
// Прокрутка до конца страницы
await page.evaluate(() => {
window.scrollTo(0, document.documentElement.scrollHeight);
});Получение списка элементов
Чтобы получить несколько элементов, можно использовать page.$$eval, который получает все элементы, соответствующие заданному селектору, а затем в функции обратного вызова перебирает эти элементы для получения конкретных атрибутов.
JavaScript
import { chromium } from 'playwright'
// Запуск браузера
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');
await page.waitForSelector('.titleline > a')
// Получение заголовков статей
const titles = await page.$$eval('.titleline > a', elements =>
elements.map(el => el.innerText)
);
// Вывод захваченных заголовков
console.log('Заголовки статей:');
titles.forEach((title, index) => console.log(`${index + 1}: ${title}`));Перехват HTTP-запросов
Метод page.route используется для перехвата запросов на странице. '**/*' — это универсальный символ, обозначающий все запросы. Затем в функции обратного вызова можно обработать все запросы. Параметр route используется для определения, должен ли запрос выполниться нормально или быть прерванным, а также может быть использован для переписывания ответа.
JavaScript
import { chromium } from 'playwright'
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
await page.route('**/*', (route) => {
const request = route.request();
// Перехват и блокировка запросов шрифтов
if (request.url().includes('https://fonts.gstatic.com/')) {
route.fulfill({
status: 404,
contentType: 'image/x-icon',
body: ''
});
console.log('Запрос иконки заблокирован');
// Перехват и блокировка запросов стилей
} else if (request.resourceType() === 'stylesheet') {
route.abort();
console.log('Запрос стилей заблокирован');
// Перехват и блокировка запросов изображений
} else if (request.resourceType() === 'image') {
route.abort();
console.log('Запрос изображения заблокирован');
// Разрешение остальных запросов
} else {
route.continue();
}
});
await page.goto('https://www.youtube.com/');Снимки экрана
Playwright предоставляет готовый к использованию API для создания снимков экрана, что является очень полезной функцией. Вы можете управлять качеством снимка с помощью параметра quality и обрезать изображение с помощью параметра clip. Если у вас есть требования к пропорциям снимков, вы можете настроить viewport для их реализации.
JavaScript
import { chromium } from 'playwright';
const browser = await chromium.launch({ viewport: { width: 1920, height: 1080 } });
const page = await browser.newPage();
await page.goto('https://www.youtube.com/');
// Снимок всего экрана
await page.screenshot({ path: 'screenshot1.png' });
// Снимок в формате JPEG с качеством 50
await page.screenshot({ path: 'screenshot2.jpeg', quality: 50 });
// Обрезка изображения, указав область обрезки
await page.screenshot({ path: 'screenshot3.jpeg', clip: { x: 0, y: 0, width: 150, height: 150 } });
console.log('Снимки экрана сохранены');
await browser.close();Nstbrowser также может выполнять все эти функции!
Конечно, вы можете использовать различные инструменты для выполнения этих задач. Например, RPA от Nstbrowser может ускорить процесс веб-скрейпинга!
Шаг 1. Перейдите на главную страницу Nstbrowser, а затем перейдите в раздел RPA/Workflow > Создать рабочий процесс.
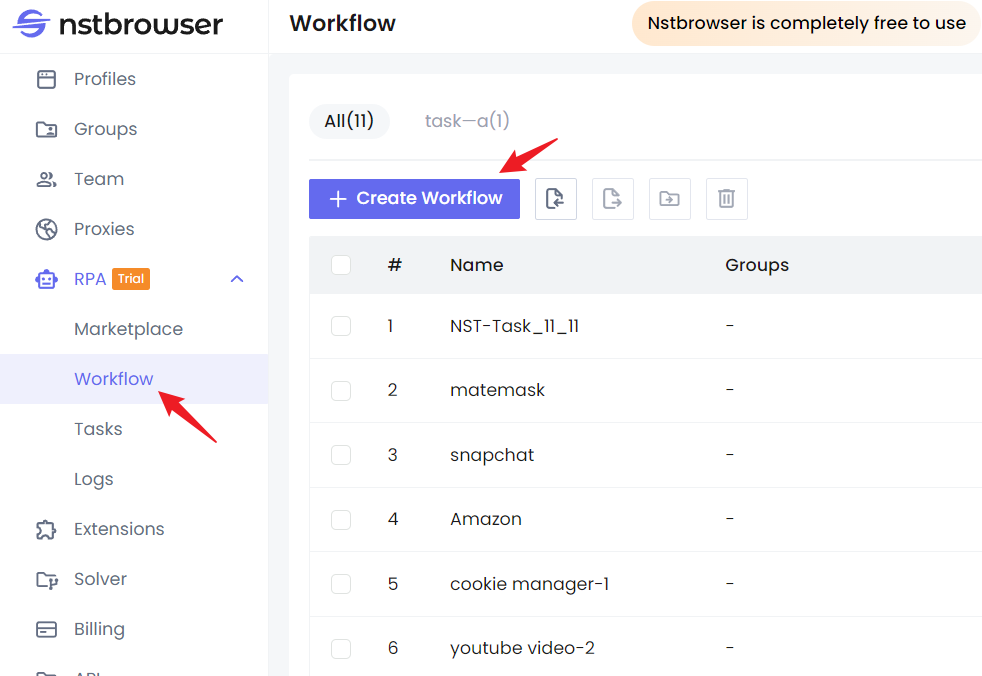
Шаг 2. Как только вы попадете на страницу редактирования рабочего процесса, вы сможете легко воспроизвести вышеописанные функции, просто перетаскивая элементы.
Слева Nodes охватывает почти все потребности веб-скрейпинга и автоматизации, и они тесно интегрированы с API Playwright.
Вы можете настроить порядок выполнения этих узлов, связывая их, подобно тому, как вы выполняете асинхронный код на JavaScript. Если вы знакомы с Playwright, вы обнаружите, что начать использование функций RPA от Nstbrowser очень просто — все интуитивно понятно.
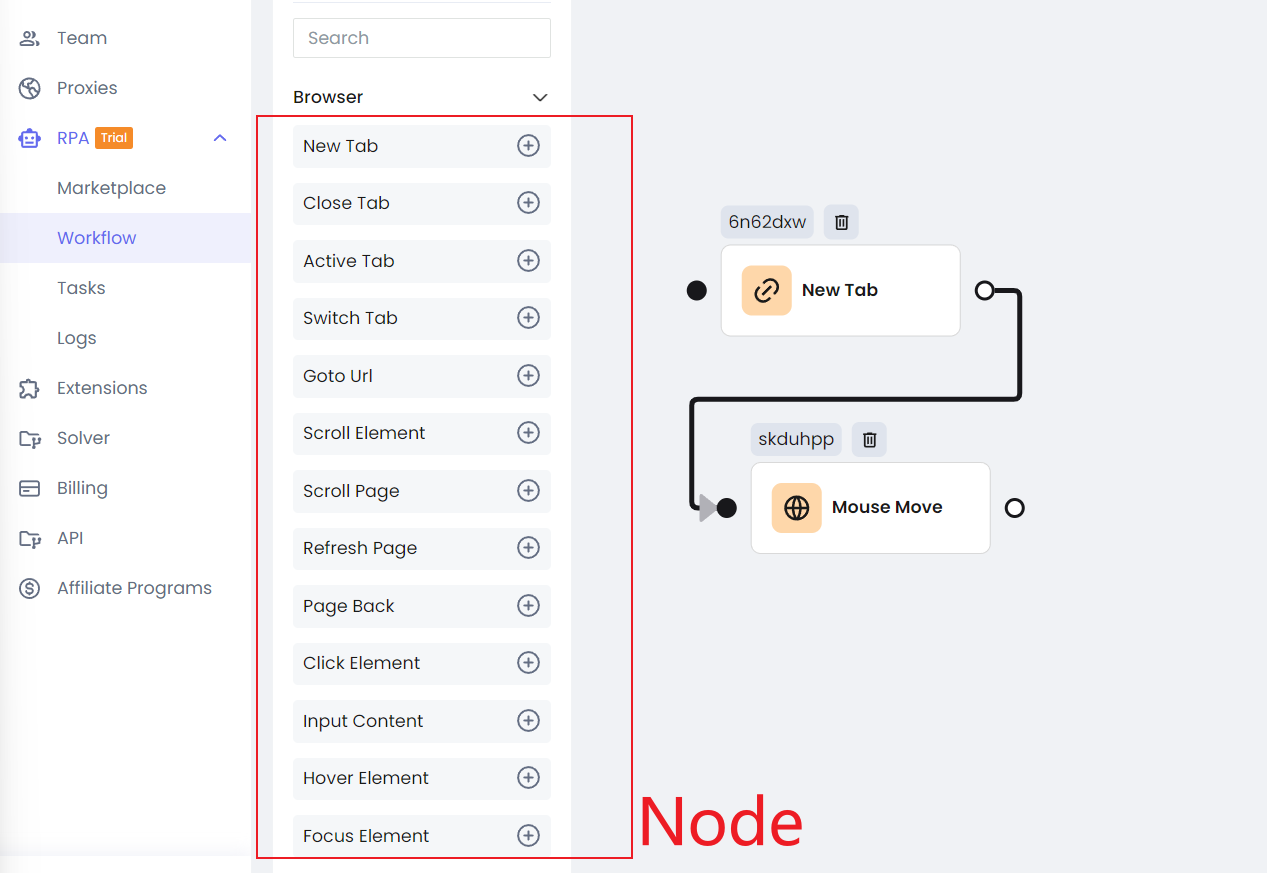
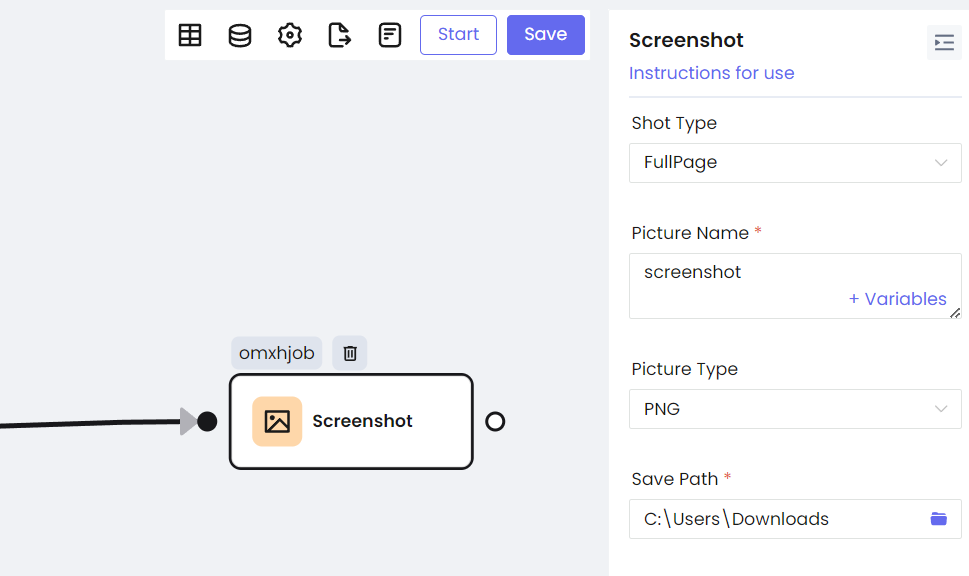
Шаг 3. Каждый Node можно настроить отдельно, настройки схожи с теми, что используются в Playwright.
- Нажатие кнопки
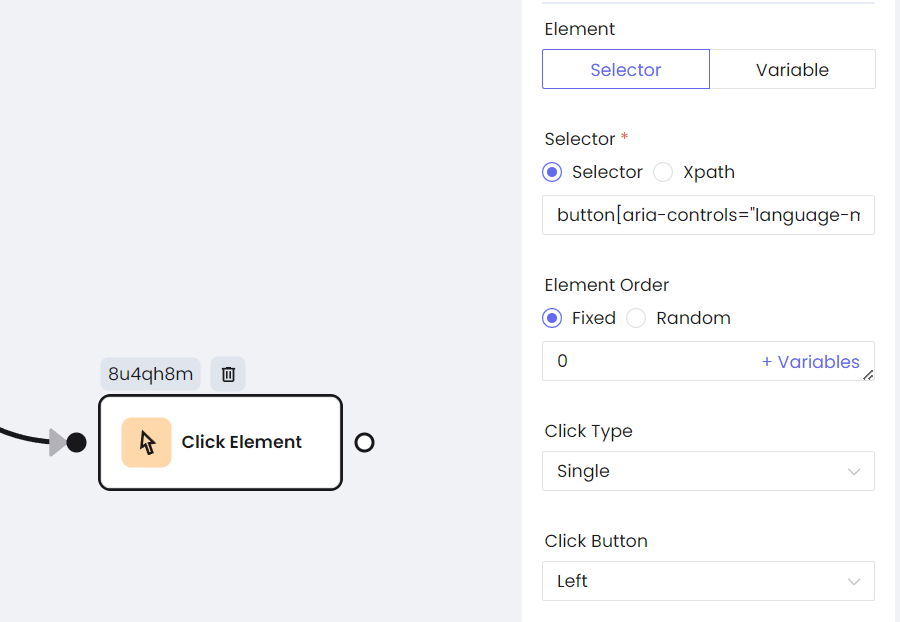
- Прокрутка страницы
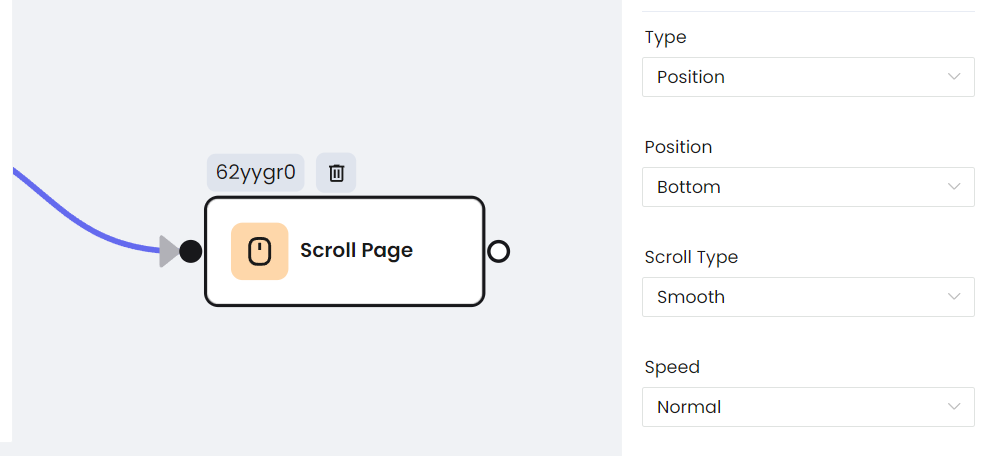
- Получение списка элементов
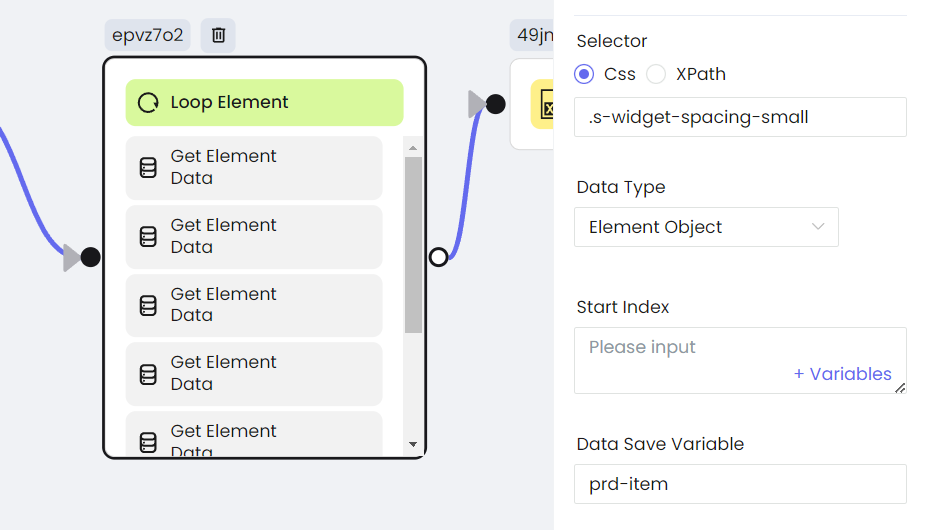
- Перехват HTTP запросов
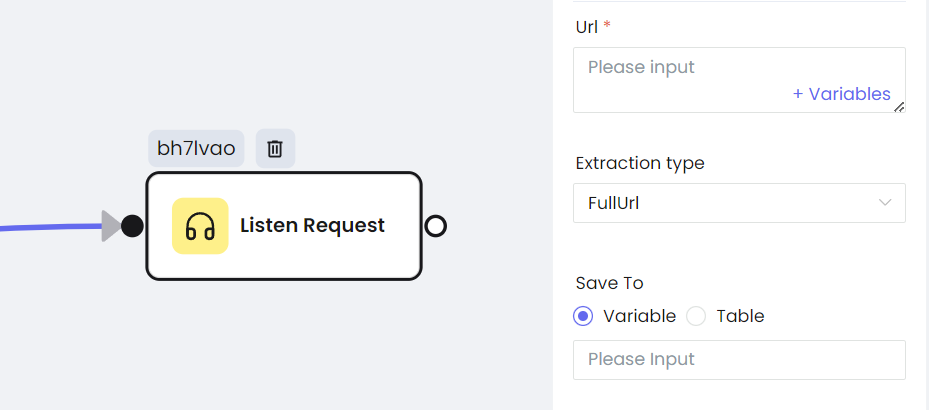
- Снимки экрана
Playwright vs. Puppeteer vs. Selenium
| Стандарт | Playwright | Puppeteer | Selenium |
|---|---|---|---|
| Поддержка браузеров | Chromium, Firefox и WebKit | Браузеры на базе Chromium | Chrome, Firefox, Safari, Internet Explorer и Edge |
| Поддержка языков | TypeScript, JavaScript, Python, .NET и Java | Node.js | Java, Python, C#, JavaScript, Ruby, Perl, PHP, TypeScript |
| Операционные системы | Windows, macOS, Linux | Windows и OS X | Windows, macOS, Linux, Solaris |
| Сообщество и экосистема | Растущее сообщество, мощная поддержка Microsoft и постоянная разработка | Сильное сообщество, поддерживаемое Google, особенно для пользователей Chromium | Долгое существование, большое активное сообщество и обширная экосистема, включая плагины и интеграции |
| Поддержка CI/CD | Да | Да | Да |
| Поддержка записи и воспроизведения | В панели Sources в Chrome DevTools | Playwright CodeGen | Selenium IDE |
| Различия в веб-скрейпинге | Современные функции и скорость, подходит для скрейпинга в разных браузерах | Отличные результаты в Chrome, высокая скорость | Многофункциональный инструмент для веб-скрейпинга, но может быть медленным |
| Безголовый режим | Поддержка безголового режима во всех поддерживаемых браузерах | Поддержка безголового режима, но только для браузеров на базе Chromium | Поддержка безголового режима, но реализация зависит от драйвера браузера |
| Снимки экрана | PDF и захват изображений, особенно в Chromium | PDF и захват изображений, легко в использовании | Не поддерживает встроенный захват PDF |
Заключение
Playwright — это действительно мощный инструмент!
Он предлагает мощный и многофункциональный набор инструментов для веб-скрейпинга. Кроме того, отличная документация и растущее сообщество Playwright делают автоматизацию задач намного удобнее.
В этом блоге вы узнали больше о Playwright:
- Преимущества веб-скрейпинга с Playwright.
- Эффективное использование NodeJS в Playwright.
- Выполнение других операций с помощью Playwright.
Browserless от Nstbrowser в Docker обладает потрясающими возможностями. Хотите освободить место на диске и избавиться от ограничений локального оборудования? Используйте полностью управляемый облачный сервис от Nstbrowser прямо сейчас!
Больше





