
Browserless
Как парсить данные о товарах Amazon с помощью Puppeteer и Browserless?
Скрапинг Amazon позволит в значительной степени избежать трудоемких и ресурсозатратных проблем. Прочитайте этот учебник и найдите эффективный способ скрапинга Amazon.
Nov 08, 2024Luke Ulyanov
Вы всегда можете найти всю необходимую и ценную информацию о товарах, продавцах, отзывах, рейтингах, спецпредложениях, новостях и т. д. на Amazon. Будь то продавец, проводящий рыночный анализ, или частное лицо, собирающее данные, использование высококачественного, удобного и быстрого инструмента поможет вам максимально точно собирать различную информацию с Amazon.
Почему так важно парсить данные о товарах на Amazon?
Amazon собирает ценную информацию в одном месте: товары, отзывы, рейтинги, эксклюзивные предложения, новости и т. д. Поэтому парсинг данных на Amazon в значительной степени позволит избежать трудоемких и затратных по времени проблем. Как бизнес, использование Amazon product scraper может принести вам как минимум следующие 4 значительных преимущества:
- Понять цены на местном или даже глобальном рынке и сравнить цены
- Проанализировать различия с конкурентами
- Определить целевые группы
- Улучшить изображение продукта
- Предсказать потребности пользователей
- Собирать информацию о клиентах
Типичные причины для парсинга товаров на Amazon
- Мониторинг цен и товаров конкурентов
- Понимание рыночных тенденций
- Оптимизация маркетинговых стратегий
- Улучшение товарных карточек
- Оптимизация цен
- Улучшение исследований товаров
- Отслеживание настроений клиентов
Помогает ли Browserless в создании Amazon Product Scraper?
Бесголовые браузеры отлично справляются с автоматизированной работой? Верно, мы будем использовать самый мощный сервис бесголовых браузеров от Nstbrowser: Browserless для сбора информации о товарах на Amazon.
При сборе данных о товарах на Amazon мы всегда сталкиваемся с рядом серьезных проблем, таких как обнаружение ботов, распознавание проверочных кодов и блокировка IP. Использование Browserless позволяет полностью избежать этих головных болей!
Browserless от Nstbrowser предоставляет реальные отпечатки браузеров пользователей, причем каждый отпечаток уникален. Кроме того, участие в нашем абонентском плане позволяет полностью обойти CAPTCHA, обеспечивая беспрепятственный доступ. Присоединяйтесь к нашей Discord программе рефералов, чтобы получить $1,500 наличными уже сейчас!
Как мы можем парсить данные о товарах на Amazon?
Не откладывая, давайте начнем официально использовать Browserless для сбора данных!
Предварительные условия
Прежде чем начать, нам нужно подключиться к сервису Browserless. Использование Browserless позволяет решать сложные задачи веб-скрапинга и автоматизации в большом масштабе, и вы можете по-настоящему насладиться полностью управляемым облачным развертыванием.
Browserless использует браузерно-ориентированный подход, обеспечивает мощные возможности бесголового развертывания и обеспечивает более высокую производительность и надежность. Дополнительную информацию о Browserless вы можете найти в нашей соответствующей документации.
Получите API KEY и перейдите на страницу меню Browserless в клиенте Nstbrowser или вы можете нажать здесь, чтобы получить к ней доступ напрямую.
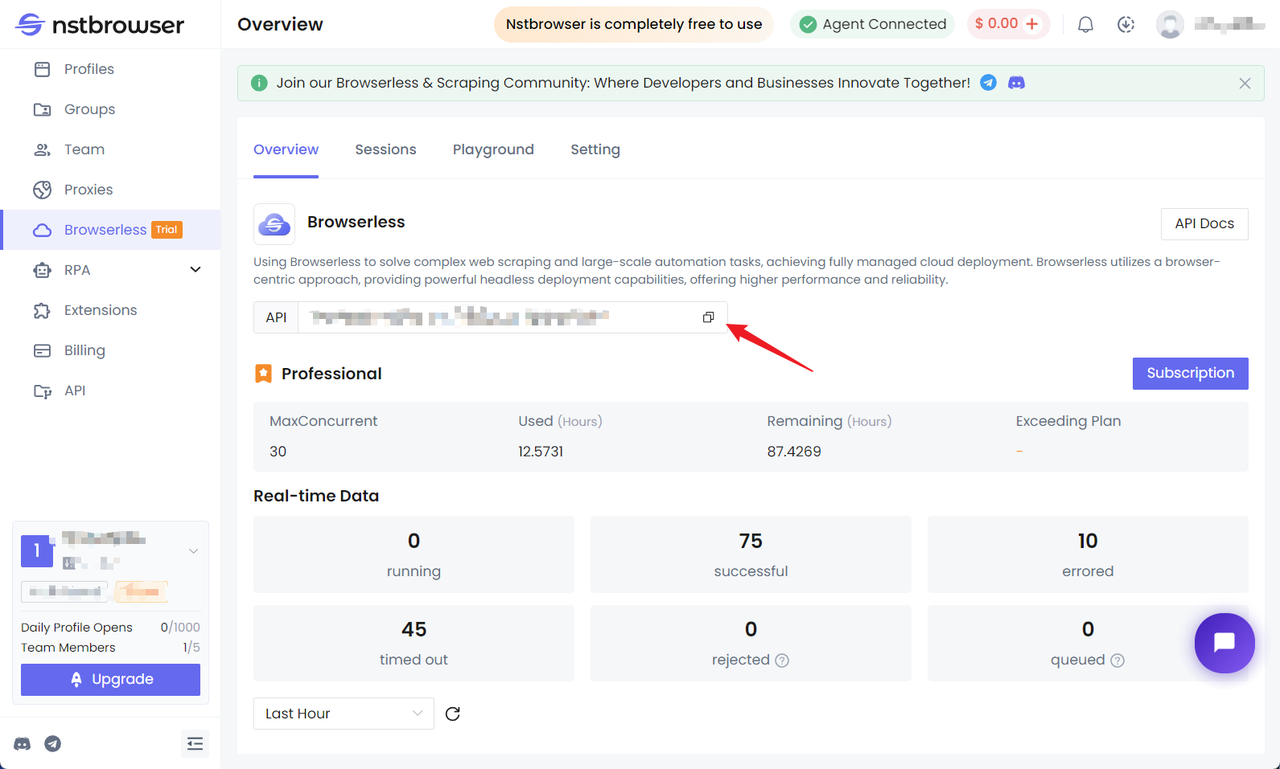
Установите Puppeteer и подключитесь к Browserless
- Установите Puppeteer. Более легкий puppeteer-core - лучший выбор.
Bash
# pnpm
pnpm i puppeteer-core
# yarn
yarn add puppeteer-core
# npm
npm i --save puppeteer-core- Мы подготовили код для вызова Browserless. Вам нужно только указать apiKey и прокси, чтобы начать последующие операции Amazon product scraper:
JavaScript
const apiKey = "your ApiKey"; // required
const config = {
proxy: 'your proxy', // required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
// platform: 'windows', // support: windows, mac, linux
// kernel: 'chromium', // only support: chromium
// kernelMilestone: '128', // support: 128
// args: {
// "--proxy-bypass-list": "detect.nstbrowser.io"
// }, // browser args
// fingerprint: {
// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent supportted since v0.15.0
// },
};
const query = new URLSearchParams({
token: apiKey, // required
config: JSON.stringify(config),
});
const browserlessWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;Начните скрапинг
Шаг 1: Проверка целевой страницы
Перед скрапингом мы можем попробовать перейти на https://www.amazon.com/. Если это первый визит, велика вероятность появления проверочного кода:
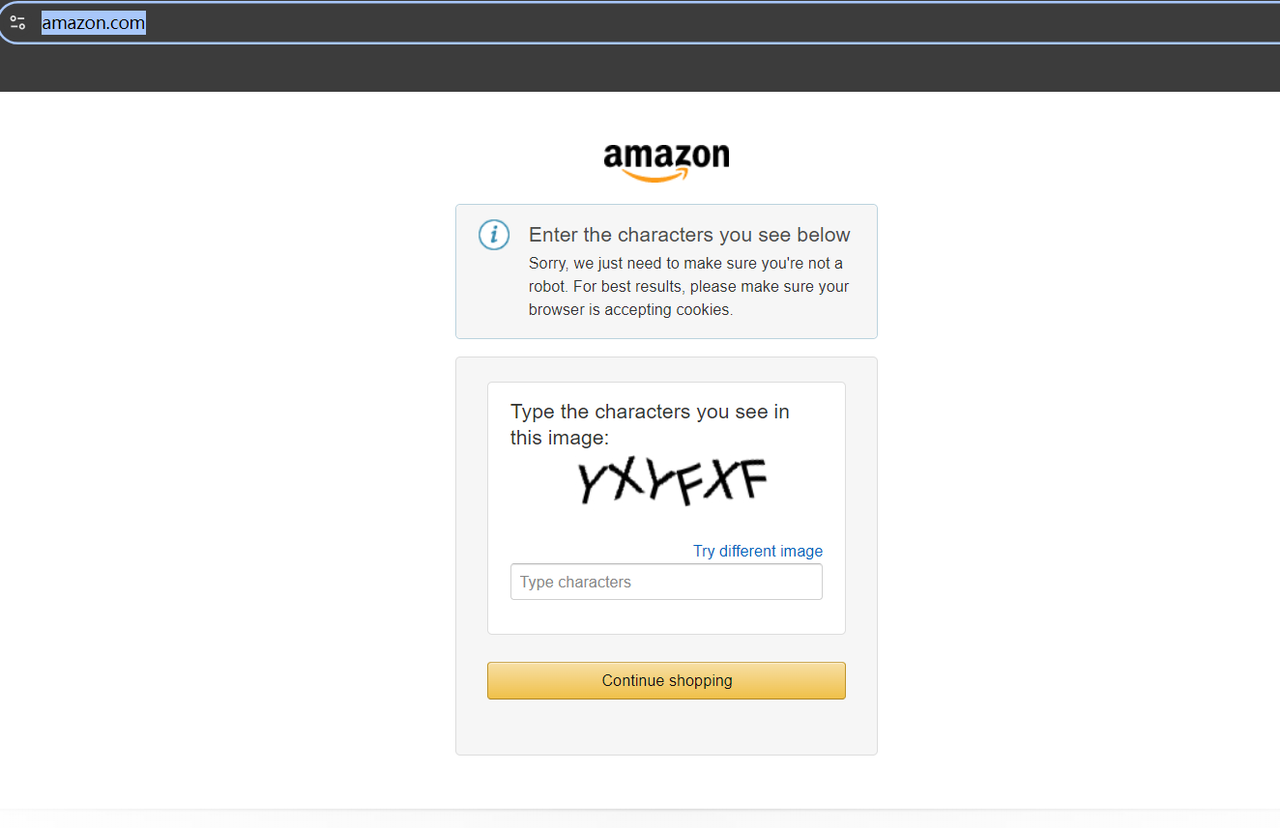
Но это не имеет значения, нам не нужно прилагать больших усилий, чтобы найти инструмент для декодирования проверочных кодов. В этом случае вам нужно только посетить домен Amazon в вашем регионе или в регионе вашего прокси, и проверочный код не будет активирован.
Например, давайте посетим: https://www.amazon.co.uk/: домен Amazon в Великобритании. Мы видим, что страница открывается без проблем, затем попробуйте ввести нужное ключевое слово продукта в верхней строке поиска или перейдите по ссылке напрямую, например:
Bash
https://www.amazon.co.uk/s?k=shirtЗначение после /s?k= в URL - это ключевое слово продукта. Перейдя по этой ссылке, вы увидите товары, связанные с рубашками на Amazon. Теперь вы можете открыть "Инструменты разработчика" (F12), чтобы проверить HTML-структуру страницы и подтвердить данные, которые нам нужно будет парсить в дальнейшем, позиционируя курсор.
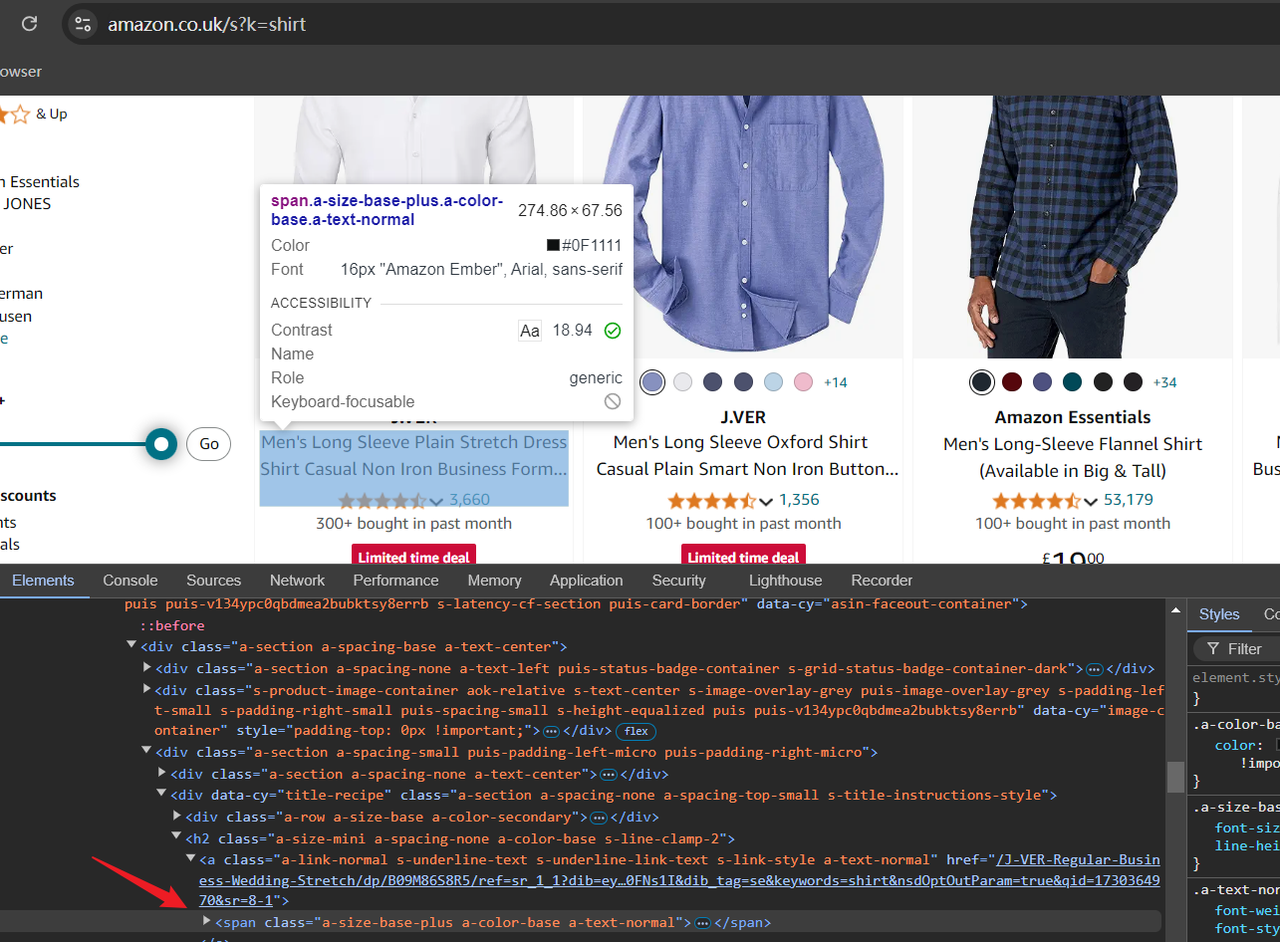
Шаг 2: Написание скрипта
Сначала я добавил строку кода в начале скрипта. В следующем коде используется первый параметр скрипта в качестве ключевого слова товара на Amazon, и последующие скрипты также будут использовать этот параметр для сбора данных:
JavaScript
const productName = process.argv.slice(2);
if (productName.length !== 1) {
console.error('product name CLI arguments missing!');
process.exit(2);
}Далее нам нужно:
- Импортировать Puppeteer и подключиться к Browserless
- Перейти на страницу с результатами поиска товаров на Amazon
- Добавить скриншот, чтобы проверить, был ли доступ успешным
JavaScript
import puppeteer from "puppeteer-core";
const browser = await puppeteer.connect({
browserWSEndpoint: browserlessWSEndpoint,
defaultViewport: null,
})
console.info('Connected!');
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// Добавление скриншотов для облегчения последующей отладки
await page.screenshot({ path: 'amazon_page.png' })Теперь мы используем page.$$, чтобы получить список всех товаров, перебрать список товаров и по одному получить нужные данные в цикле. Затем мы соберем эти данные в массив productDataList и распечатаем его:
JavaScript
// Получение контейнера всех элементов результатов поиска
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// Получение различной информации о товаре: название, рейтинг, ссылка на изображение, цена
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
return null;
}
}
const title = await safeEval('.s-title-instructions-style > h2 > a > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
console.log('amazon_product_data_list :', productDataList);
await browser.close();Запуск скрипта:
Bash
node amazon.mjs shirtВ случае успеха на консоль будет выведено следующее:

Шаг 3: Вывод собранных данных в виде JSON-файла
Очевидно, что для более качественного анализа данных недостаточно просто распечатать их на консоль. Вот простой пример: быстро преобразуйте объект JS в JSON-файл с помощью fs модуля:
JavaScript
import fs from 'fs'
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')Хорошо, давайте посмотрим на наш полный код:
JavaScript
import puppeteer from "puppeteer-core";
import fs from 'fs'
const productName = process.argv.slice(2);
if (productName.length !== 1) {
console.error('product name CLI arguments missing!');
process.exit(2);
}
const apiKey = "your ApiKey"; // 'your proxy'
const config = {
proxy: 'your proxy', // required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
// platform: 'windows', // support: windows, mac, linux
// kernel: 'chromium', // only support: chromium
// kernelMilestone: '128', // support: 128
// args: {
// "--proxy-bypass-list": "detect.nstbrowser.io"
// }, // browser args
// fingerprint: {
// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent supportted since v0.15.0
// },
};
const query = new URLSearchParams({
token: apiKey, // required
config: JSON.stringify(config),
});
const browserlessWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;
const browser = await puppeteer.connect({
browserWSEndpoint: browserlessWSEndpoint,
defaultViewport: null,
})
console.info('Connected!');
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// Добавление скриншотов для облегчения последующей отладки
await page.screenshot({ path: 'amazon_page.png' })
// Получение контейнера всех элементов результатов поиска
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// Получение различной информации о товаре: название, рейтинг, ссылка на изображение, цена
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
console.log(`Error fetching ${selector}:`, e);
return null;
}
}
const title = await safeEval('.s-title-instructions-style > h2 > a > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')
console.log('amazon_product_data_list :', productDataList);
await browser.close();Теперь, после запуска скрипта, вы можете не только увидеть печать на консоли, но и файл amazon_product_data.json, который был записан в текущей папке.
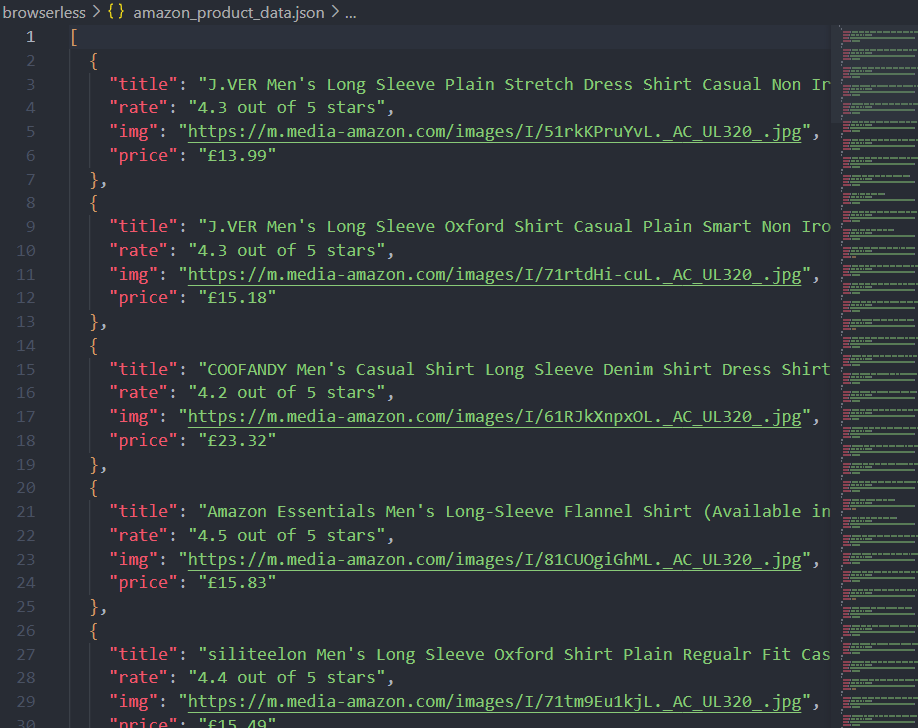
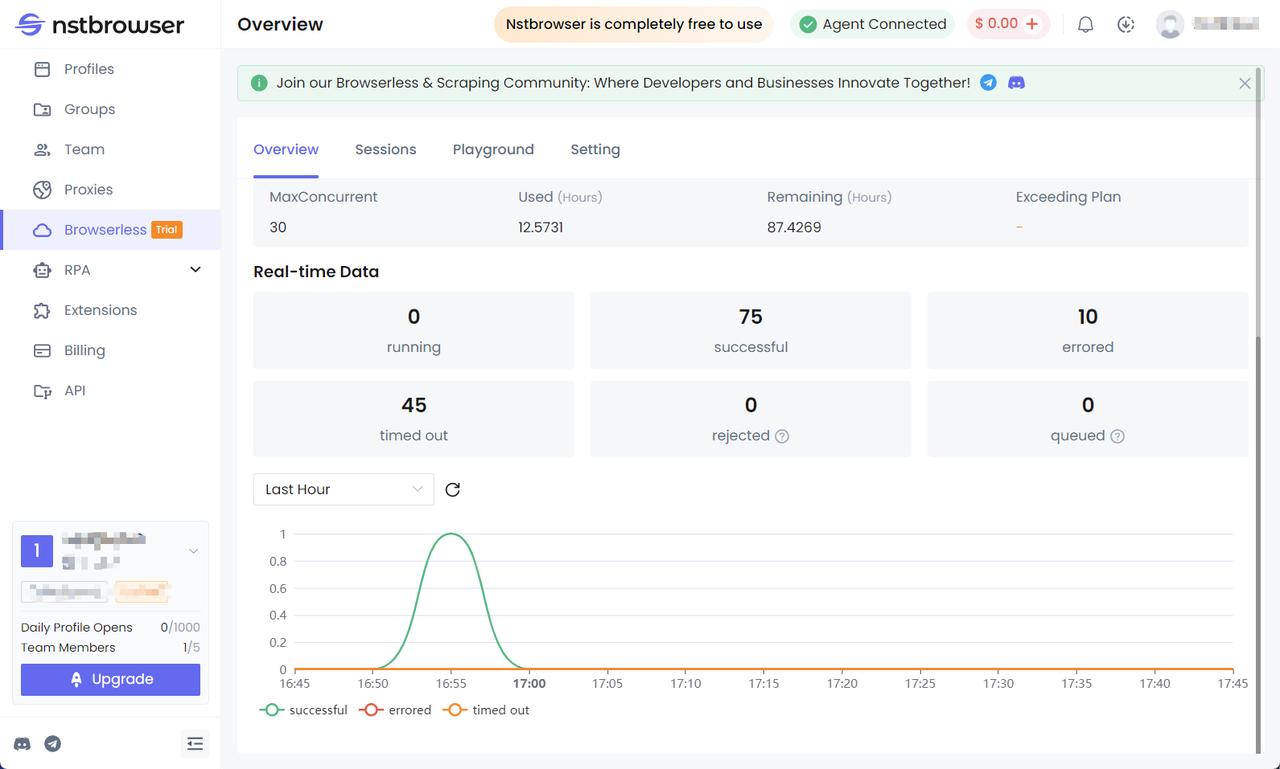
Проверьте панель управления Browserless
Вы можете просмотреть статистику последних запросов и оставшегося времени сеанса в меню Browserless клиента Nstbrowser.
Nstbrowser RPA: более простой способ создать свой Amazon Scraper
Использование инструментов RPA для сбора веб-данных является распространенным методом сбора данных. Использование инструментов RPA может значительно повысить эффективность сбора данных и снизить стоимость сбора. Функция Nstbrowser RPA может обеспечить вам лучший опыт RPA и максимальную эффективность работы.
Прочитав этот учебник, вы:
- Узнаете, как использовать RPA для сбора данных
- Узнаете, как сохранять данные, собранные с помощью RPA
Подготовка
Сначала у вас должна быть учетная запись Nstbrowser, а затем войдите в клиент Nstbrowser, перейдите на страницу рабочего процесса модуля RPA и нажмите "Новый рабочий процесс".
Теперь мы можем начать настройку рабочего процесса сбора RPA на основе результатов поиска товаров на Amazon.
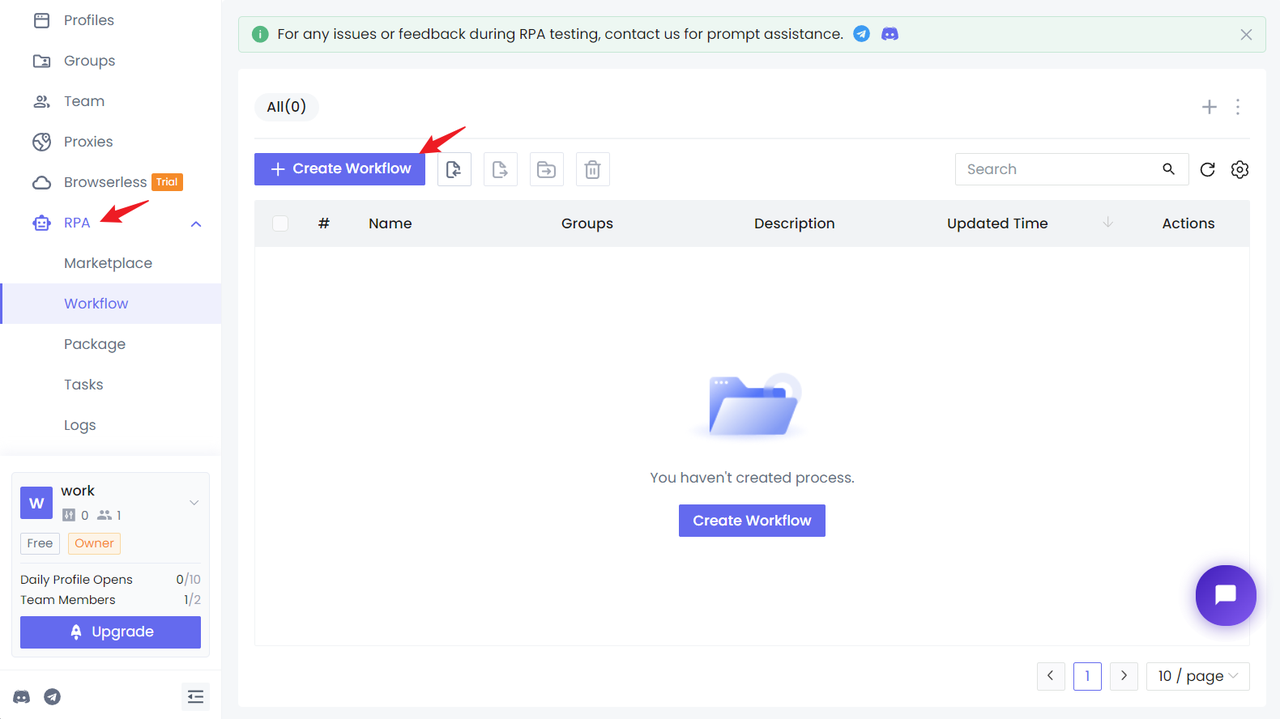
Шаг 1. Переход на целевой сайт
- Нам нужно посетить наш целевой сайт: https://www.amazon.co.uk;
- Вы также можете использовать основной сайт Amazon напрямую: https://www.amazon.com/, но при первом посещении вам нужно будет вручную обработать проверочный код;
- Используйте узел
Переход по ссылке, настройте URL-адрес сайта, и вы сможете посетить целевой сайт:
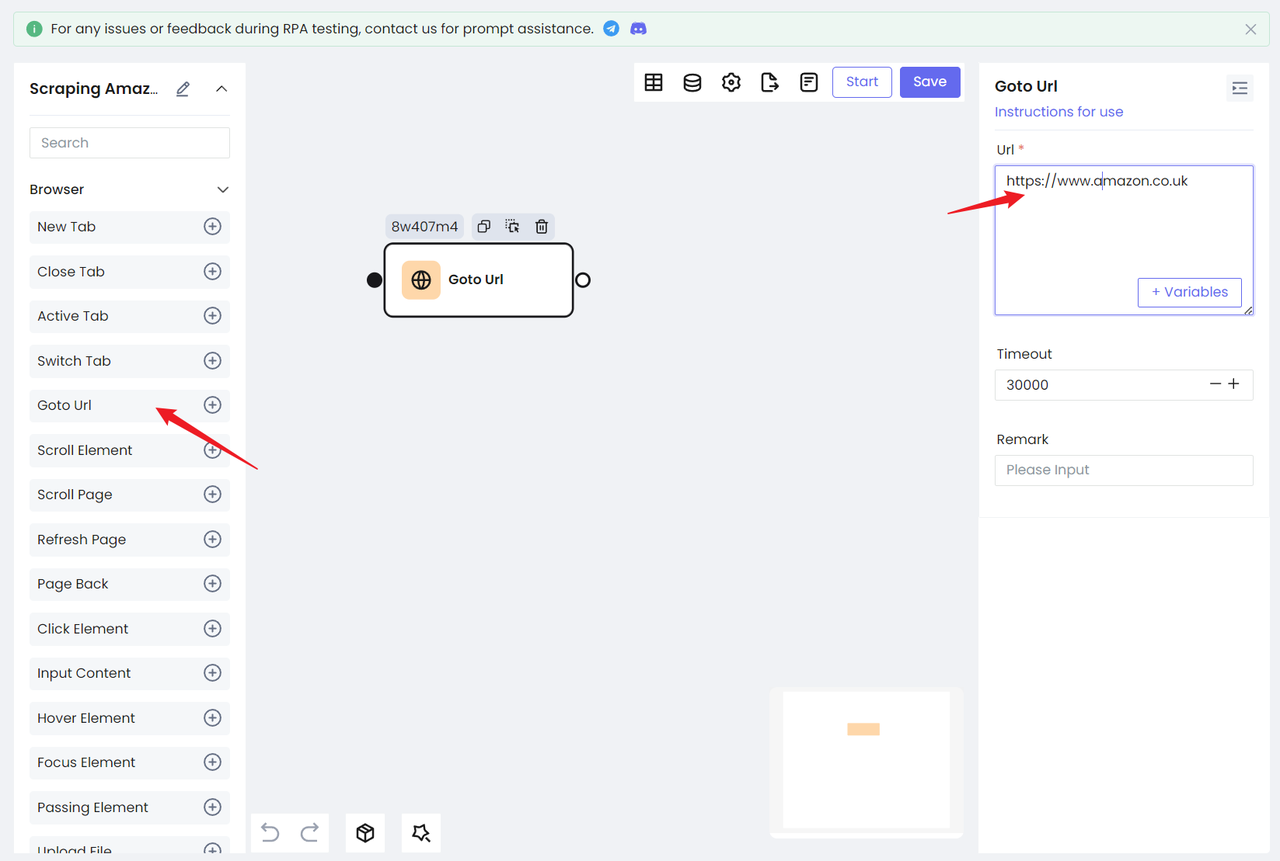
Шаг 2. Поиск целевого контента
На этот раз мы не будем использовать метод запроса соответствующего продукта по URL, а используем RPA, чтобы помочь ввести текст в поле ввода на домашней странице, а затем запустить переход к поиску. Это не только сделает нас более знакомыми с работой RPA, но и позволит в значительной степени избежать контроля сайта на предмет рисков.
Хорошо, после перехода на целевой сайт нам нужно сначала найти целевой адрес. Здесь нам нужно использовать инструмент Chrome Devtool, чтобы найти HTML-элемент.
- Откройте инструмент Devtool и выберите поле поиска с помощью мыши. Мы видим:
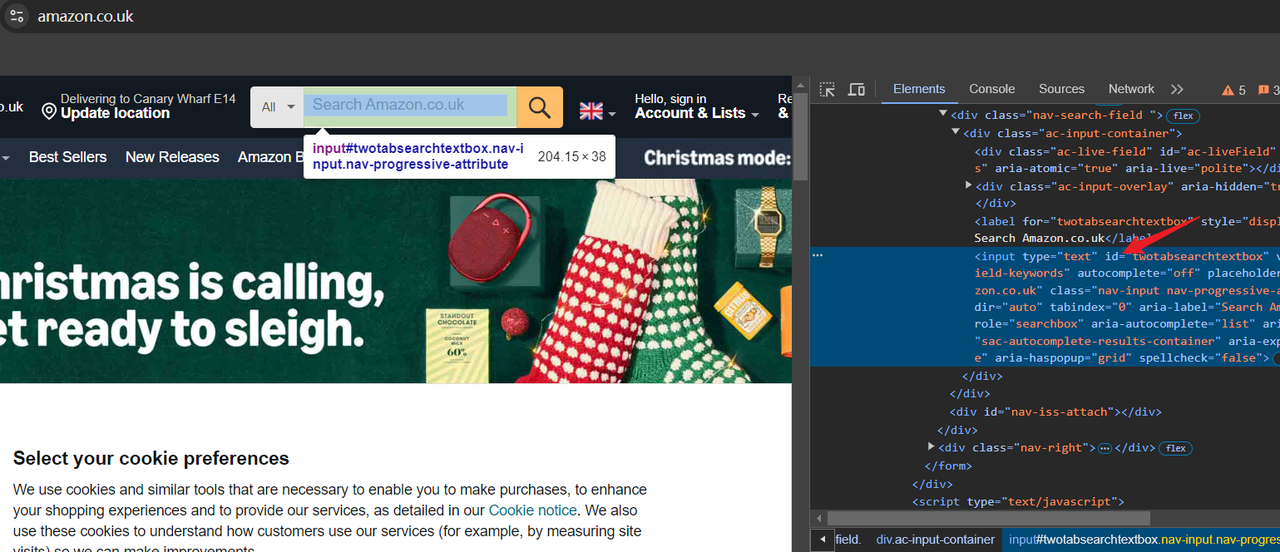
- Наше целевое поле ввода имеет атрибут id, который можно использовать как CSS-селектор для поиска поля ввода.
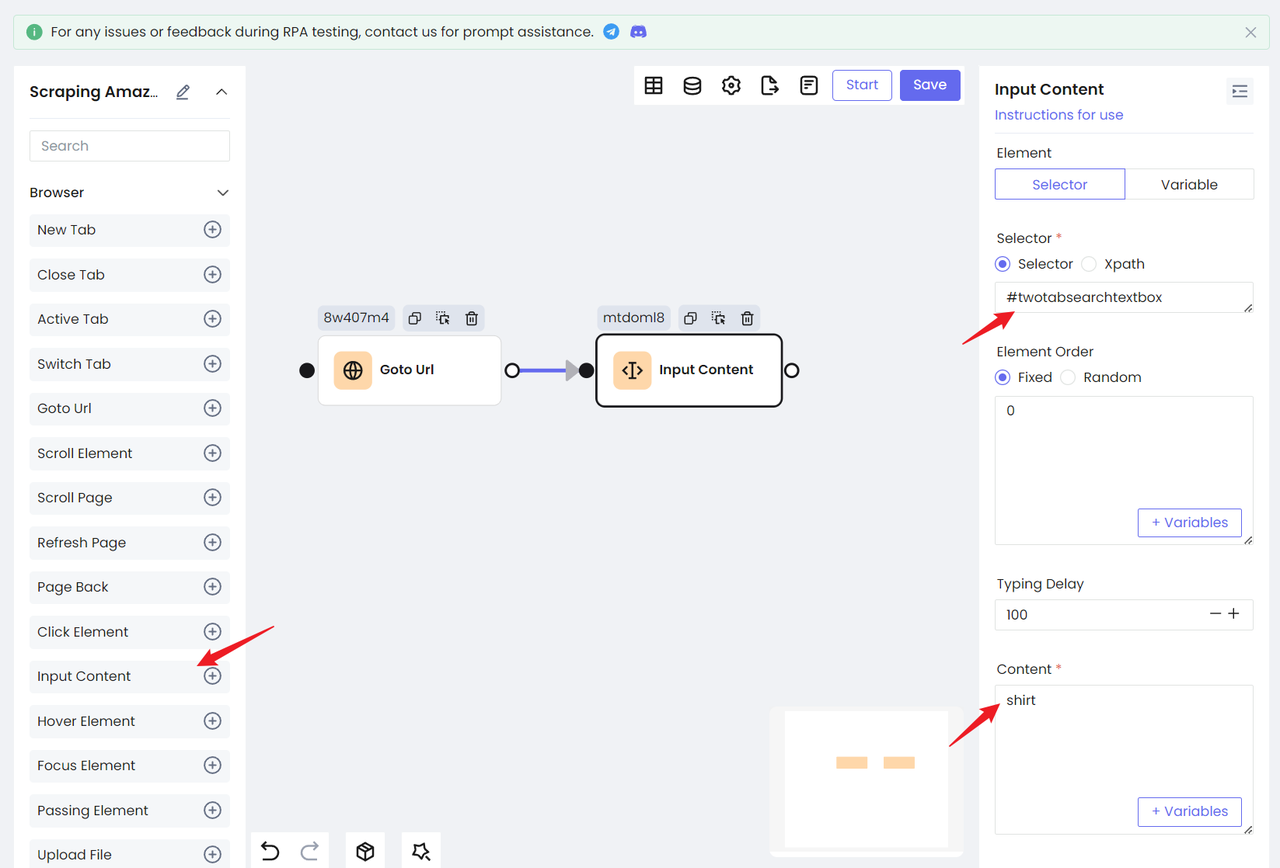
Добавьте узел Ввод текста:
- Выберите Селектор в параметре "Элемент". Эта опция единым образом выбирает Селектор.
- Заполните CSS-селектор
id, который мы определили в поле ввода - и затем введите в параметре "Текст" текст, который мы хотим найти.
Таким образом, мы завершили действие ввода текста в поле ввода.
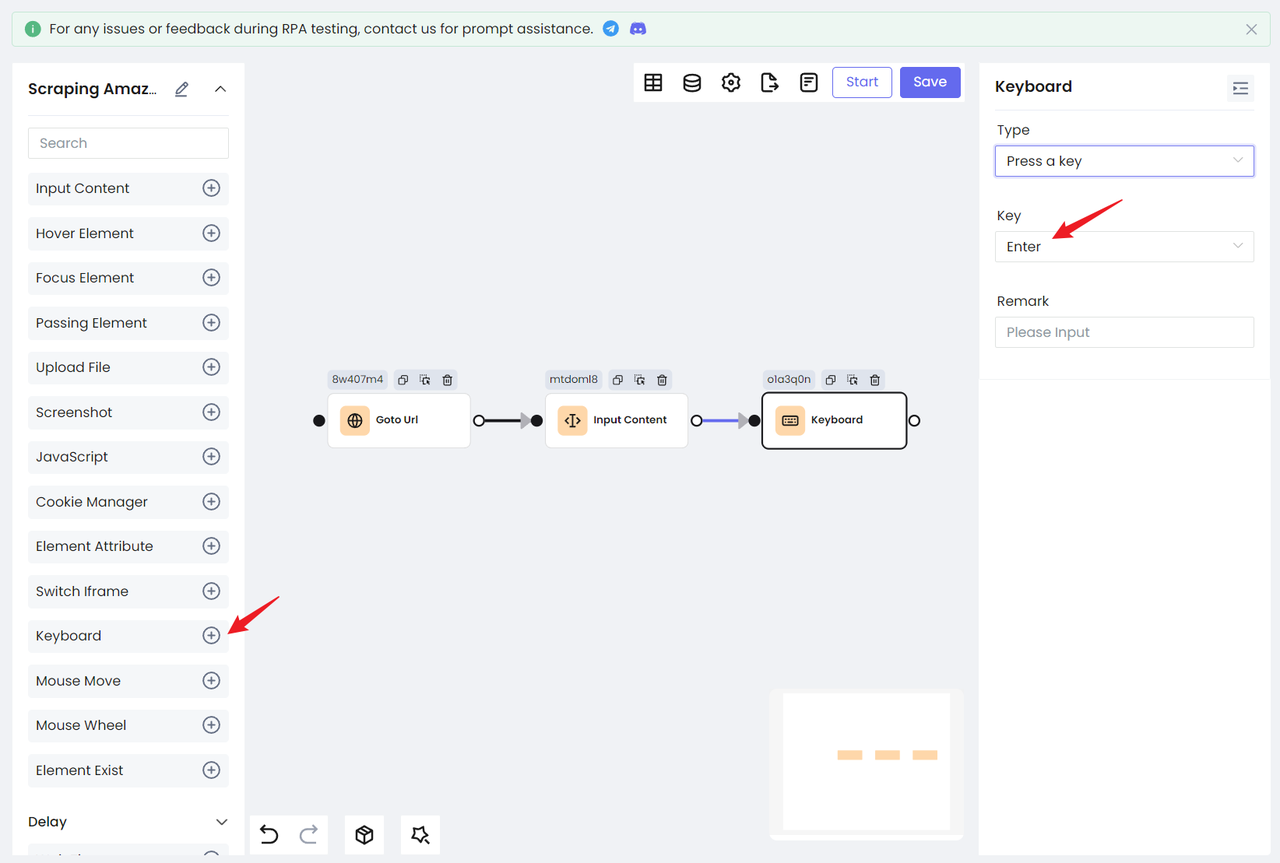
- Затем используйте узел
Клавиатура, чтобы симулировать действие ввода с помощью клавиши Enter для поиска товаров:
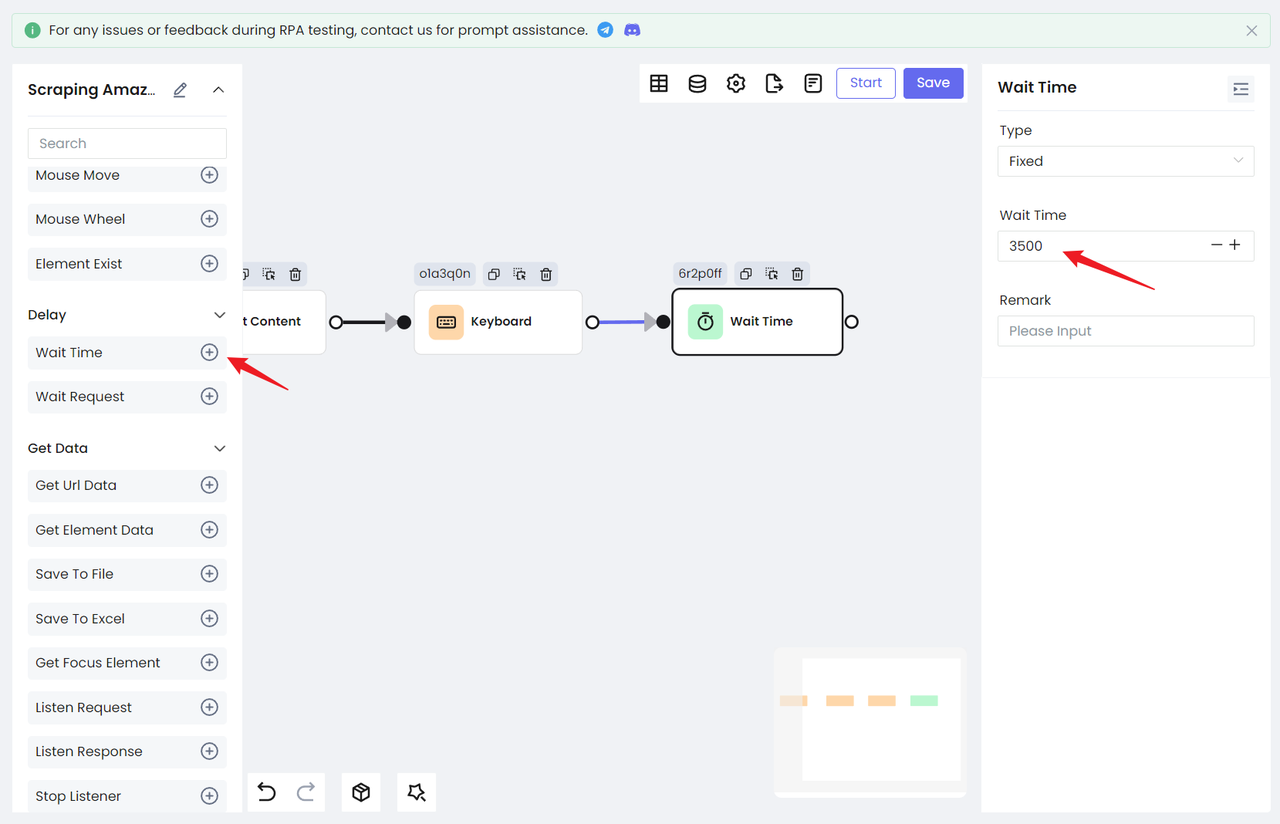
Поскольку страница поиска будет переходить на новую страницу, нам нужно добавить действие ожидания, чтобы убедиться, что мы успешно загрузили страницу с результатами. Nstbrowser RPA предоставляет два варианта ожидания: Ожидание времени и Ожидание запроса.
Ожидание времени: используется для ожидания в течение определенного периода времени. Вы можете выбрать фиксированное время или случайное время в зависимости от конкретной ситуации.Ожидание запроса: используется для ожидания завершения сетевого запроса. Применимо для получения данных через сетевые запросы.
Шаг 3. Перебор списка товаров
Хорошо, теперь мы успешно видим новую страницу поиска товаров, и следующий шаг - парсинг этого контента.
Присмотревшись, мы видим, что результаты поиска на Amazon отображаются в виде списка карточек. Это очень классический способ отображения:
Точно так же откройте инструмент Devtool и найдите каждый элемент данных в карточке:
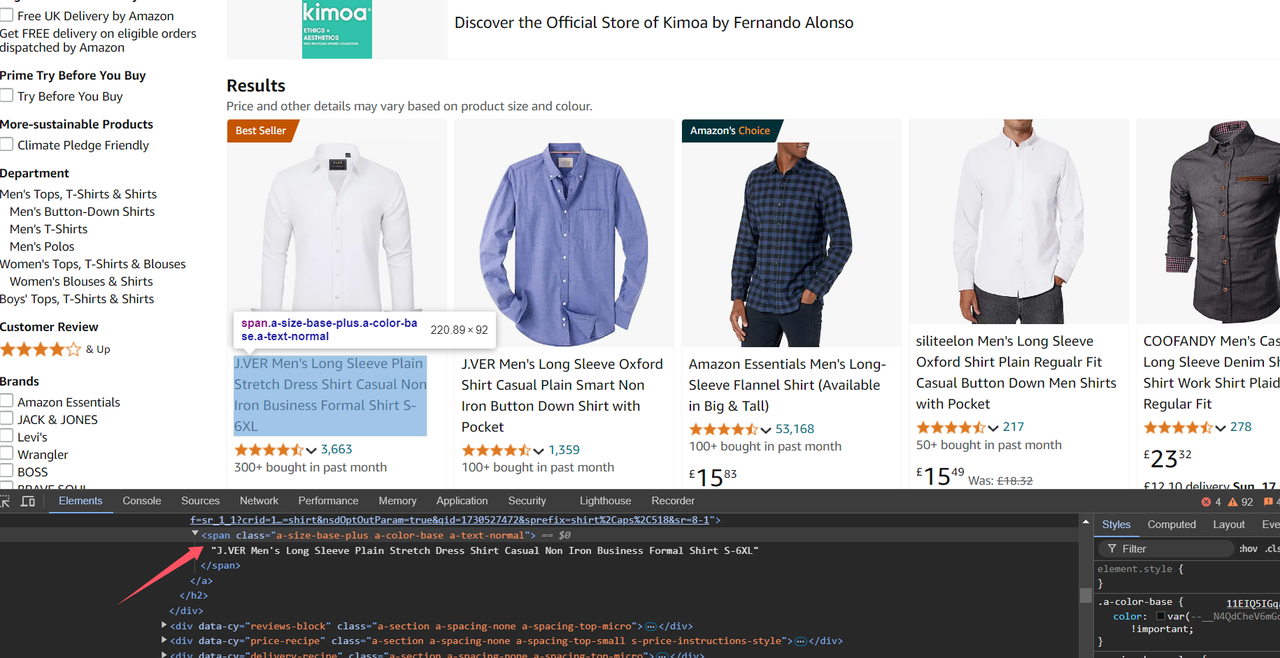
Поскольку каждый элемент в списке карточек является HTML-элементом, нам нужно использовать узел Цикл по элементам для перебора всех результатов поиска. Мы заполняем CSS-селектор списка product в Селекторе и выбираем Объект элемента для Типа данных, что означает получение целевого элемента и сохранение его как объекта элемента в переменную. Установите имя переменной product в параметре Сохранить данные в переменной и сохраните индекс как productIndex.
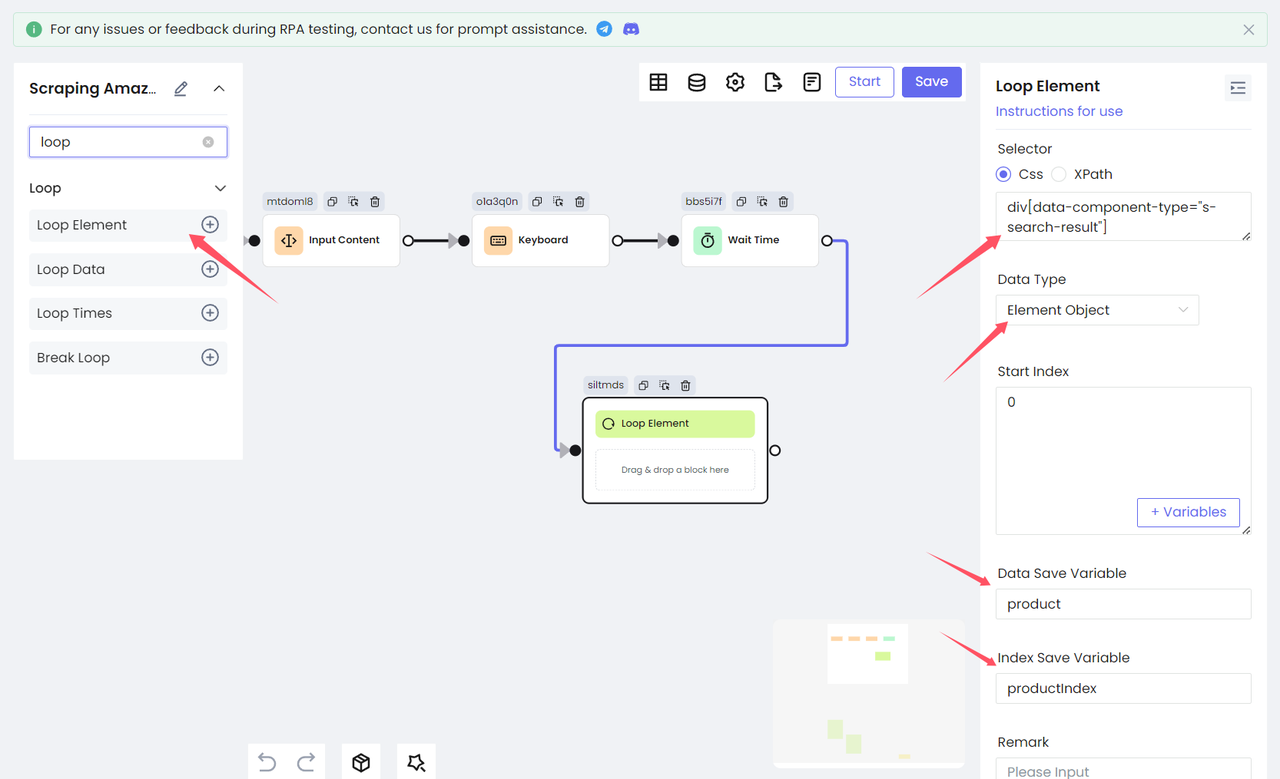
Шаг 4. Получение данных
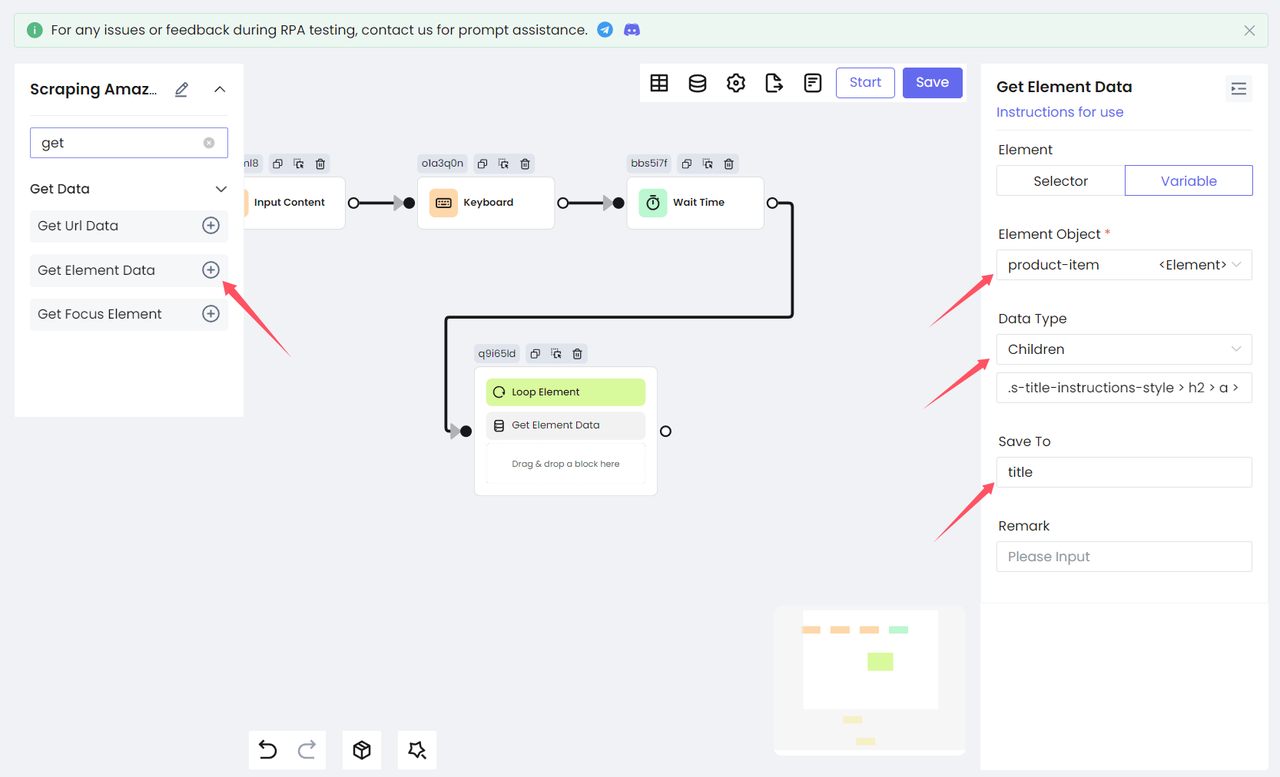
Далее нам нужно обработать каждый пройденный элемент и получить необходимую информацию из product. Мы получаем элемент заголовка продукта. Здесь нам нужно использовать узел Получить данные элемента, чтобы получить его и в итоге сохранить как переменную title.
Выберите Дочерние элементы в качестве Типа данных, что означает получение дочерних элементов целевого элемента и сохранение их как объекта элемента в переменную title. Вам нужно заполнить селектор элемента дочернего элемента. CSS-селектор, введенный здесь, - это, естественно, CSS-селектор заголовка продукта:
Затем мы используем тот же метод для преобразования остальной информации о продукте: рейтинга, ссылок на изображения и цен, в процессы RPA.
- Имена переменных и CSS-селекторы дочерних элементов:
Bash
'title' .s-title-instructions-style > h2 > a > span
'rate' a > i.a-icon.a-icon-star-small > span
'img' span[data-component-type="s-product-image"] img
'price' div[data-cy="price-recipe"] .a-offscreen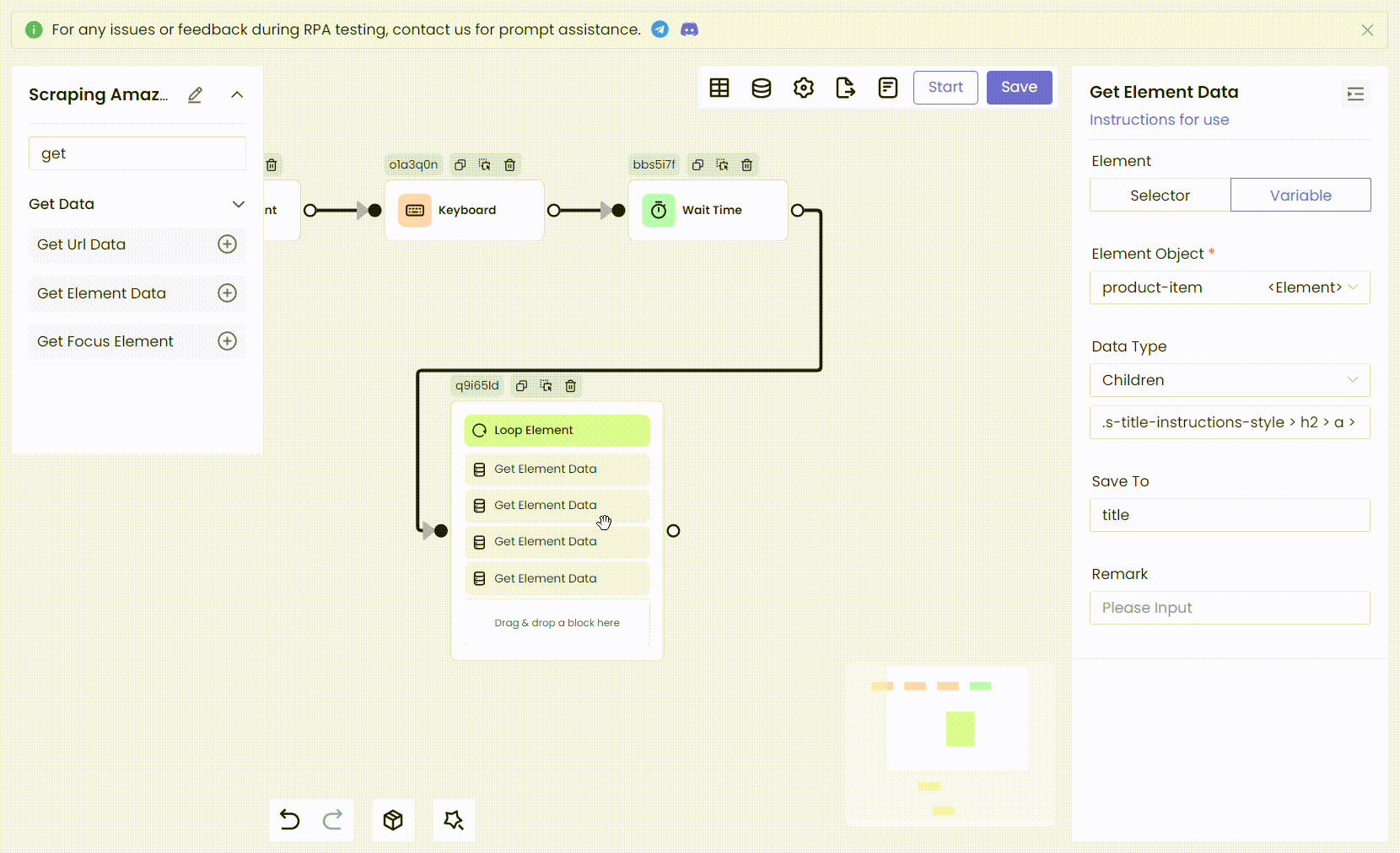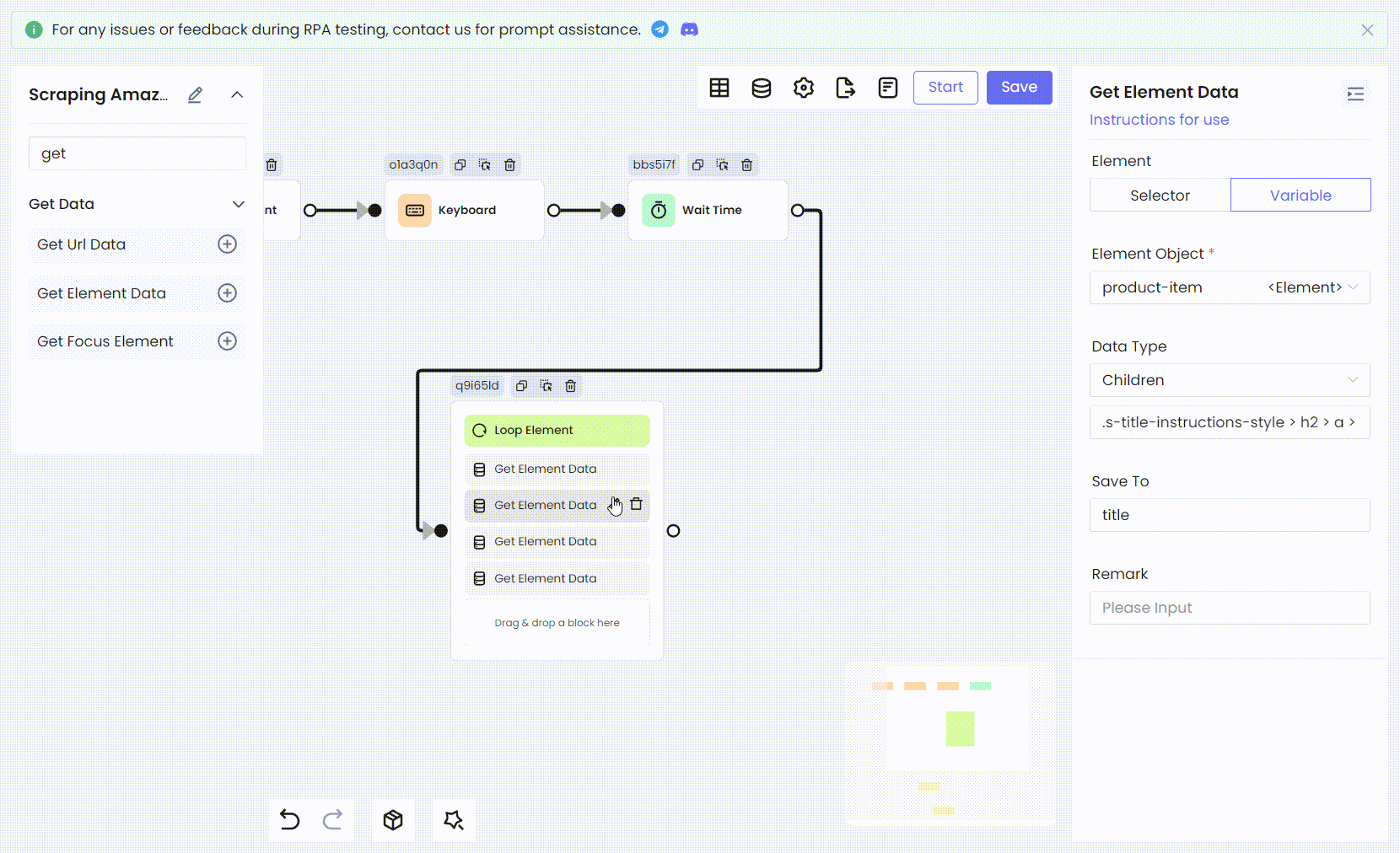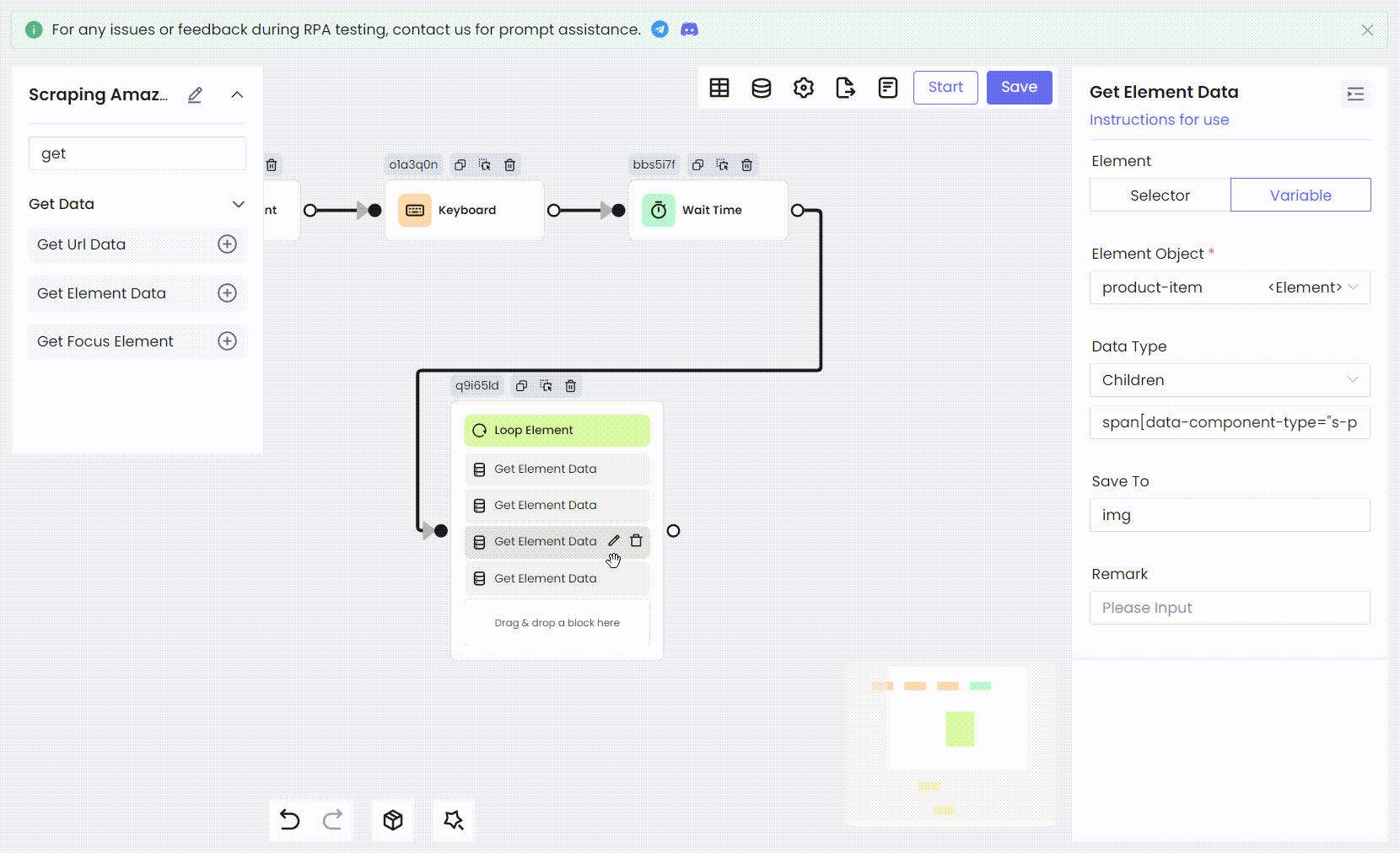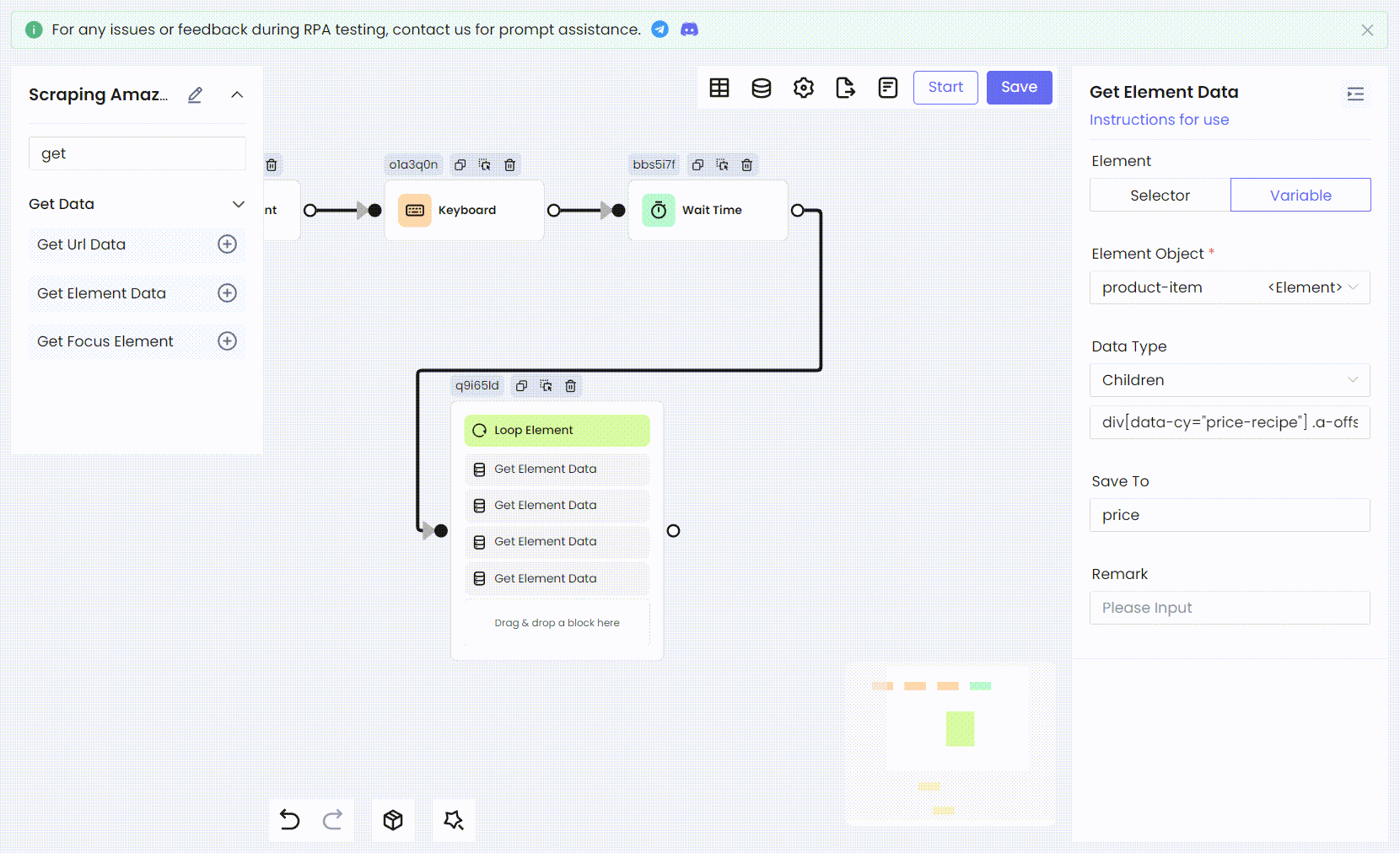
Однако переменные данные, полученные выше, на самом деле являются HTML-элементами. Нам все еще нужно обработать их, чтобы вывести текст в HTML-элементах и подготовить к последующему хранению данных.
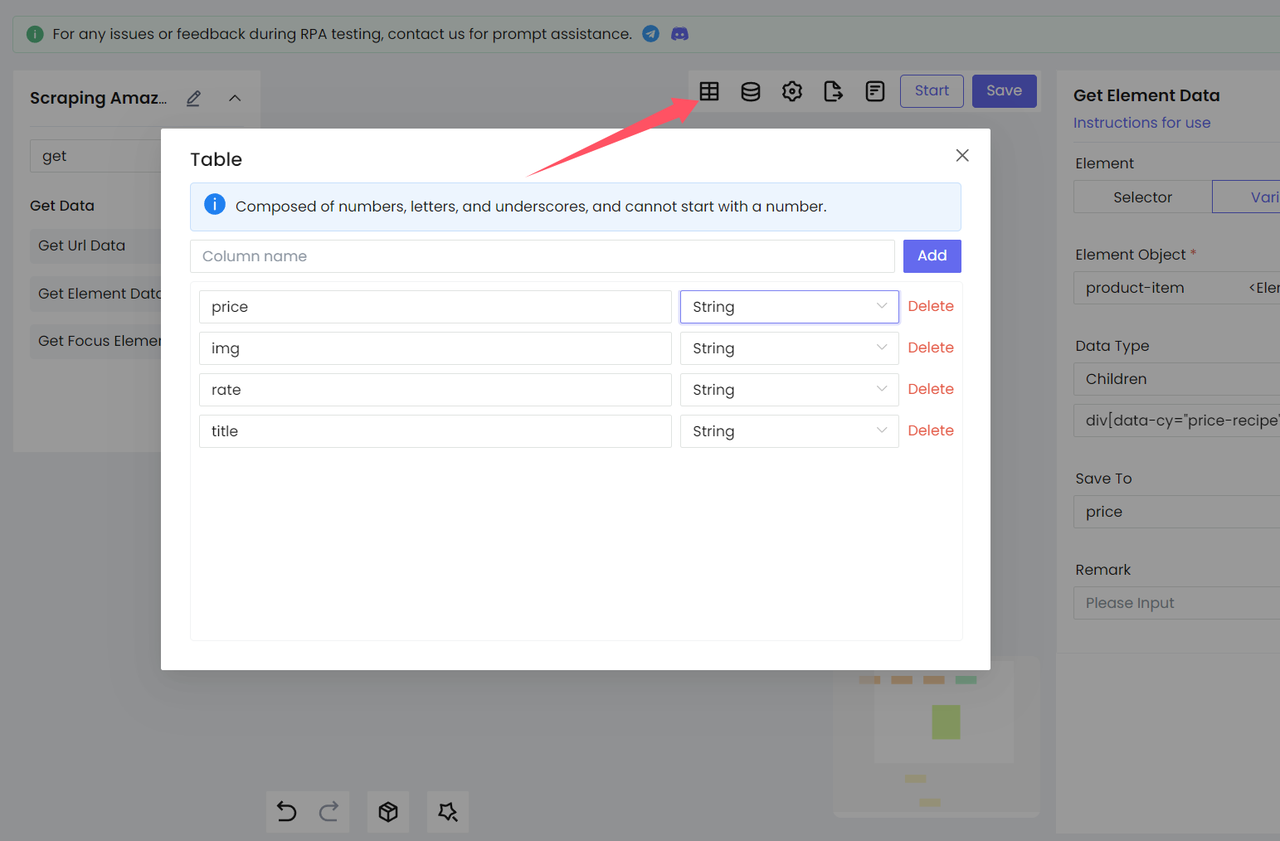
- Настройка таблицы
Нам нужно
- Настроить таблицу
- И сгенерировать соответствующий Excel на основе полей этой таблицы:
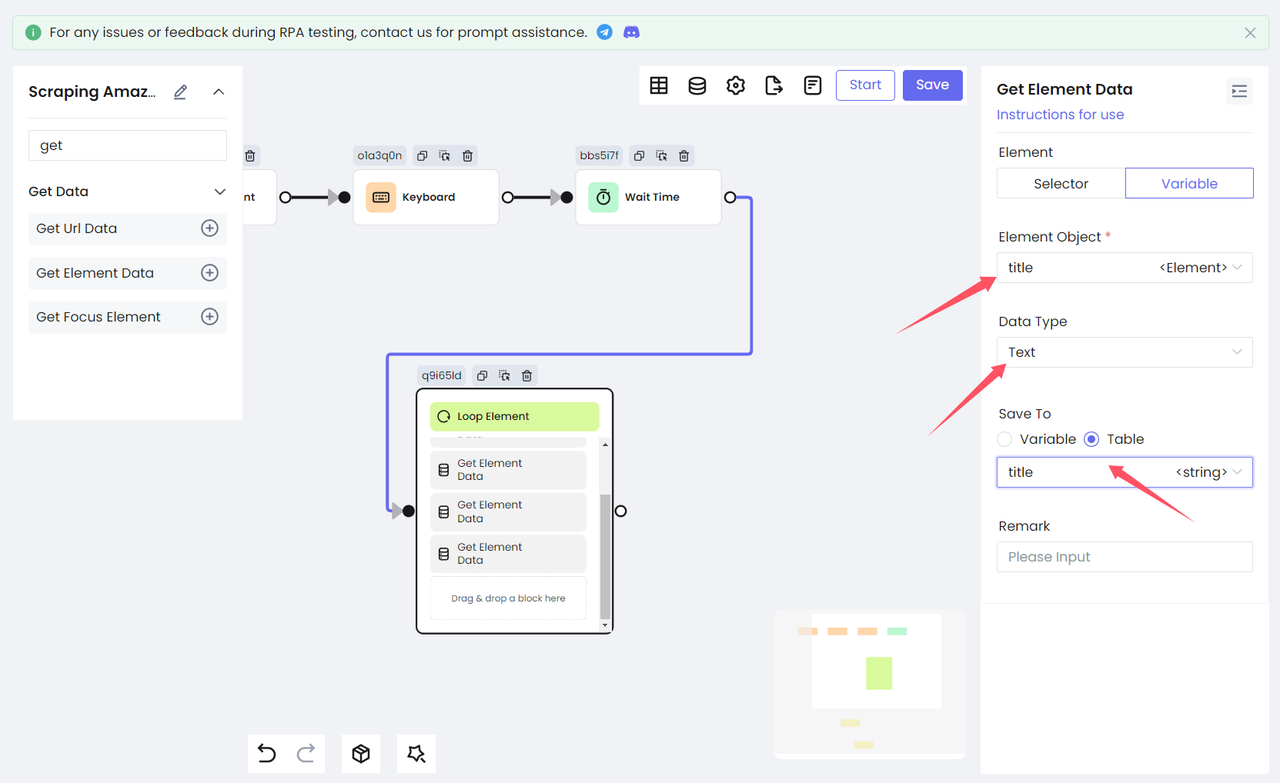
- Получение текста элемента
Добавьте снова узел Получить данные элемента, чтобы вывести полученные выше переменные в виде текста и сохранить их в табличной переменной для последующего хранения данных. Выберите Тип данных Текст, чтобы получить innerText целевого элемента. (На рисунке ниже показана обработка переменной title)
- Получение ссылки на изображение
Затем мы используем тот же метод, чтобы преобразовать рейтинг и цену продукта в окончательную текстовую информацию.
Ссылка на изображение требует дополнительной обработки. Здесь мы используем узел javascript, чтобы получить src изображения текущего пройденного продукта. Обратите внимание, что переменная индекса productIndex, сохраненная узлом Цикл по элементам, должна быть введена в сценарий и в итоге сохранена как переменная imgSrc.
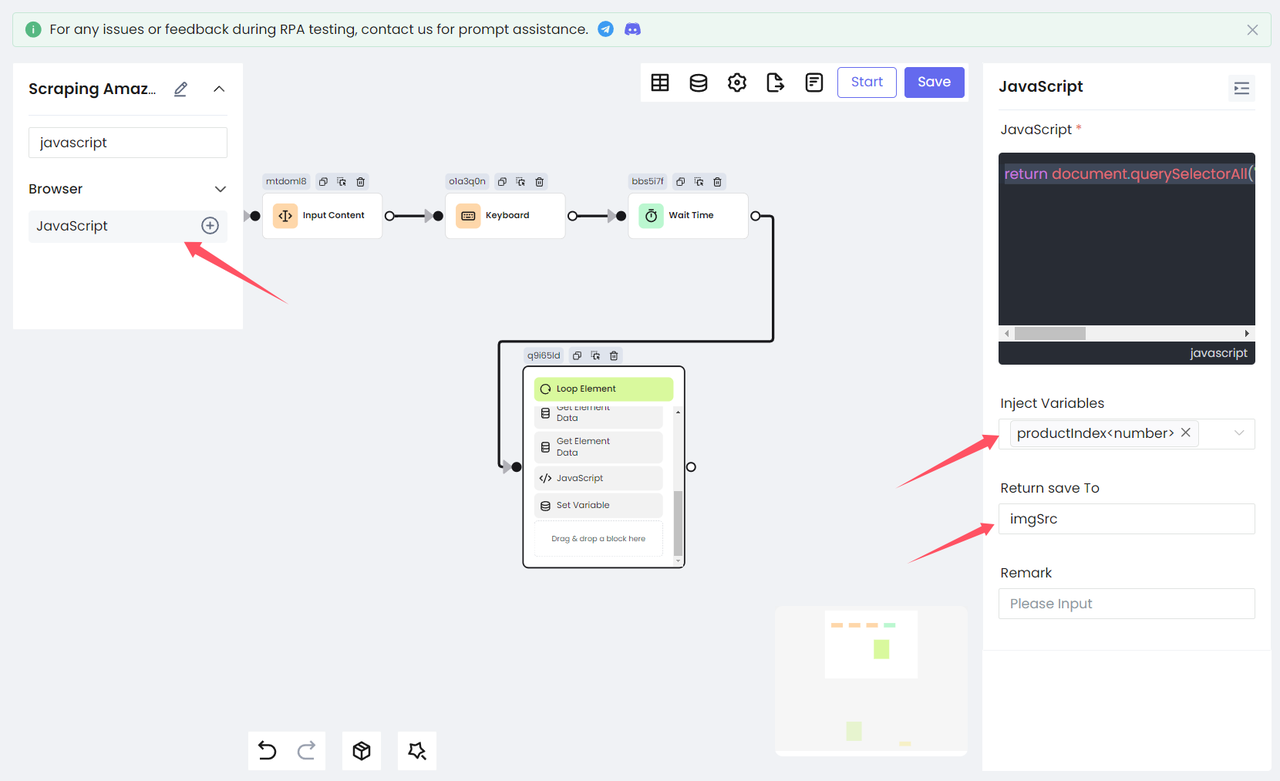
JavaScript
return document.querySelectorAll('[data-image-latency="s-product-image"]')[productIndex].getAttribute('src')Наконец, мы используем узел "Установить переменную", чтобы сохранить переменную imgSrc в таблицу:
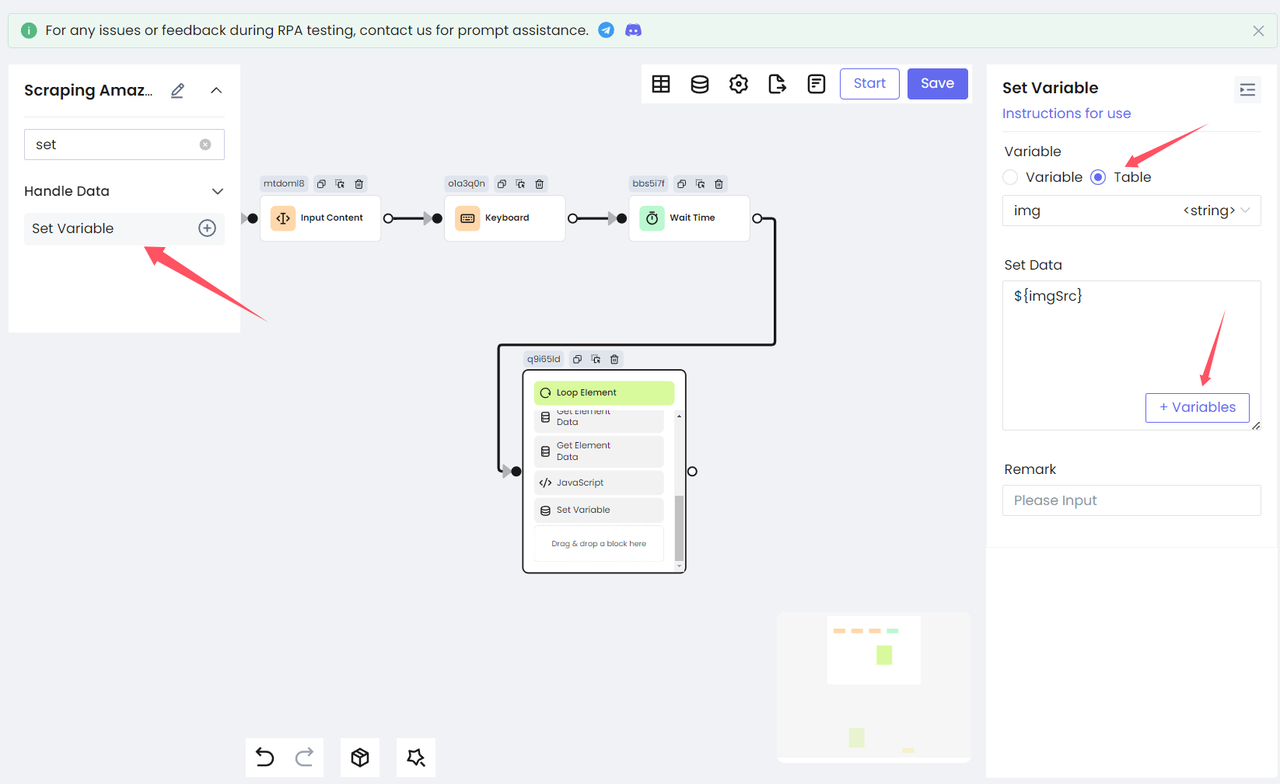
Шаг 5. Сохранение результата
На этом этапе мы получили все данные, которые хотим собрать, и пришло время сохранить эти данные.
- Nstbrowser RPA предоставляет два способа сохранения данных:
Сохранить в файлиСохранить в Excel.
Сохранить в файлпредоставляет три типа файлов на выбор: .txt, .CSV и .JSON.Сохранить в Excelпозволяет сохранять данные только в файлы Excel.
Для удобства просмотра мы выбираем сохранение собранных данных в Excel. Добавьте узел Сохранить в Excel, настройте путь к файлу и имя файла, который нужно сохранить, выберите табличное содержимое, которое нужно сохранить, и все готово!
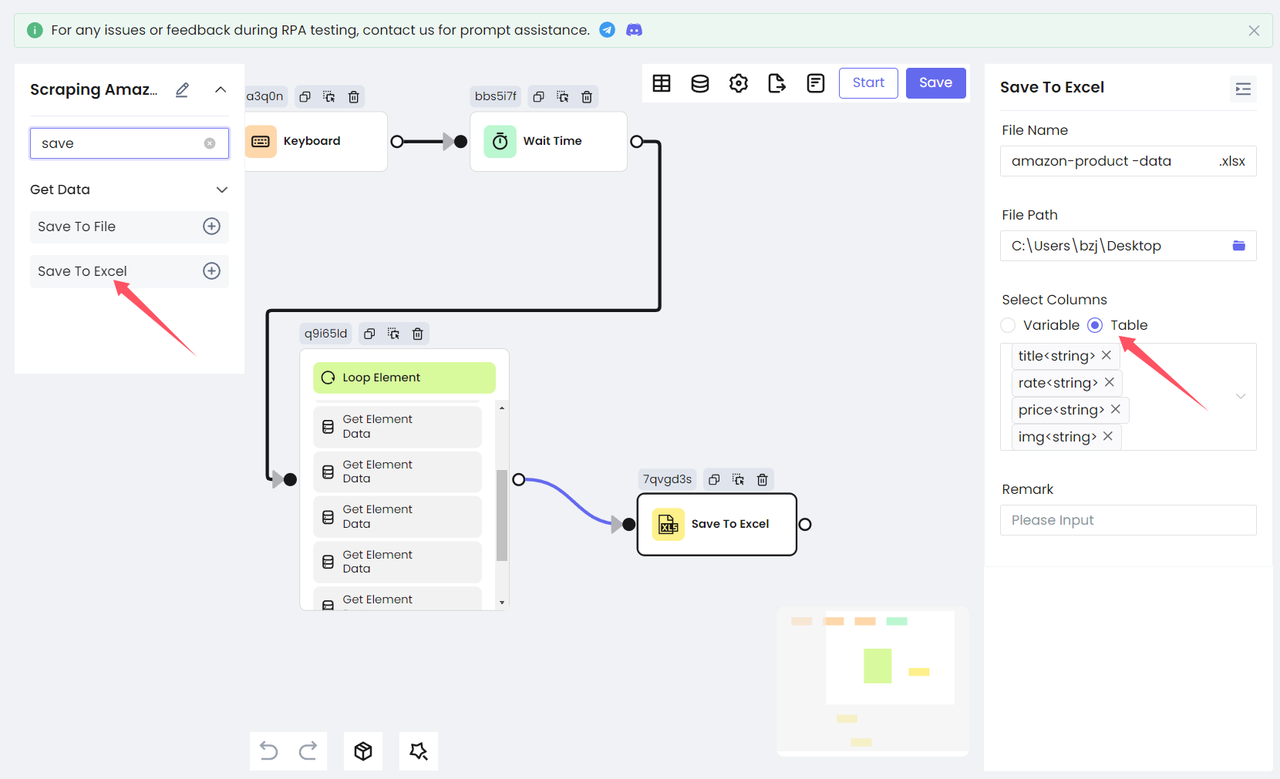
Запуск RPA
Сначала сохраните настроенный рабочий процесс, затем вы можете запустить его непосредственно на текущей странице или вернуться на предыдущую страницу, создать новые задачи и нажать кнопку "Запустить", чтобы запустить его. На этом этапе мы можем начать сбор данных о товарах на Amazon!
После завершения выполнения вы увидите файл amazon-product-data.xlsx, созданный на рабочем столе.
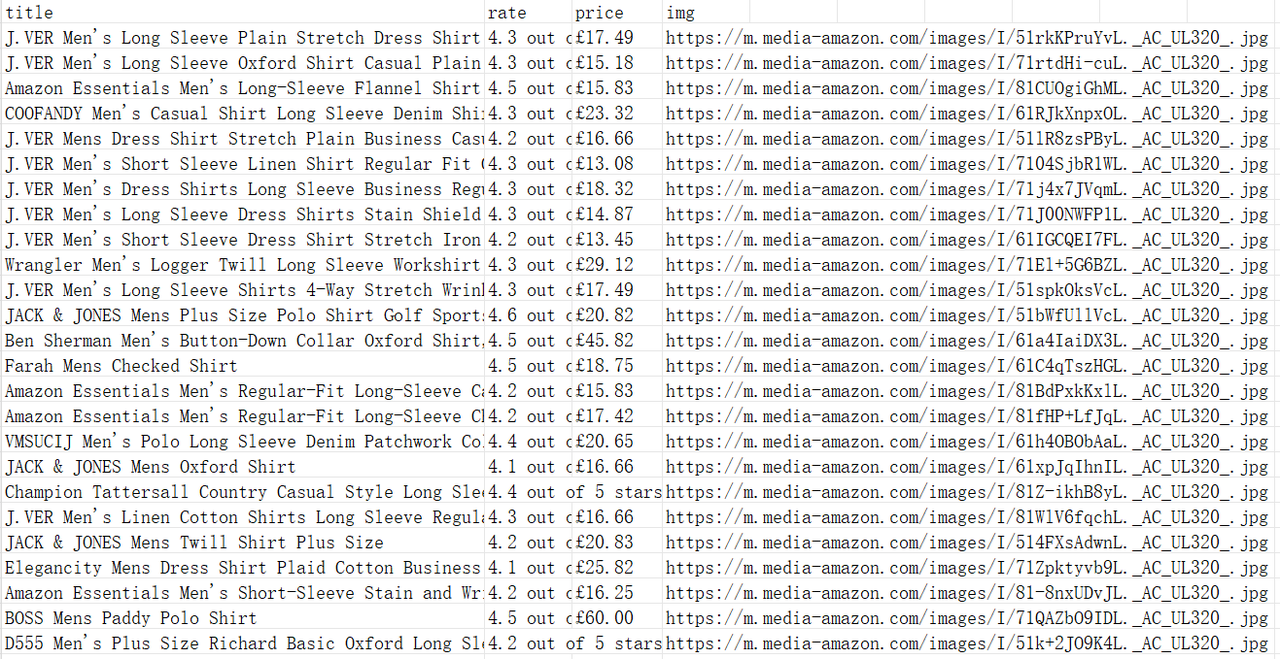
Итоги
Самый простой способ скрапинга товаров на Amazon - создать свой собственный Amazon product scraper с помощью Browserless. Эта самая полная учебная статья 2024 года ясно объясняет вам:
- Преимущества парсинга товаров на Amazon.
- Мощные функции Amazon product scraper от Browserless.
- Как создать более простой скрапер с помощью RPA от Nstbrower.
Особо интересуетесь веб-данными? Посмотрите наш рынок RPA. Nstbrowser подготовил 20 мощных программ RPA, которые могут решить все ваши проблемы во всех аспектах.
**Если у вас есть особые потребности в Browserless, парсинге данных или автоматизации, пожалуйста, свяжитесь с нами вовремя. Мы готовы предоставить вам высококачественные индивидуальные услуги.
Отказ от ответственности: Любые данные и сайты, упомянутые в этой статье, используются только для демонстрационных целей. Мы решительно против незаконных и нарушающих авторские права действий. Если у вас есть вопросы или опасения, пожалуйста, немедленно свяжитесь с нами.
Больше





