
Browserless
Web Scraping sin navegador: NodeJs en Selenium
El uso de headlesschrome es importante en el web scraping. Este artículo habla sobre los pasos más detallados para realizar web scraping con NodeJS y Selenium sin navegador.
Aug 14, 2024Carlos Rivera
¿Funciona Bien Selenium?
Selenium es un marco de automatización web de código abierto muy popular, que se utiliza principalmente para la automatización de pruebas en navegadores. Además, también se puede usar para resolver problemas de scraping web dinámico.
Selenium tiene 3 componentes principales:
- Selenium IDE: Un complemento del navegador que proporciona una manera más rápida y sencilla de crear, ejecutar y depurar scripts de Selenium.
- Selenium WebDriver: Un conjunto de APIs portables que ayudan a escribir pruebas automatizadas en cualquier lenguaje de programación que se ejecute en un navegador.
- Selenium Grid: Herramienta de automatización para distribuir y escalar pruebas a través de múltiples navegadores, sistemas operativos y plataformas.
¿Es Browserless Bueno para el Web Scraping?
¿Qué es Browserless?
Nstbrowserless es un servicio basado en la nube para headlesschrome que ejecuta operaciones web y ejecuta scripts de automatización sin requerir una interfaz gráfica. Es particularmente útil para automatizar tareas como el web scraping y otros procesos automatizados.
¿Es Browserless bueno para el web scraping?
¡Sí, absolutamente! Nstbrowserless puede realizar scraping web complejo y cualquier otra tarea de automatización en la nube. Liberará el servicio local y el almacenamiento de tus dispositivos. Nstbrowserless funciona con un navegador anti-detect y una característica de headlesschrome. Ya no tienes que preocuparte por ser detectado y enfrentar bloqueos web.
Combinar Browserless y Selenium mejora la automatización web al permitir que Selenium ejecute scripts de prueba en un entorno headlesschrome basado en la nube proporcionado por Browserless. Esta configuración es eficiente para tareas a gran escala como el web scraping, ya que elimina la necesidad de un navegador físico mientras maneja contenido dinámico e interacciones con el usuario.
¿Tienes alguna idea maravillosa o dudas sobre el web scraping y Browserless?
¡Veamos qué están compartiendo otros desarrolladores en Discord y Telegram!
¿Cuáles Son las Ventajas del Web Scraping con Selenium?
- Manejo de Contenido Dinámico: Selenium puede interactuar con sitios web cargados con JavaScript. Permite hacer scraping del contenido que se carga dinámicamente después de la carga inicial de la página.
- Automatización del Navegador: Selenium puede simular interacciones reales del usuario con los sitios web, como hacer clic en botones, completar formularios y navegar por las páginas, lo que lo hace ideal para extraer datos de sitios que requieren interacción del usuario.
- Soporte Multinavegador: Selenium admite una variedad de navegadores (Chrome, Firefox, Safari), por lo que puedes realizar pruebas y scraping en diferentes entornos.
- Flexibilidad de Lenguaje de Programación: Selenium es compatible con varios lenguajes de programación, incluidos Python, Java, C# y JavaScript, lo que brinda a los desarrolladores flexibilidad para elegir su lenguaje preferido.
- Evasión de Medidas Anti-Scraping: La capacidad de Selenium para imitar el comportamiento real del usuario lo hace efectivo para evadir algunas medidas anti-scraping diseñadas para prevenir el scraping automatizado, como CAPTCHA y limitación de velocidad.
- Recolección de Datos en Tiempo Real: Con Selenium, puedes hacer scraping y recolectar datos en tiempo real, lo cual es útil para aplicaciones sensibles al tiempo.
- Amplia Comunidad y Documentación: Selenium tiene una gran comunidad activa junto con documentación extensa para ayudar a solucionar problemas y aumentar la eficiencia de tus proyectos de scraping web.
¿Cómo Usar NodeJS en Selenium?
Usando Node.js en Selenium, los desarrolladores pueden controlar headlesschrome para realizar varias operaciones, como web scraping, pruebas automatizadas, generación de capturas de pantalla, etc.
Esta combinación aprovecha las características eficientes y no bloqueantes de Node.js y las capacidades del navegador headlesschrome para lograr una automatización y procesamiento de datos eficientes.
Paso 1. Instalación
Ingresa el siguiente comando en la terminal:
Shell
npm install selenium-webdriverSi la terminal informa un error, verifica si tu computadora tiene un entorno de Node.js:
Shell
node --version¿No tienes un entorno de Node.js? Por favor, instala primero la última versión del entorno de Node.js.
Paso 2. Ejecutar el Navegador con NodeJS en Selenium
Selenium es conocido por sus poderosas capacidades de automatización de navegadores. Admite la mayoría de los navegadores principales, incluidos Chrome, Firefox, Edge, Opera, Safari e Internet Explorer.
Como Chrome es el más popular y potente entre ellos, lo usarás en este tutorial.
JavaScript
import { Builder, Browser } from 'selenium-webdriver';
async function run() {
const driver = new Builder()
.forBrowser(Browser.CHROME)
.build();
await driver.get('https://www.yahoo.com/');
}También puedes agregar cualquier personalización que desees. Vamos a hacer que nuestros scripts sean headlesschrome:
JavaScript
import { Builder, Browser } from 'selenium-webdriver';
import chrome from 'selenium-webdriver/chrome';
const options = new chrome.Options();
options.addArguments('--remote-allow-origins=*');
options.addArguments('--headless');
async function run() {
const driver = new Builder()
.setChromeOptions(options)
.forBrowser(Browser.CHROME)
.build();
await driver.get('https://www.yahoo.com/');
}¡Ahora puedes visitar cualquier sitio web!
Paso 3. Hacer Scraping del Sitio Web
Una vez que tengas el HTML completo de la página web, puedes proceder a extraer los datos requeridos. En este caso, vamos a analizar el título y el contenido de todas las noticias en la página.
Para lograr esta tarea, debes seguir estos pasos:
- Analiza el DOM de la página web usando DevTools.
- Implementa una estrategia efectiva de selección de nodos para ubicar las noticias.
- Extrae los datos requeridos y almacénalos en un arreglo/objeto de JavaScript.
DevTools es una herramienta invaluable en el web scraping. Te ayuda a inspeccionar el HTML, CSS y JavaScript cargados actualmente. También puedes obtener información sobre las solicitudes de red realizadas a la página y sus tiempos de carga correspondientes.
Los selectores CSS y las expresiones XPath son las estrategias de selección de nodos más confiables. Puedes usar cualquiera de ellas para ubicar los elementos, pero en este tutorial, por simplicidad, utilizaremos los selectores CSS.
Vamos a usar DevTools para encontrar el selector CSS correcto. Abre la página web objetivo en tu navegador y haz clic derecho en el elemento del producto > Inspeccionar para abrir DevTools.
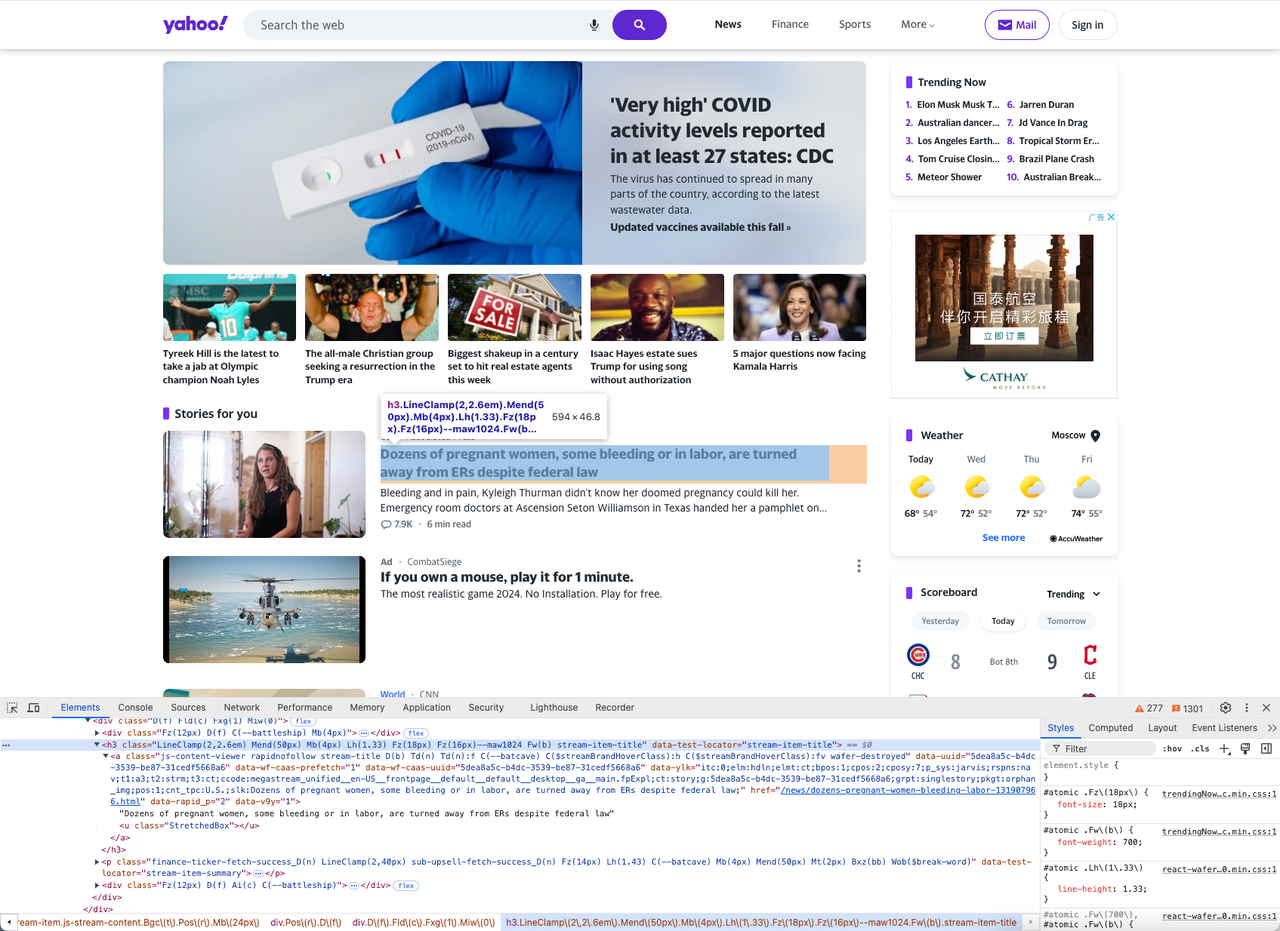
Puedes ver que la estructura de cada título de noticia está compuesta por una etiqueta h3 y una etiqueta a, y podemos usar el selector h3[data-test-locator="stream-item-title"] para ubicarlas.
Usamos el mismo método para encontrar el selector p[data-test-locator="stream-item-summary"] para el contenido de las noticias.
Define el selector CSS usando la información anterior y ubica el producto usando los métodos findElements() y findElement().
Además, usa el método getText() para extraer el texto interno del nodo HTML, y finalmente almacena el nombre y el precio extraídos en un arreglo.
JavaScript
const titlesArray = [];
const contentArray = [];
const newsTitles = await driver.findElements(By.css('h3[data-test-locator="stream-item-title"]'));
const newsContents = await driver.findElements(By.css('p[data-test-locator="stream-item-summary"]'));
for (let title of newsTitles) {
titlesArray.push(await title.getText());
}
for (let content of newsContents) {
contentArray.push(await content.getText());
}Paso 4. Exportación de datos
¡Hemos obtenido los datos de web scraping! Ahora necesitamos exportarlos a un archivo CSV.
Importa el módulo fs incorporado de Node.js, que proporciona funciones para trabajar con el sistema de archivos:
JavaScript
import fs from 'node';Luego, inicializa una variable de cadena llamada newsData con una fila de encabezado que contenga los nombres de las columnas ("title, content\n").
JavaScript
let newsData = 'title,content\n';A continuación, recorre los dos arreglos (titlesArray y contentsArray) que contienen los títulos y el contenido de las noticias. Para cada elemento del arreglo, añade una línea después de newsData con una coma separando el título y el contenido.
JavaScript
for (let i = 0; i < titlesArray.length; i++) {
newsData += `${titlesArray[i]},${contentsArray[i]}\n`;
}Utiliza la función fs.writeFile() para escribir la cadena newsData en un archivo llamado yahooNews.csv. Esta función acepta tres parámetros: el nombre del archivo, los datos a escribir y una función de callback para manejar cualquier error encontrado durante el proceso de escritura.
JavaScript
fs.writeFile("yahooNews.csv", newsData, err => {
if (err) {
console.error("Error:", err);
} else {
console.log("¡Éxito!");
}
});Al ejecutar nuestro código, obtendremos un resultado similar a este:

Felicidades, has aprendido a usar Selenium y headlesschrome: NodeJS para hacer scraping.
¿Cómo evitar el bloqueo web al hacer scraping con Browserless?
Usar el modo headlesschrome en Browserless puede evitar automáticamente la detección web y el bloqueo web en la mayor medida posible. Pero combina estas estrategias para lograr un scraping más eficiente y una experiencia fluida.
- Simular el comportamiento real del usuario
A continuación se muestra un código de ejemplo que utiliza Selenium y Node.js para simular el comportamiento real del usuario. El código muestra cómo establecer el User-Agent, simular operaciones con el mouse, manejar contenido dinámico, simular la entrada del teclado y controlar el comportamiento del navegador.
Antes de usarlo, asegúrate de tener instalados selenium-webdriver y chromedriver.
JavaScript
const { Builder, By, Key, until } = require('selenium-webdriver');
const chrome = require('selenium-webdriver/chrome');
const path = require('path');
// Iniciar el navegador
(async function example() {
// Configurar opciones de Chrome
let chromeOptions = new chrome.Options();
chromeOptions.addArguments('headless'); // Usar modo headless
chromeOptions.addArguments('window-size=1280,800'); // Establecer el tamaño de la ventana del navegador
// Crear una instancia de WebDriver
let driver = await new Builder()
.forBrowser('chrome')
.setChromeOptions(chromeOptions)
.build();
try {
// Establecer User-Agent y otros encabezados de solicitud
await driver.executeCdpCmd('Network.setUserAgentOverride', {
userAgent: 'Tu User-Agent personalizado',
});
// Navegar a la página objetivo
await driver.get('https://example.com');
// Simular movimiento y clics del mouse
let element = await driver.findElement(By.css('selector-for-clickable-element'));
await driver.actions().move({ origin: element }).click().perform();
// Tiempo de espera aleatorio
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
await sleep(Math.random() * 5000 + 2000); // Esperar aleatoriamente entre 2 y 7 segundos
// Manejar contenido dinámico y esperar a que cargue un elemento específico
await driver.wait(until.elementLocated(By.css('#dynamic-content')), 10000);
// Simular entrada de teclado
let searchInput = await driver.findElement(By.css('#search-input'));
await searchInput.sendKeys('Node.js', Key.RETURN);
// Desplazamiento aleatorio
await driver.executeScript('window.scrollBy(0, window.innerHeight);');
} finally {
// Cerrar el navegador
await driver.quit();
}
})();- Usar un proxy
Usar un servidor proxy para ocultar tu dirección IP real puede evitar eficazmente el bloqueo de IP. Puedes optar por rotar el proxy para usar una dirección IP diferente para cada solicitud, reduciendo así el riesgo de bloqueo.
- Limitar la frecuencia de scraping
Controla la frecuencia de scraping para evitar enviar un gran número de solicitudes en un corto período de tiempo, lo que puede reducir la posibilidad de activar mecanismos anti-scraping. Puedes establecer un intervalo de tiempo apropiado para enviar solicitudes y simular el comportamiento normal de navegación.
- Evitar CAPTCHAs
Si el sitio web utiliza CAPTCHA para protección, puedes usar un servicio de reconocimiento de CAPTCHA de terceros para resolver estos desafíos automáticamente o configurar Selenium para manejar CAPTCHA.
- Ocultar la huella del navegador real
Algunos sitios web utilizan huellas del navegador para identificar herramientas automatizadas. Configurar diferentes huellas del navegador o usar un navegador anti-detect con cambio de huella incorporado puede ayudar a evitar la detección del sitio web.
- Procesamiento de contenido cargado dinámicamente
Usar Browserless junto con Selenium para procesar contenido cargado dinámicamente (como solicitudes AJAX) puede asegurar que se capture toda la información renderizada dinámicamente en la página web, no solo el contenido estático.
Uso de Selenium para otras operaciones web
1. Localizar elementos
Selenium en sí mismo proporciona una variedad de métodos para encontrar elementos en la página, incluyendo:
- Buscar por nombre de etiqueta: Buscar por el nombre de la etiqueta del elemento, como
<input>o<button>, adecuado para búsquedas extensas. - Buscar por nombre de clase HTML: Buscar utilizando el nombre de clase CSS del elemento, como
.class-name, adecuado para localizar rápidamente elementos con nombres de clase específicos. - Buscar por ID: Buscar por el ID único del elemento, como
#element-id, que es particularmente efectivo para encontrar rápidamente elementos específicos. - Usar selectores CSS: Utilizar la sintaxis de selectores CSS para encontrar elementos, y puedes seleccionar elementos con atributos, nombres de clase o estructuras específicas, como
div > p.class-name. - Usar expresiones XPath: Encontrar elementos por rutas XPath, permitiendo una navegación precisa de las estructuras de la página, como
//div[@id='example'].
Así, en Selenium WebDriver, podemos localizar elementos en una página web a través del método find_element. Solo necesitas agregar los requisitos específicos al usarlo. Por ejemplo:
find_element_by_id: Encontrar un elemento por su ID único.find_element_by_class_name: Encontrar un elemento por su nombre de clase CSS.find_element_by_link_text: Encontrar un elemento de enlace por su texto de enlace.
2. Esperar elementos
En ciertas situaciones, como una red lenta o un navegador, tu script puede fallar o mostrar resultados inconsistentes.
En lugar de esperar un intervalo fijo, elige esperar de manera inteligente, como esperar a que aparezca un nodo específico o se muestre en la página. Esto asegura que los elementos web estén correctamente cargados antes de interactuar con ellos, reduciendo las posibilidades de errores como elemento no encontrado y elemento no interactuable.
El siguiente fragmento de código implementa la estrategia de espera. El método until.elementsLocated define la condición de espera, asegurando que WebDriver espere hasta que el elemento especificado sea encontrado o se alcance el tiempo máximo de espera de 5000 milisegundos (5 segundos).
JavaScript
const { Builder, By, until } = require('selenium-webdriver');
const yourElements = await driver.wait(until.elementsLocated(By.css('.your-css-selector')), 5000);3. Captura de pantalla
En NodeJS, puedes tomar capturas de pantalla simplemente llamando a una función. Sin embargo, hay algunas consideraciones para asegurar que las capturas de pantalla se capturen correctamente:
- Tamaño de la ventana: Asegúrate de que la ventana del navegador tenga un tamaño adecuado para el contenido que necesitas capturar. Si la ventana es demasiado pequeña, partes de la página pueden ser recortadas.
- Carga completa de la página: Antes de capturar una captura de pantalla, verifica que todas las solicitudes HTTP asíncronas se hayan completado y que la página se haya renderizado completamente. Esto asegura que la captura de pantalla refleje con precisión el estado final de la página.
JavaScript
import fs from 'node';
import { Builder, Browser } from 'selenium-webdriver';
async function screenshot() {
const driver = new Builder()
.forBrowser(Browser.CHROME)
.build();
await driver.get('https://www.yahoo.com/');
const pictureData = await driver.takeScreenshot();
fs.writeFileSync('screenshot.png', pictureData, 'base64');
}
screenshot();4. Uso de Nstbrowser para completar tareas
¿Hay una forma más sencilla de lograr todas
las tareas especializadas? ¡Claro que sí! Nstbrowser proporciona servicios RPA completamente gratuitos. Simplemente configurando el flujo de trabajo que necesitas, puedes lograr fácilmente todos los requisitos de scraping.
Obtener datos de elemento
Esperar solicitud
Captura de pantalla
5. Ejecutar comandos personalizados en JavaScript
Una de las características destacadas de usar una herramienta de automatización de navegador como Selenium es la capacidad de aprovechar el propio motor JavaScript del navegador. Esto significa que puedes inyectar y ejecutar código JavaScript personalizado en el contexto de la página web con la que estás interactuando.
JavaScript
const javascript = 'window.scrollBy(100, 100)';
await driver.executeScript(javascript);Reflexiones finales
En este tutorial de Selenium Node.js, aprendiste cómo usar headlesschrome con Selenium para configurar un proyecto WebDriver en Node.js, hacer scraping de datos de sitios web dinámicos, interactuar con contenido dinámico y abordar desafíos comunes de scraping web.
¡Ahora es un buen momento para construir tu propio proceso de scraping web! Con la ayuda de RPA Nstbrowser, todo lo complejo se simplificará.
Más





