
Browserless
Pyppeteer: Cómo usar Puppeteer en Python con Browserless
¿Qué es Pyppeteer? ¿Cómo podemos integrar Pyppeteer en Browserless? En este blog puedes encontrar pasos detallados para hacer uso completo de Pyppeteer.
Oct 09, 2024Carlos Rivera
¿Qué es Pyppeteer en Python?
Pyppeteer es un puerto de Python de la popular biblioteca Node.js Puppeteer, que se utiliza para controlar navegadores Chrome o Chromium sin cabeza programáticamente.
Esencialmente, Pyppeteer permite a los desarrolladores de Python automatizar tareas dentro de un navegador web, como raspar páginas web, probar aplicaciones web o interactuar con sitios web como si un usuario real lo estuviera haciendo, pero sin una interfaz gráfica.
¿Qué es Browserless?
Browserless es una solución de navegador basada en la nube que permite una automatización eficiente del navegador, raspado de sitios y pruebas.
Utiliza la biblioteca de huellas digitales de Nstbrowser para permitir el cambio aleatorio de huellas digitales, lo que da como resultado una recopilación y automatización de datos fluidas. La robusta infraestructura en la nube de Browserless facilita la gestión de actividades automatizadas al permitir el acceso a varias instancias de navegador simultáneamente.
¿Tienes alguna idea maravillosa y dudas sobre el raspado web y Browserless?
¡Veamos lo que otros desarrolladores están compartiendo en Discord y Telegram!
¿Para qué se puede utilizar Pyppeteer?
Captura de pantalla usando Pyppeteer
Cuando se utiliza Browserless, no se puede ver ninguna pantalla, por lo que cuando necesitamos conocer la pantalla específica del navegador en algunos enlaces, se recomienda que utilice la API de captura de pantalla para obtener la captura de pantalla.
La ejecución del siguiente script generará una captura de pantalla llamada youtube_screenshot.png en la ruta actual del script:
Python
import asyncio
from pyppeteer import connect
async def main():
# Conectarse al navegador
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("¡Conectado!")
# Crear una nueva página
page = await browser.newPage()
# Visitar youtube
await page.goto("https://www.youtube.com/")
# tomar una captura de pantalla
await page.screenshot({"path": "youtube_screenshot.png"})
await page.close()
asyncio.run(main())Interactuar con páginas dinámicas
En los sitios web modernos, se confía en JavaScript para actualizar el contenido dinámicamente. Por ejemplo, las plataformas de redes sociales a menudo usan desplazamiento infinito en sus publicaciones, y la carga de los datos de la página también requiere esperar la respuesta del backend, así como una variedad de operaciones de formulario y varios eventos del navegador.
Sí, Pyppeteer también puede hacer lo mismo: esperar a que se cargue, hacer clic en los botones, ingresar formularios y otras operaciones del navegador.
1. Esperando a que la página se cargue
Las API comúnmente utilizadas para esperar a que se cargue la página son waitForSelector y waitFor.
waitForSelectorse utiliza principalmente para asegurar que un cierto elemento en la página se cargue normalmentewaitForsimplemente espera un tiempo determinado.
Python
import asyncio
from pyppeteer import connect
async def main():
# Conectarse al navegador
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("¡Conectado!")
# Visitar nasa
page = await browser.newPage()
await page.goto("https://www.disney.com/")
# Esperar a que se carguen las noticias
await page.waitForSelector('.content-body')
# esperar otros 2 segundos
await page.waitFor(2000)
# tomar una captura de pantalla
await page.screenshot({"path": "disney.png"})
await page.close()
asyncio.run(main())2. Desplazamiento de la página
En page.evaluate, puede establecer la posición de la barra de desplazamiento llamando a la API de la ventana, lo que es muy conveniente.
Python
import asyncio
from pyppeteer import connect
async def main():
# Conectarse al navegador
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("¡Conectado!")
# Visitar HBO Max
page = await browser.newPage()
await page.goto('https://www.max.com/');
# Desplazarse hasta el final
await page.evaluate("window.scrollTo(0, document.documentElement.scrollHeight)");
# tomar una captura de pantalla
await page.screenshot({"path": "HBOMax.png"})
await page.close()
asyncio.run(main())3. Hacer clic en el botón
En Python Pyppeteer, podemos usar page.click para hacer clic en un botón o hipervínculo. Establecer el retraso de entrada lo hace más parecido a la operación de un usuario real.
El siguiente es un ejemplo simple.
Python
import asyncio
from pyppeteer import connect
async def main():
# Conectarse al navegador
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("¡Conectado!")
page = await browser.newPage()
await page.goto("https://example.com/")
# hacer clic en el enlace
await page.click("p > a", {"delay": 200})
# tomar una captura de pantalla
await page.screenshot({"path": "example.png"})
await page.close()
asyncio.run(main())4. Entrada de formulario
¿Cómo ingresar datos usando Python Pyppeteer? Por favor, use el page.type para ingresar contenido en el cuadro de entrada especificado.
Python
import asyncio
from pyppeteer import connect
async def main():
# Conectarse al navegador
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("¡Conectado!")
# Crear una nueva página
page = await browser.newPage()
# Visitar el desarrollador de Chrome
await page.goto("https://developer.chrome.com/")
await page.setViewport({"width": 1920, "height": 1080})
# Ingresar contenido en el cuadro de búsqueda
await page.type(".devsite-search-field", "headless", {"delay": 200})
# tomar una captura de pantalla
await page.screenshot({"path": "developer.png"})
await page.close()
asyncio.run(main())Iniciar sesión usando Pyppeteer
Después de los ejemplos anteriores, podemos pensar fácilmente en las interacciones involucradas en el inicio de sesión, como la operación de tipo de entrada y la operación de clic del botón.
Entonces, en el siguiente ejemplo, cambiemos el método de escritura. Intentaremos iniciar sesión en Nstbrowser Client. Después de iniciar sesión, tomaré una captura de pantalla para verificar si es exitosa.
Python
import asyncio
from pyppeteer import connect
async def main():
# Conectarse al navegador
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("¡Conectado!")
# Visitar Nstbrowser Client
page = await browser.newPage()
await page.goto("https://app.nstbrowser.io/account/login")
await page.waitForSelector("input")
inputs = await page.querySelectorAll("input")
# Ingresar su dirección de correo electrónico en el primer cuadro de entrada
await inputs[0].type("[email protected]", delay=100)
# Ingresar su contraseña en el segundo cuadro de entrada
await inputs[1].type("9KLYUWn3GmrzHPRGQl0EZ1QP3OWPFwcB", delay=100)
buttons = await page.querySelectorAll("button")
# Hacer clic en el botón de inicio de sesión
await buttons[1].click()
# Esperando la respuesta de la solicitud de inicio de sesión
login_url = "https://api.nstbrowser.io/api/v1/passport/login"
await page.waitForResponse(lambda res: res.url == login_url)
await page.waitFor(2000)
# tomar una captura de pantalla
await page.screenshot({"fullPage": True, "path": "./nstbrowser.png"})
await page.close()
asyncio.run(main())- Resultado de la ejecución:
¡Podemos ver que nuestro proyecto ha sido redirigido a la página de inicio, lo que indica que hemos iniciado sesión en Nstbrowser correctamente!
Cómo usar Pyppeteer en Browserless?
¿Podría Pyppeteer funcionar con Browserless?
Definitivamente, puede encontrar los pasos específicos para integrar Pyppeteer en Browserless.
Paso 1: Obtener la API KEY
Antes de comenzar, necesitamos tener un servicio Browserless. El uso de Browserless puede resolver tareas complejas de rastreo web y automatización a gran escala, y ahora ha logrado una implementación en la nube totalmente administrada.
Browserless adopta un enfoque centrado en el navegador, proporciona potentes capacidades de implementación sin cabeza y ofrece un mayor rendimiento y confiabilidad. Para obtener más información sobre Browserless, puede hacer clic aquí para obtener más información.
Obtenga la API KEY y vaya a la página de menú Browserless del cliente Nstbrowser, o puede hacer clic aquí para acceder
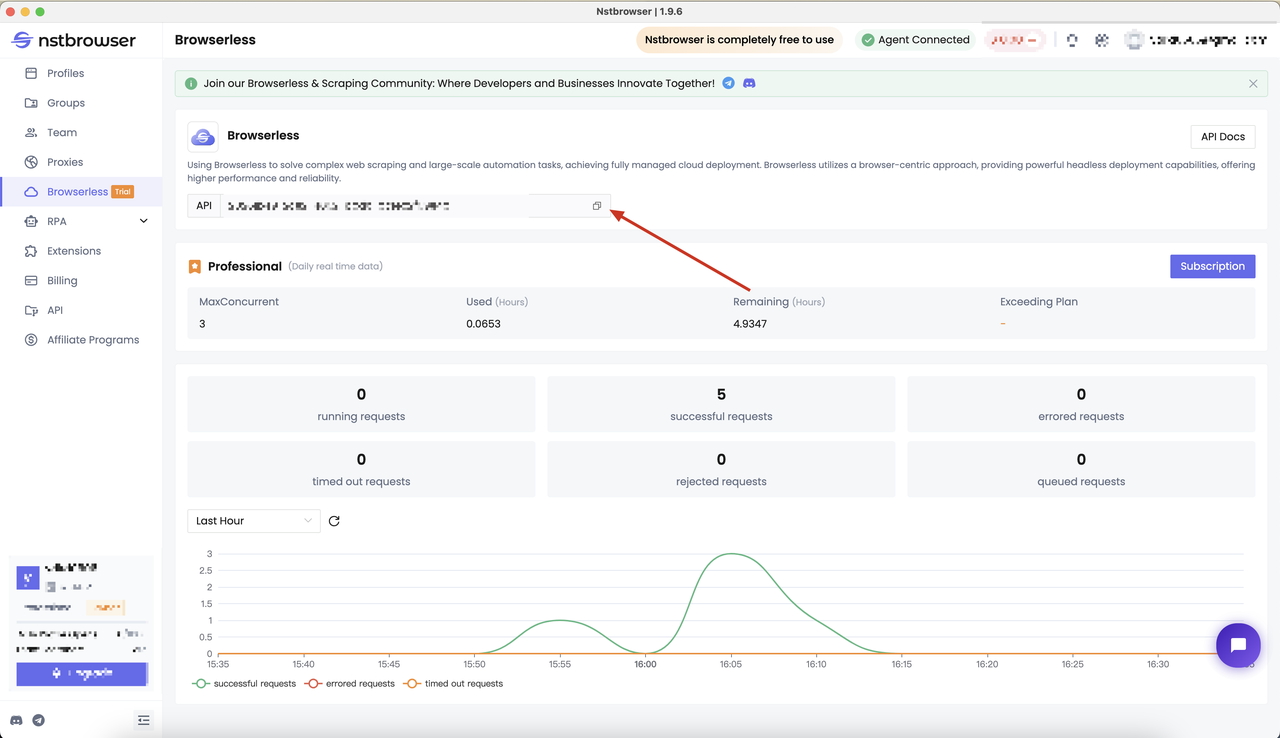
Paso 2: Instalar Pyppeteer
Pyppeteer es la versión de Python de Puppeteer, que proporciona una funcionalidad similar y permite a los desarrolladores controlar navegadores sin cabeza utilizando scripts de Python. Permite a los desarrolladores automatizar las interacciones con las páginas web a través del código de Python y se usa muy comúnmente en escenarios como rastreadores, pruebas y captura de datos.
Plain Text
pip install pyppeteerPaso 3: Conectar Pyppeteer a Browserless
Necesitamos preparar el siguiente código. Simplemente complete su API key y proxy para conectarse a Browserless.
Python
from urllib.parse import urlencode
import json
token = "your api key" # 'required'
config = {
"proxy": "your proxy", # required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
# "platform": "windows", # support: windows, mac, linux
# "kernel": 'chromium', # only support: chromium
# "kernelMilestone": '128', # support: 128
# "args": {
# "--proxy-bypass-list": "detect.nstbrowser.io"
# }, # browser args
# "fingerprint": {
# userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', # userAgent supportted since v0.15.0
# },
}
query = urlencode({"token": token, "config": json.dumps(config)})
browser_ws_endpoint = f"ws://less.nstbrowser.io/connect?{query}"¡Conectado y comencemos a raspar!
Python
import asyncio
from pyppeteer import connect
async def main():
# Conectarse al navegador
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("¡Conectado!")
asyncio.run(main())Paso 4: Utilizar Pyppeteer en el Browserless
En este blog, profundizaremos en un caso simple para ayudarlo a comenzar rápidamente con Browserless - rastrear Books to Scrape.
En el siguiente ejemplo, intentamos rastrear todos los títulos de los libros en la página actual:
- Abra la página
- Espere a que la página se cargue normalmente
- Abra la consola de depuración
- Determine el elemento HTML correspondiente al título del libro en cualquier ubicación:
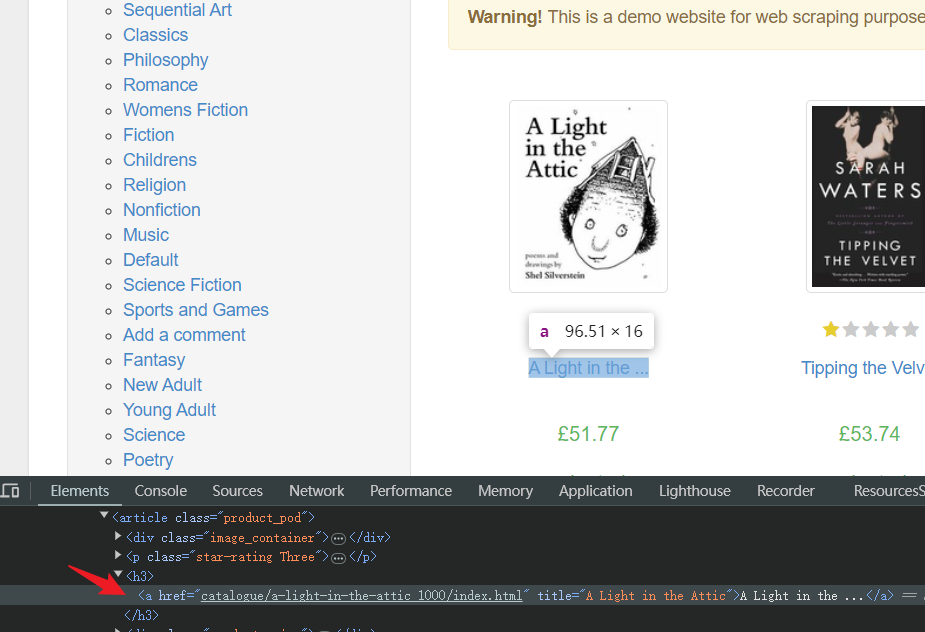
- Scripts:
Python
import asyncio
from pyppeteer import connect
async def main():
# Conectarse al navegador
browser = await connect(browserWSEndpoint=browser_ws_endpoint)
print("¡Conectado!")
# Crear una nueva página
page = await browser.newPage()
# Visitar Books to Scrape
await page.goto("http://books.toscrape.com/")
# Esperar a que se cargue la lista de libros
await page.waitForSelector("section")
# Seleccionar todos los elementos del título del libro
books = await page.querySelectorAll("article.product_pod > h3 > a")
# recorrer todos los elementos para extraer títulos
for book in books:
title_element = await book.getProperty("textContent")
title = await title_element.jsonValue()
print(f"[{title}]")
await page.close()
# Ejecutar el script
asyncio.run(main())- Resultados:
Ejecutar el script anterior imprimirá todos los datos capturados en la consola:
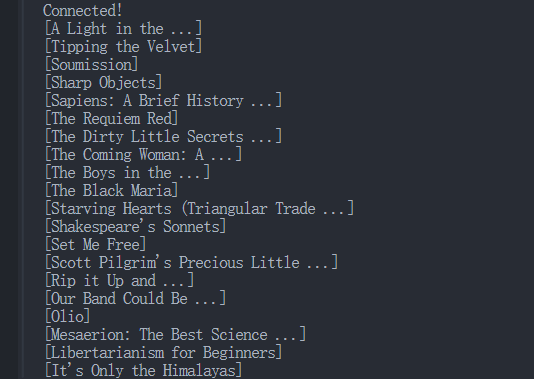
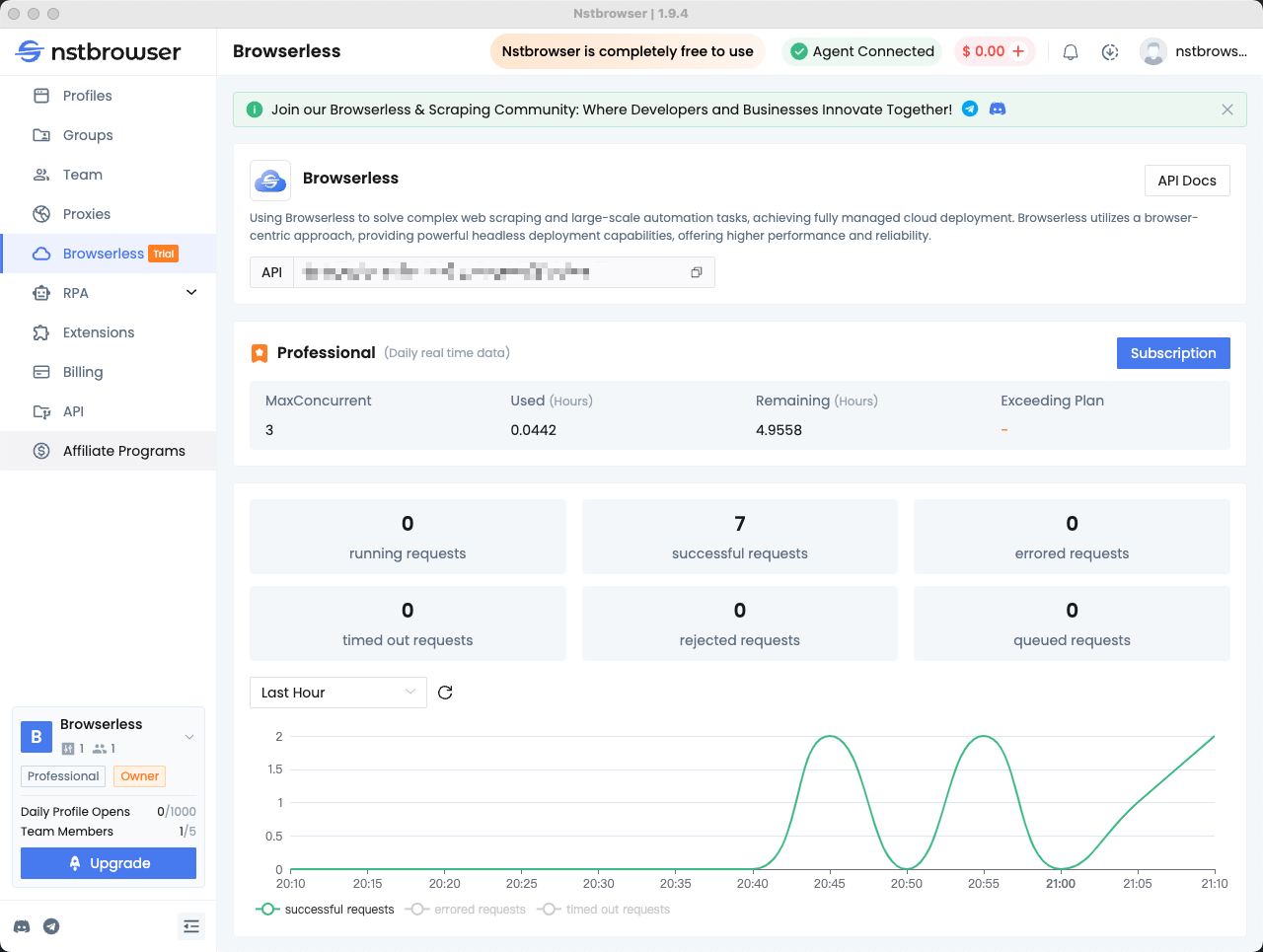
Paso 5: Verificar los datos en el panel de Browserless
Puede ver las estadísticas de las solicitudes recientes y el tiempo de sesión restante en el menú Browserless del cliente Nstbrowser.
Errores comunes al usar Pyppeteer
La mayoría de los desarrolladores pueden encontrar algunos errores al configurar y usar Pyppeteer. ¡No te preocupes! Aquí puedes encontrar cómo solucionarlos.
Error 1: No se puede instalar Pyppeteer
Mientras instala Pyppeteer, puede encontrar el error "No se puede instalar Pyppeteer".
Por favor, compruebe la versión de Python en su sistema. Pyppeteer solo admite Python 3.6+. Por lo tanto, intente actualizar Python y reinstalar Pyppeteer.
Error 2: El navegador Pyppeteer se cerró inesperadamente
Es posible que encuentre este error: pyppeteer.errors.BrowserError: Browser closed unexpectedly cuando ejecute un script de Python de Pyppeteer por primera vez después de la instalación.
Esto significa que todas las dependencias de Chromium no están completamente instaladas. Por favor, instale el controlador de Chrome manualmente usando el siguiente comando:
Plain Text
pyppeteer-installNotas para llevar
Pyppeteer es un puerto de Python no oficial de la clásica biblioteca Node.js Puppeteer. Es un paquete fácil de instalar, ligero y rápido para la automatización web y el raspado de sitios web dinámicos.
En este blog, has aprendido:
- ¿Qué es Pyppeteer?
- Pasos específicos para integrar Pyppeteer con Browserless.
- Otros casos de uso de Pyppeteer.
Si desea obtener más información sobre las características de Browserless, consulte el manual oficial. Nstbrowser le proporciona el mejor navegador en la nube para resolver las limitaciones locales del trabajo de automatización.
Más





