
Paquete de Proxies hasta75% DTO+15% Bonocon

¿Headless? Sí, eso significa que este navegador no tiene una interfaz gráfica de usuario (GUI). En lugar de usar un mouse o un dispositivo táctil para interactuar con los elementos visuales, utilizas una interfaz de línea de comandos (CLI) para realizar automatizaciones.
Existen muchas herramientas de raspado web disponibles para headlesschrome, y headlesschrome generalmente elimina muchos dolores de cabeza.
También te puede interesar: ¿Cómo detectar y evitar la detección de headlesschrome?
¿Qué es Puppeteer? Es una biblioteca de Node.js que proporciona una API de alto nivel para controlar headlesschrome o Chromium o interactuar con el Protocolo DevTools.
Hoy exploraremos headlesschrome en profundidad con Puppeteer.
Como puedes imaginar, hay varias grandes ventajas al usar Puppeteer para el raspado web:
En el siguiente ejemplo, realizaremos un raspado web básico para ayudarte a comenzar rápidamente con Puppeteer. La página que elegimos para rastrear es la sección de reseñas de Apple AirPods Pro de Amazon.
Pero no te preocupes, antes de eso, aún necesitamos algo de preparación:
Si no lo tienes, instala Node.js (LTS) directamente y luego instala Puppeteer a través del gestor de paquetes npm de Node.js. Este proceso puede ser un poco largo porque Puppeteer también necesita instalar el Chrome correspondiente.
npm i puppeteerTambién puedes usar este demo para obtener una comprensión general de Puppeteer. No te quedes atascado aquí, porque más adelante presentaremos el uso de Puppeteer y escenarios relacionados en detalle.
Puppeteer está habilitado en modo headless por defecto. Aquí, headless está desactivado a través de puppeteer.launch({ headless: false }) para que puedas ver el proceso de rastreo.
import puppeteer from 'puppeteer';
// Inicia tu navegador y abre una nueva pestaña
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Navega a una URL especificada
await page.goto('https://developer.chrome.com/');
// Establece el tamaño de la pantalla
await page.setViewport({width: 1080, height: 1024});
// Localiza el elemento del cuadro de búsqueda e ingresa el contenido en el cuadro de búsqueda
await page.locator('.devsite-search-field').fill('automate beyond recorder');
// Espera y haz clic en el primer resultado de búsqueda
await page.locator('.devsite-result-item-link').click();
// Localiza el título completo usando una cadena única
const textSelector = await page
.locator('text/Customize and automate')
.waitHandle();
const fullTitle = await textSelector?.evaluate(el => el.textContent);
// Imprime el título completo
console.log('El título de esta publicación del blog es "%s".', fullTitle);
// Cierra la instancia del navegador
await browser.close();Puppeteer es una biblioteca asincrónica basada en promesas que se ejecuta a través de async await, lo que puede presentar sus funciones de manera muy intuitiva. El demo anterior y los ejemplos siguientes no necesitan funciones async. Esto es porque el "type": "module" en package.json está configurado para ejecutarse como módulos ES.
Bien, empecemos.
Por favor, abre la sección de comentarios de Apple AirPods Pro primero, y luego necesitamos identificar los elementos en los que queremos capturar el contenido. Puedes abrir las Herramientas de Desarrollador presionando Ctrl + Shift + I (Windows/Linux) o Cmd + Option + I (Mac).
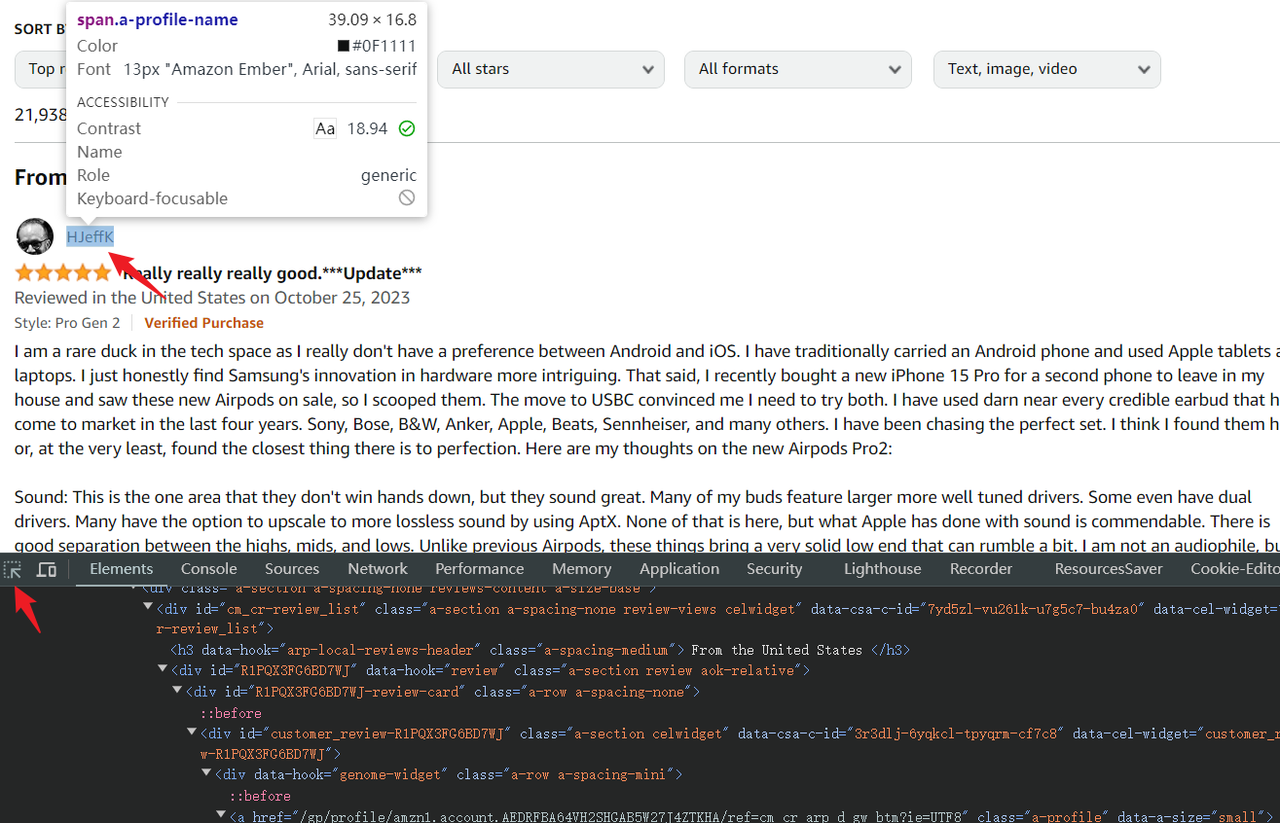
Puppeteer soporta múltiples métodos de selección de elementos (selectores de puppeteer), pero el método más recomendado para comenzar es el CSS simple. El .devsite-search-field usado arriba también es un selector CSS.
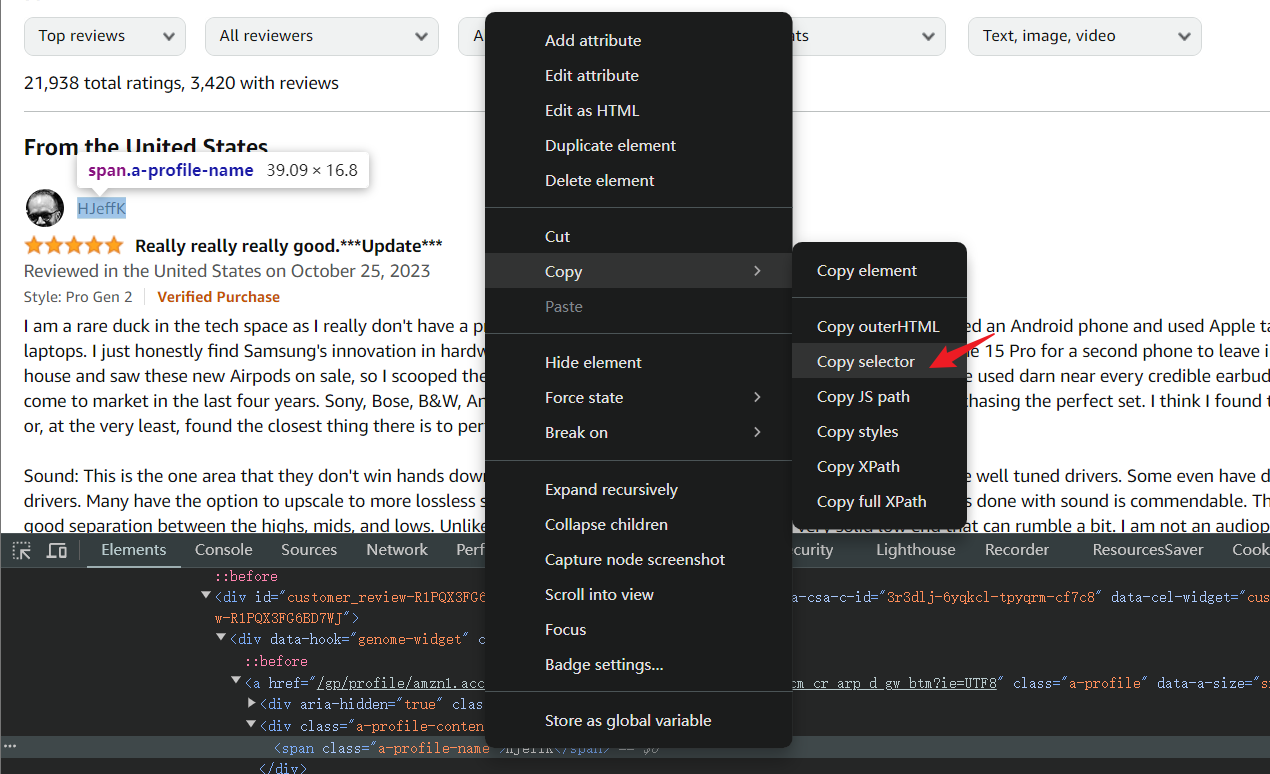
Para estructuras CSS complejas, la consola de depuración puede copiar directamente los selectores CSS. Haz clic derecho en el HTML del elemento que necesita ser capturado para abrir el menú > Copiar > Copiar selector.
Pero no se recomienda hacer esto, ya que los selectores copiados de estructuras complejas son muy poco legibles y no son propicios para el mantenimiento del código. Por supuesto, está completamente bien para algunas selecciones simples y pruebas personales y aprendizaje.
Ahora, el selector de elementos ha sido determinado. Podemos usar Puppeteer para intentar capturar el nombre de usuario que seleccioné arriba.
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(
`https://www.amazon.com/Apple-Generation-Cancelling-Transparency-Personalized/product-reviews/B0CHWRXH8B/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews`
);
const username = await page.$eval('div[data-hook="genome-widget"] .a-profile-name', node => node.textContent)
console.log('[username]===>', username);Como puedes ver, el código anterior usa page.goto para saltar a la página especificada. Luego page.$eval puede obtener el primer nodo de elemento coincidente y obtener los atributos específicos del nodo del elemento a través de una función de callback.
Si tienes la suerte de no activar la página de verificación de Amazon, puedes obtener el valor con éxito. Sin embargo, un script estable no puede depender solo de la suerte, por lo que aún necesitamos hacer algunas optimizaciones a continuación.
Aunque hemos obtenido la información del nodo del elemento a través del método anterior, debemos considerar otros factores: como la velocidad de carga de la red, si la página se desplaza hasta el elemento objetivo para cargar el elemento correctamente y si se activa una página de verificación que necesita ser manejada manualmente.
Entonces, antes de que se complete la carga, debemos esperar pacientemente. Por supuesto, Puppeteer también nos proporciona APIs correspondientes para usar.
El waitForSelector comúnmente utilizado es una API que espera a que el elemento aparezca. Podemos usarlo para optimizar el código anterior para asegurar la estabilidad del script. Solo usa la API waitForSelector antes de llamar a page.$eval.
De esta manera, Puppeteer esperará a que la página cargue el elemento div[data-hook="genome-widget"] .a-profile-name antes de ejecutar el código subsecuente.
await page.waitForSelector('div[data-hook="genome-widget"] .a-profile-name');
const username = await page.$eval('div[data-hook="genome-widget"] .a-profile-name', node => node.textContent)También hay otras APIs de espera para diferentes escenarios. Veamos algunas comunes:
page.waitForFunction(pageFunction, options, ...args): Espera a que la función especificada devuelva true en el contexto de la página.import puppeteer from 'puppeteer'
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
// Espera a que el `window.title` de la página cambie a "Example Domain"
await page.waitForFunction('document.title === "Example Domain"');
console.log('El título ha cambiado a "Example Domain"');
await browser.close();page.waitForNavigation(options): Espera a que se complete la navegación de la página. La navegación puede ser haciendo clic en un enlace, enviando un formulario, llamando a window.location, etc.import puppeteer from 'puppeteer';
const browser = await puppeteer.launch();
const page = await browser.new
Page();
await page.goto('https://example.com');
// Haz clic en el enlace y espera a que la navegación se complete
await Promise.all([
page.click('a'),
page.waitForNavigation()
])
console.log('Navegación completa');
await browser.close();page.waitForRequest(urlOrPredicate, options): Espera a que se realicen solicitudes que coincidan con la URL especificada o una función condicional.import puppeteer from "puppeteer";
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://example.com');
// La solicitud requiere que monitorees la URL de la solicitud de la página real. Esto es solo un ejemplo.
// Pero puedes ingresar manualmente https://example.com/resolve en la barra de direcciones del navegador para activar la solicitud y verificar este demo.
const Request = await page.waitForRequest('https://example.com/resolve');
console.log('request-url:', Request.url());
await browser.close()page.waitForResponse(urlOrPredicate, options): Espera a que una respuesta coincida con la URL especificada o una función condicional.import puppeteer from "puppeteer";
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://example.com');
// La respuesta requiere que monitorees la URL de la respuesta de la página real. Esto es solo un ejemplo.
// Pero puedes ingresar manualmente https://example.com/resolve en la barra de direcciones del navegador para activar la respuesta y verificar este demo.
const response = await page.waitForResponse('https://example.com/resolve');
console.log('response-status:', response.status());
await browser.close();page.waitForNetworkIdle(options): Espera a que la actividad de la red en la página se vuelva inactiva. Este método es útil para asegurarse de que la página haya terminado de cargar.import puppeteer from "puppeteer";
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.waitForNetworkIdle({
timeout: 30000, // Tiempo máximo de espera de 30 segundos
idleTime: 500 // Es decir, no hay actividad de red dentro de 500 milisegundos de tiempo de inactividad
});
console.log('La red está inactiva.');
// Guarda una captura de pantalla para verificar si la página se ha cargado completamente
await page.screenshot({ path: 'example.png' });
await browser.close();setTimeout: Usar directamente la API de Javascript también es una buena opción. Después de un pequeño empaquetado, puede ejecutarse en el contexto de la página.// Espera dos segundos antes de ejecutar el script subsecuente
await new Promise(resolve => setTimeout(resolve, 2000))
await page.click('.devsite-result-item-link'); // Haz clic en este elemento¿Tienes alguna idea maravillosa o dudas sobre el raspado web y el uso de navegadores sin interfaz gráfica?
¡Veamos lo que otros desarrolladores están compartiendo en Discord y Telegram!
Bien, comencemos a raspar los datos completos de la lista de comentarios de la página.
Podemos reescribir el código anterior para no solo rastrear un solo nombre de usuario, sino enfocarnos en toda la lista de comentarios.
El siguiente código también utiliza page.waitForSelector para esperar a que el elemento de comentario se cargue, y usa page.$$ para obtener todos los nodos de elementos que coinciden con el selector de elementos:
await page.waitForSelector('div[data-hook="review"]');
const reviewList = await page.$$('div[data-hook="review"]');A continuación, necesitamos recorrer la lista de elementos de comentarios y obtener la información que necesitamos de cada elemento de comentario.
En el siguiente código, podemos obtener el textContent del título, la calificación, el nombre de usuario y el contenido, y obtener el valor del atributo data-src en el nodo del elemento del avatar, que es la dirección URL del avatar.
for (const review of reviewList) {
const title = await review.$eval(
'a[data-hook="review-title"] .cr-original-review-content',
node => node.textContent,
);
const rate = await review.$eval(
'i[data-hook="review-star-rating"] .a-icon-alt',
node => node.textContent,
);
const username = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-name',
node => node.textContent,
);
const avatar = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-avatar img',
node => node.getAttribute('data-src'),
);
const content = await review.$eval(
'span[data-hook="review-body"] span',
node => node.textContent,
);
console.log('[log]===>', { title, rate, username, avatar, content });
}Al ejecutar el código anterior, deberías poder ver la información del registro impresa en la terminal.
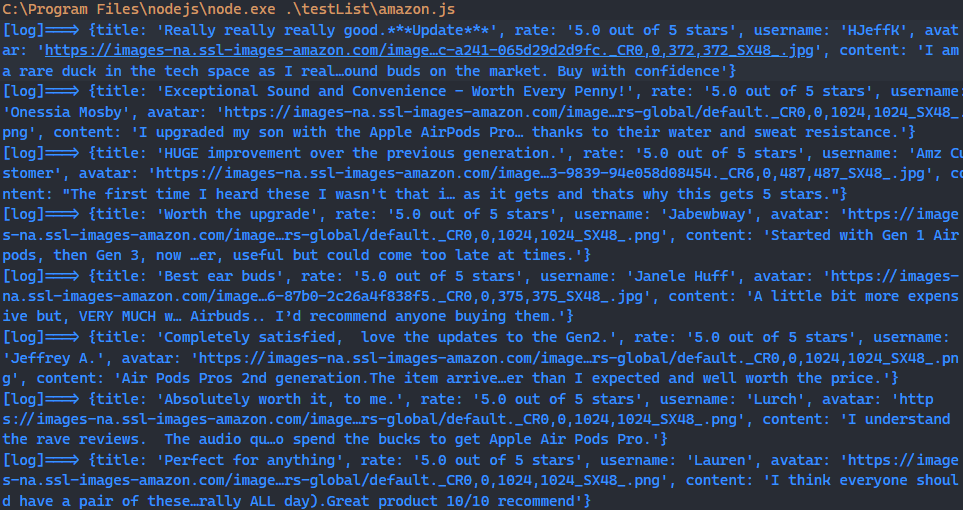
Si deseas almacenar estos datos, puedes usar el módulo básico de nodejs fs para escribir los datos en un archivo JSON para tu análisis posterior.
A continuación, se muestra una función de utilidad simple:
import fs from 'fs';
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`Archivo guardado con éxito: ${filename}`);
});
}El código completo es el siguiente. Después de ejecutarlo, podrás encontrar el archivo amazon_reviews_log.json en la ruta de ejecución del script actual. ¡Este archivo registra todos tus resultados de raspado!
import puppeteer from 'puppeteer';
import fs from 'fs';
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(
`https://www.amazon.com/Apple-Generation-Cancelling-Transparency-Personalized/product-reviews/B0CHWRXH8B/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews`
);
await page.waitForSelector('div[data-hook="review"]');
const reviewList = await page.$$('div[data-hook="review"]');
const reviewLog = []
for (const review of reviewList) {
const title = await review.$eval(
'a[data-hook="review-title"] .cr-original-review-content',
node => node.textContent,
);
const rate = await review.$eval(
'i[data-hook="review-star-rating"] .a-icon-alt',
node => node.textContent,
);
const username = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-name',
node => node.textContent,
);
const avatar = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-avatar img',
node => node.getAttribute('data-src'),
);
const content = await review.$eval(
'span[data-hook="review-body"] span',
node => node.textContent,
);
console.log('[log]===>', { title, rate, username, avatar, content });
reviewLog.push({ title, rate, username, avatar, content })
}
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`Archivo guardado con éxito: ${filename}`);
});
}
saveObjectToJson(reviewLog, 'amazon_reviews_log.json')
await browser.close()¿Entendiste el uso básico mencionado anteriormente? Ahora, podemos continuar explorando las poderosas funciones de Puppeteer. Después de ejecutar los siguientes ejemplos, creo que tendrás una nueva comprensión de esta herramienta.
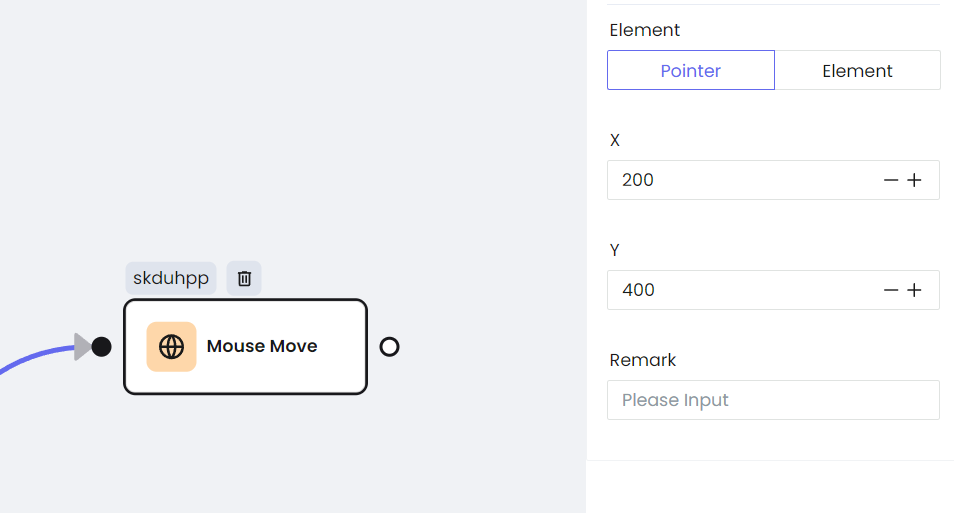
Utiliza page.mouse.move para operar el movimiento de tu ratón.
Para que puedas sentir que el cursor se está moviendo en la página, el siguiente demo es un bucle infinito, lo que hará que el ratón se mueva aleatoriamente para activar el estilo de desplazamiento de la página.
Cabe destacar que, para activar el estilo de desplazamiento, el ratón no debe moverse demasiado rápido. Configura la tasa de movimiento steps: 10 en el método move. Y este paso también puede reducir la probabilidad de que el sitio web detecte tu actividad.
Page.evaluate es una API muy útil que te permite ejecutar código JavaScript que solo se ejecuta en el entorno del navegador en el contexto de la página, como usar la API de window. El propósito aquí es desplazarse hasta la parte inferior de la página para que se carguen completamente los comentarios.
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://www.google.com');
// Obtener el ancho y la altura de la pantalla
const { width, height } = await page.evaluate(() => {
return { width: window.innerWidth, height: window.innerHeight };
});
// Bucle infinito, simular movimiento aleatorio del ratón
while (true) {
const x = Math.floor(Math.random() * width);
const y = Math.floor(Math.random() * height);
await page.mouse.move(x, y, { steps: 10 });
console.log(`Posición del ratón: (${x}, ${y})`);
await new Promise(resolve => setTimeout(resolve, 200)); // Se mueve cada 0.2 segundos
}También encontramos esto en el demo inicial. ¿Qué tal cambiar la forma de escribir y usar algunas otras APIs para implementarlo?
Puedes ver que algunos selectores a continuación están precedidos por >>>, que es el Selector de Shadow DOM proporcionado por Puppeteer. La mayoría de las operaciones se configuran con un activador de retardo a través de delay, lo que puede simular bien el comportamiento de personas reales. Esto hace que tu script sea más estable y evita activar el mecanismo anti-raspado de algunos sitios web.
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({
headless: false,
// defaultView establece el ancho y la altura en 0, lo que significa que el contenido de la página web llena toda la ventana.
defaultViewport: { width: 0, height: 0 }
});
const page = await browser.newPage();
await page.goto('https://developer.chrome.com/docs/css-ui?hl=de');
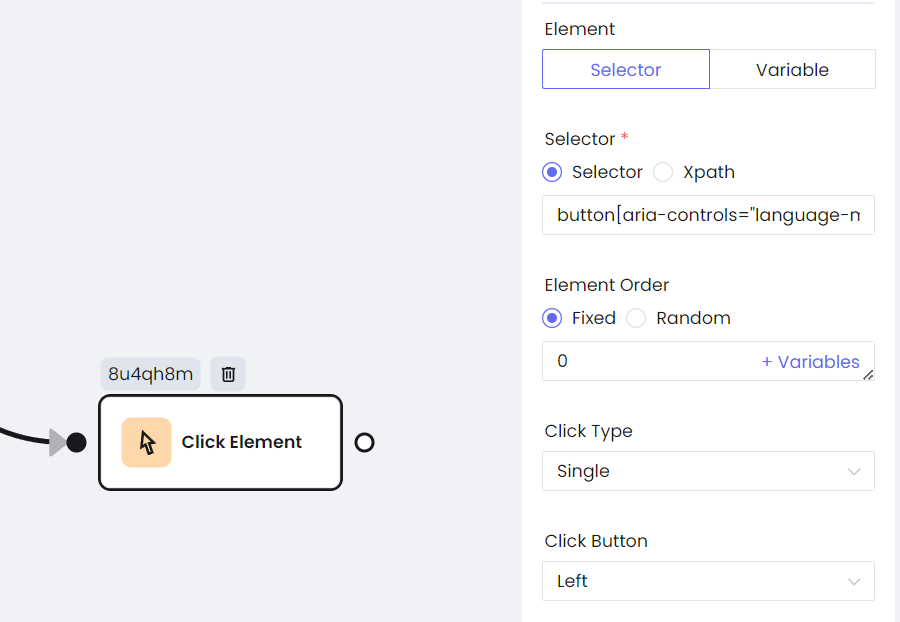
await page.click('>>> button[aria-controls="language-menu"]', { delay: 500 });
// Saltar a una nueva página y esperar a que el salto tenga éxito
await Promise.all([
page.click('>>> li[role="presentation"]', { delay: 500 }),
page.waitForNavigation(),
])
// Usar setTimeout como retraso para esperar 2 segundos a que se cargue la página
await new Promise(resolve => setTimeout(resolve, 2000))
// Enfocar en la caja de búsqueda
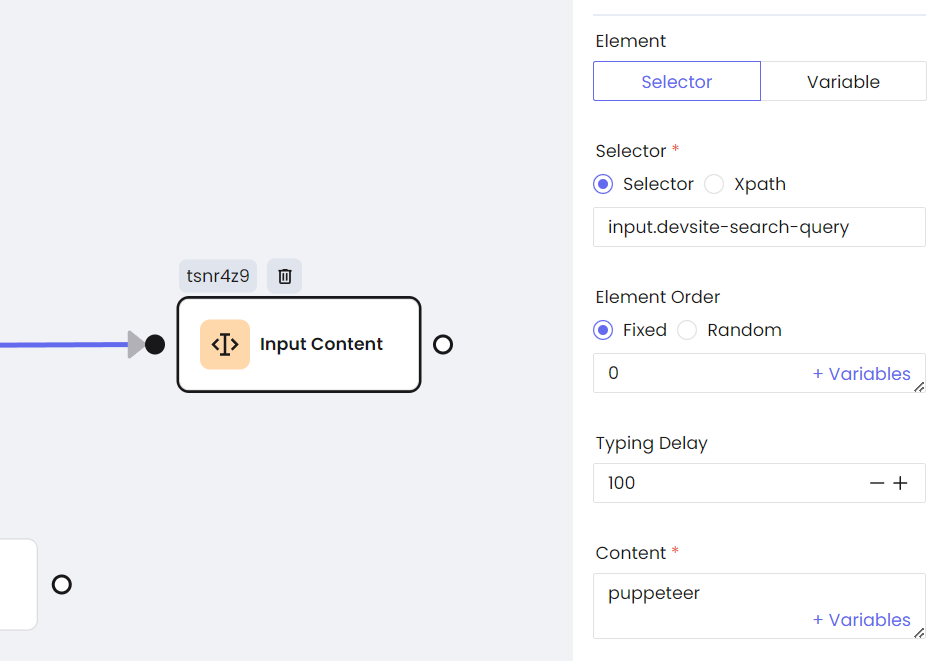
await page.focus('input.devsite-search-query', { delay: 500 });
// Ingresar texto a través del teclado
await page.keyboard.type('puppeteer', { delay: 200 });
// Activar la tecla Enter del teclado y enviar el formulario
await page.keyboard.press('Enter')
console.log('formulario enviado con éxito');
await page.close()Puppeteer proporciona una API de captura de pantalla lista para usar, que es una característica muy práctica que hemos visto en los ejemplos anteriores.
La calidad del archivo de captura de pantalla se puede controlar bien a través de la calidad, y clip se utiliza para recortar la imagen. Si tienes requisitos específicos para la proporción de la captura de pantalla, también puedes configurar defaultViewport para lograrlo.
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ defaultViewport: { width: 1920, height: 1080 } });
const page = await browser.newPage();
await page.goto('https://www.youtube.com/');
await page.screenshot({ path: 'screenshot1.png', });
await page.screenshot({ path: 'screenshot2.jpeg', quality: 50 });
await page.screenshot({ path: 'screenshot3.jpeg', clip: { x: 0, y: 0, width: 150, height: 150 } });
console.log('captura de pantalla guardada');
await browser.close();Para interceptar solicitudes, primero necesitas usar setRequestInterception para activar la intercepción de solicitudes. Ejecuta el siguiente demo y te sorprenderás al ver que el estilo de la página desaparece, y las imágenes y los íconos también desaparecen.
Esto se debe a que la solicitud se monitorea a través de la página, y el resourceType y la url de interceptedRequest se utilizan para determinar si se cancela o se reescribe la solicitud correspondiente.
Debemos tener en cuenta que el método isInterceptResolutionHandled debe llamarse antes de procesar la intercepción de solicitudes para evitar un procesamiento repetido de las solicitudes o conflictos.
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Activar la intercepción de solicitudes
await page.setRequestInterception(true);
page.on('request', interceptedRequest => {
// Evitar que la solicitud se procese repetidamente
if (interceptedRequest.isInterceptResolutionHandled()) return;
// Interceptar la solicitud y reescribir la respuesta
if (interceptedRequest.url().includes('https://fonts.gstatic.com/')) {
interceptedRequest.respond({
status: 404,
contentType: 'image/x-icon',
})
console.log('solicitud de íconos bloqueada');
// Bloquear la solicitud de estilo
} else if (interceptedRequest.resourceType() === 'stylesheet') {
interceptedRequest.abort();
console.log('solicitud de hoja de estilo bloqueada');
// Bloquear la solicitud de imagen
} else if (interceptedRequest.resourceType() === 'image') {
interceptedRequest.abort();
console.log('solicitud de imagen bloqueada');
} else {
interceptedRequest.continue();
}
});
await page.goto('https://www.youtube.com/');Por supuesto, las funciones anteriores también se pueden lograr con la ayuda de algunas herramientas, como usar Nstbrowser RPA para hacer que tu scraper sea más rápido.
Paso 1. Ve a la página principal de Nstbrowser y haz clic en RPA/Workflow > crear workflow.
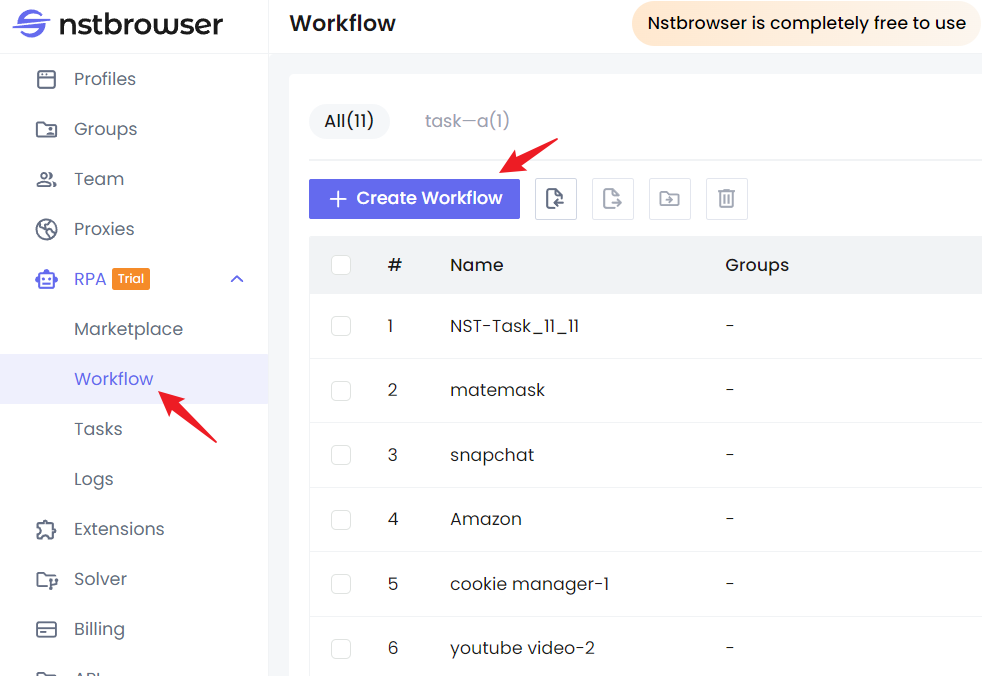
Paso 2. Después de ingresar a la página de edición del workflow, puedes reproducir directamente las funciones anteriores arrastrando el ratón.
El Nodo en la izquierda puede satisfacer casi todas tus necesidades de automatización o scraper, y estos nodos son altamente consistentes con la API de Puppeteer.
Puedes calibrar el orden de ejecución de estos nodos conectándolos como ejecutar código asíncrono en Javascript. Si conoces Puppeteer, puedes comenzar rápidamente con la función de RPA de Nstbrowser. Es tal cual como lo ves.
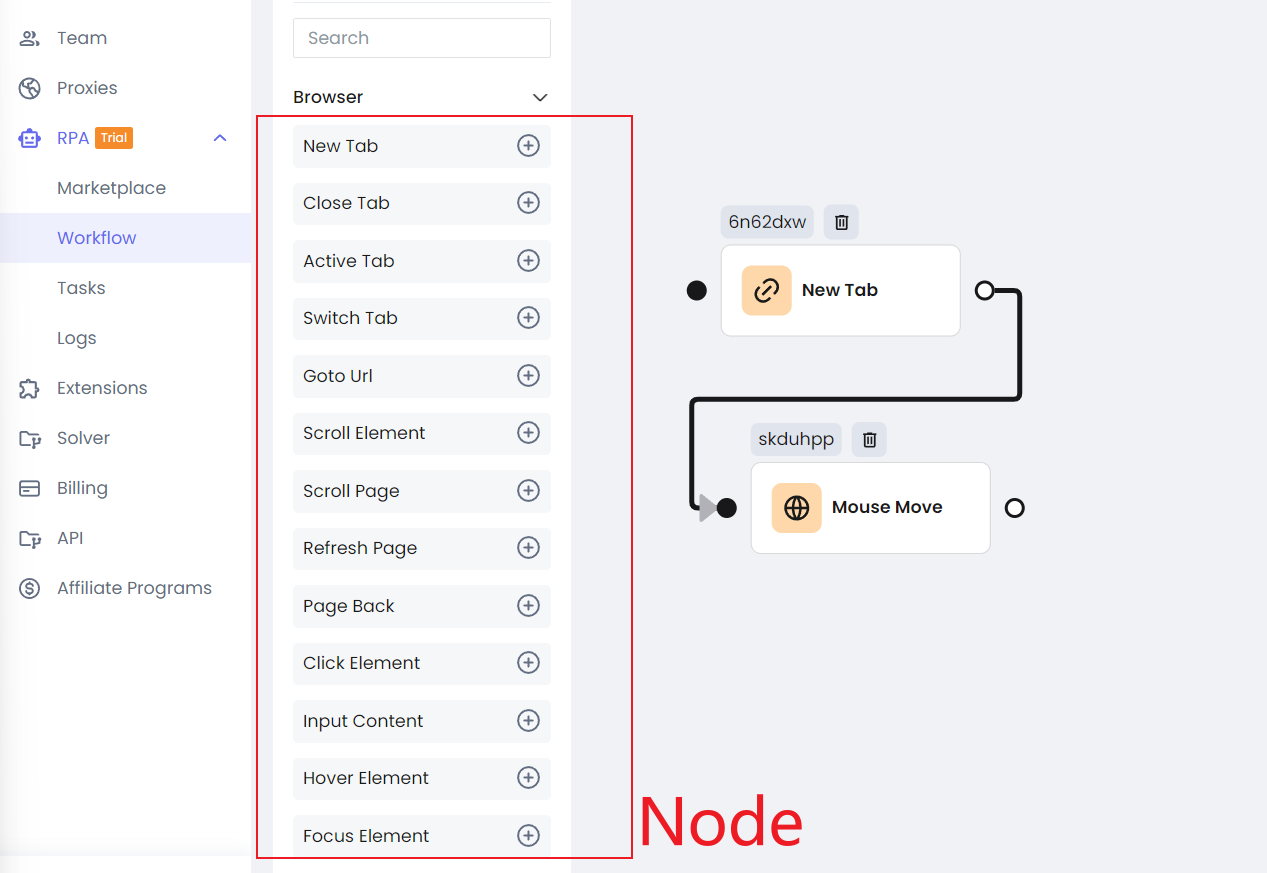
Paso 3. Cada Nodo se puede configurar individualmente, y la información de configuración casi corresponde a la configuración de Puppeteer.
a. Movimiento del ratón
b. Hacer clic en el botón
c. Entrada de datos
d. Teclas del teclado
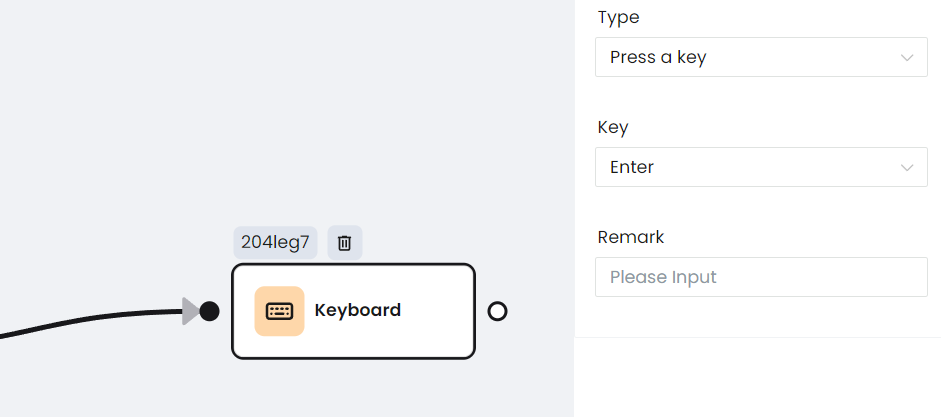
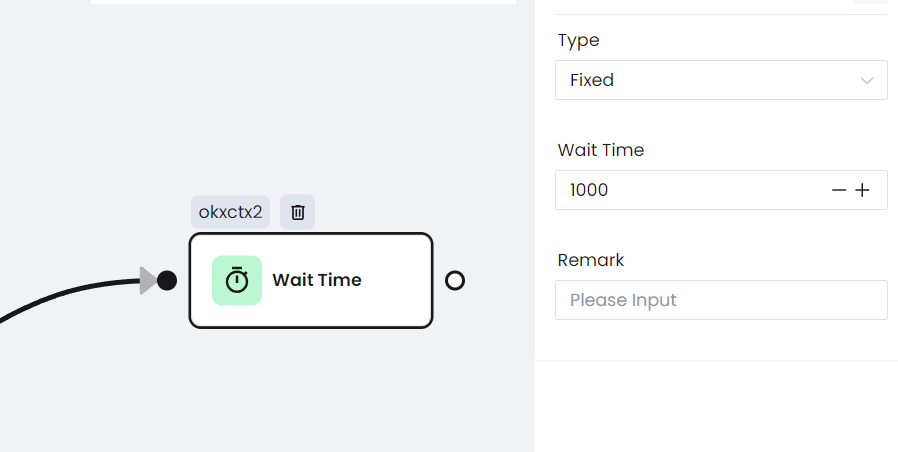
e. Esperar una respuesta
f. Captura de pantalla
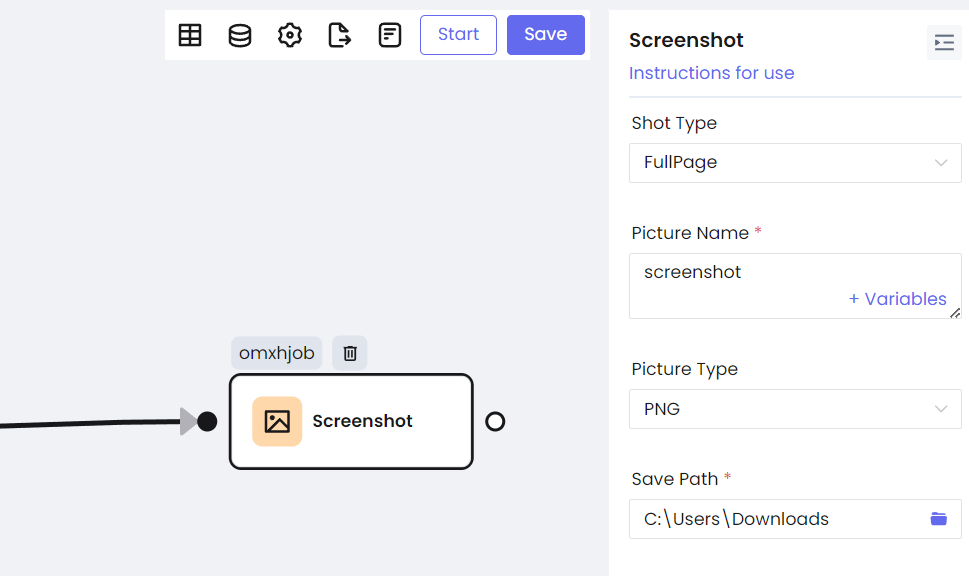
Además, Nstbrowser RPA tiene nodos más comunes y únicos. Puedes realizar operaciones comunes de scraping con un simple arrastre y soltado.
Los encabezados HTTP son información adicional intercambiada entre el cliente (navegador) y el servidor. Contienen metadatos para solicitudes y respuestas, como el tipo de contenido, el agente de usuario, las configuraciones de idioma, etc.
Los encabezados HTTP comunes incluyen:
User-Agent: Identifica el tipo de aplicación cliente, el sistema operativo, la versión del software y otra información.Accept-Language: Indica el idioma que el cliente puede entender y su prioridad.Referer: Indica la página de origen de la solicitud.Al modificar estos encabezados, puedes disfrazarte como un navegador o sistema operativo diferente, reduciendo así el riesgo de ser detectado como un robot.
Cuando usas Puppeteer, puedes usar el método page.setExtraHTTPHeaders para establecer los encabezados antes de acceder a la página web:
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Configurar encabezados HTTP personalizados
await page.setExtraHTTPHeaders({
'Accept-Language': 'es-ES,es;q=0.9',
'Referer': 'https://www.google.com',
'MyHeader': 'hola puppeteer'
});
await page.goto('https://www.httpbin.org/headers');Pero si quieres modificar el User-Agent, no puedes usar el método anterior. Debido a que el User-Agent en el navegador tiene un valor predeterminado. Si realmente deseas cambiarlo, puedes usar page.setUserAgent.
import puppeteer from "puppeteer";
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.5790.98 Safari/537.36');
await page.goto('https://example.com/');
const navigator = await page.evaluate(_ => window.navigator.userAgent)
const platform = await page.evaluate(_ => window.navigator.platform)
console.log('userAgent: ', navigator);
console.log('platform: ', platform);
await browser.close();
Pero este paso no es suficiente. De la información impresa anteriormente, el platform aún está configurado en win32 y no se ha modificado realmente.
La mayoría de los sitios web detectan a través de window.navigator. Por lo tanto, es necesario modificar profundamente el navigator. Antes de usar page.goto, podemos modificar profundamente el navigator en page.evaluateOnNewDocument.
Aquí hay una breve descripción de la diferencia entre page.evaluateOnNewDocument y page.evaluate:
evaluateOnNewDocument.evaluate.await page.evaluateOnNewDocument(() => {
Object.defineProperties(navigator, {
platform: {
get: () => 'Mac'
},
});
});
Cada línea de este artículo está desempeñando un papel crucial para describir las guías más detalladas sobre:
¿Quieres hacer web scraping y automatización sin esfuerzo? ¡Nstbrowser RPA te ayuda a simplificar todas las tareas!





