
Browserless
Browserless Web Scraping: NodeJS en Playwright
¿Qué es Playwright? ¿Cómo se extrae información de un sitio web con NodeJS? Este blog trata sobre cómo hacer web scraping con Playwright con NodeJS. Además, aquí puedes encontrar el secreto de Browserless.
Aug 19, 2024Carlos Rivera
¿Qué es Playwright?
Playwright es un marco de trabajo de código abierto para pruebas y automatización web. Basado en Node.js y desarrollado por Microsoft, admite Chromium, Firefox y WebKit a través de una única API. Puede funcionar en Windows, Linux y macOS, y es compatible con TypeScript, JavaScript, Python, .NET y Java.
¿Cuáles son las ventajas de NodeJS en Playwright para la extracción de datos web?
Playwright no es solo una herramienta, sino una solución integral para la extracción de datos web en Node.js, combinando poder, flexibilidad y eficiencia para satisfacer los requisitos más exigentes de la automatización web moderna.
- Manejo robusto de interacciones con la página
- Manejo automático de contenido dinámico
- Resiliencia contra técnicas anti-scraping
En Node.js, el modo sin cabeza en Playwright es una gran ventaja. Permite ejecutar navegadores sin la interfaz visual, acelerando el proceso de extracción y haciéndolo adecuado para tareas a gran escala.
Playwright maneja bien interacciones web complejas, como la carga de contenido dinámico, la gestión de entradas de usuario y el manejo de acciones asincrónicas. Esto lo hace perfecto para extraer datos de sitios web modernos que dependen en gran medida de JavaScript. La capacidad de interceptar solicitudes de red es otra fortaleza. Te da control sobre las solicitudes y respuestas, ayudando a eludir medidas anti-scraping y a ajustar tu proceso de extracción.
Lo que también es excelente acerca de Playwright es lo fácil que se integra con proyectos de Node.js. Puedes incorporarlo sin problemas en tus flujos de trabajo existentes y usarlo junto con otras bibliotecas de JavaScript o TypeScript. Además, dado que funciona en Windows, Linux y macOS, puedes desplegar tus scripts de extracción en diferentes plataformas sin complicaciones.
¿Qué es Browserless?
Browserless es un servicio de navegador sin cabeza basado en la nube diseñado por Nstbrowser para ejecutar operaciones web y scripts de automatización sin una interfaz gráfica.
Una de las características clave de Nstbrowserless es su capacidad para eludir bloqueos comunes como CAPTCHAs y bloqueo de IP, gracias a sus sistemas integrados Anti-detect, Web Unblocker y proxy inteligente. Estas herramientas aseguran que tus scripts de automatización se ejecuten sin problemas, incluso en sitios web con medidas de seguridad estrictas.
Browserless admite clústeres de contenedores en la nube, lo que te permite escalar tus operaciones sin esfuerzo. Ya sea que estés ejecutando en Windows, Linux o macOS, nuestra plataforma proporciona una solución consistente y a nivel empresarial para todas tus necesidades de automatización web. Está diseñada para integrarse a la perfección en tus flujos de trabajo existentes, ofreciendo un entorno robusto y confiable para operaciones web de alto rendimiento.
¿Tienes ideas maravillosas y dudas sobre la extracción de datos web y Browserless?
¡Veamos lo que otros desarrolladores están compartiendo en Discord y Telegram!
¿Cómo hacer extracción de datos web con Playwright y NodeJS?

Paso 1: Instalar y Configurar Playwright
Primero, asegúrate de que Node.js esté instalado en tu sistema. Si no lo está, descarga e instala la versión LTS. Luego, usa npm, el gestor de paquetes de Node.js, para instalar Playwright.
Bash
npm init playwright@latestEjecuta el comando de instalación y realiza las siguientes selecciones para comenzar:
- Decide entre TypeScript y JavaScript (TypeScript es la opción predeterminada).
- Nombra tu carpeta de pruebas (por defecto es
testoe2esi ya existe una carpeta de pruebas). - Elige si deseas agregar el flujo de trabajo de GitHub Actions para facilitar la ejecución de pruebas en CI.
- Determina si quieres instalar el navegador Playwright ahora (esto está configurado en verdadero por defecto, pero también puedes hacerlo manualmente más tarde usando
npx playwright install).
Paso 2: Lanzar el navegador con Playwright
Como un navegador normal, Playwright puede renderizar JavaScript, imágenes, etc., por lo que puede extraer datos cargados dinámicamente. El script es más difícil de detectar y bloquear porque simula el comportamiento normal del usuario y es difícil de identificar como un script automatizado.
JavaScript
import { chromium } from 'playwright';
const browser = await chromium.launch({ headless: false }); // Abre el navegador y crea una nueva pestaña
const page = await browser.newPage();
await page.goto('https://developer.chrome.com/'); // Visita la URL especificada
await page.setViewportSize({ width: 1080, height: 1024 }); // Establece el tamaño de la ventana
console.log('[¡Navegador abierto!]');Por defecto, Playwright opera en modo sin cabeza. En el código proporcionado, deshabilitamos el modo sin cabeza configurando headless: false, lo que te permite probar visualmente tu script. La demostración y los ejemplos siguientes no necesitan funciones asíncronas debido a la configuración "type": "module" en package.json, que permite la ejecución de módulos ES.
Paso 3: Comenzar a rastrear
Comenzaremos con una tarea básica de extracción de datos web para familiarizarte rápidamente con Playwright. ¡Vamos a extraer reseñas para los Apple AirPods Pro en Amazon!
La extracción de datos web efectiva comienza con analizar la página. Necesitas identificar dónde se encuentra la información que deseas extraer. La consola de depuración del navegador puede ayudarnos mucho:
Después de abrir la página web, necesitas abrir la consola de depuración presionando Ctrl + Shift + I (Windows/Linux) o Cmd + Option + I (Mac).
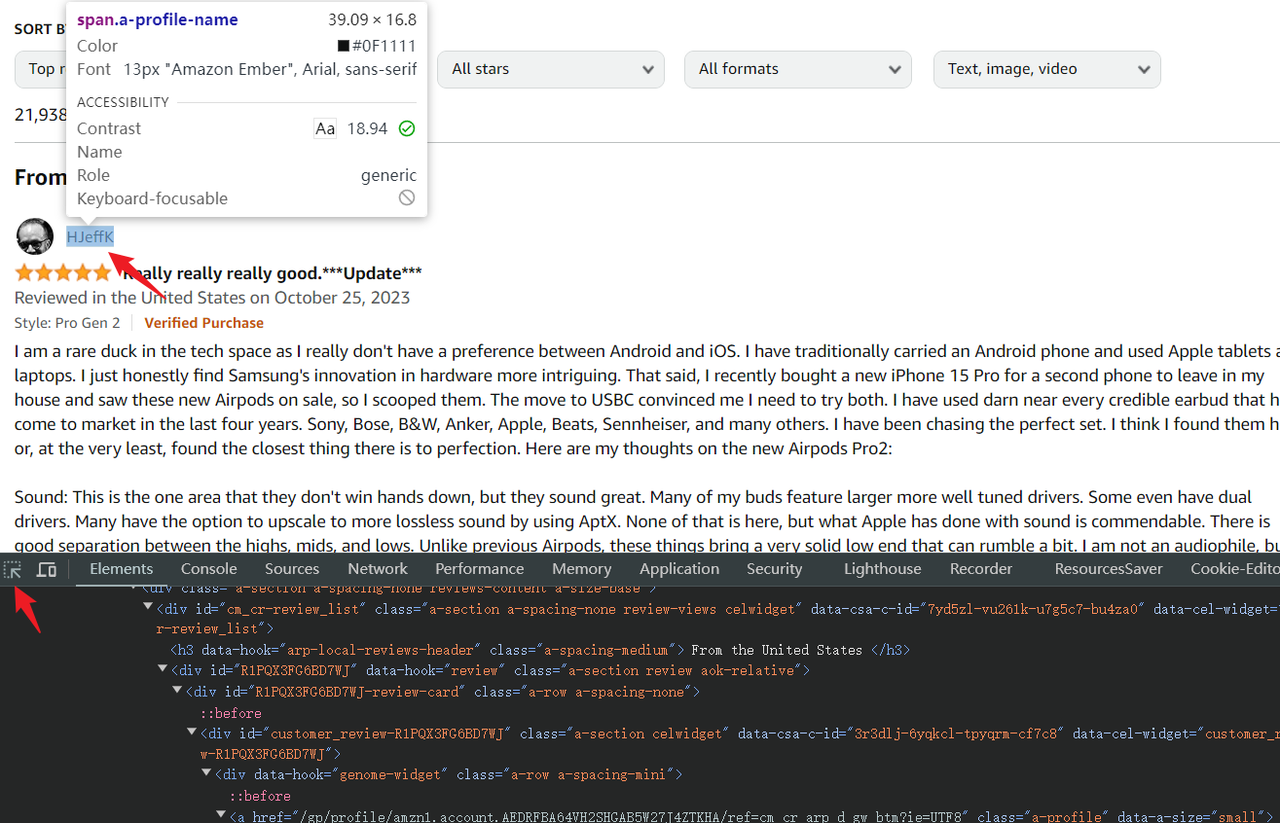
- Selecciona el selector de elementos en la parte superior izquierda de la consola.
- Pasa el cursor sobre los elementos que deseas extraer, y el código HTML correspondiente se resaltará en la consola.
Playwright admite varios métodos para seleccionar elementos, pero usar selectores CSS simples es a menudo la forma más fácil de comenzar. El .devsite-search-field usado anteriormente es un ejemplo de un selector CSS.
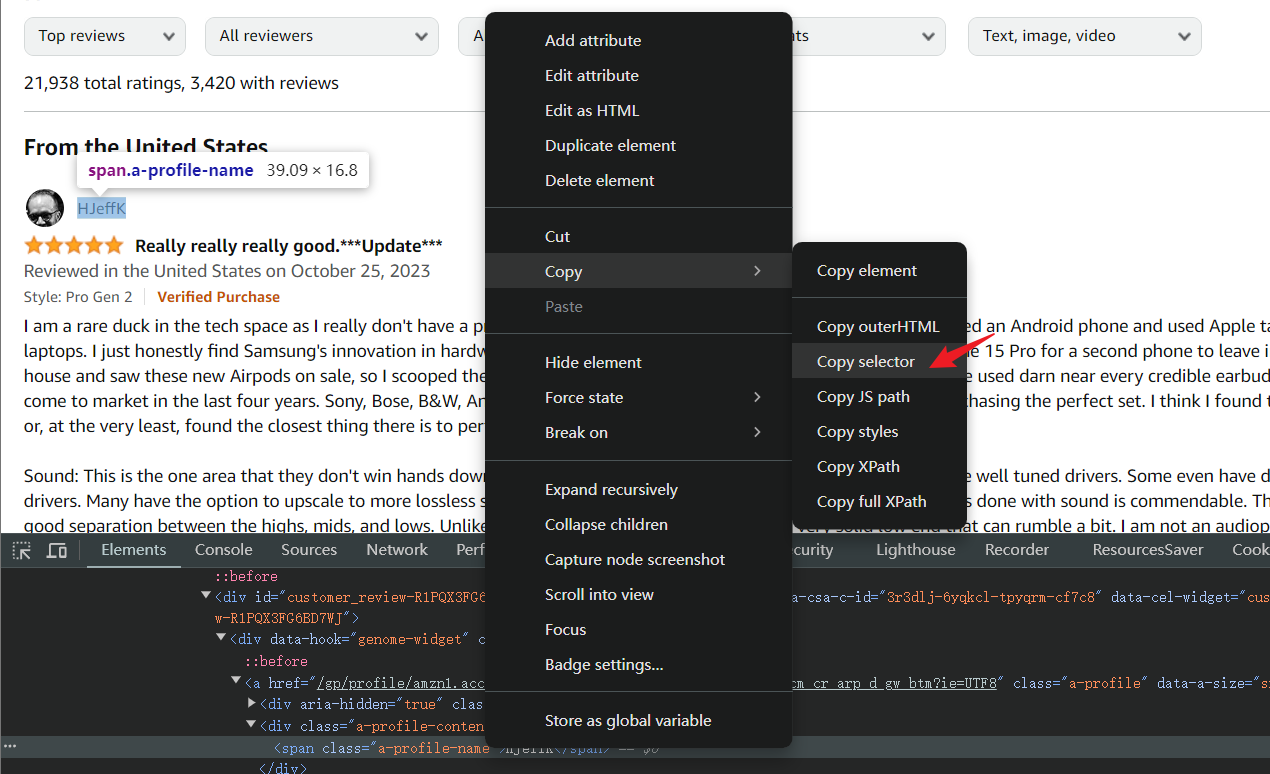
Para estructuras CSS complejas, la consola de depuración puede copiar directamente los selectores CSS. Haz clic derecho en el HTML del elemento que deseas capturar y selecciona abrir menú > Copiar > Copiar selector.
Ahora que se ha determinado el selector de elementos, podemos usar Playwright para intentar obtener el nombre de usuario que seleccioné anteriormente.
JavaScript
import { chromium } from 'playwright'; // También puedes usar 'firefox' o 'webkit'
// Inicia una nueva instancia del navegador
const browser = await chromium.launch();
// Crea una nueva página
const page = await browser.newPage();
// Navega a la URL especificada
await page.goto('https://www.amazon.com/Apple-Generation-Cancelling-Transparency-Personalized/product-reviews/B0CHWRXH8B/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews');
// Espera a que el nodo cargue, hasta 10 segundos
await page.waitForSelector('div[data-hook="genome-widget"] .a-profile-name', { timeout: 10000 });
// Extrae el nombre de usuario
const username = await page.$eval('div[data-hook="genome-widget"] .a-profile-name', node => node.textContent);
console.log('[nombre de usuario]===>', username);
// Cierra el navegador
await browser.close();Puedes ajustar el código para extraer más que un solo nombre de usuario, como recuperar una lista completa de comentarios:
- Utiliza
page.waitForSelectorpara asegurar que los elementos de reseña se carguen completamente. - Usa
page.$$para seleccionar todos los elementos que coincidan con el selector especificado.
Luego, recorre la lista de elementos de reseña y extrae la información necesaria de cada uno. El código proporcionado capturará el título, la calificación, el nombre de usuario, el contenido del texto y el atributo data-src del avatar, que incluye la URL del avatar.
Como se demuestra, el código:
page.gotopara navegar a la página deseada.waitForSelectorpara esperar hasta que el nodo objetivo se muestre correctamente.page.$evalpara obtener el primer elemento coincidente y extraer atributos específicos mediante una función de devolución de llamada.
JavaScript
await page.waitForSelector('div[data-hook="review"]');
const reviewList = await page.$$('div[data-hook="review"]');A continuación, necesitamos recorrer la lista de elementos de revisión y obtener la información requerida de cada elemento de revisión.
En el siguiente código, podemos obtener el título, la calificación, el nombre de usuario y el contenido de textContent, así como el valor del atributo data-src del nodo del elemento de avatar, que es la dirección URL del avatar.
JavaScript
for (const review of reviewList) {
const title = await review.$eval(
'a[data-hook="review-title"] > span:nth-of-type(2)',
node => node.textContent,
);
const rate = await review.$eval(
'i[data-hook="review-star-rating"] .a-icon-alt',
node => node.textContent,
);
const username = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-name',
node => node.textContent,
);
const avatar = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-avatar img',
node => node.getAttribute('data-src'),
);
const content = await review.$eval(
'span[data-hook="review-body"] span',
node => node.textContent,
);
console.log('[log]===>', { title, rate, username, avatar, content });
}Paso 4: Exportar datos
Después de ejecutar el código anterior, deberías poder ver la salida de la información de registro en la terminal.
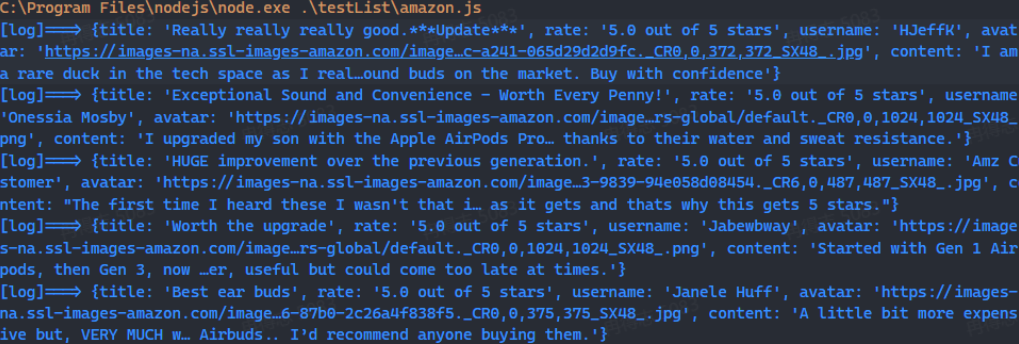
Si deseas almacenar estos datos más adelante, puedes usar el módulo básico de Node.js fs para escribir los datos en un archivo JSON para su análisis posterior. A continuación, se muestra una función de herramienta simple:
JavaScript
import fs from 'fs';
// Guardar como archivo JSON
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2);
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`Archivo guardado exitosamente: ${filename}`);
});
}El código completo es el siguiente. Después de ejecutarlo, puedes encontrar el archivo amazon_reviews_log.json en la ruta de ejecución del script actual, que registra todos los resultados de la extracción.
JavaScript
import { chromium } from 'playwright';
import fs from 'fs';
// Iniciar el navegador
const browser = await chromium.launch();
const page = await browser.newPage();
// Visitar la página
await page.goto(
`https://www.amazon.com/Apple-Generation-Cancelling-Transparency-Personalized/product-reviews/B0CHWRXH8B/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews`
);
// Esperar a que se cargue el elemento de revisión
await page.waitForSelector('div[data-hook="review"]');
// Obtener todos los elementos de revisión
const reviewList = await page.$$('div[data-hook="review"]');
const reviewLog = [];
// Recorrer la lista de elementos de revisión
for (const review of reviewList) {
const title = await review.$eval(
'a[data-hook="review-title"] > span:nth-of-type(2)',
node => node.textContent.trim()
);
const rate = await review.$eval(
'i[data-hook="review-star-rating"] .a-icon-alt',
node => node.textContent.trim()
);
const username = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-name',
node => node.textContent.trim()
);
const avatar = await review.$eval(
'div[data-hook="genome-widget"] .a-profile-avatar img',
node => node.getAttribute('data-src')
);
const content = await review.$eval(
'span[data-hook="review-body"] span',
node => node.textContent.trim()
);
console.log('[log]===>', { title, rate, username, avatar, content });
reviewLog.push({ title, rate, username, avatar, content });
}
// Guardar como archivo JSON
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2);
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`Archivo guardado exitosamente: ${filename}`);
});
}
saveObjectToJson(reviewLog, 'amazon_reviews_log.json');
await browser.close();Uso de Playwright para otras operaciones web
Hacer clic en un botón
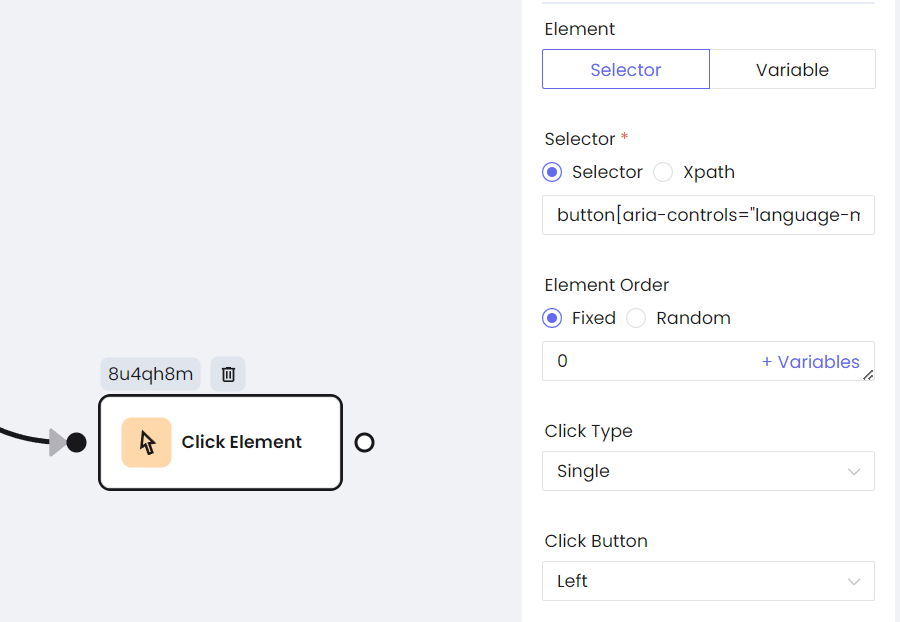
Haz clic en un botón con page.click y establece un retraso para que la operación sea más parecida a la humana. Aquí tienes un ejemplo simple.
JavaScript
import { chromium } from 'playwright'
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://example.com/'); // Visitar la URL especificada
await page.waitForTimeout(3000)
await page.click('p > a', { delay: 200 })Desplazar la página
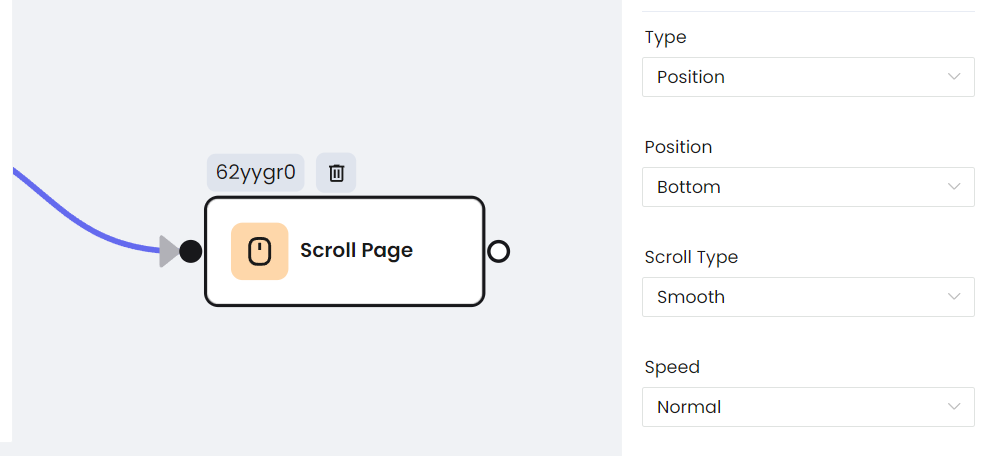
En page.evaluate, es muy conveniente establecer la posición de la barra de desplazamiento llamando a la API de Window. Page.evaluate es una API muy útil:
JavaScript
import { chromium } from 'playwright'
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://www.nstbrowser.io/'); // Visitar la URL especificada
// Desplazarse hasta el final
await page.evaluate(() => {
window.scrollTo(0, document.documentElement.scrollHeight);
});Capturar una lista de elementos
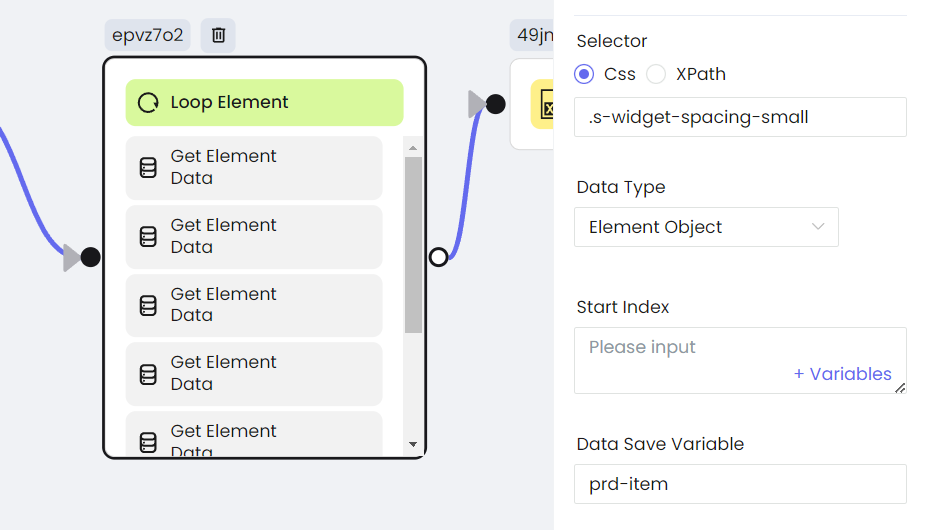
Para capturar varios elementos, podemos usar page.$$eval, que puede obtener todos los elementos que coinciden con el selector especificado, y finalmente recorrer estos elementos en la función de retorno para obtener propiedades específicas.
JavaScript
import { chromium } from 'playwright'
// Iniciar el navegador
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');
await page.waitForSelector('.titleline > a')
// Capturar el título del artículo
const titles = await page.$$eval('.titleline > a', elements =>
elements.map(el => el.innerText)
);
// Mostrar el título capturado
console.log('Título del artículo:');
titles.forEach((title, index) => console.log(`${index + 1}: ${title}`));Interceptar solicitudes HTTP
El método page.route se usa para interceptar solicitudes en la página. '**/*' es un comodín, lo que significa que coincide con todas las solicitudes. Luego, todas las solicitudes se pueden procesar en la función de retorno. El parámetro route se usa para establecer si la solicitud se ejecuta normalmente o se interrumpe, y también se puede usar para reescribir la respuesta.
JavaScript
import { chromium } from 'playwright'
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
await page.route('**/*', (route) => {
const request = route.request();
// Interceptar y bloquear solicitudes de fuentes
if (request.url().includes('https://fonts.gstatic.com/')) {
route.fulfill({
status: 404,
contentType: 'image/x-icon',
body: ''
});
console.log('Solicitud de icono bloqueada');
// Interceptar y bloquear solicitudes de hojas de estilo
} else if (request.resourceType() === 'stylesheet') {
route.abort();
console.log('Solicitud de hoja de estilo bloqueada');
// Interceptar y bloquear solicitudes de imágenes
} else if (request.resourceType() === 'image') {
route.abort();
console.log('Solicitud de imagen bloqueada');
// Permitir que otras solicitudes continúen
} else {
route.continue();
}
});
await page.goto('https://www.youtube.com/');Captura de pantalla
Playwright proporciona una API de captura de pantalla lista para usar, que es una característica muy práctica. Puedes controlar la calidad del archivo de la captura de pantalla a través de la calidad y recortar la imagen a través de un clip. Si tienes requisitos para la proporción de la captura de pantalla, puedes configurar la viewport para lograrlo.
JavaScript
import { chromium } from 'playwright';
const browser = await chromium.launch({ viewport: { width: 1920, height: 1080 } });
const page = await browser.newPage();
await page.goto('https://www.youtube.com/');
// Capturar toda la página
await page.screenshot({ path: 'screenshot1.png' });
// Capturar una imagen JPEG, establecer la calidad en 50
await page.screenshot({ path: 'screenshot2.jpeg', quality: 50 });
// Recortar la imagen, especificar el área de recorte
await page.screenshot({ path: 'screenshot3.jpeg', clip: { x: 0, y: 0, width: 150, height: 150 } });
console.log('Captura de pantalla guardada');
await browser.close();¡Los nodos de Nstbrowser pueden lograr todo esto!
¡Ciertamente, puedes realizar todas estas tareas usando diversas herramientas! Por ejemplo, el RPA de Nstbrowser puede acelerar tu proceso de extracción de datos.
Paso 1. Visita la página de inicio de Nstbrowser, luego navega a RPA/Workflow > crear flujo de trabajo.
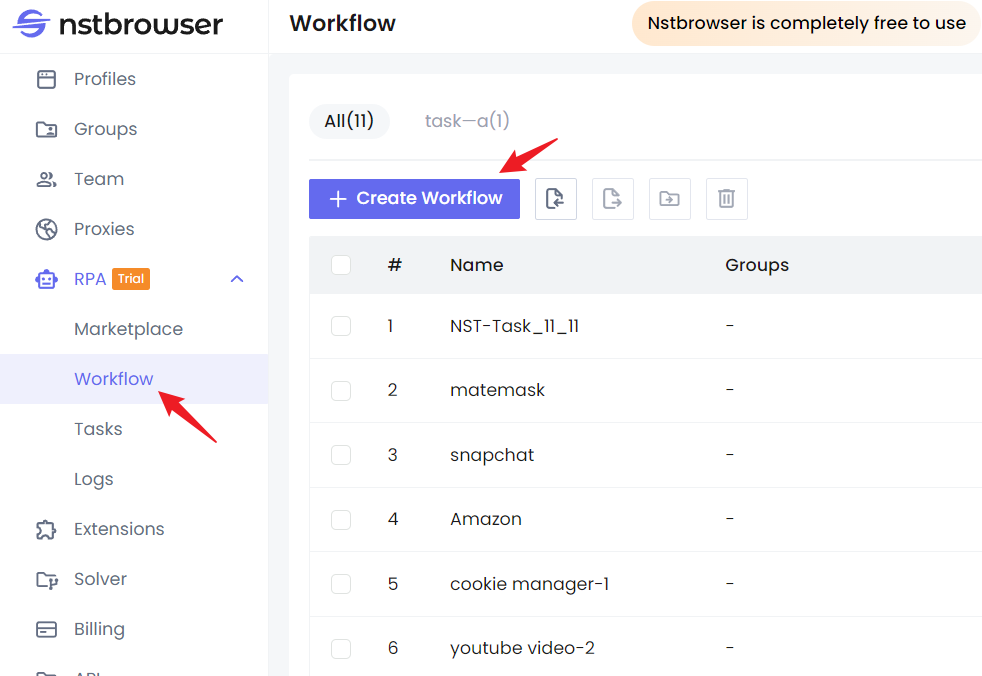
Paso 2. Una vez en la página de edición del flujo de trabajo, puedes replicar fácilmente las funciones anteriores simplemente arrastrando y soltando con el ratón.
Los Nodos a la izquierda cubren casi todas tus necesidades de extracción de datos y automatización, y están alineados estrechamente con la API de Playwright.
Puedes ajustar el orden de ejecución de estos nodos vinculándolos, de manera similar a como se ejecuta el código asíncrono en JavaScript. Si estás familiarizado con Playwright, encontrarás fácil comenzar a usar la función RPA de Nstbrowser—lo que ves es lo que obtienes.
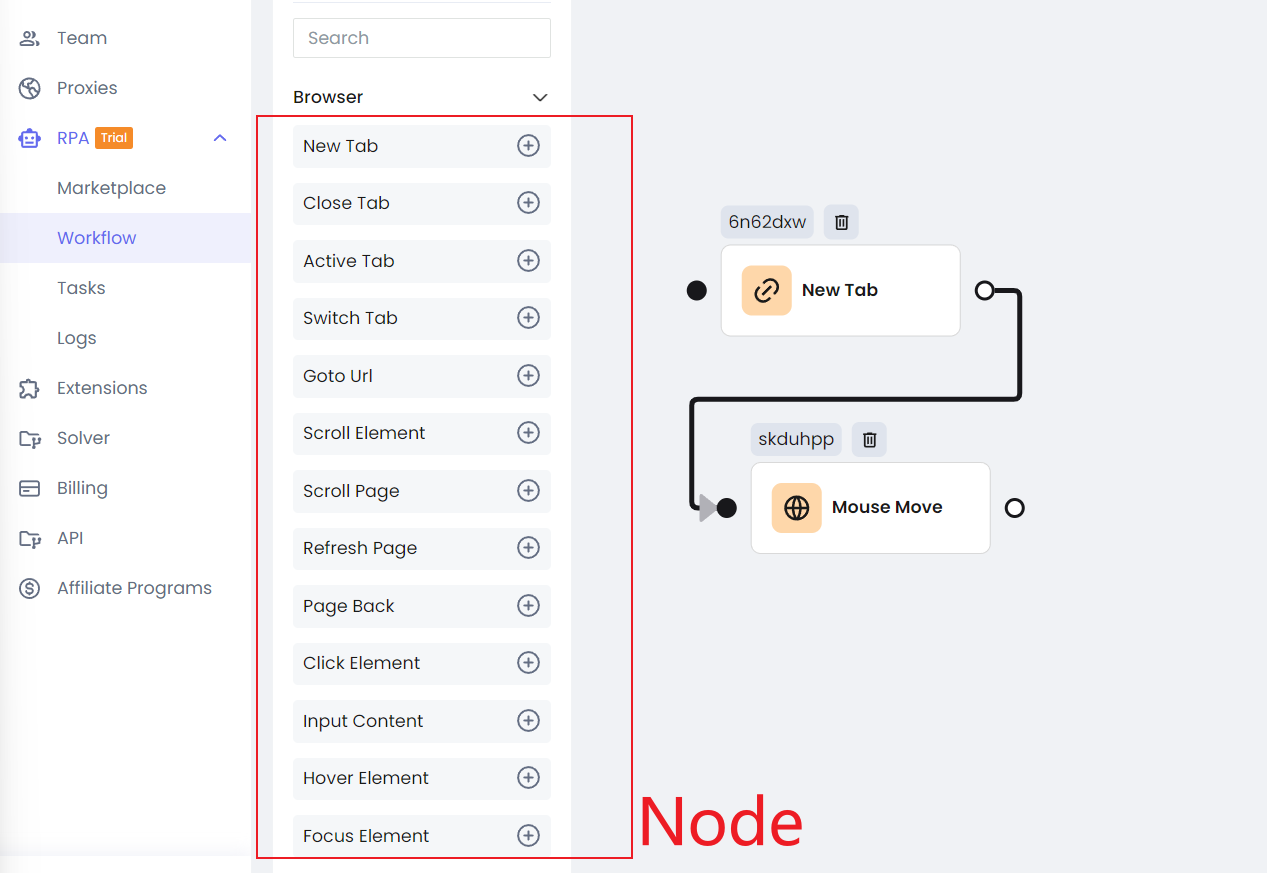
Paso 3. Cada Nodo se puede configurar individualmente, con ajustes que coinciden estrechamente con los de Playwright.
- Hacer clic en el botón
- Desplazar la página
- Extraer lista de elementos
- Interceptar solicitudes HTTP
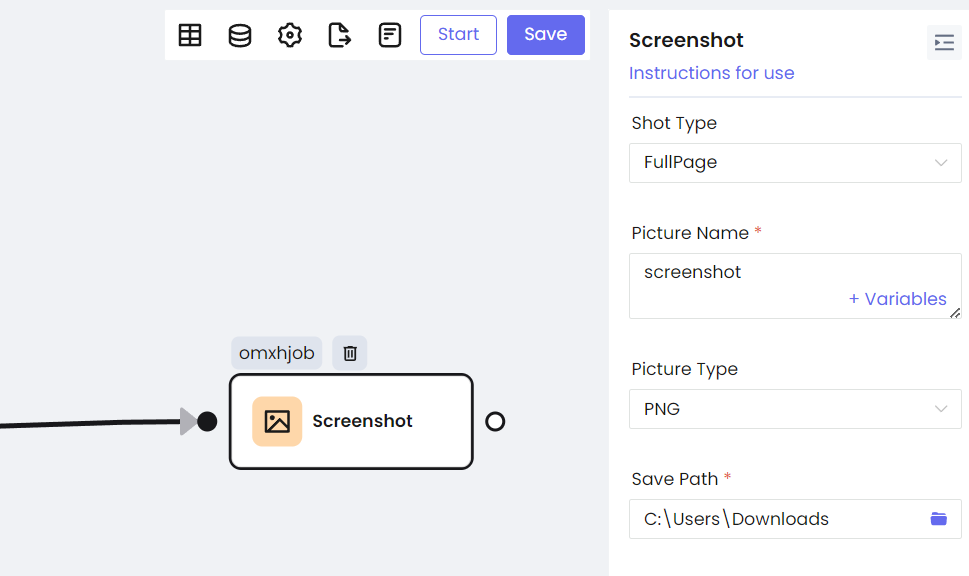
- Captura de pantalla
Playwright vs. Puppeteer vs. Selenium
| Criterio | Playwright | Puppeteer | Selenium |
|---|---|---|---|
| Compatibilidad con navegadores | Chromium, Firefox y WebKit | Navegadores basados en Chromium | Chrome, Firefox, Safari, Internet Explorer y Edge |
| Compatibilidad de lenguajes | TypeScript, JavaScript, Python, .NET y Java | Node.js | Java, Python, C#, JavaScript, Ruby, Perl, PHP, TypeScript |
| Sistema operativo | Windows, macOS, Linux | Windows y OS X | Windows, macOS, Linux, Solaris |
| Comunidad y ecosistema | Comunidad en crecimiento con sólido soporte y desarrollo continuo por parte de Microsoft | Respaldado por Google con una comunidad fuerte, especialmente para quienes se enfocan en Chromium | Establecido, con una gran comunidad activa y un extenso ecosistema, incluidos complementos e integraciones |
| Soporte para integración CI/CD | Sí | Sí | Sí |
| Soporte para grabación y reproducción | En el panel Sources de Chrome DevTools | Playwright CodeGen | Selenium IDE |
| Diferencia en web scraping | Con características modernas y velocidad, bueno para scraping en diferentes navegadores | Excelente en Chrome, y es rápido | Versátil para web scraping pero puede ser más lento |
| Modo sin cabeza | Soporta modo sin cabeza para todos los navegadores compatibles | Soporta modo sin cabeza pero solo para navegadores basados en Chromium | Soporta modo sin cabeza, pero la implementación varía según el controlador del navegador |
| Capturas de pantalla | Captura de PDF e imagen, especialmente en Chromium | Captura de PDF e imagen, fácil de usar | No tiene captura de PDF integrada |
Reflexiones finales
¡Playwright es muy poderoso!
Proporciona un conjunto de herramientas de web scraping poderoso y versátil. Además, la excelente documentación de Playwright y la creciente comunidad aportan gran conveniencia a tus tareas de automatización.
En este blog, has obtenido una comprensión más profunda de Playwright:
- Ventajas del web scraping con Playwright.
- Uso eficiente de NodeJS en Playwright.
- Uso de Playwright para completar otras operaciones.
Browserless de Nstbrowser está lleno de características poderosas en Docker. ¿Quieres liberar tu almacenamiento y deshacerte de las restricciones en los dispositivos locales? ¡Logra una gestión completamente en la Nube con Nstbrowser ahora!
Más





