
Browserless
How to Scrape Yandex Images Results Using Playwright and Browserless?
Scraping data of Yandex image search is really difficult. However, effective steps and codes in this article will help you easily scrape the content.
Oct 24, 2024Carlos Rivera
What Is Yandex?
Yandex is a multinational company based in Russia that is best known for its search engine, which is among the biggest in the country. Yandex provides a range of services in addition to search capabilities. Additionally, Yandex provides Yandex Image Search, which allows you to look for photographs using keywords.
The results of Yandex image searches differ slightly from those of Google and Bing. Numerous filters, including size, orientation, type, color, format, recent, and wallpaper, are also supported by Yandex image search.
Thousands of photos can be scraped for a variety of purposes, including marketing, branding, research, teaching, and creative.
Scraping Yandex Is Really Difficult!
Yandex employs advanced anti-bot measures designed to detect and block automated requests. This includes the implementation of CAPTCHAs and strict IP rate limiting, which can hinder scraping efforts.
Many Yandex pages feature dynamic content that loads via JavaScript. This means that simple scraping techniques may not capture all relevant information, necessitating the use of more sophisticated tools such as headless browsers.
Additionally, Yandex frequently updates its algorithms and the structure of its pages. This constant evolution can cause scraping scripts to break, requiring regular maintenance and adjustments.
There are legal considerations to take into account, as scraping may violate Yandex's terms of service, potentially leading to legal repercussions for users.
The vast amount of data available on Yandex means that efficient data handling is essential, adding another layer of complexity to the scraping process.
These factors combined make scraping Yandex a challenging endeavor that requires careful planning and execution.
Why Browserless Works Well for Scraping Yandex Image Search?
Nstbrowser's Browserless is a typical Headless Chrome cloud service that operates online applications and automates scripts without a graphical user interface. For tasks like web scraping and other automated operations, it is especially helpful.
Nstbrowser integrates anti-detection, web unblocker, and browserless features into Browserless. Browserless is totally free to test. Our documentation has been prepared for more details.
Do you have any wonderful ideas or doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord!
How to Scrape Yandex Image Search Results?
Environment Preset
At the very beginning, we should prepare our Browserless service. Browserless can help solve complex web crawling and large-scale automation tasks, and fully managed cloud deployment has been achieved.
- Browserless uses a browser-centric approach, offers robust headless deployment features, and provides improved dependability and speed. Check out our documentation on Browserless for additional details.
- Go to the Browserless menu page of the Nstbrowser client to obtain the API KEY, or you can directly obtain it through the jump link here.
Determine the crawling target
Just as before, please follow us to determine the scraping target first.
Let's use Playwright and combine it with Nstbrowser's Browserless service to crawl the top images when searching for the keyword "cat".
The data we need includes: "image address", "image summary", "image width", and "image height", and save the results to a CSV file.
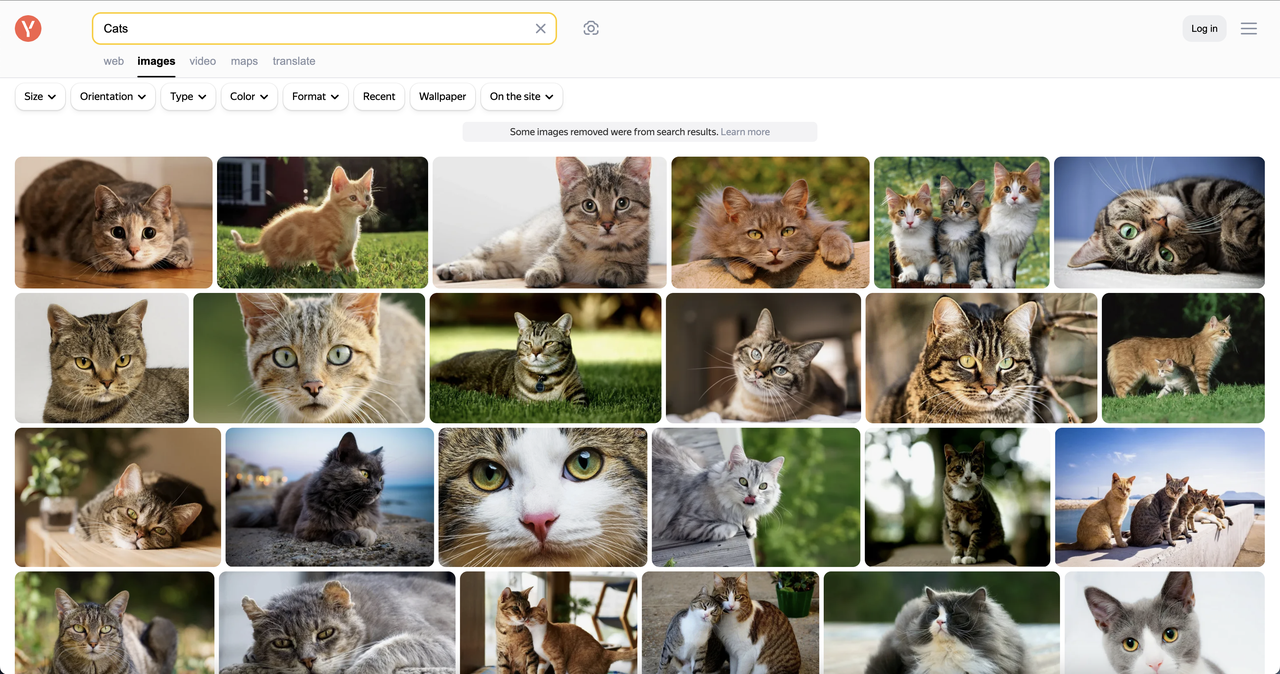
Start crawling using Nstbrowser Browserless service
Follow the steps below to create the project and start scraping:
Step 1. Build a main.py file and a new Python project.
Step 2. Using Nstbrowser's Browserless to create a browser instance.
Python
from playwright.sync_api import sync_playwright
token = "You API token" # required
config = {
"proxy": "", # required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
# "platform": "windows", # support: windows, mac, linux
# "kernel": "chromium", # only support: chromium
# "kernelMilestone": "124", # support: 113, 120, 124
# "args": {
# "--proxy-bypass-list": "detect.nstbrowser.io"
# }, # browser args
# "fingerprint": {
# "userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36",
# },
}
query = urlencode({
"token": token,
"config": json.dumps(config)
})
browser_ws_endpoint = f"ws://less.nstbrowser.io/connect?{query}"
def get_browser():
playwright = sync_playwright().start()
return playwright.chromium.connect_over_cdp(browser_ws_endpoint)Step 3. Obtain image data and clean it
- Define the crawl target website address:
Python
target_website_url = "https://yandex.com/images/search?family=yes&from=tabbar&text=cats"- Here, Playwright uses the
page.gotomethod to help open the target web page.
This step is to ensure that the browser can load the page correctly and wait for the DOM content of the web page to be fully loaded.
Python
page.goto(url, timeout=60000, wait_until="domcontentloaded")- Next, we need to find all elements with
data-stateattributes on the page and try to find the target element (the element containing the image data).
This step uses the query_selector_all method to get these elements and locate the element containing the image information through get_attribute("id") and get_attribute("data-state").
Python
data_states = page.query_selector_all("[data-state]")
images_app = None
for data_state in data_states:
if "ImagesApp" in data_state.get_attribute("id"):
images_app = data_state.get_attribute("data-state")
break- After getting the target element, the code calls the
get_image_resultsfunction.
This function parses the JSON data in the data-state attribute of the target element and extracts the image information.
Python
def get_image_results(images_app):
images_app_obj = json.loads(images_app)
images_lists = images_app_obj['initialState']["serpList"]["items"]["entities"]
imgs = []
for key in images_lists:
img = images_lists[key]
imgs.append({
"url": img["url"],
"alt": img["alt"],
"width": img["width"],
"height": img["height"],
})
return imgsStep 4. Save the crawling results and export them to a CSV file
Before saving the data, you need to define the header of the CSV file. Four fields are defined here: URL, Alt, Width, and Height. These fields represent the basic properties of each image. Use the open() function to open a file named yandex_images.csv in write mode ('w'). At the same time, the encoding format is specified as UTF-8 and newline='' is set to avoid blank lines when writing.
Python
def save_csv(data):
try:
header = ["URL", "Alt", "Width", "Height"]
with open('yandex_images.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(header)
for item in data:
writer.writerow(
[
item["url"],
item["alt"],
item["width"],
item["height"],
])
print("Saved to yandex_images.csv")
except Exception as e:
print(e)The whole code lines
Python
import json
import csv
from urllib.parse import urlencode
from playwright.sync_api import sync_playwright
token = "" # required
config = {
"proxy": "", # required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
# "platform": "windows", # support: windows, mac, linux
# "kernel": "chromium", # only support: chromium
# "kernelMilestone": "124", # support: 113, 120, 124
# "args": {
# "--proxy-bypass-list": "detect.nstbrowser.io"
# }, # browser args
# "fingerprint": {
# "userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36",
# },
}
query = urlencode({
"token": token,
"config": json.dumps(config)
})
browser_ws_endpoint = f"ws://less.nstbrowser.io/connect?{query}"
target_website_url = "https://yandex.com/images/search?family=yes&from=tabbar&text=cats"
def get_browser():
playwright = sync_playwright().start()
return playwright.chromium.connect_over_cdp(browser_ws_endpoint)
def get_image_results(images_app):
try:
images_app_obj = json.loads(images_app)
images_lists = images_app_obj['initialState']["serpList"]["items"]["entities"]
imgs = []
for key in images_lists:
img = images_lists[key]
imgs.append({
"url": img["url"],
"alt": img["alt"],
"width": img["width"],
"height": img["height"],
})
return imgs
except Exception as e:
print(e)
def get_tar(url, page):
try:
print("Open page: " + url)
page.goto(url, timeout=60000, wait_until="domcontentloaded")
data_states = page.query_selector_all("[data-state]")
images_app = None
results = []
for data_state in data_states:
if "ImagesApp" in data_state.get_attribute("id"):
images_app = data_state.get_attribute("data-state")
break
if images_app is None:
print("Cannot find the target element")
else:
print("Found the target element")
results = get_image_results(images_app)
return results
except Exception as e:
print(e)
def save_csv(data):
try:
header = ["URL", "Alt", "Width", "Height"]
with open('yandex_images.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(header)
for item in data:
writer.writerow(
[
item["url"],
item["alt"],
item["width"],
item["height"],
])
print("Saved to yandex_images.csv")
except Exception as e:
print(e)
def main():
try:
with get_browser() as browser:
page = browser.new_page()
res = get_tar(target_website_url, page)
if len(res) == 0:
print("No results")
else:
save_csv(res)
browser.close()
except Exception as e:
print(e)
if __name__ == "__main__":
main()Scraping result

It's A Wrap
Scraping Yandex image search is difficult, as everyone knows. However, you can easily scrape Yandex search results for any chosen term and export the data into CSV or JSON files if you follow the scraping instructions in this post and utilize the Python code that is provided.
You can easily scrape Yandex SERP at scale with Nstbrowser and Browserless. Now, using Browserless is totally free. Don't pass up this fantastic chance!
Please contact us if you need a more powerful solution.
Disclaimer: Any data and websites mentioned in this article are for demonstration purposes only. We firmly oppose illegal and infringing activities. If you have any questions or concerns, please contact us promptly.
More





