
Browserless
How to Scrape Stock Data from Yahoo Finance Using Browserless?
Yahoo Finance is a typical dynamic website. It is very difficult to scrape it. This blog will help you easily finish web scraping Yahoo Finance using Puppeteer and Browserless.
Oct 25, 2024Robin Brown
Is it Legal to Do Web Scraping on Yahoo Finance?
How about the legality of scraping Yahoo Finance? Will it be recognized as an illegal activity?
Please don't be nervous. Most of the data on the Yahoo Finance website is open source and public information. The Yahoo Finance data we can scrape includes:
- Stock market news updates
- Current stock prices of companies
- Trends in company stock prices go up or down.
- Mutual funds and ETFs
- Values of currencies and even cryptocurrencies
Although this is true in principle, you should still pay attention to local web scraping laws and regulations just in case.
Why Do We Need to Scrape Stock Data from Yahoo Finance?
Before scraping, it is important to figure out the reasons. Why should we scrape it? Here we can give you the analysis.
By scraping recent data, investors can get the latest stock prices, trading volumes, and market dynamics, so as to make timely decisions. In addition, by analyzing historical data, investors can build basic models to predict stock price trends and assist in investment strategy formulation.
We are always afraid of risks. We can obtain performance data of different stocks to help us optimize our investment portfolio to reduce risks.
Financial reports, news, and other events have a significant impact on stock prices. By scraping data, we can clearly understand the stock market and help investors make correct decisions.
After a cycle of investment, we need to give a summary of feedback on the development of the invested funds. Using Browserless for data scraping can timely and effectively test historical data and verify the effectiveness of trading strategies, thereby improving the success rate of transactions.
Why Browserless Helps a Lot with Scraping Yahoo Finance?
However, Yahoo Finance may use measures such as IP blocking, CAPTCHAs, and request rate limiting to prevent automated scraping. And because some data may be loaded dynamically through JavaScript, we need to use a more powerful and stable program to deal with dynamic web pages.
Don't be sad! Browserless plays good to deal with these problems.
Browserless is a cloud-based solution engineered for scalable browser automation, web scraping, and web testing. Browserless has native compatibility with Playwright and Puppeteer. It is also designed with automatic captcha solving and proxy services. Besides, it equips an extensible platform with APIs for integrating real-time views and retrieving logs and recordings.
Browserless is now totally to test!
Do you have any wonderful ideas or doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord!
Scrape Yahoo Finance Using Puppeteer and Browserless
Prerequisite
Browserless service is necessary for us to scrape Yahoo Finance. Nstbrowser's Browserless is an effective tool to deal with complex web scraping and large-scale automation tasks, and it supports fully managed cloud deployment.
Browserless adopts a browser-centric approach, provides powerful headless deployment capabilities, and provides higher performance and reliability. For more information about Browserless, you can learn from our Browserless documents.
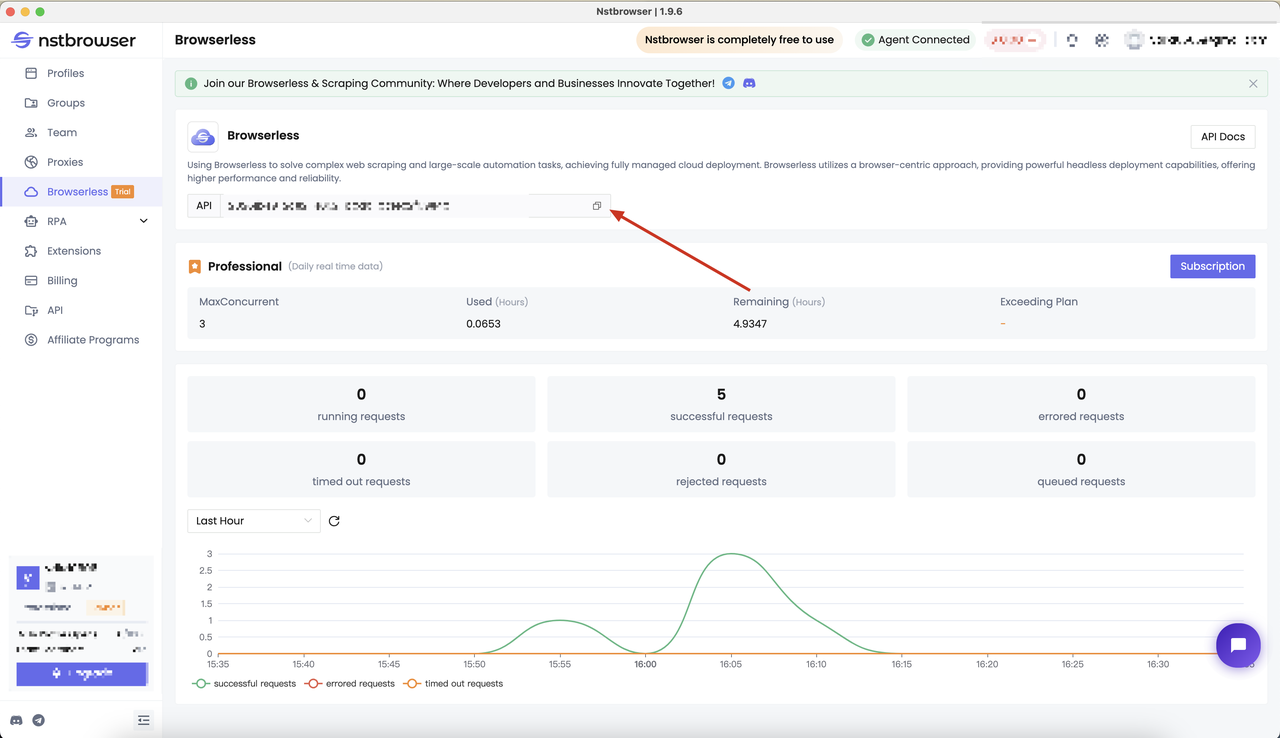
- Well, how to get the API KEY? Please open the Browserless menu page of the Nstbrowser client, or you can just go through our jump link.
Build a crawling framework
- Install puppeteer. Here we choose the more lightweight
puppeteer-core:
Bash
# pnpm
pnpm i puppeteer-core
# yarn
yarn add puppeteer-core
# npm
npm i --save puppeteer-core- The following code has been prepared for you in the Browserless document. You only need to fill in the
apiKeyandproxyto start the subsequent Browserless operations:
JavaScript
import puppeteer from "puppeteer-core";
const apiKey = "your ApiKey"; // required
const config = {
proxy: 'your proxy', // required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
// platform: 'windows', // support: windows, mac, linux
// kernel: 'chromium', // only support: chromium
// kernelMilestone: '128', // support: 128
// args: {
// "--proxy-bypass-list": "detect.nstbrowser.io"
// }, // browser args
// fingerprint: {
// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent supportted since v0.15.0
// },
};
const query = new URLSearchParams({
token: apiKey, // required
config: JSON.stringify(config),
});
const browserlessWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;Start crawling
Step 1. Connect Browserless and crawl stock prices
Before starting web scraping Yahoo Finance, we can observe the URL of Yahoo Finance first: https://finance.yahoo.com/quote/AAPL/. Among them, AAPL is the stock code.
Obviously, you can switch to the stock page you need to crawl by changing the stock code path. Then open the developer tool (F12) to check the HTML structure of the page and position the cursor at the current market price.
Next, we will try to crawl this price:
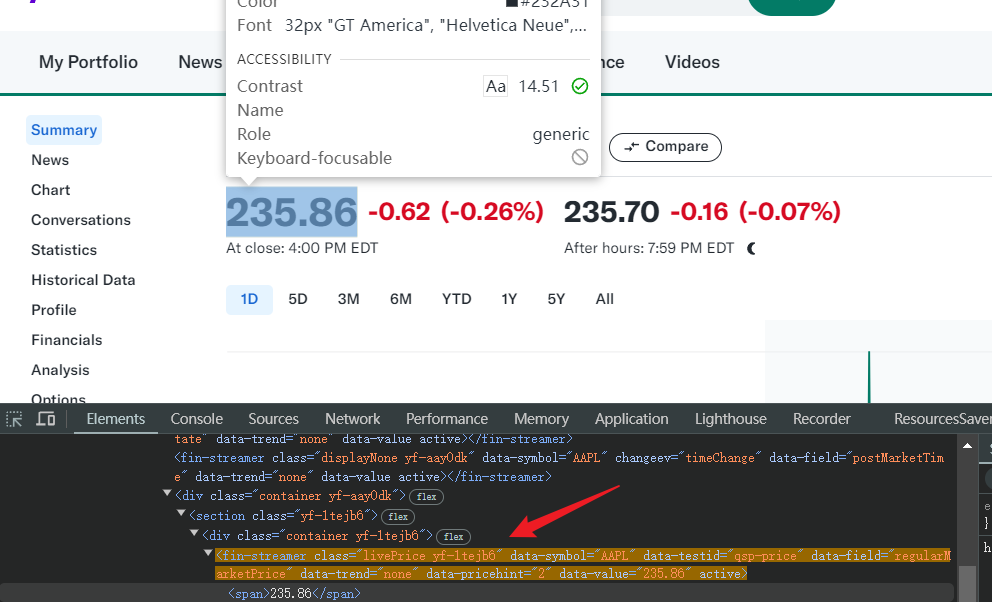
In the above preparations, we have obtained the Browserless connection port, so we can start crawling directly.
JavaScript
// connect to browserless
const browser = await puppeteer.connect({
browserWSEndpoint: browserlessWSEndpoint,
defaultViewport: null,
})
const page = await browser.newPage();
await page.goto('https://finance.yahoo.com/quote/AAPL');
// Add screenshots to facilitate subsequent troubleshooting
await page.screenshot({ path: 'yahoo.png' });
const selector = '[data-symbol="AAPL"][data-field="regularMarketPrice"]';
// Extract the inner text of an element matching a selector (i.e. a stock price)
const regularMarketPrice = await page.$eval(selector, el => el.innerText);
console.log(`Apple The current stock price is:${regularMarketPrice}`);Step 2. Skip Cookie Authorization
Wait! If we run the above script now, it will most likely fail. Why? Let's take a look at the screenshot finance.png generated when I run the script.
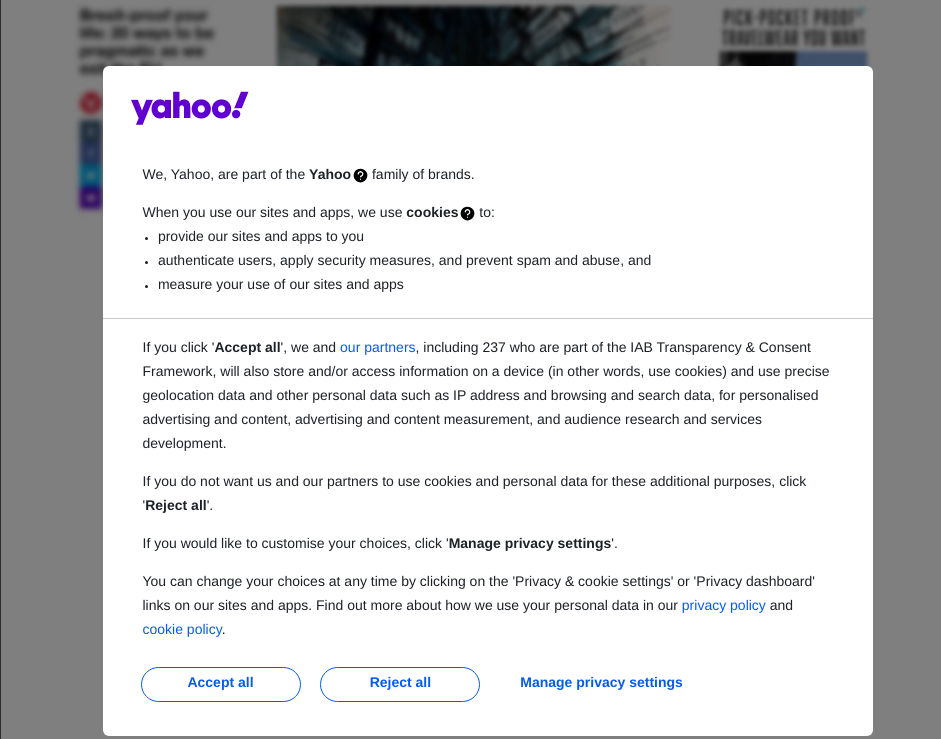
It can be seen that the crawling failure is caused by our not yet performing cookie authorization. Then we will use Puppeteer to help us skip cookie authorization:
- Open a new browser to re-trigger the cookie authorization page
- Use the development console to locate the
Accept allelement in the same way and obtain its corresponding class selector - Use puppeteer to click this element node
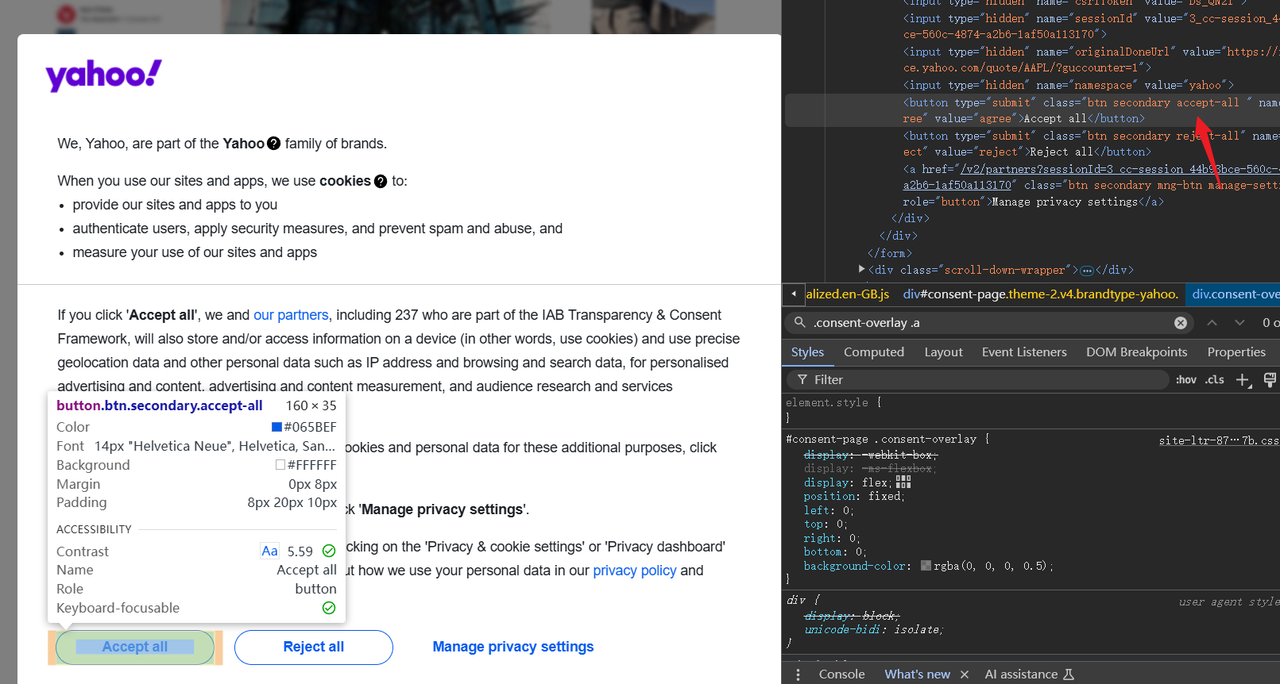
The above operations can be easily completed with just a few simple lines of code!
The following code is used to wait for the element with class .consent-overlay to appear on the page, and then click the "Accept all" (.accept-all) button in the layer. And we need to use the try catch to exclude the situation where the cookie has been authorized.
JavaScript
try {
await page.waitForSelector('.consent-overlay');
// click the "accept all" button
await page.click('.consent-overlay .accept-all');
} catch (e) {
console.log('Cookie has been authorized');
}- So the codes should be:
JavaScript
import puppeteer from "puppeteer-core";
const apiKey = "your ApiKey"; // 'your proxy'
const config = {
proxy: 'your proxy', // required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
// platform: 'windows', // support: windows, mac, linux
// kernel: 'chromium', // only support: chromium
// kernelMilestone: '128', // support: 128
// args: {
// "--proxy-bypass-list": "detect.nstbrowser.io"
// }, // browser args
// fingerprint: {
// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent supportted since v0.15.0
// },
};
const query = new URLSearchParams({
token: apiKey, // required
config: JSON.stringify(config),
});
const browserlessWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;
const browser = await puppeteer.connect({
browserWSEndpoint: browserlessWSEndpoint,
defaultViewport: null,
})
const page = await browser.newPage();
await page.goto('https://finance.yahoo.com/quote/AAPL/');
await page.screenshot({ path: 'yahoo.png' });
try {
await page.waitForSelector('.consent-overlay');
// click the "accept all" button
await page.click('.consent-overlay .accept-all');
} catch (e) {
console.log('Cookie has been authorized');
}
const selector = '[data-symbol="AAPL"][data-field="regularMarketPrice"]';
const regularMarketPrice = await page.$eval(selector, el => el.innerText);
console.log(`Apple The current stock price is:${regularMarketPrice}`);- The output:

Step 3. Improve the script and use the stock code as a script parameter
However, writing the stock code directly in the code is not flexible enough. So we'd better add the following code at the top of the script. The following code will force the script to be run with the script parameter: stock code.
JavaScript
const tickerSymbols = process.argv.slice(2);
if (tickerSymbols.length === 0) {
console.error('Ticker symbol CLI arguments missing!');
process.exit(2);
}Since there may be multiple stock codes, we need to define an array (stockList) to receive the crawled results. In the following code, we will use a simple loop to traverse and process the incoming stock code list.
JavaScript
// An array containing all the crawled data
const stockList = [];
for (const tickerSymbol of tickerSymbols) {
console.log(`Scraping data for: ${tickerSymbol}`);
// Navigate to Yahoo Finance page
await page.goto(`https://finance.yahoo.com/quote/${tickerSymbol}`);
try {
await page.waitForSelector('.consent-overlay');
// Click the "accept all" button
await page.click('.consent-overlay .accept-all');
} catch (e) { }
// Defining selectors using template literals and stock symbols
const selectors = {
regularMarketPrice: `[data-symbol="${tickerSymbol}"][data-field="regularMarketPrice"]`,
regularMarketChange: `[data-symbol="${tickerSymbol}"][data-field="regularMarketChange"]`,
regularMarketChangePercent: `[data-symbol="${tickerSymbol}"][data-field="regularMarketChangePercent"]`,
preMarketPrice: `[data-symbol="${tickerSymbol}"][data-field="preMarketPrice"]`,
preMarketChange: `[data-symbol="${tickerSymbol}"][data-field="preMarketChange"]`,
preMarketChangePercent: `[data-symbol="${tickerSymbol}"][data-field="preMarketChangePercent"]`
};
// Initialize an empty object to store financial data
const financialData = { tickerSymbol };
// Loop through each selector to extract the text content
for (const [key, selector] of Object.entries(selectors)) {
try {
financialData[key] = await page.$eval(selector, el => el.innerText);
// Remove brackets for percentage values
if (key.includes('ChangePercent')) {
financialData[key] = financialData[key].replace('(', '').replace(')', '');
}
} catch {
financialData[key] = 'N/A'; // If the element is not found, the value is set to N/A
}
}
// Add the financial data of the current stock symbol to the stock array
stockList.push(financialData);
}
console.log(JSON.stringify(stockList, null, 2));Run the following script:
JavaScript
node yahoo.mjs AAPL TSLAIf successful, the following will be printed on the console:
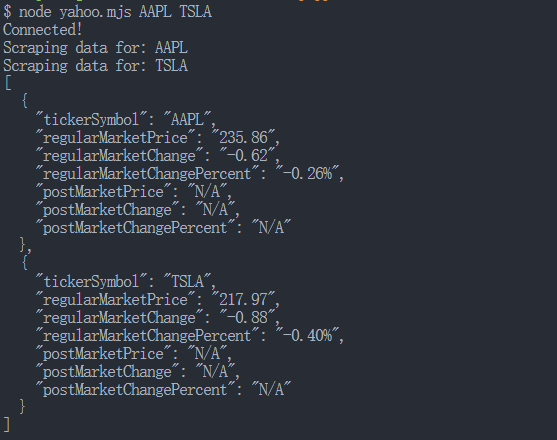
Step 4. Export data to CSV
Obviously, for better data analysis, it is not enough to just print the data in the console. Here is a simple example. Simply manually splice the following CSV, and then use the fs module to create a CSV file of the crawling results:
JavaScript
// Generate csv string and write to csv file
let csvData = 'Ticker Symbol,Regular Market Price,Regular Market Change,Regular Market Change Percent,Pre Market Price,Pre Market Change,Pre Market Change Percent\n';
stockList.forEach(stock => {
csvData += `${stock.tickerSymbol},${stock.regularMarketPrice},${stock.regularMarketChange},${stock.regularMarketChangePercent},${stock.preMarketPrice},${stock.preMarketChange},${stock.preMarketChangePercent}\n`;
});
fs.writeFileSync('stocks_data.csv', csvData);- The whole code:
JavaScript
import puppeteer from "puppeteer-core";
import fs from 'fs'
const tickerSymbols = process.argv.slice(2);
if (tickerSymbols.length === 0) {
console.error('Ticker symbol CLI arguments missing!');
process.exit(2);
}
const apiKey = "your ApiKey"; // 'your proxy'
const config = {
proxy: 'your proxy', // required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
// platform: 'windows', // support: windows, mac, linux
// kernel: 'chromium', // only support: chromium
// kernelMilestone: '128', // support: 128
// args: {
// "--proxy-bypass-list": "detect.nstbrowser.io"
// }, // browser args
// fingerprint: {
// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent supportted since v0.15.0
// },
};
const query = new URLSearchParams({
token: apiKey, // required
config: JSON.stringify(config),
});
const browserlessWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;
const browser = await puppeteer.connect({
browserWSEndpoint: browserlessWSEndpoint,
defaultViewport: null,
})
console.info('Connected!');
const page = await browser.newPage();
// An array containing all the crawled data
const stockList = [];
for (const tickerSymbol of tickerSymbols) {
console.log(`Scraping data for: ${tickerSymbol}`);
// Navigate to Yahoo Finance page
await page.goto(`https://finance.yahoo.com/quote/${tickerSymbol}`);
try {
await page.waitForSelector('.consent-overlay');
// Click the "accept all" button
await page.click('.consent-overlay .accept-all');
} catch (e) { }
// Defining selectors using template literals and stock symbols
const selectors = {
regularMarketPrice: `[data-symbol="${tickerSymbol}"][data-field="regularMarketPrice"]`,
regularMarketChange: `[data-symbol="${tickerSymbol}"][data-field="regularMarketChange"]`,
regularMarketChangePercent: `[data-symbol="${tickerSymbol}"][data-field="regularMarketChangePercent"]`,
preMarketPrice: `[data-symbol="${tickerSymbol}"][data-field="preMarketPrice"]`,
preMarketChange: `[data-symbol="${tickerSymbol}"][data-field="preMarketChange"]`,
preMarketChangePercent: `[data-symbol="${tickerSymbol}"][data-field="preMarketChangePercent"]`
};
// Initialize an empty object to store financial data
const financialData = { tickerSymbol };
// Loop through each selector to extract the text content
for (const [key, selector] of Object.entries(selectors)) {
try {
financialData[key] = await page.$eval(selector, el => el.innerText);
// Remove brackets for percentage values
if (key.includes('ChangePercent')) {
financialData[key] = financialData[key].replace('(', '').replace(')', '');
}
} catch {
financialData[key] = 'N/A'; // If the element is not found, the value is set to N/A
}
}
// Add the financial data of the current stock symbol to the stock array
stockList.push(financialData);
}
console.log(JSON.stringify(stockList, null, 2));
// Generate csv string and write to csv file
let csvData = 'Ticker Symbol,Regular Market Price,Regular Market Change,Regular Market Change Percent,Pre Market Price,Pre Market Change,Pre Market Change Percent\n';
stockList.forEach(stock => {
csvData += `${stock.tickerSymbol},${stock.regularMarketPrice},${stock.regularMarketChange},${stock.regularMarketChangePercent},${stock.preMarketPrice},${stock.preMarketChange},${stock.preMarketChangePercent}\n`;
});
fs.writeFileSync('stocks_data.csv', csvData);
await browser.close();Now, after running the script, you can not only see the console print, but also see the stocks_data.csv file written in the current path.

Check the Browserless Dashboard
You can view statistics for recent requests and remaining session time in the Browserless menu of the Nstbrowser client.
Ending Thoughts
Browserless of Nstbrowser is a powerful web scraping and automation tool. It can easily bypass detection and ensure stability when scraping stock prices. In this tutorial, you learned:
- Why Yahoo Finance is so important.
- How to extract data from it using Puppeteer and Browserless.
Yahoo Finance is a typical dynamic website with advanced data protection technology built in based on the powerful functions of JavaScript.
So, if you want to easily scrape Yahoo Finance data, you must use an equally powerful scraping tool. Our free Browserless provides you with the most convenient and fastest way to scrape. Just call a few lines of code, and you can do it.
Disclaimer: Any data and websites mentioned in this article are for demonstration purposes only. We firmly oppose illegal and infringing activities. If you have any questions or concerns, please contact us promptly.
More





