
Browserless
Deploy Headlesschrome in Docker: Run in Browserless
How to deploy headlesschrome in Docker? This blog will inspire you with detailed steps to using Browserless in Docker container.
Sep 18, 2024Robin Brown
What is Browserless?
Browserless is a cloud-based browser solution designed for effective browser automation, web scraping, and testing.
It utilizes Nstbrowser’s fingerprint library to enable random fingerprint switching, ensuring smooth data collection and automation. Thanks to its robust cloud infrastructure, Browserless simplifies access to multiple browser instances, making it easier to manage automation tasks.
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
How does Browserless work?
Browserless works by providing a headless browser as a service, which allows users to perform browser automation tasks without the need for a graphical interface.
It enables developers to run browser-based tasks, such as web scraping, automated testing, and rendering web pages, through APIs. By operating in a cloud environment, Browserless simplifies the process of automating browsers by eliminating the need for manual setup or maintaining browser infrastructure.
Browserless supports popular libraries like Puppeteer and Playwright, allowing users to interact with websites programmatically. Its Docker-based infrastructure allows for scalable and flexible deployment, making it efficient for both small-scale and enterprise-level applications. It can be integrated into workflows to automate repetitive tasks or gather data from websites that require a browser to access.
How to Deploy Headlesschrome in Docker?
Step 1: Get Your API Key
For a better experience, please create a new account on our official website.
Log in to the Nstbrowser client using the information you registered with. After successfully logging in, don't forget to generate your unique API key from the API menu!
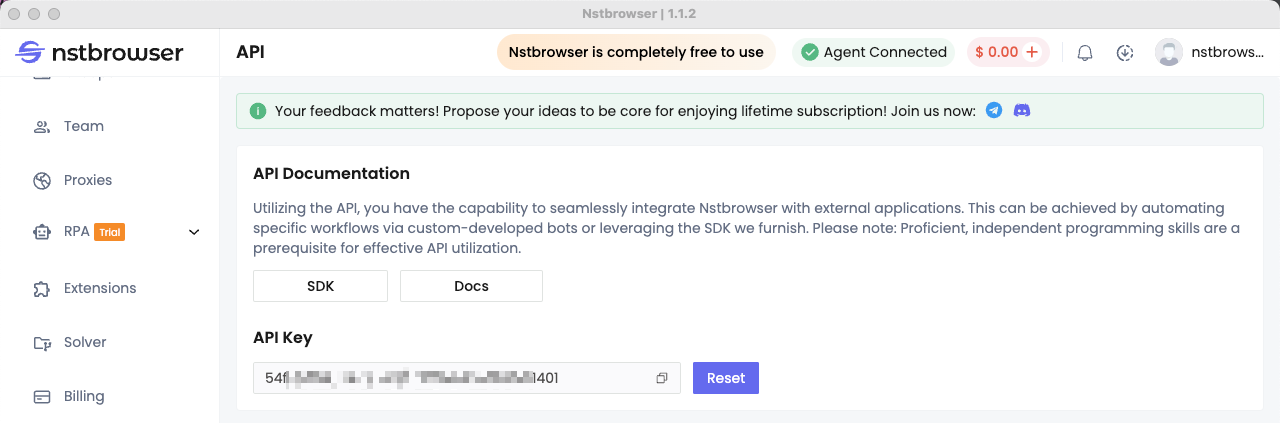
Step 2: Get the Nstbrowserless Image and Run
You need to get the API Key and replace the following {YOUR_API_KEY} part.
Bash
docker run -it -e TOKEN={YOUR_API_KEY} -e SERVER_PORT=8848 -p 8848:8848 --name nstbrowserless nstbrowser/browserless:0.0.1-beta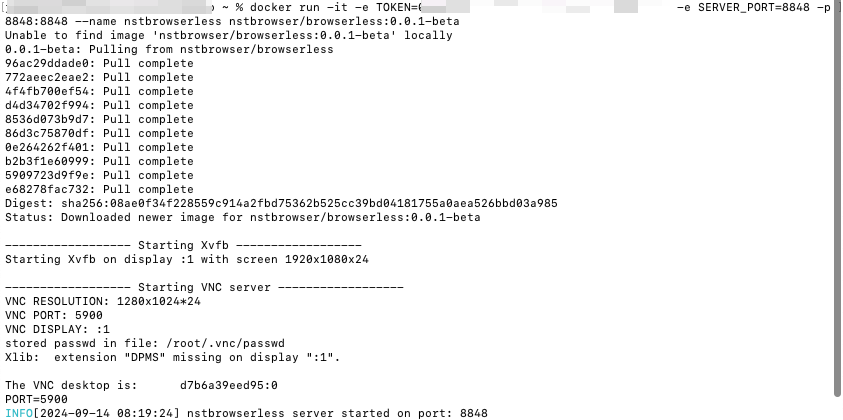
How to use Browserless in Docker Container?
You can connect to the headless browser through Puppeteer, Playwright, Chromedp or other CDP libraries to achieve the operation and screenshot functions of the headless browser.
Puppeteer
Puppeteer is a Node.js library that provides a high-level API to control the Chrome browser and supports operations through the DevTools protocol.
- Install Puppeteer
Bash
npm install puppeteer- Prepare the
puppeteer.jsfile
JavaScript
const puppeteer = require("puppeteer");
(async () => {
const host = "127.0.0.1:8848"; // Replace with your Docker container IP
const browserWSEndpoint = `ws://${host}/ws/connect`;
try {
const browser = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint,
});
const page = await browser.newPage();
await page.goto("https://google.com", { waitUntil: 'networkidle2' }); // Wait for the network to be idle
await page.screenshot({ path: "screenshot.png", fullPage: true }); // Take a full-page screenshot
console.log("Screenshot taken and saved as screenshot.png");
await browser.close(); // Close the browser connection
} catch (err) {
console.error("Error occurred:", err);
}
})();- Run your scripts
Bash
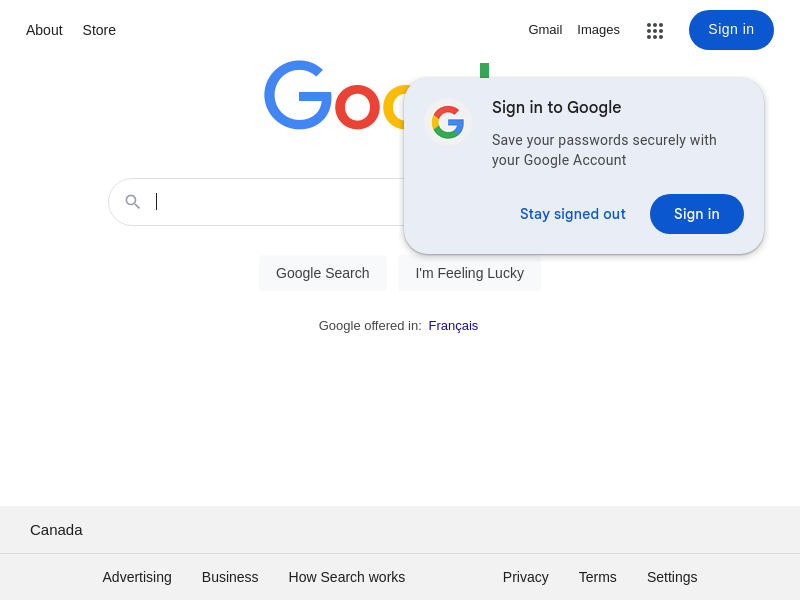
node puppeteer.jsAfter running, you can see that the headless browser is working as we wished:

Now, the project has finished, you can figure out the generated screenshot.png:
Playwright CDP
Playwright is a framework for web testing and automation that allows testing the Chrome browser through a single API.
- Install the Playwright
Bash
npm install playwright- Prepare the playwright.js file
JavaScript
import { chromium } from "playwright";
(async () => {
const host = "127.0.0.1:8848"; // replace with your Docker container IP
const browserWSEndpoint = `ws://${host}/ws/connect`;
try {
const browser = await chromium.connectOverCDP(browserWSEndpoint);
const context = await browser.newContext();
const page = await context.newPage();
await page.goto("https://www.google.com/", { waitUntil: 'networkidle' }); // wait for the network to be idle
await page.screenshot({ path: "screenshot.png" }); // take a full-page screenshot
console.log("Screenshot taken and saved as screenshot.png");
await browser.close(); // close the browser connection
} catch (err) {
console.error("Error occurred:", err);
}
})();- Run your scripts
Bash
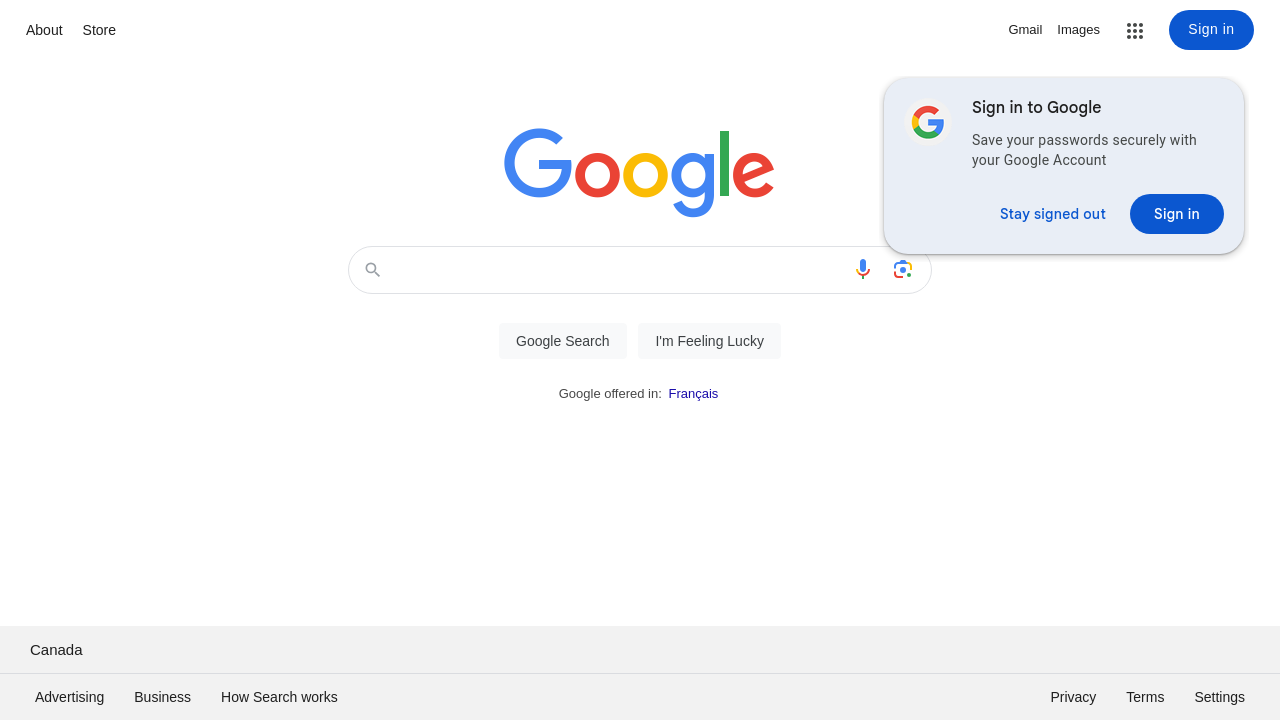
node playwright.jsSame as Puppeteer, after running, you can figure out the generated screenshot.png as well.
The Bottom Lines
Browserless makes web scraping and automation easy. In this blog, you can see:
- The effective way to deploy headlesschrome in Docker.
- Detailed steps to use Browserless in Docker container.
Running a browser inside a container provides a lot of flexibility and scalability. It is also much cheaper than traditional VM-based instances.
Nstbrowser gives you the optimal solution. Try Browserless for free now!
More





