
Browserless
Playwright Web Scraping: in Docker of Browserless
Running Playwright in Docker is the second game-changer! What about the basics of Docker? How to do Playwright web scraping in Docker? Find out in this blog.
Aug 23, 2024Robin Brown
Be Familiar with Docker
What is Docker? Do you still remember the shipping industry and the development of standardized containers in the mid-20th century?
The introduction of containers allowed people to use large machinery such as cranes to load and unload goods. This greatly reduced shipping time and costs, making cargo transportation faster and more efficient than ever before. Therefore, it contributed to the prosperity of the shipping industry to a great extent.
Yes, Docker is like containers in the field of software development: introducing a standardized, container-based approach to packaging, distributing, and running applications. It greatly accelerates the development of the dev field.
In simple terms, Docker is a tool that allows developers to easily deploy their applications into sandboxes (called Docker containers) to run on the host operating system (i.e. Linux).
What Benefits Does Docker Give?
- Isolated Execution Environment
- Simplified Testing
- Reliability and Consistency at Scale
- Faster Feature Delivery
What is Browserless?
Browserless is a cloud-based clustered browser solution tailored for efficient browser automation, web scraping, and testing.

Built on Nstbrowser’s fingerprint library, it offers random fingerprint switching for seamless data collection and automation. With its strong cloud infrastructure, Browserless enables easy access to multiple browser instances, streamlining the management of automation tasks.
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
How Do You Use the Docker Image of Nstbrowser?
Before you start using Nstbrowser's Docker image, make sure you've completed the following steps:
- Ensure you have Docker set up. If Docker isn't installed on your system yet, please follow the instructions in Docker Docs.
- Obtain a Nstbrowser account. If you haven't registered yet, you can sign up on the official Nstbrowser website.
- After your account is ready, visit the following page to retrieve your API key.
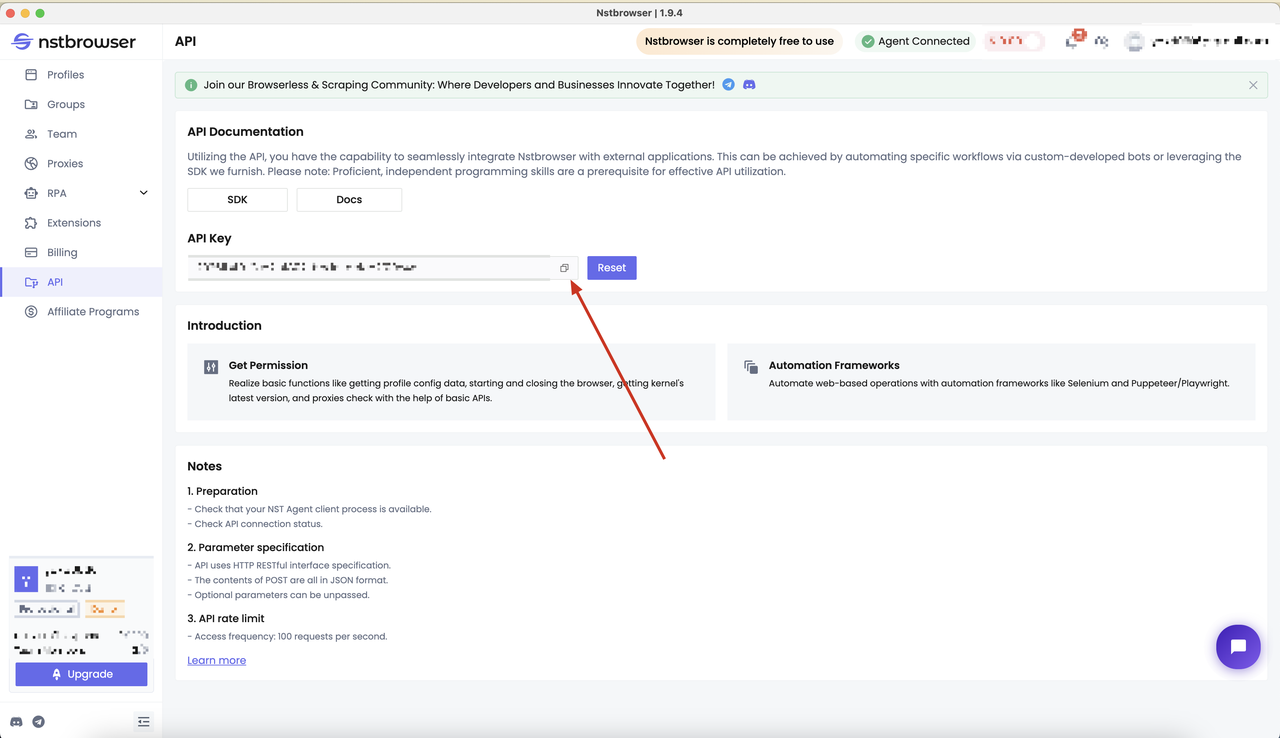
Once these preparations are done, you can pull the Nstbrowser Docker image using the following command:
Bash
# Pull the Browserless image
docker pull nstbrowser/browserless:0.0.1-beta
# Run the Browserless image
docker run -it -e TOKEN=xxx -e SERVER_PORT=8848 -p 8848:8848 --name nstbrowserless nstbrowser/browserless:0.0.1-beta
# After running, you can use the docker ps command to check whether the container is running properly
docker ps
Crawling Dynamic Websites with Playwright in Docker
Now, let's figure out how to use Playwright based on the Nstbrowser Docker image to crawl dynamic websites! Don't be confused!
Here you can find the step-by-step to complete a simple example.
Step 1: Determine crawl targets
We must identify the information we want to crawl at the beginning. In this example, we choose to crawl all the article titles of Hacker News and store the crawled content locally.
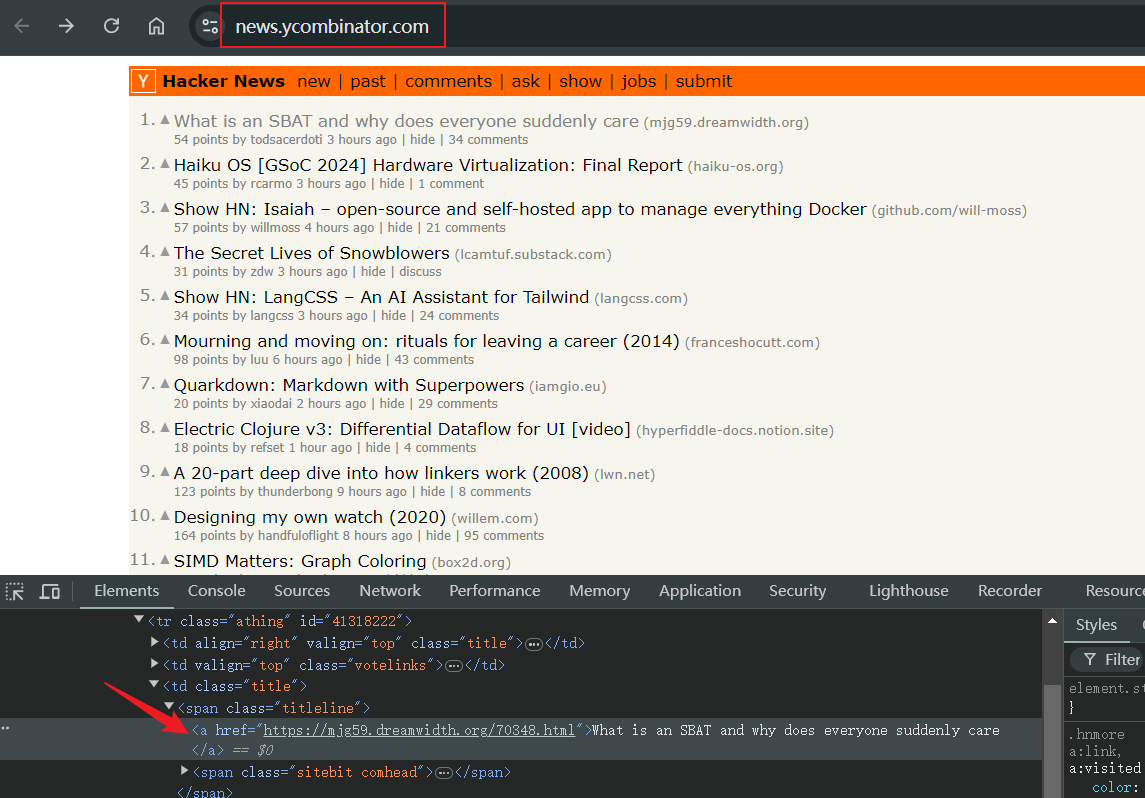
Step 2: Writing a Playwright Script
Next, it's time to write a Playwright script to crawl our target. This is where Playwright can be used to get to the target page and retrieve the article title.
In the following example, we'll connect to the Browserless port in our docker container to run the script. Don't hesitate to have a check!
JavaScript
import { chromium } from 'playwright'
// Start the browser
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');
await page.waitForSelector('.titleline > a')
// Grab the article title
const titles = await page.$$eval('.titleline > a', elements =>
elements.map(el => el.innerText)
);
// Output the captured title
console.log('Article title:');
titles.forEach((title, index) => console.log(`${index + 1}: ${title}`));Step 3: Project Initialization
How about your script's working condition? Before scraping with Browserless, we also need to initialize a new project:
Bash
cd ~
makedir playwright-docker
cd playwright-dockerStep 4: Connect to Browserless and start crawling
Scraping time! Now let's try to connect to the Browserless port in the docker container in Playwright.
- Prepare the configuration information for the interface:
JavaScript
const host = 'host.docker.internal:8848';
const config = {
once: true,
headless: true, // Set headless mode
autoClose: true,
args: { '--disable-gpu': '', '--no-sandbox': '' }, // browser args should be a dictionary
fingerprint: {
name: '',
platform: 'mac',
kernel: 'chromium',
kernelMilestone: 124,
hardwareConcurrency: 8,
deviceMemory: 8,
},
};
const browserWSEndpoint = `ws://${host}/ws/connect?${encodeURIComponent(
JSON.stringify(config)
)}`;- Connect via
connectOverCDP:
JavaScript
const { chromium } = require('playwright');
async function execPlaywright() {
const browser = await chromium.connectOverCDP(browserWSEndpoint);
const context = await browser.newContext();
const page = await context.newPage();
}- Scraping the web
JavaScript
const { chromium } = require('playwright');
async function execPlaywright() {
try {
const browser = await chromium.connectOverCDP(browserWSEndpoint);
const context = await browser.newContext();
const page = await context.newPage();
// Navigate to the target URL
await page.goto('https://news.ycombinator.com/');
// Wait for element to load
await page.waitForSelector('.titleline > a')
// Grab the article title
const titles = await page.$$eval('.titleline > a', elements =>
elements.map(el => el.innerText)
);
// Output the captured title
console.log('Article title:');
titles.forEach((title, index) => console.log(`${index + 1}: ${title}`));
// Close the browser
await browser.close();
} catch (err) {
console.error('launch', err);
}
}
execPlaywright().then()Step 5: Storing crawl results
For subsequent data analysis, you can use the basic Node.js module fs to write the data to a JSON file. Here is a simple tool function:
JavaScript
import fs from 'fs';
// Save as a JSON file
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2);
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}The complete code is below. After running, you can find the Hacker News_log.json file in the current script execution path, which logs all the crawling results!
JavaScript
const fs = require('fs')
const { chromium } = require('playwright');
const host = 'host.docker.internal:8848';
const config = {
once: true,
headless: true, // Set headless mode
autoClose: true,
args: { '--disable-gpu': '', '--no-sandbox': '' }, // browser args should be a dictionary
fingerprint: {
name: '',
platform: 'mac',
kernel: 'chromium',
kernelMilestone: 124,
hardwareConcurrency: 8,
deviceMemory: 8,
},
};
const browserWSEndpoint = `ws://${host}/ws/connect?${encodeURIComponent(
JSON.stringify(config)
)}`;
async function execPlaywright() {
try {
const browser = await chromium.connectOverCDP(browserWSEndpoint);
const context = await browser.newContext();
const page = await context.newPage();
// Navigate to the target URL
await page.goto('https://news.ycombinator.com/');
// Wait for element to load
await page.waitForSelector('.titleline > a')
// Grab the article title
const titles = await page.$$eval('.titleline > a', elements =>
elements.map(el => el.innerText)
);
// Output the captured title
console.log('Article title:');
titles.forEach((title, index) => console.log(`${index + 1}: ${title}`));
// data storage
saveObjectToJson(titles.map((title, index) => ({ [index + 1]: title })), 'Hacker News_log.json')
// Close the browser
await browser.close();
} catch (err) {
console.error('launch', err);
}
}
// Save as a JSON file
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2);
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
execPlaywright().then();6 Key Components of Docker
- Docker Engine: It is the core part of Docker that handles the creation and management of containers.
- Dockerfile: The Dockerfile uses DSL (Domain Specific Language) and contains instructions for generating Docker images. You should create the Dockerfile in order when creating your application, as the Docker daemon will run all the instructions from top to bottom.
- Docker Image: it is a read-only template for creating instructions for a Docker container that contains application code and dependencies. Docker Image consists of files with multiple layers for executing code in Docker containers.
- Docker Container: The Docker container is a runtime instance of a Docker image. Allows developers to package the application with all the required parts, such as libraries and other dependencies.
- Docker Hub: It is a cloud-based repository for finding and sharing container images. It offers features like you can push images to private or public registries where you can store and share Docker images.
- Docker Registry: It is a storage distribution system for docker images where you can store images in public and private mode.
6 Important Docker Commands
- Docker Run: start the container from the image and specify runtime options and commands.
- Docker Pull: extracts the container image from the container registry to the local machine.
- Docker ps: displays the running container and its important information like container ID, image used, and status.
- Docker Stop: stop the running container normally and shut down the processes in it.
- Docker Start: restart the stopped container and resume its operation from the previous state.
- Docker Login: login to the Docker registry so that you can access the private repository.
Ending Thoughts
We have finished anything we need for Playwright web scraping in Docker! You've learned:
- The basics of Docker
- Introduction to Browserless and how to use it
- How to do web scraping in Browserlss
Overall, Docker is all about helping to streamline the process and ensuring that Playwright runs in a consistent environment with the necessary services and data to ensure efficient web scraping.
Now start discovering more about the mysteries of Browserless!
More





