
Headless Browser
How to use Nstbrowser docker to crawl YouTube videos?
This tutorial uses the Nstbrowser Docker image to demonstrate crawling YouTube video links
Jan 08, 2025Carlos Rivera
We've got an incredible 90% Off Subscription Deal just for you! Now, you can enjoy the following unbeatable prices:
- Professional Plan: Only **29.9/month** (original price 299)
- Enterprise Plan: Only **59.9/month** (original price 599)
What’s more, you’ll keep enjoying these discounts with auto-renewal! No extra steps needed—your discount will be automatically applied at renewal.
Prerequisites
Before we officially start, we need to understand Nstbrowser.
Nstbrowser is a powerful fingerprint browser that can be configured with multiple fingerprints, which is helpful to avoid some headaches in large-scale crawling tasks, such as robot detection, verification code recognition and IP blocking, and can effectively prevent identification and tracking of visited sites.
First, we need to get the API Key in Nstbrowser.
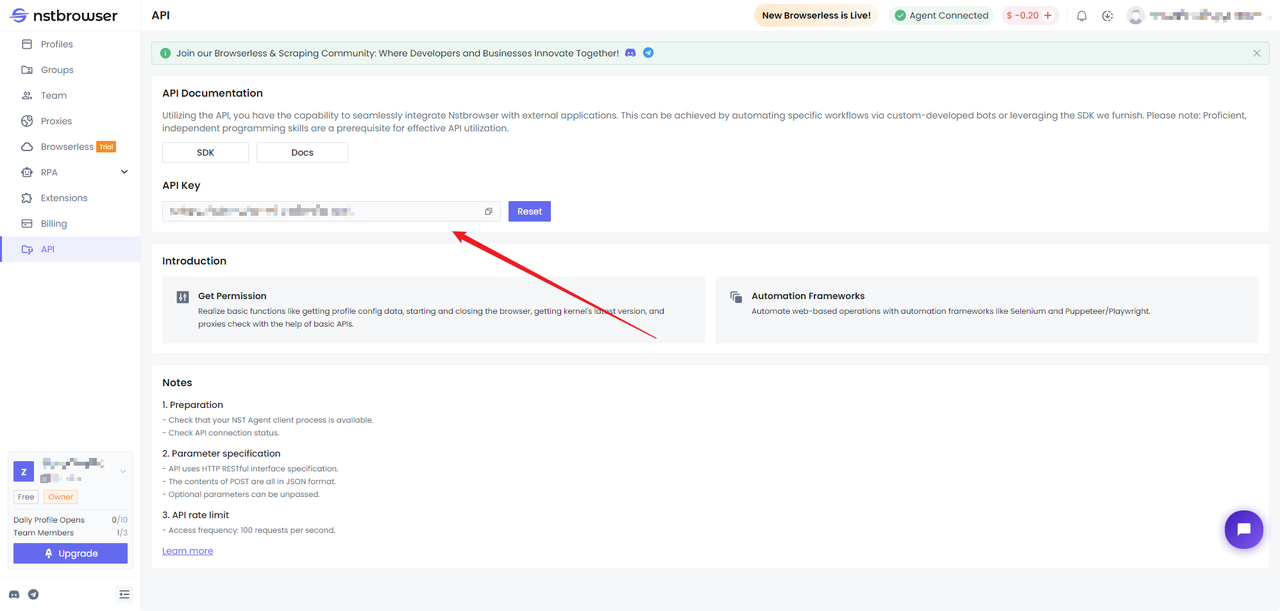
Step 1. Pull the Nstbrowser Docker image
Bash
docker pull docker.io/nstbrowser/browserless:latestStep 2. Run the container
Bash
docker run -d -it \
-e TOKEN="YOU API KEY" \
-p 8848:8848 \
--name nstbrowserless \
nstbrowser/browserless:latestStep 3. Build a crawling script
Here we use puppeteer-core for demonstration
- Install
puppeteer-core:
Bash
# pnpm
pnpm i puppeteer-core
# yarn
yarn add puppeteer-core
# npm
npm i --save puppeteer-core- Prepare Nstbrowser Docker configuration
Only a partial configuration list is listed here. For all configurations, please refer to the Nstbrowser API Document: https://apidocs.nstbrowser.io/api-10293510.
JavaScript
async function start() {
const config = {
"name": "testProfile",
"platform": "windows",
"kernel": "chromium",
// "proxy": "http://127.0.0.1:8000", //Nstbrowser Docker support the use of proxy for network access
// "doProxyChecking": false,
// "fingerprint": { // configure the required fingerprint information to bypass tracking at visiting sites
// "flags": {
// "timezone": "BasedOnIp",
// "screen": "Custom"
// },
// "screen": {
// "width": 1000,
// "height": 1000
// },
// "userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.6723.60 Safari/537.36"
// },
// "args": { //support configure browser startup parameters
// "--proxy-bypass-list": "*.nstbrowser.io"
// }
};
const query = new URLSearchParams({
config: encodeURIComponent(JSON.stringify((config))),
});
const browserWSEndpoint = `ws://localhost:8848/connect?${query.toString()}`;
await execPuppeteer(browserWSEndpoint);
}- Start grabbing the video elements on youtube
- First, we use the browser's developer tools (F12) to get the search bar element and the click search button element on youtube:
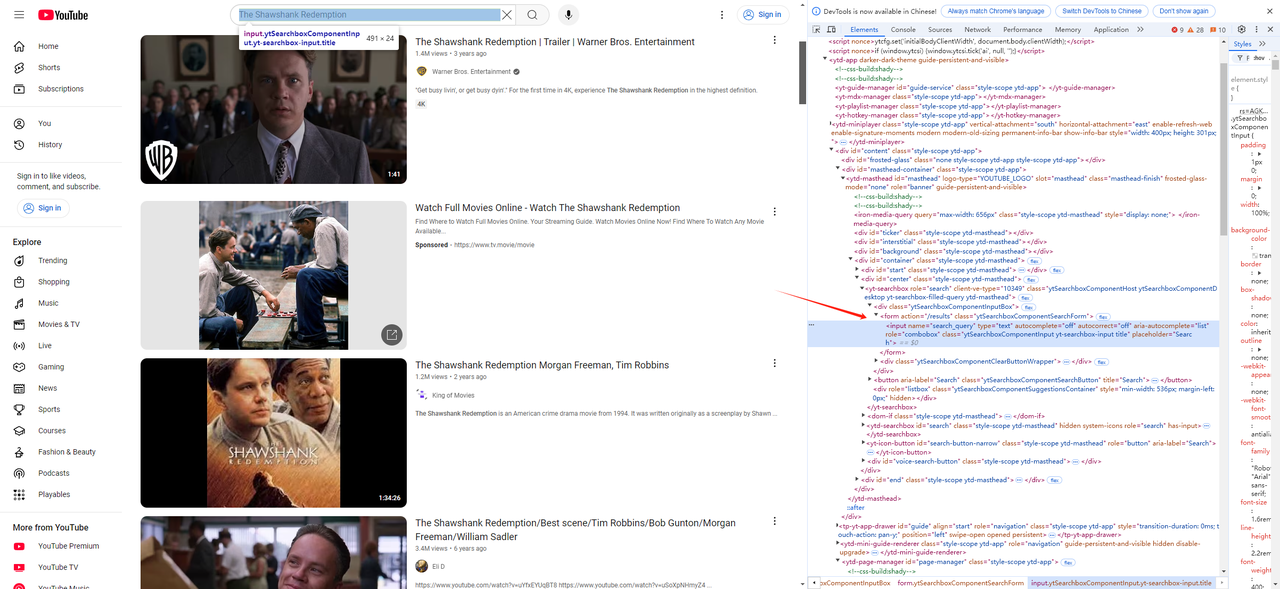
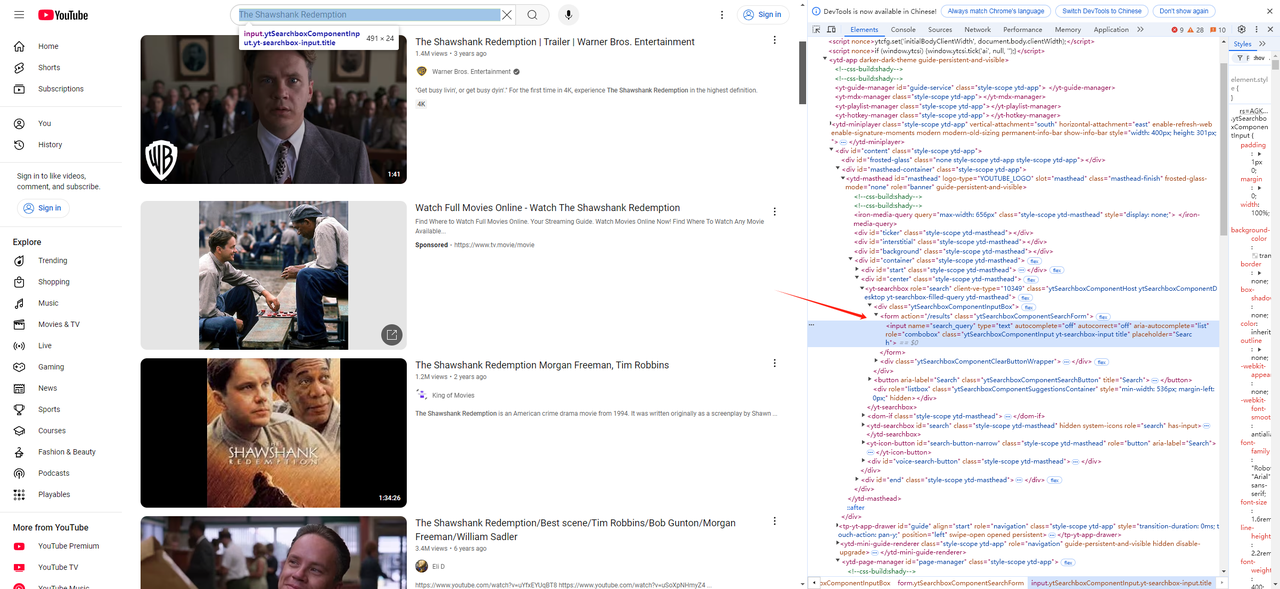
Next, write the input search script and click search script:
JavaScript
async function execPuppeteer(browserWSEndpoint) {
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
});
const page = await browser.newPage();
// visit youtube
await page.goto('https://www.youtube.com');
// enter a search term
await page.type('#center > yt-searchbox > div.ytSearchboxComponentInputBox > form > input', 'The Shawshank Redemption', { delay: '100' }) // Here, delay is used to delay the interval event of each character input to simulate the scene of real user input.
// click the search button
await page.click('yt-searchbox button[aria-label=Search]')
// wait for a page element to render
await page.waitForSelector('ytd-video-renderer ytd-thumbnail >a')- Use the same method to find the video information we need:
JavaScript
// the ytd-video-renderer tag is a per-video item element
const videoElement = await page.$$('ytd-video-renderer')- Extract video title, channel number, link and other information from tags:
JavaScript
const renderList = []
for (const element of videoElement) {
const link = await element.$('ytd-thumbnail > a').then((el) => {
return el.evaluate((ele) => {
return `https://www.youtube.com${ele.getAttribute('href')}`;
})
})
const title = await element.$('ytd-thumbnail + div yt-formatted-string').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
const channel = await element.$('ytd-thumbnail + div > div[id=channel-info] yt-formatted-string >a').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
renderList.push({
channel,
title,
link
})
}
console.log("renderList:", renderList)- Run the above script, we can get the video data on youtube:
JavaScript
renderList: [
{
channel: 'Warner Bros. Entertainment',
title: 'The Shawshank Redemption | Trailer | Warner Bros. Entertainment',
link: 'https://www.youtube.com/watch?v=PLl99DlL6b4&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
{
channel: 'King of Movies',
title: 'The Shawshank Redemption Morgan Freeman, Tim Robbins',
link: 'https://www.youtube.com/watch?v=XIv97tIImz8&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
{
channel: 'Eli D',
title: 'The Shawshank Redemption/Best scene/Tim Robbins/Bob Gunton/Morgan Freeman/William Sadler',
link: 'https://www.youtube.com/watch?v=0spucxvMfjE&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
.......
{
channel: 'BBC Global',
title: 'How The Shawshank Redemption went from flop to hit | BBC Global',
link: 'https://www.youtube.com/watch?v=jbn9IgCIeB4&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
{
channel: 'Turner Classic Movies',
title: 'Tim Robbins and Morgan Freeman reflect on 30 years of THE SHAWSHANK REDEMPTION | TCMFF 2024',
link: 'https://www.youtube.com/watch?v=pYmAy3H0s3Q&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
}
]The whole codes:
JavaScript
import puppeteer from 'puppeteer-core';
import express from "express";
async function execPuppeteer(browserWSEndpoint, search) {
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
});
const page = await browser.newPage();
await page.goto('https://www.youtube.com');
await page.type('#center > yt-searchbox > div.ytSearchboxComponentInputBox > form > input', search, { delay: '100' })
await page.click('yt-searchbox button[aria-label=Search]')
await page.waitForSelector('ytd-video-renderer ytd-thumbnail >a')
const videoElement = await page.$$('ytd-video-renderer')
const renderList = []
for (const element of videoElement) {
const link = await element.$('ytd-thumbnail > a').then((el) => {
return el.evaluate((ele) => {
return `https://www.youtube.com${ele.getAttribute('href')}`;
})
})
const title = await element.$('ytd-thumbnail + div yt-formatted-string').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
const channel = await element.$('ytd-thumbnail + div > div[id=channel-info] yt-formatted-string >a').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
renderList.push({
channel,
title,
link
})
}
console.log(renderList);
await browser.close();
return renderList;
} catch (err) {
console.log(`Error fetching ${selector}:`, e);
}
}
async function start(search) {
const config = {
"name": "testProfile",
"platform": "windows",
"kernel": "chromium",
"kernelMilestone": "130",
// "proxy": "http://127.0.0.1:8000",
// "doProxyChecking": false,
// "fingerprint": {
// "flags": {
// "timezone": "BasedOnIp",
// "screen": "Custom"
// },
// "screen": {
// "width": 1000,
// "height": 1000
// },
// "userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.6723.60 Safari/537.36"
// },
// "args": {
// "--proxy-bypass-list": "*.nstbrowser.io"
// }
};
const query = new URLSearchParams({
config: encodeURIComponent(JSON.stringify((config))),
});
const browserWSEndpoint = `ws://localhost:8838/connect?${query.toString()}`;
return await execPuppeteer(browserWSEndpoint, search);
}
const app = express();
app.get("/youtube/:search", async (req, resp) => {
const search = req.params.search;
const renderList = await start(search);
resp.send({ "code": 200, "data": renderList })
})
app.listen(8080, () => console.log("Listening on PORT: 8080"))Nstbrowser Docker API usage
During the running process, you can also call other APIs in the container service to operate the browser in the container
- http://localhost:8848/start
- Method: POST
Step 1. Start a new browser instance:
JavaScirpt
request:
{
"name": "testProfile",
"once": true,
"platform": "windows",
"kernel": "chromium",
"kernelMilestone": "130",
"fingerprint": {
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.6613.85 Safari/537.36"
}
}
response:
{
"data": {
"profileId": "4a9911a9-6d28-41b9-8bf4-cc08592afcbd",
"port": 31685,
"webSocketDebuggerUrl": "ws://127.0.0.1:31685/devtools/browser/19df3c03-2b13-49db-ac1d-989bb68a353f"
},
"err": false,
"msg": "success",
"code": 200
}Step 2. After the startup is complete, you can directly connect to the browser just started through the URL of the webSocketDebuggerUrl parameter to execute other script commands.
- http://localhost:8848/stop/{profileId}
- Method: GET
Close the browser instance of the specified profileId:
JavaScript
response:
{
"data": null,
"err": false,
"msg": "success",
"code": 200
}- http://localhost:8848/stopAll
- Method: GET
Close all browser instances:
JavaScript
response:
{
"data": null,
"err": false,
"msg": "success",
"code": 200
}- http://localhost:8848/running
- Method: GET
Get all running browser instances:
JavaScript
response:
{
"data": [
{
"profileId": "605ffe1f-7bdf-4ac7-b0bb-70746cb92a0f",
"remoteDebuggingPort": 26192,
"running": true,
"starting": false,
"stopping": false
},
{
"profileId": "8693f526-5a9f-4669-86db-c48866921ffc",
"remoteDebuggingPort": 45850,
"running": true,
"starting": false,
"stopping": false
}
],
"err": false,
"msg": "success",
"code": 200
}- http://localhost:8848/json/list/{profileId}
- Method: GET
Get the page list opened by the browser instance. Through the page list, we can check the browser operation status at any time:
JavaScript
response:
{
"data": [
{
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=127.0.0.1:45850/devtools/page/401571FE7D5A477074F539B39AEE0EC6",
"id": "401571FE7D5A477074F539B39AEE0EC6",
"title": "tiktok - Google Search",
"type": "page",
"url": "https://www.google.com/search?q=tiktok&oq=tikto&gs_lcrp=EgZjaHJvbWUqDQgAEAAYgwEYsQMYgAQyDQgAEAAYgwEYsQMYgAQyBggBEEUYOTINCAIQABiDARixAxiABDIKCAMQABixAxiABDIKCAQQABixAxiABDIKCAUQABixAxiABDIHCAYQABiABDIHCAcQABiABDIKCAgQABixAxiABDINCAkQLhiDARixAxiABNIBCTgyMzJqMGoxNagCALACAA&sourceid=chrome&ie=UTF-8",
"webSocketDebuggerUrl": "ws://127.0.0.1:45850/devtools/page/401571FE7D5A477074F539B39AEE0EC6"
},
{
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=127.0.0.1:45850/devtools/page/293BECFB09421FE88DB74CB222AFDCA6",
"id": "293BECFB09421FE88DB74CB222AFDCA6",
"title": "The Shawshank Redemption - YouTube",
"type": "page",
"url": "https://www.youtube.com/results?search_query=The+Shawshank+Redemption",
"webSocketDebuggerUrl": "ws://127.0.0.1:45850/devtools/page/293BECFB09421FE88DB74CB222AFDCA6"
}
],
"err": false,
"msg": "success",
"code": 200
}The End Thoughts
Nstbrowser Docker provides a convenient Nstbrowser fingerprint browser service. Through docker container technology, it can well isolate the complex environment on the host machine and support running Nstbrowser browser services on different platforms. Container isolation can run multiple instances locally, crawl data on different websites, and achieve anti-user tracking.
More





