
Headless Browser
如何在 Playwright 中运行无头浏览器?
什么是无头浏览器?它的优缺点如何?在本博客中,我们可以找到关于它的所有信息,并学习如何使用 Nstbrowserless 进行网络抓取。
Jul 16, 2024Carlos Rivera
传统的带有GUI的浏览器在工作负载增加时通常会消耗大量的系统资源。此外,它需要一个可见窗口来渲染网页,这会减慢测试执行速度并限制可扩展性。
一个无头浏览器(headlesschrome)是一种无需真实浏览器就能顺利抓取动态内容的工具。
它可以解决资源密集型测试的问题,从而提高测试执行效率和可扩展性。
那么如何在Python和Selenium中运行无头浏览器呢?
现在开始阅读这篇文章吧!
什么是Python Headlesschrome?
浏览器是一个计算机程序,允许用户浏览和与网页交互。另一方面,无头浏览器没有图形用户界面。那么它能做什么呢?是否有很大不同?是的!这个功能帮助Python headlesschrome:
- 浏览互联网上的任何网站。
- 渲染网站提供的JavaScript文件。
- 与该网页的组件交互。
哦,等等!你可能会问我们如何与无头浏览器互动。没有GUI呀!
别担心。让我向你展示 Web Driver。
另一个问题——那是什么?Web Driver是一个框架。它允许我们通过编程控制各种网络浏览器。
有没有典型的例子?当然有,我们都熟悉的Selenium。我们经常使用它,但你知道它也是一个重要的无头浏览器吗?
Python Headlesschrome的优点:
- 自动化任务。无头浏览器可以自动执行浏览器操作,如点击、填写表单、提交等。适用于自动化测试和任务自动化。
- 使用更少的存储。它不需要为浏览器和网站绘制图形元素。
- 非常快。无头浏览器不需要等待页面完全加载,可以显著加快抓取过程。
- 模拟真实用户行为。它可以模拟用户的浏览器环境和行为,有助于绕过反机器人检测。
- 灵活性。它可以通过编程轻松控制浏览器行为,如设置请求头、处理cookie、处理页面元素等。这对复杂的数据收集或操作非常有帮助。
- 适应性强。无头浏览器能够处理各种网站和动态内容,如单页应用(SPA)或需要JavaScript渲染的页面。
Python Headlesschrome的缺点:
- 缺乏可视化渲染进行调试和测试。无头浏览器在测试执行期间不渲染页面,可视化调试和测试变得更加困难。
- 稳定性和可靠性问题。由于网站结构的变化或网络问题,无头浏览器需要及时处理。
- 更新维护。依赖第三方库和浏览器版本更新,可能需要定期更新代码以适应新的浏览器功能或修复漏洞。
- 反爬措施。网站总是会检测并阻止自动访问。因此,你需要采取一些反机器人检测措施,如设置适当的请求头、模拟人类行为等。
Nstbrowser可以高度模拟人类行为以绕过反机器人检测和解锁网站!
立即免费试用!
您对网页抓取和 Browseless 有什么好的想法或疑惑吗?
快来看看其他开发人员在 Discord 和 Telegram 上分享了什么!
Python Selenium支持的6个无头浏览器
Selenium非常强大!它支持多少个无头浏览器呢?让我们现在来找出其中的6个!它们主要通过Web Driver进行控制和操作。
- Chrome
- Firefox
- Edge
- Safari
- Opera
- Chromium
Python headlesschrome的3个最佳替代品?
Python Selenium headlesschrome并不是唯一的无头浏览器!
让我们看看其他替代品。有些只提供一种编程语言,而其他的可以提供多种语言绑定。
1. Puppeteer
Puppeteer是由Google开发的一个Node.js库。它提供了一个高级API,用于控制无头的Chrome或Chromium浏览器。Puppeteer提供了强大的功能来自动化浏览器任务、生成截图和PDF、以及在网页中执行JavaScript代码。
2. Playwright
Playwright是另一个由微软贡献者开发的网页自动化工具。本质上它也是一个Node.js库,用于浏览器自动化,但它为其他语言(如Python、.NET和Java)提供了API。与Python Selenium相比,它相对较快。
3. Nstbrowser
什么是Nstbrowser?
Nstbrowser是一个完全免费的反检测浏览器。它在无头模式下实现云端网页抓取,完全不受本地资源的限制。轻松实现网页抓取和自动化流程。
- 轻松执行大规模并发任务,有效节省资源和时间。
- 运行任何脚本并使用无头浏览器执行复杂的浏览器操作或网页抓取任务。
- 跟踪RAM、CPU和GPU使用情况,确保浏览器消耗适当的资源。
- 通过动态分配资源来响应突发流量,以平衡和扩展负载。
- 提供专用服务器实例,享受更高的性能、更灵活的配置选项和更好的隔离。
如何使用Nstbrowserless实现无头模式?
以下展示如何使用Nstbrowserless,在docker容器中使用Nstbrowser反检测浏览器并设置无头模式抓取网页数据,具体到抓取TikTok主页探索页用户头像为例:
步骤1:页面分析
- 进入TikTok主页。
- 打开控制台元素页面。
- 定位探索页元素。
然后,你可以发现该元素是一个带有属性data-e2e="nav-explore"的a链接元素标签。
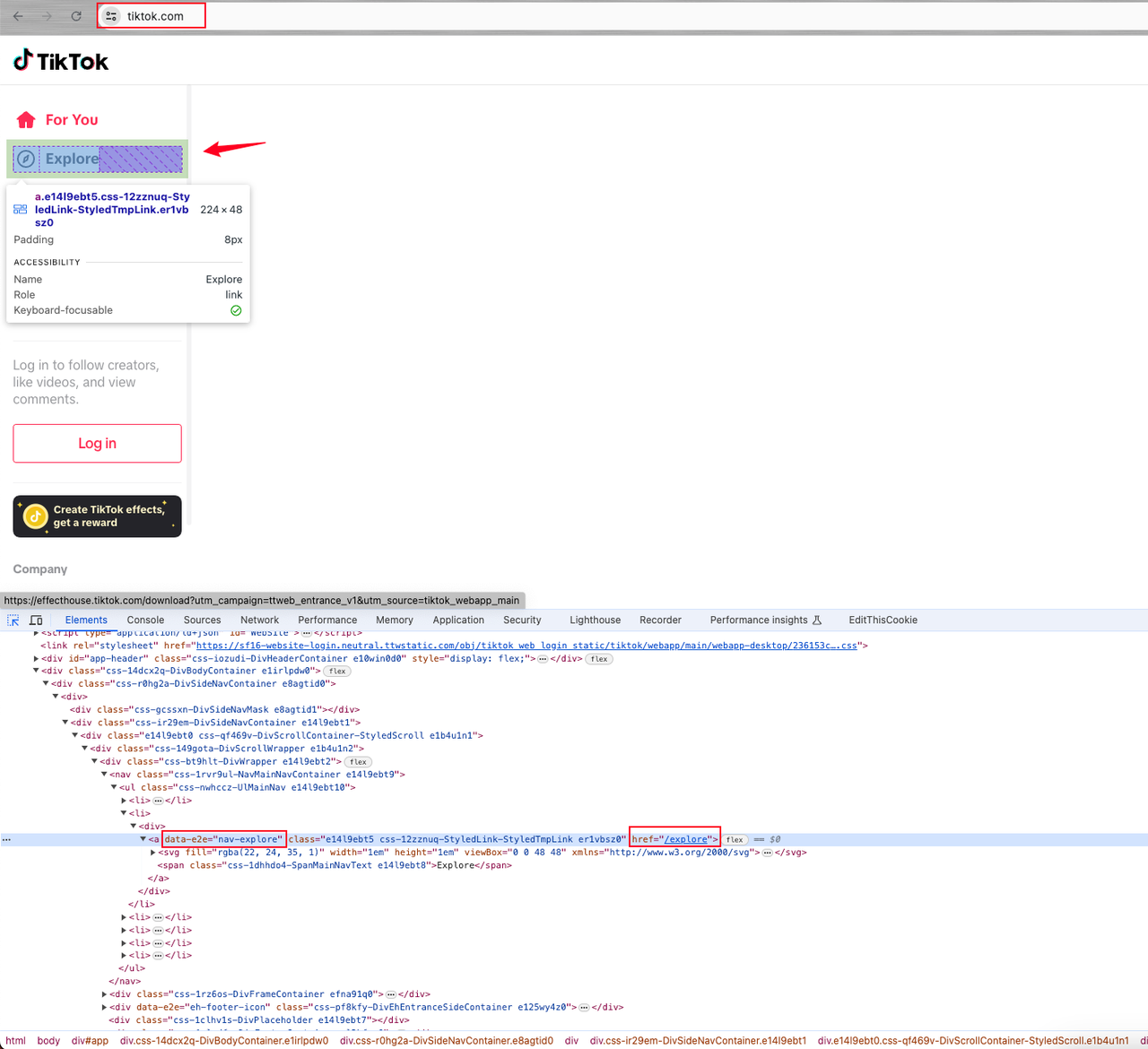
点击探索元素后,我们发现页面没有用户头像,只能得到用户昵称。
为什么会这样?
这是因为我们需要点击昵称进入用户主页才能得到用户头像。
所以,我们必须进入每个用户的主页,然后找到带有属性data-e2e="explore-item-list"的元素,即动态用户列表:
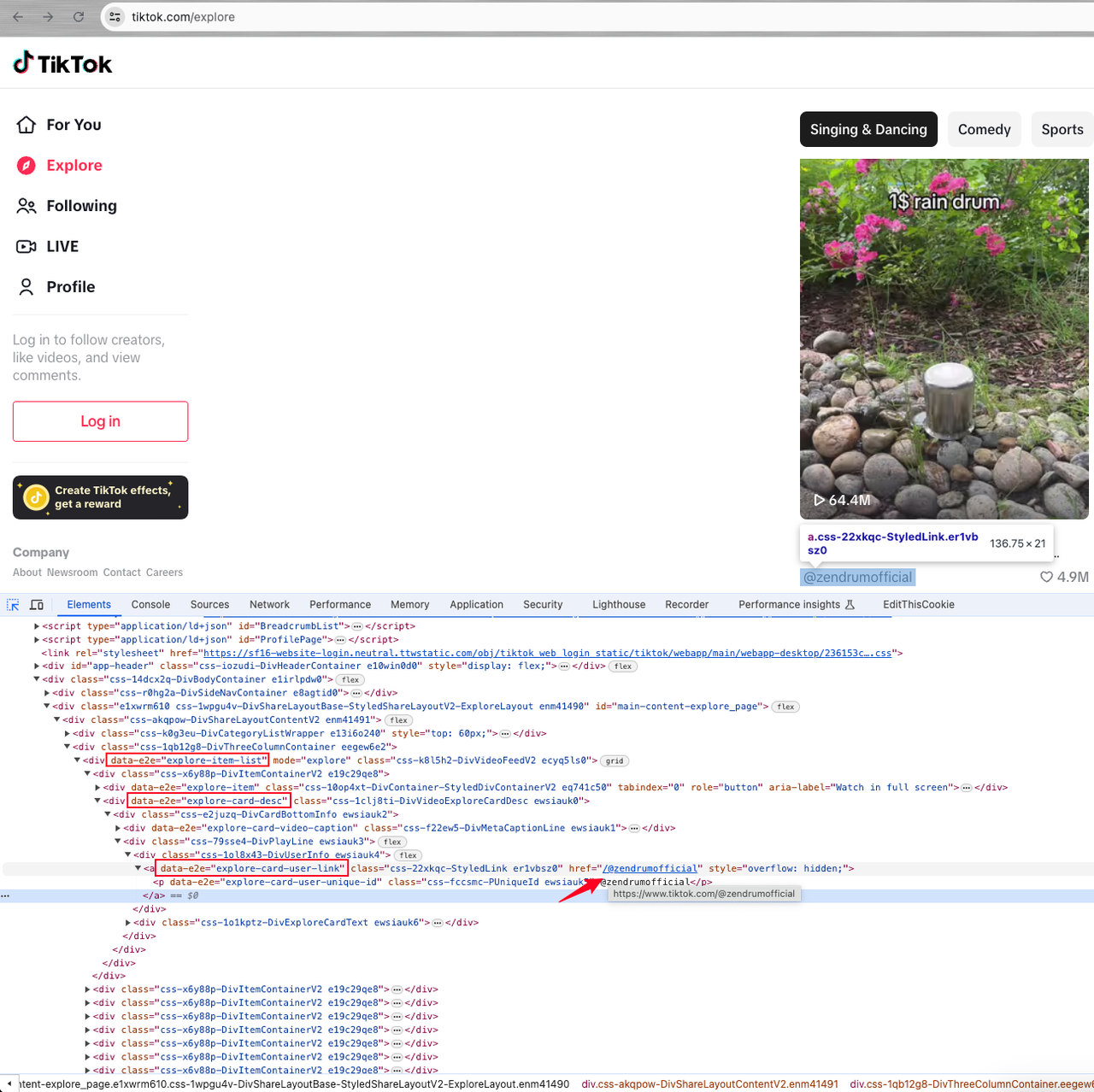
现在,我们需要进行进一步分析。
在列表下的div元素中,有一个带有属性data-e2e="explore-card-desc"的元素,这个元素里面包含一个带有属性data-e2e="explore-card-user-link"的a标签。
a标签的href属性值是用户的id,加上TikTok的域名前缀就是用户的主页。
让我们进入用户的主页并继续分析:
然后我们可以找到一个带有属性div[data-e2e="user-page"]的div[data-e2e="user-avatar"]元素,用户头像是其下方span img元素的src属性值。
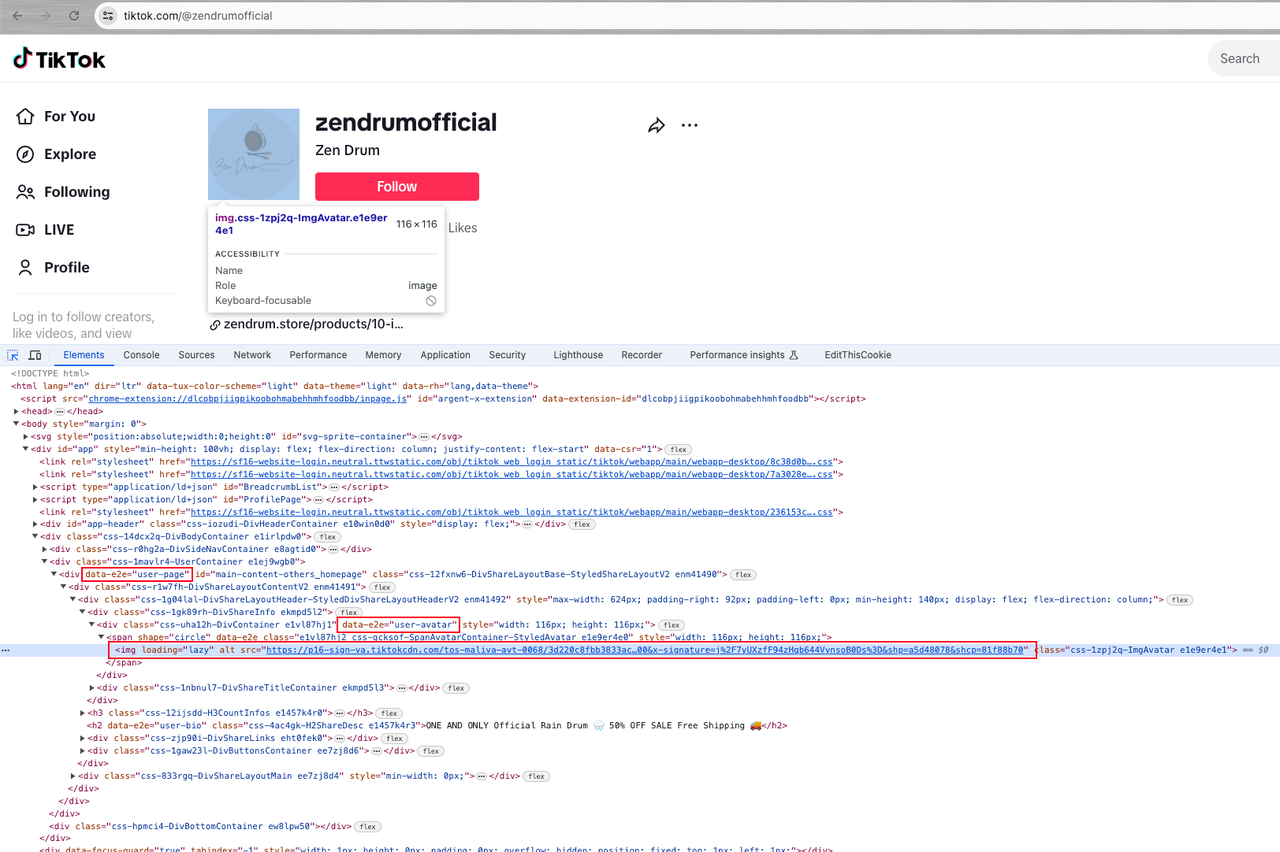
接下来,是时候使用Nstbrowserless获取我们想要的数据了。
步骤2:在使用Nstbrowserless之前,必须提前安装并运行Docker。
Shell
# 拉取镜像
docker pull nstbrowser/browserless:0.0.1-beta
# 运行nstbrowserless
docker run -it -e TOKEN=xxx -e SERVER_PORT=8848 -p 8848:8848 --name nstbrowserless nstbrowser/browserless:0.0.1-beta步骤3: 编码(Python-Playwright)并设置无头模式。
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # 设置无头模式
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # 浏览器参数应为字典
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # 支持:windows, mac, linux
"kernel": 'chromium', # 仅支持:chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # 支持:2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # 支持:2, 4, 8
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("Profile URL: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("chrome://version")
await page.wait_for_load_state('networkidle')
await page.screenshot(path="chrome_version.png")
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())运行上述代码后,你可以在chrome://versionpage中获取以下信息:

内核启动命令中的--headless参数表示内核在无头模式下运行。
数据抓取全局代码:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def scrape_user_profile(browser, user_home_page):
# 进入用户主页并抓取用户头像
user_page = await browser.new_page()
try:
await user_page.goto(user_home_page)
await user_page.wait_for_load_state('networkidle')
user_avatar_element = await user_page.query_selector(
'div[data-e2e="user-page"] div[data-e2e="user-avatar"] span img')
if user_avatar_element:
user_avatar = await user_avatar_element.get_attribute('src')
if user_avatar:
print(user_avatar)
# TODO
finally:
await user_page.close()
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # 支持:true 或 false
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # 浏览器参数应为字典
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # 支持:windows, mac, linux
"kernel": 'chromium', # 仅支持:chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # 支持:2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # 支持:2, 4, 8
},
"proxy": "", # 如果无法浏览TikTok网站,请设置适当的代理
}
query = {
'config': json.dumps(config)
}
profile_url = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profile_url)
tiktok_url = "https://www.tiktok.com"
try:
page = await browser.new_page()
await page.goto(tiktok_url)
await page.wait_for_load_state('networkidle')
explore_elem = await page.query_selector('[data-e2e="nav-explore"]')
if explore_elem:
await explore_elem.click()
ul_element = await page.query_selector('[data-e2e="explore-item-list"]')
if ul_element:
li_elements = await ul_element.query_selector_all('div')
tasks = []
for li in li_elements:
# 查找用户主页url链接
a_element = await li.query_selector('[data-e2e="explore-card-desc"]')
if a_element:
user_link = await li.query_selector('a[data-e2e="explore-card-user-link"]')
if user_link:
href = await user_link.get_attribute('href')
if href:
tasks.append(scrape_user_profile(browser, tiktok_url + href))
await asyncio.gather(*tasks)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())运行程序:
到目前为止,我们已经通过Nstbrowserless使用Python-Playwright完成了抓取TikTok主页探索页用户头像数据。
总结
无头浏览器具有强大的功能和方便的使用方法。它们可以轻松快速地完成网页抓取和自动化任务。
在这篇文章中,我们学习了:
- 什么是Python headlesschrome?
- Python headlesschrome的优点和缺点。
- 如何使用Nstbrowserless进行快速高效的网页抓取。
更多





