
Headless Browser
如何使用Nstbrowser docker爬取YouTube视频?
本教程使用 Nstbrowser Docker 镜像演示爬取 YouTube 视频链接
Jan 08, 2025Carlos Rivera
我们为您提供令人难以置信的90% 折扣订阅优惠!现在,您可以享受以下无与伦比的价格:
- 专业版: 仅需 **29.9/月**(原价 299)
- 企业版: 仅需 **59.9/月**(原价 599)
更重要的是,您将通过自动续订继续享受这些折扣!无需额外步骤——您的折扣将在续订时自动应用。
预备条件
在我们正式开始之前,我们需要了解Nstbrowser。
Nstbrowser 是一款强大的指纹浏览器,可以配置多个指纹,这有助于避免大规模爬取任务中的一些难题,例如机器人检测、验证码识别和IP封锁,并能有效防止访问网站的识别和跟踪。
首先,我们需要获取Nstbrowser中的API Key。
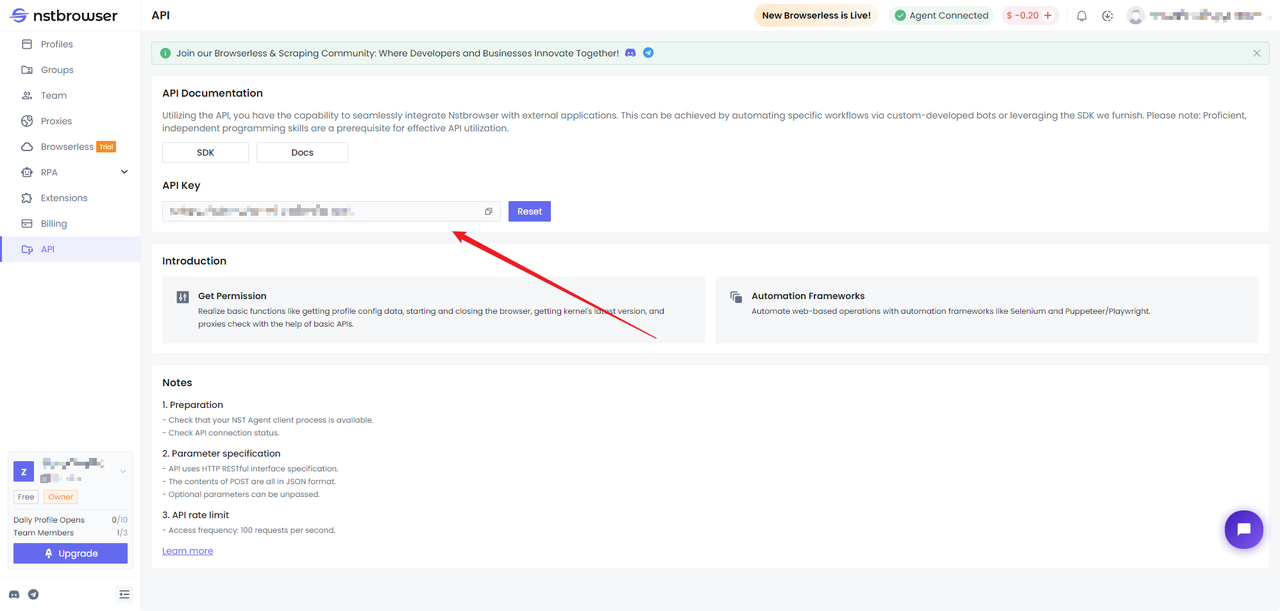
步骤 1. 拉取 Nstbrowser Docker 镜像
Bash
docker pull docker.io/nstbrowser/browserless:latest步骤 2. 运行容器
Bash
docker run -d -it \
-e TOKEN="YOUR API KEY" \
-p 8848:8848 \
--name nstbrowserless \
nstbrowser/browserless:latest步骤 3. 构建爬取脚本
这里我们使用puppeteer-core进行演示
- 安装
puppeteer-core:
Bash
# pnpm
pnpm i puppeteer-core
# yarn
yarn add puppeteer-core
# npm
npm i --save puppeteer-core- 准备 Nstbrowser Docker 配置
这里只列出了部分配置列表。所有配置,请参考Nstbrowser API 文档:https://apidocs.nstbrowser.io/api-10293510。
JavaScript
async function start() {
const config = {
"name": "testProfile",
"platform": "windows",
"kernel": "chromium",
// "proxy": "http://127.0.0.1:8000", //Nstbrowser Docker 支持使用代理进行网络访问
// "doProxyChecking": false,
// "fingerprint": { // 配置所需指纹信息,以绕过访问网站时的追踪
// "flags": {
// "timezone": "BasedOnIp",
// "screen": "Custom"
// },
// "screen": {
// "width": 1000,
// "height": 1000
// },
// "userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.6723.60 Safari/537.36"
// },
// "args": { //支持配置浏览器启动参数
// "--proxy-bypass-list": "*.nstbrowser.io"
// }
};
const query = new URLSearchParams({
config: encodeURIComponent(JSON.stringify((config))),
});
const browserWSEndpoint = `ws://localhost:8848/connect?${query.toString()}`;
await execPuppeteer(browserWSEndpoint);
}- 开始抓取 youtube 上的视频元素
- 首先,我们使用浏览器的开发者工具 (F12) 获取 youtube 上的搜索栏元素和点击搜索按钮元素:
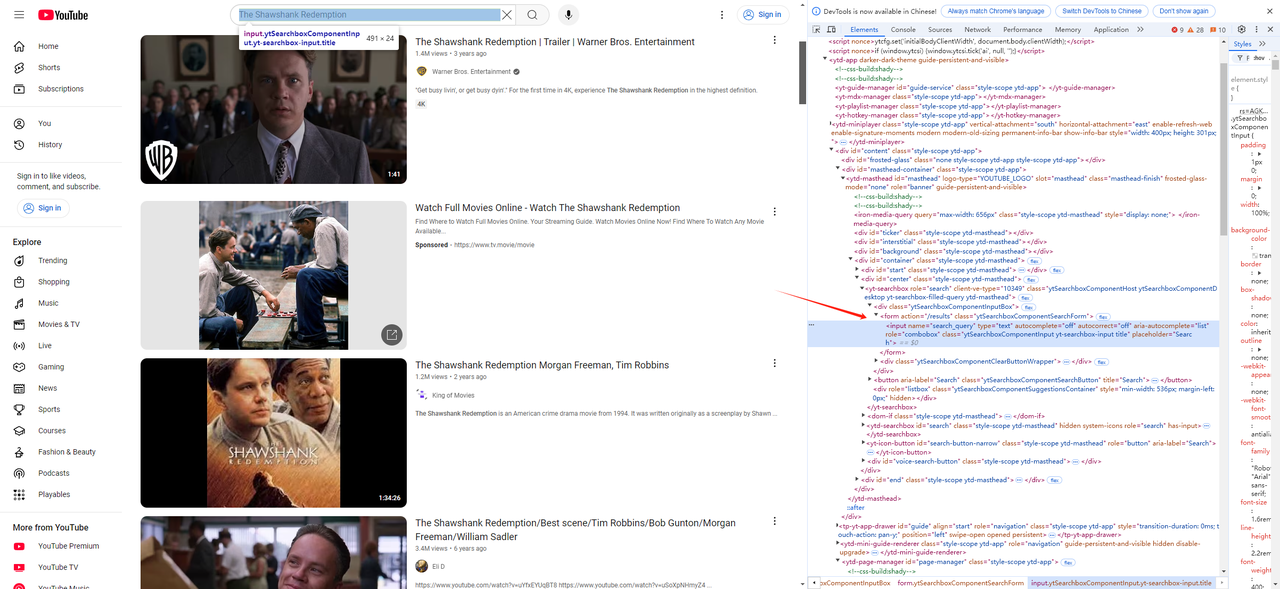
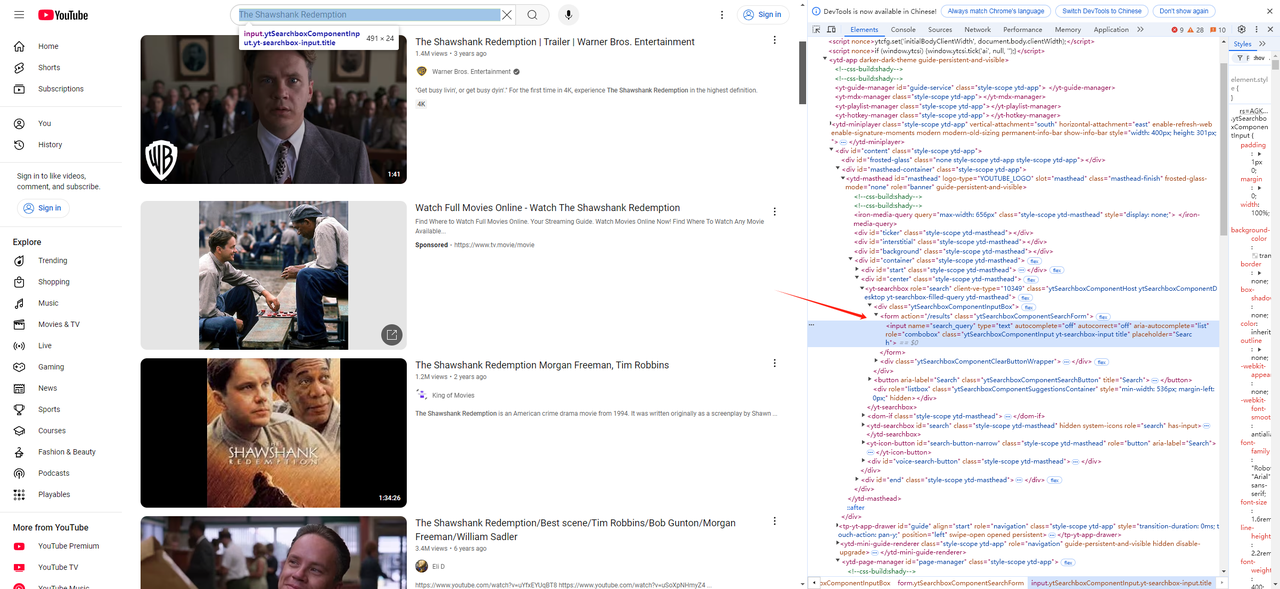
接下来,编写输入搜索脚本和点击搜索脚本:
JavaScript
async function execPuppeteer(browserWSEndpoint) {
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
});
const page = await browser.newPage();
// 访问 youtube
await page.goto('https://www.youtube.com');
// 输入搜索词
await page.type('#center > yt-searchbox > div.ytSearchboxComponentInputBox > form > input', 'The Shawshank Redemption', { delay: '100' }) // 这里,delay 用于延迟每个字符输入的间隔事件,以模拟真实用户输入的场景。
// 点击搜索按钮
await page.click('yt-searchbox button[aria-label=Search]')
// 等待页面元素渲染
await page.waitForSelector('ytd-video-renderer ytd-thumbnail >a')- 使用相同的方法找到我们需要视频信息:
JavaScript
// ytd-video-renderer 标签是每个视频的项目元素
const videoElement = await page.$$('ytd-video-renderer')- 从标签中提取视频标题、频道号、链接等信息:
JavaScript
const renderList = []
for (const element of videoElement) {
const link = await element.$('ytd-thumbnail > a').then((el) => {
return el.evaluate((ele) => {
return `https://www.youtube.com${ele.getAttribute('href')}`;
})
})
const title = await element.$('ytd-thumbnail + div yt-formatted-string').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
const channel = await element.$('ytd-thumbnail + div > div[id=channel-info] yt-formatted-string >a').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
renderList.push({
channel,
title,
link
})
}
console.log("renderList:", renderList)- 运行上述脚本,我们可以获取 youtube 上的视频数据:
JavaScript
renderList: [
{
channel: 'Warner Bros. Entertainment',
title: 'The Shawshank Redemption | Trailer | Warner Bros. Entertainment',
link: 'https://www.youtube.com/watch?v=PLl99DlL6b4&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
{
channel: 'King of Movies',
title: 'The Shawshank Redemption Morgan Freeman, Tim Robbins',
link: 'https://www.youtube.com/watch?v=XIv97tIImz8&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
{
channel: 'Eli D',
title: 'The Shawshank Redemption/Best scene/Tim Robbins/Bob Gunton/Morgan Freeman/William Sadler',
link: 'https://www.youtube.com/watch?v=0spucxvMfjE&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
.......
{
channel: 'BBC Global',
title: 'How The Shawshank Redemption went from flop to hit | BBC Global',
link: 'https://www.youtube.com/watch?v=jbn9IgCIeB4&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
},
{
channel: 'Turner Classic Movies',
title: 'Tim Robbins and Morgan Freeman reflect on 30 years of THE SHAWSHANK REDEMPTION | TCMFF 2024',
link: 'https://www.youtube.com/watch?v=pYmAy3H0s3Q&pp=ygUYVGhlIFNoYXdzaGFuayBSZWRlbXB0aW9u'
}
]完整代码:
JavaScript
import puppeteer from 'puppeteer-core';
import express from "express";
async function execPuppeteer(browserWSEndpoint, search) {
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
});
const page = await browser.newPage();
await page.goto('https://www.youtube.com');
await page.type('#center > yt-searchbox > div.ytSearchboxComponentInputBox > form > input', search, { delay: '100' })
await page.click('yt-searchbox button[aria-label=Search]')
await page.waitForSelector('ytd-video-renderer ytd-thumbnail >a')
const videoElement = await page.$$('ytd-video-renderer')
const renderList = []
for (const element of videoElement) {
const link = await element.$('ytd-thumbnail > a').then((el) => {
return el.evaluate((ele) => {
return `https://www.youtube.com${ele.getAttribute('href')}`;
})
})
const title = await element.$('ytd-thumbnail + div yt-formatted-string').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
const channel = await element.$('ytd-thumbnail + div > div[id=channel-info] yt-formatted-string >a').then((el) => {
return el.evaluate((ele) => {
return ele.textContent
})
})
renderList.push({
channel,
title,
link
})
}
console.log(renderList);
await browser.close();
return renderList;
} catch (err) {
console.log(`Error fetching ${selector}:`, e);
}
}
async function start(search) {
const config = {
"name": "testProfile",
"platform": "windows",
"kernel": "chromium",
"kernelMilestone": "130",
// "proxy": "http://127.0.0.1:8000",
// "doProxyChecking": false,
// "fingerprint": {
// "flags": {
// "timezone": "BasedOnIp",
// "screen": "Custom"
// },
// "screen": {
// "width": 1000,
// "height": 1000
// },
// "userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.6723.60 Safari/537.36"
// },
// "args": {
// "--proxy-bypass-list": "*.nstbrowser.io"
// }
};
const query = new URLSearchParams({
config: encodeURIComponent(JSON.stringify((config))),
});
const browserWSEndpoint = `ws://localhost:8838/connect?${query.toString()}`;
return await execPuppeteer(browserWSEndpoint, search);
}
const app = express();
app.get("/youtube/:search", async (req, resp) => {
const search = req.params.search;
const renderList = await start(search);
resp.send({ "code": 200, "data": renderList })
})
app.listen(8080, () => console.log("Listening on PORT: 8080"))Nstbrowser Docker API 使用
在运行过程中,您也可以调用容器服务中的其他API来操作容器中的浏览器
- http://localhost:8848/start
- 方法:POST
步骤 1. 启动一个新的浏览器实例:
JavaScirpt
请求:
{
"name": "testProfile",
"once": true,
"platform": "windows",
"kernel": "chromium",
"kernelMilestone": "130",
"fingerprint": {
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.6613.85 Safari/537.36"
}
}
响应:
{
"data": {
"profileId": "4a9911a9-6d28-41b9-8bf4-cc08592afcbd",
"port": 31685,
"webSocketDebuggerUrl": "ws://127.0.0.1:31685/devtools/browser/19df3c03-2b13-49db-ac1d-989bb68a353f"
},
"err": false,
"msg": "success",
"code": 200
}步骤 2. 启动完成后,您可以通过webSocketDebuggerUrl参数的URL直接连接到刚刚启动的浏览器,执行其他脚本命令。
关闭指定profileId的浏览器实例:
JavaScript
响应:
{
"data": null,
"err": false,
"msg": "success",
"code": 200
}关闭所有浏览器实例:
JavaScript
响应:
{
"data": null,
"err": false,
"msg": "success",
"code": 200
}获取所有正在运行的浏览器实例:
JavaScript
响应:
{
"data": [
{
"profileId": "605ffe1f-7bdf-4ac7-b0bb-70746cb92a0f",
"remoteDebuggingPort": 26192,
"running": true,
"starting": false,
"stopping": false
},
{
"profileId": "8693f526-5a9f-4669-86db-c48866921ffc",
"remoteDebuggingPort": 45850,
"running": true,
"starting": false,
"stopping": false
}
],
"err": false,
"msg": "success",
"code": 200
}获取浏览器实例打开的页面列表。通过页面列表,我们可以随时检查浏览器操作状态:
JavaScript
响应:
{
"data": [
{
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=127.0.0.1:45850/devtools/page/401571FE7D5A477074F539B39AEE0EC6",
"id": "401571FE7D5A477074F539B39AEE0EC6",
"title": "tiktok - Google Search",
"type": "page",
"url": "https://www.google.com/search?q=tiktok&oq=tikto&gs_lcrp=EgZjaHJvbWUqDQgAEAAYgwEYsQMYgAQyDQgAEAAYgwEYsQMYgAQyBggBEEUYOTINCAIQABiDARixAxiABDIKCAMQABixAxiABDIKCAQQABixAxiABDIKCAUQABixAxiABDIHCAYQABiABDIHCAcQABiABDIKCAgQABixAxiABDINCAkQLhiDARixAxiABNIBCTgyMzJqMGoxNagCALACAA&sourceid=chrome&ie=UTF-8",
"webSocketDebuggerUrl": "ws://127.0.0.1:45850/devtools/page/401571FE7D5A477074F539B39AEE0EC6"
},
{
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=127.0.0.1:45850/devtools/page/293BECFB09421FE88DB74CB222AFDCA6",
"id": "293BECFB09421FE88DB74CB222AFDCA6",
"title": "The Shawshank Redemption - YouTube",
"type": "page",
"url": "https://www.youtube.com/results?search_query=The+Shawshank+Redemption",
"webSocketDebuggerUrl": "ws://127.0.0.1:45850/devtools/page/293BECFB09421FE88DB74CB222AFDCA6"
}
],
"err": false,
"msg": "success",
"code": 200
}最后的想法
Nstbrowser Docker 提供了一个方便的 Nstbrowser 指纹浏览器服务。通过 docker 容器技术,它可以很好地隔离主机上的复杂环境,并支持在不同平台上运行 Nstbrowser 浏览器服务。容器隔离可以在本地运行多个实例,爬取不同网站的数据,并实现反用户追踪。
更多





