
Headless Browser
Безголовый браузер: Как запустить его на Playwright?
Что такое headlesschrome? Как насчет его преимуществ и недостатков? В этом блоге мы найдем всю информацию о нем и узнаем, как использовать Nstbrowserless для веб-скрапинга.
Jul 16, 2024Luke Ulyanov
Традиционный браузер с графическим интерфейсом (GUI) обычно потребляет большое количество системных ресурсов по мере увеличения рабочей нагрузки. Кроме того, он требует видимого окна для отображения веб-страниц, что замедляет выполнение тестов и ограничивает масштабируемость.
Headlesschrome — это инструмент, который может плавно обрабатывать динамическое содержимое без необходимости в реальном браузере.
Он решает проблему ресурсоемкого тестирования, позволяя более эффективно выполнять тесты и улучшать масштабируемость.
Как же запустить headless браузер в Python и Selenium?
Начните читать эту статью прямо сейчас!
Что такое Python Headlesschrome?
Наш браузер — это компьютерная программа, которая позволяет пользователям просматривать и взаимодействовать с веб-страницами. С другой стороны, headless браузер не имеет графического интерфейса. Что же он может делать? Очень ли он отличается? Да! Эта функция помогает Python headlesschrome:
- Переходить на любой сайт в Интернете.
- Отображать JavaScript файлы, предоставленные сайтом.
- Взаимодействовать с компонентами этой веб-страницы.
Ой, подождите! У вас может возникнуть вопрос, как мы можем взаимодействовать с Headlesschrome. Ведь у него нет GUI!
Не волнуйтесь, дорогие. Позвольте мне показать вам Web Driver.
Еще один вопрос — что это? Web Driver — это фреймворк. Он позволяет нам управлять различными веб-браузерами через программирование.
Есть ли типичный пример? Да, мы все знакомы с Selenium. Мы часто его используем, но знаете ли вы, что он также является важным headless браузером?
Преимущества Python headlesschrome:
- Автоматизированные задачи. Headless браузер может автоматически выполнять действия браузера, такие как нажатие, заполнение форм, отправка и т. д. Это подходит для автоматизированного тестирования и автоматизации задач.
- Меньшее потребление ресурсов. Он не нуждается в отрисовке графических элементов для браузера и сайта.
- Очень быстро. Headlesschrome не нужно ждать полной загрузки страницы, что значительно ускоряет процесс скрапинга.
- Симуляция реального поведения пользователя. Он может имитировать среду и поведение браузера пользователя, что помогает обойти защиту от ботов.
- Гибкость. Он может легко контролировать поведение браузера через программирование, например, устанавливая заголовки запросов, обрабатывая куки, обрабатывая элементы страницы и т. д. Это очень полезно для сложного сбора данных или операций.
- Адаптивность. Headlesschrome способен обрабатывать широкий спектр веб-сайтов и динамического контента, таких как одностраничные приложения (SPA) или страницы, требующие отображения JavaScript.
Недостатки Python headlesschrome:
- Отсутствие визуального отображения для отладки и тестирования. Headless браузеры не отображают страницы визуально во время выполнения тестов, что усложняет отладку и тестирование.
- Проблемы со стабильностью и надежностью. Из-за изменений в структуре веб-сайта или проблем с сетью, headlesschrome нужно обрабатывать своевременно.
- Обновление и обслуживание. Зависимость от сторонних библиотек и обновлений версий браузера может потребовать периодического обновления кода для адаптации к новым функциям браузера или исправления ошибок.
- Меры против скрапинга. Веб-сайты всегда обнаруживают и блокируют автоматизированный доступ. Поэтому необходимо применять несколько мер для обхода защиты от ботов, таких как настройка соответствующих заголовков запросов, имитация человеческого поведения и т. д.
Nstrowser может высоко имитировать человеческое поведение для обхода защиты от ботов и разблокировки веб-сайтов! Попробуйте бесплатно сейчас!
Есть ли у вас хорошие идеи или вопросы о веб-скрейпинге и Browserless?
Посмотрите чем делятся другие разработчики в Discord и Telegram!
6 headless браузеров, поддерживаемых Python Selenium
Насколько мощен Selenium! Сколько же headless браузеров он поддерживает? Давайте выделим 6 из них прямо сейчас! Они управляются и манипулируются в основном через Web Driver.
- Chrome
- Firefox
- Edge
- Safari
- Opera
- Chromium
3 лучших альтернативы Python headlesschrome?
Python Selenium headlesschrome не является единственным headless браузером!
Давайте рассмотрим другие альтернативы. Некоторые из них предлагают только один язык программирования, другие могут предлагать привязки к нескольким языкам.
1. Puppeteer
Puppeteer — это библиотека Node.js, разработанная Google. Она предоставляет высокоуровневый API для управления headless Chrome или Chromium браузером. Puppeteer предлагает мощные функции для автоматизации задач браузера, создания скриншотов и PDF, а также выполнения JavaScript кода на веб-страницах.
2. Playwright
Playwright — это еще один инструмент для автоматизации веб-сайтов, разработанный участниками от Microsoft. По сути, это также библиотека Node.js для автоматизации браузера, но она предоставляет API для других языков, таких как Python, .NET и Java. Он относительно быстрее по сравнению с Python Selenium.
3. Nstbrowser
Что такое Nstbrowser?
Nstbrowser — это полностью бесплатный антидетект-браузер. Он позволяет выполнять веб-скрапинг в headless режиме, полностью освобождая от ограничений локальных ресурсов. Легко осуществлять веб-скрапинг и автоматизацию процессов.
- Легко выполнять массовые параллельные задачи, эффективно экономя ресурсы и время.
- Выполнять любые скрипты и осуществлять сложные операции браузера или задачи веб-скрапинга с помощью headless браузера.
- Отслеживать использование ОЗУ, ЦП и ГП, чтобы убедиться, что браузер потребляет правильное количество ресурсов.
- Реагировать на резкое увеличение трафика, динамически распределяя ресурсы для балансировки и масштабирования нагрузок.
- Предоставлять выделенные серверные экземпляры для получения более высокой производительности, более гибких вариантов конфигурации и лучшей изоляции.
Как использовать Nstbrowserless для достижения Headless?
Ниже показано, как использовать Nstbrowserless, использовать антидетект браузер Nstbrowser в docker-контейнере и настроить headless режим для скрапинга веб-данных, в частности для скрапинга аватарок пользователей на домашней странице Explore page TikTok:
Шаг 1. Анализ страницы
- Перейдите на домашнюю страницу TikTok.
- Откройте консоль элементов страницы.
- Найдите элемент страницы Explore.
Тогда вы обнаружите, что элемент — это a элемент ссылки с атрибутом data-e2e="nav-explore".
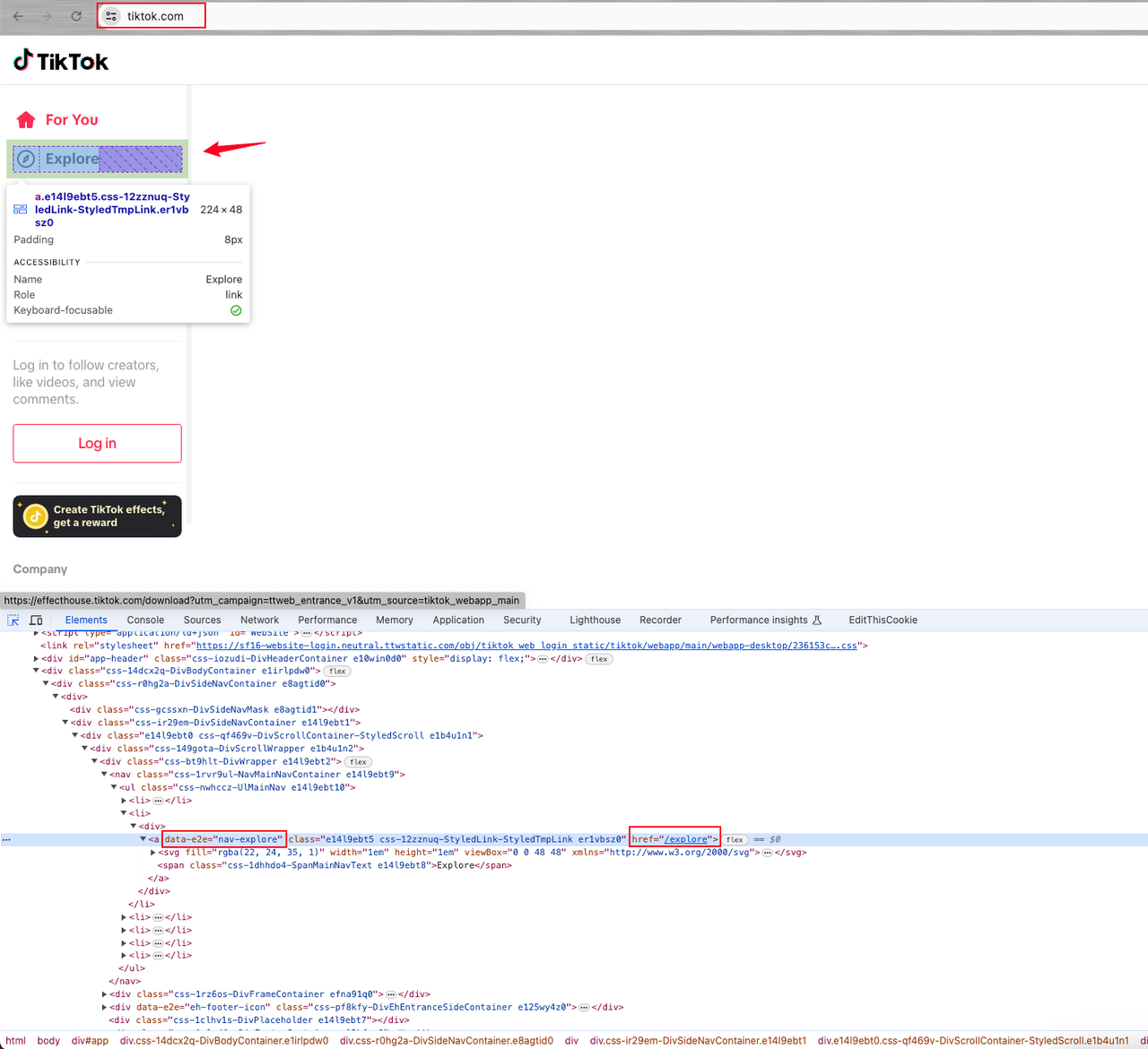
После нажатия на элемент Explore мы обнаруживаем, что на странице нет аватаров пользователей, и мы можем получить только никнеймы пользователей.
Почему это так?
Это потому, что нам нужно нажать на никнейм, чтобы перейти на домашнюю страницу пользователя, прежде чем мы сможем получить аватар пользователя.
Итак, нам нужно перейти на домашнюю страницу каждого пользователя, а затем найти элемент с атрибутом data-e2e="explore-item-list", который представляет собой динамический список пользователей:
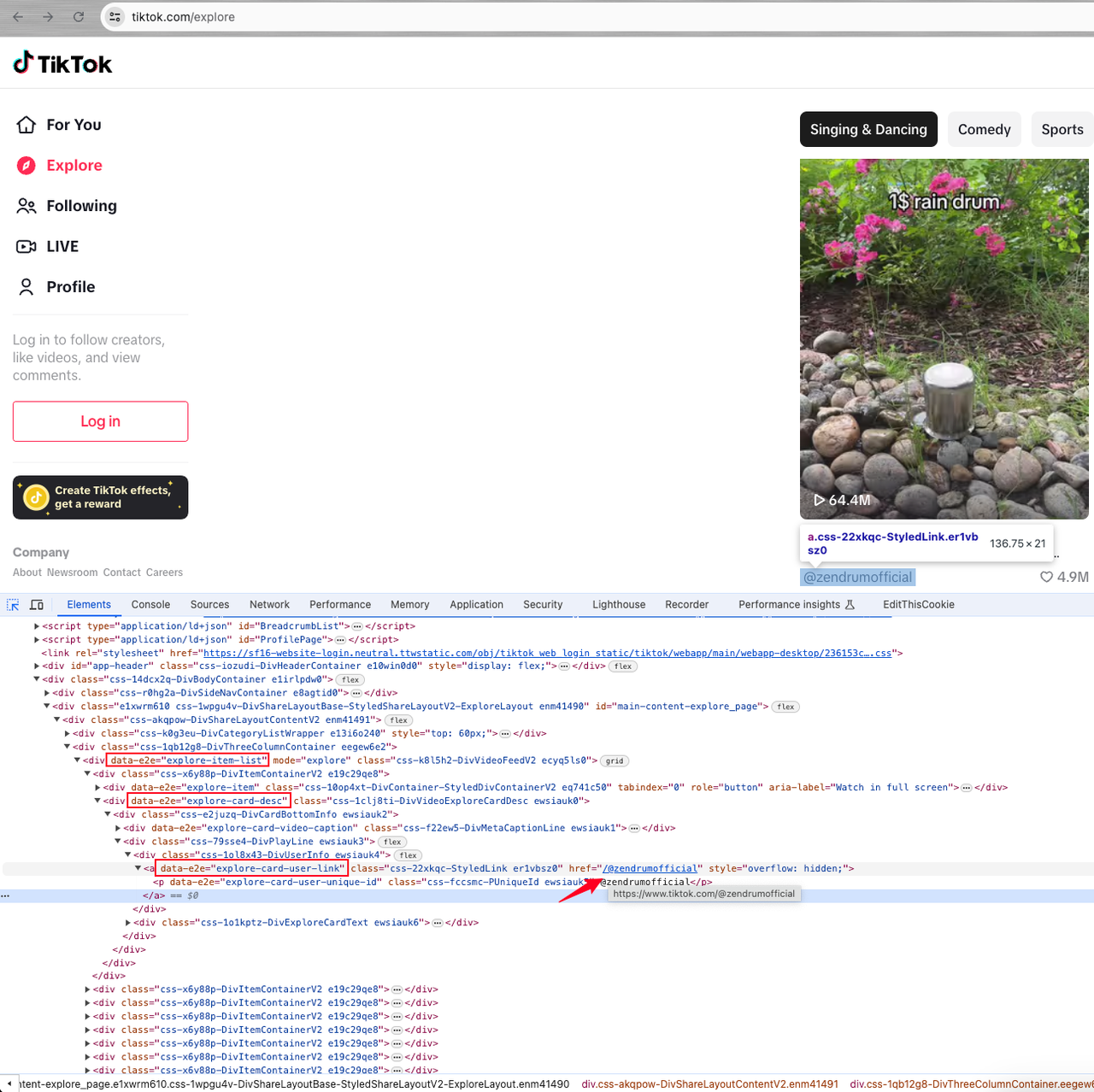
Теперь нам нужно завершить дополнительный анализ.
В элементе div под списком есть элемент с атрибутом data-e2e="explore-card-desc", который содержит тег a с атрибутом data-e2e="explore-card-user-link".
Значение атрибута href тега a является идентификатором пользователя. Добавление префикса доменного имени TikTok дает домашнюю страницу пользователя.
Перейдем на домашнюю страницу пользователя и продолжим анализ:
Тогда мы обнаружим элемент div[data-e2e="user-avatar"] с атрибутом div[data-e2e="user-page"], где аватар пользователя является значением атрибута src элемента span img под ним.
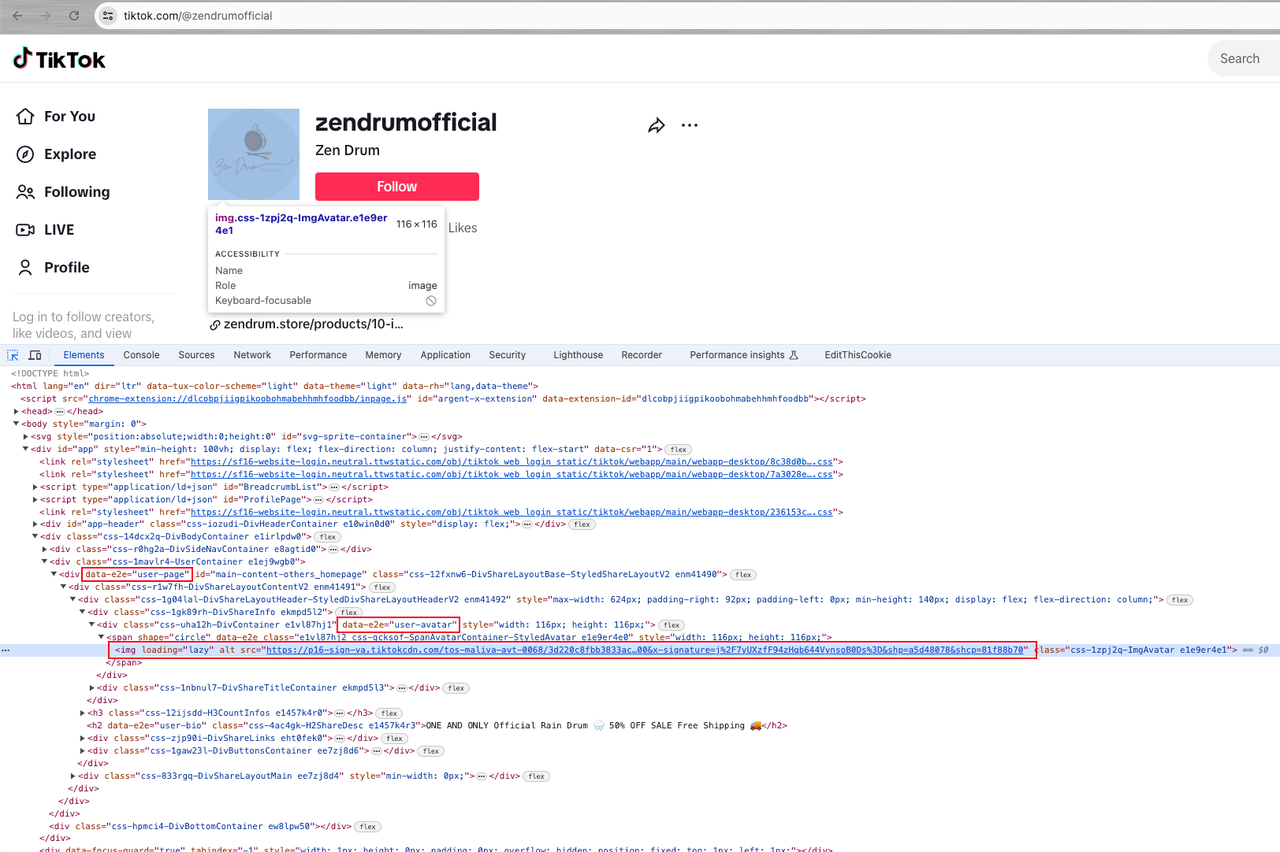
Теперь пришло время использовать Nstbrowserless для получения данных, которые нам нужны.
Шаг 2. Перед использованием Nstbrowserless, необходимо предварительно установить и запустить Docker.
Shell
# загрузить образ
docker pull nstbrowser/browserless:0.0.1-beta
# запустить
nstbrowserless
docker run -it -e TOKEN=xxx -e SERVER_PORT=8848 -p 8848:8848 --name nstbrowserless nstbrowser/browserless:0.0.1-betaШаг 3. Кодирование (Python-Playwright) и настройка headless режима.
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # установить headless режим
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # аргументы браузера должны быть словарем
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # поддержка: windows, mac, linux
"kernel": 'chromium', # поддержка только: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # поддержка: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # поддержка: 2, 4, 8
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("URL профиля: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("chrome://version")
await page.wait_for_load_state('networkidle')
await page.screenshot(path="chrome_version.png")
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Запустите приведенный выше код, и вы получите следующую информацию на странице chrome://version:

Параметр --headless в командной строке запуска ядра указывает на то, что ядро работает в headless режиме.
Код для скрапинга данных:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def scrape_user_profile(browser, user_home_page):
# перейти на домашнюю страницу пользователя и скрапить аватар пользователя
user_page = await browser.new_page()
try:
await user_page.goto(user_home_page)
await user_page.wait_for_load_state('networkidle')
user_avatar_element = await user_page.query_selector(
'div[data-e2e="user-page"] div[data-e2e="user-avatar"] span img')
if user_avatar_element:
user_avatar = await user_avatar_element.get_attribute('src')
if user_avatar:
print(user_avatar)
# TODO
finally:
await user_page.close()
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # поддержка: true или false
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # аргументы браузера должны быть словарем
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # поддержка: windows, mac, linux
"kernel": 'chromium', # поддержка только: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # поддержка: 2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # поддержка: 2, 4, 8
},
"proxy": "", # установить подходящий прокси, если вы не можете исследовать сайт TikTok
}
query = {
'config': json.dumps(config)
}
profile_url = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profile_url)
tiktok_url = "https://www.tiktok.com"
try:
page = await browser.new_page()
await page.goto(tiktok_url)
await page.wait_for_load_state('networkidle')
explore_elem = await page.query_selector('[data-e2e="nav-explore"]')
if explore_elem:
await explore_elem.click()
ul_element = await page.query_selector('[data-e2e="explore-item-list"]')
if ul_element:
li_elements = await ul_element.query_selector_all('div')
tasks = []
for li in li_elements:
# найти URL ссылок на домашнюю страницу пользователя
a_element = await li.query_selector('[data-e2e="explore-card-desc"]')
if a_element:
user_link = await li.query_selector('a[data-e2e="explore-card-user-link"]')
if user_link:
href = await user_link.get_attribute('href')
if href:
tasks.append(scrape_user_profile(browser, tiktok_url + href))
await asyncio.gather(*tasks)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Запуск программы:
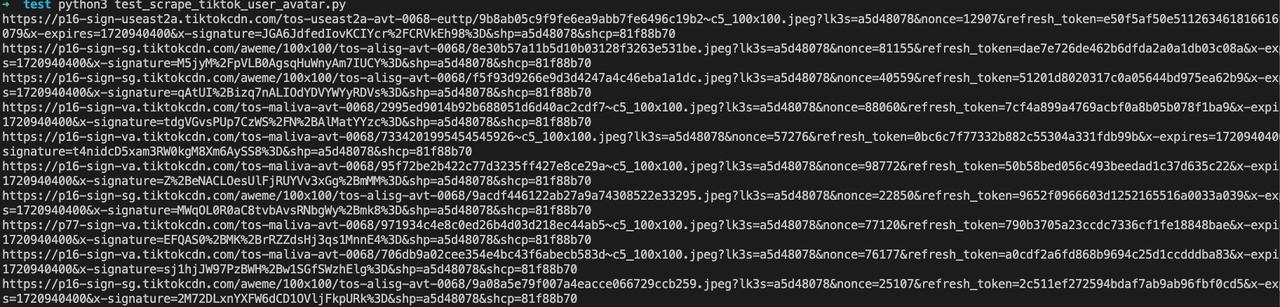
Таким образом, мы завершили скрапинг данных аватаров пользователей на странице Explore домашней страницы TikTok с использованием Python-Playwright через Nstbrowserless.
Выводы
Headless браузеры обладают мощными функциями и удобными методами использования. Они могут легко и быстро выполнять веб-скрапинг и автоматизацию.
В этой статье мы узнали:
- Что такое Python headlesschrome?
- Преимущества и недостатки Python headlesschrome.
- Как использовать Nstbrowserless для быстрого и эффективного веб-скрапинга.
Начните использовать бесплатный Nstbrowser для выполнения всех задач прямо сейчас!
Больше





